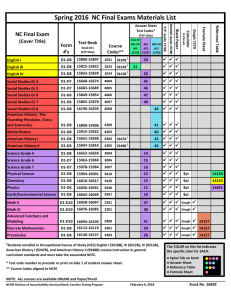
Initial studies of SCI LAN topologies for local area clustering Abstract
advertisement

Initial studies of SCI LAN topologies for local area clustering Haakon Bryhni* and Bin Wu**, University of Oslo, Norway * Department of Informatics. Email: bryhni@ifi.uio.no ** Department of Physics, Email: bin.wu@fys.uio.no Abstract A Local Area Network (LAN) can be built using the ANSI/IEEE Standard 1592-1992 Scalable Coherent Interface (SCI) as the underlying hardware protocol. For the LAN, SCI will act as a new physical layer, and traditional protocols (as e.g. TCP/IP) may be run on top of SCI. In a first approach, SCI is used to implement message passing while new protocols and functions that take advantage of the shared memory functionality can be developed. In this paper we do initial studies of throughput and latency at the physical layer for some SCI LAN candidate topologies. This performance will be a hard upper bound for application performance. SCI LANs based on ring, switched star and a mixed topology of hubs and a switched backbone are considered, and simulations are done to show how the performance metrics throughput and latency varies as function of topology and the physical transmission distance of the network. The new point in this study is to focus on the effect of increasing transmission distance to show that a LAN as well as a closely coupled system can be built by using the SCI interconnect. 1. Introduction The ANSI/IEEE 1596-1992 Scalable Coherent Interface is a standard giving computer-bus like service to nodes in a distributed environment. SCI scales well, and avoids the limitations of buses by using many point-to-point links and a hardware-embedded packet protocol to provide coherent and non-coherent shared memory to the nodes. The nodes in SCI may be processors, memories and I/O units or complete workstations (WS) connected to SCI by means of a Cluster Adapter (CLAD) doing protocol conversion between the WS bus and the SCI interconnect as shown in figure 1 [CLAD]. workstation[N] CLAD cpu mem SCI LAN I/O workstation[1] CLAD cpu mem I/O local-area “bus” with topology X Figure 1: Local area computing environment The flexibility of the interconnect allows a wide range of topologies ranging from tightly to loosely coupled systems. In this paper, we examine some candidate topologies for a loosely coupled system of SCI-connected workstations forming a Local Area Computing Environment (LACE). In a LAN environment, distances between nodes are typically in the range of 10 to 1000m. Most studies on topologies for SCI so far has been done on tightly coupled systems [e.g. Bothner93], where the effect of varying physical distance between the nodes are not considered in detail. The new point in this study is to focus on the effect of increasing transmission distance to show that a LAN as well as a closely coupled system can be built by using the SCI interconnect. A Local Area Network is characterized by a number of factors, such as the coverage of a small geographic region, the communication channels between the interconnected computers are usually privately owned (one administrative domain, often trusted nodes), the channels have a low bit error rate and are of relatively high capacity, etc. SCI matches all these requirements, and adds features such as hardware support for coherent shared memory, high-end throughput of Gbyte/s and good architectural support for design of multiprocessor systems. For computer communication, there exists two distinct methods of communication, message passing and shared memory [Tanenbaum87]. The idea of SCI LAN is closely connected to the distinction between these communication paradigms. All Local Area Networks of widespread use are based on message passing, but the advent of hardware-supported coherent shared memory (implemented by transactions in the interconnect) allow computers in a LACE to communicate by using shared memory in stead of message passing. The complexity of providing coherent shared memory in such a system is hidden by hardware, and the communication protocols may exploit the simpler shared memory communication paradigm. Use of the coherence mechanisms may further increase both performance and functionality. Using shared memory for interprocess communication is well known from multiprocessor systems [Delp88, Cheriton94], but is it possible to get the benefit of these features also in a loosely coupled LAN-like system? This will require high throughput and low latency even when transmission distance increases. In our opinion, latency is the most crucial parameter that will be discussed in the following sections. We use a simulation model to compare the candidate topologies. Our modelling and model assumptions are discussed in section 2. In section 3 the selected topologies are presented, and in section 4 the simulation results are discussed. Section 5 contains our conclusions. 2. Modelling and Model Assumptions In this section, we briefly discuss model assumptions for the simulations. 2.1 Simulation model The simulation model is a discrete-event simulator, implemented in the Modsim II programming language [MODSIM]. 2.2 Traffic We choose one common arrival intensity λ , and a negative exponential arrival distribution is used. λ is selected to give a heavy traffic load, but low enough to give reasonable latency. We use a simple traffic model, where burstiness, variations in application frame lengths and the properties of segmentation and reassembly of packets are not considered. All traffic is modelled as memory accesses with a 64-byte cache line granularity. Since we do not know the locality of SCI LAN accesses, we limit our study to two cases as shown in figure 2, 1) uniform distributed targetId’s, and 2) the central server case where one server takes 90% of total traffic (typically a multimedia server), while the rest of the traffic is uniformly distributed over all nodes. 1 Initial studies of SCI LAN topologies for local area clustering 1) Table 1: Simulation parameters 2) Parameter Value CLAD parameters τ Figure 2: Two cases of traffic distribution We model the traffic between the workstations and the server as SCI transactions DMOVE64. This is an SCI transaction moving 64 byte data with 16 byte overhead. This transaction does not require the SCI response subaction. 2.3 Physical interface We have chosen to use simulation parameters from the NodeChipTM SCI interface from Dolphin Inc., since this chip can be used in early SCI LAN applications. We simulated the 62.5 MHz CMOS chip, with 125 Mbyte/s link speed. Results for other implementations may be obtained by scaling the results to other interface chip speeds. We note, however, that the overhead introduced in higher layer protocol processing in the end-systems usually dominate over latencies introduced in the physical layer. Different approaches may be taken to overcome the protocol processing bottleneck, but in this paper we study latency and throughput on the physical layer only, since this gives us a hard upper bound of application performance. A switch can be made by N node interface chips interconnected by e.g. a non-blocking switch [Wu94]. We do not go into detail about the switch architecture, but assume that a 16 port switch can be designed by e.g. interconnecting 2x2 or 4x4 switches. We give some rough parameters in Table 1. Hubs interconnect several SCI links, and may be implemented as both rings or switches. Simulations will show the benefits of different topologies. For the physical interface, we use a propagation speed of 2.0 108 m/s which is derived from physical measurements, and we assume error free transmission. 2.4 Parameters The parameters are set as realistic as possible: 16 nodes is a reasonable (but still small) number of workstations in a LACE and we believe that both ring and switch topologies can be realized by using CMOS technology. Table 1 summarize model parameters used in the simulation. CLAD (WS bus response time) 400 ns Nodechip Bypass FIFO delay 16 ns # 4 * 80 byte buffers (input and output, request and response) of the node interface 1 Switch parameters Switch architecture Non-blocking crossbar Routing strategy Virtual Cut-trough τ Decode (Switch addr. decoding) 10 ns τ Switch (internal port-port delay) 100 ns # 4 * 80 byte buffers (input and output, request and response) of the switch 2 The parameter τ CLAD is the memory cycle time in the receiver. This parameter gives an upper bound on receive performance for each node. Cut-through routing [Bertsekas92] give the advantage of pipelining the switching process. 2.5 Performance metrics Throughput X and latency τ are simulated as experienced on the bus between an SCI interface and the rest of the CLAD logic (typically local bus “glue” logic). We assume a CLAD can follow maximum link throughput. There are two common definitions of latency, including and excluding the queuing delay in the network adapter (here: CLAD). In the first definition, latency is calculated from the generation of a packet until it is received in the destination processor or memory. In this case, both network latency, interface speed and processor/memory latency are considered. This is interesting from a users points of view, since the user experience only application performance. From a network designers view, the performance of the interconnect itself is an important upper bound for the overall system performance. To study the interconnect isolated from the interconnected systems, we exclude the queuing delay in the network adapter, and measure from the time a packet enters the SCI interface until it is received in the interface at the destination (see figure 3). Table 1: Simulation parameters Parameter Number of nodes N 2 Value 16 (3.1, 3.2) and 32 (3.3) NodeChip clock speed C 62.5 MHz Transmission speed R on serial fiber-optical link 1 Gbit/s Transaction arrival rate λ 106 Distance L 10-1000 m workstation A 2 * 10 m/s SCI Transactions used DMOVE64 8 CLAD B CLAD A CLAD LOGIC SCI IF SCI LAN SCI IF CLAD LOGIC Definition of throughput bus A Signal propagation velocity workstation B and latency Figure 3: Point of measurement bus B Initial studies of SCI LAN topologies for local area clustering We have chosen to show overall mean throughput and the mean latency experienced by all nodes. X is then the sum of all packets on all nodes sent successfully per second, τ is the average time from a packet enters the SCI interface in a workstation until it is received in the SCI interface in the target workstation. ∑ Xi i=1 workstation[1] ws[..] N N X = ws[2] 1 τ = ---N ∑ τi L i=1 ws[N] For all measurements, gross throughput X are given, net throughput (SCI user payload) are always 64/80 = 80% of this figure. Demands for throughput and latency are given by the applications and will vary for the different traffic sources. Generally, we would like to maximize X and minimize τ . Isochronous channels (e.g. audio and video) in particular, demands low latency and little variation in latency (jitter) but can to some extent tolerate loss of packets. Asynchronous channels (like e.g. memory accesses) can tolerate jitter but want high throughput, low average τ and no packet loss. The fact that the transfer of large data blocks are optimal when the transmission distance increases, is considered, and leads to the use of SCI move transactions that do not have response subactions. Protocols to ensure guaranteed delivery is left to the upper layers of the protocol as an end-to-end responsibility to minimize network processing of each packet and maximize throughput. Figure 4: SCI LAN ring topology 3.2 SCI LAN Switch-based hub In figure 5, the hub is designed by means of a switch. Each connection is now a point-to point dedicated communication link. ws[2] L workstation[1] ws[..] 3. SCI LAN Topologies In traditional LANs, there is a development away from bus-based topologies as used in e.g. IEEE 802.3 (CSMA/CD LAN). New infrastructure in office buildings are based on structured cabling systems using a star topology with twisted pair or fiber optical cabling for point-to-point connections between central hubs and the distributed workstations. Even Ethernet is now preferred as a point to point link, avoiding the inherent bottleneck of shared media. Physical star topologies (as with structured cabling systems) easily allows logical ring topologies. Ring based topologies have a number of benefits and are often a good compromise between throughput, latency and reliability. A ring uses point-to-point connections and shares the transmission capacity on the ring. The ever-increasing demand for throughput, however, will in the long run force a development towards switched networks on the cost of switch-capable hubs. ws[N] Figure 5: SCI LAN star topology 3.3 SCI LAN hubs and backbone In figure 5, a mixed topology of interconnected hubs are presented. We assume no contention in the switches, and do not simulate the shaded part of the backbone network. Contention in the central switches will of course degrade overall throughput X and increase latency τ . We have chosen to consider tree topologies, a ring, a star using a central switch, and a mixed topology of hierarchically interconnected hubs. A hub is a component for transparently connecting two or more similar buses [HUB]. The hubs can be designed as e.g. rings or stars. 3.1 SCI LAN ring-based hub We use the ring topology in figure 1 as the starting point of our simulation, since this is the default SCI interconnection, and can be realized as a “patch-panel-hub” in a wire center. The new point in this simulation compared to other simulations of the SCI ring topology is again the focus on the transmission distance. We show how the performance metrics vary as a function of the workstation to hub cable length L. The SCI ring topology have been studied in a number of different simulations and have also been treated analytically [Scott92]. For small values of L, this experiment also serves as an informal verification of the simulation model. L2 L1 ws[N] HUB ws[..] ws[1] ws[N] HUB ws[1] ws[..] Figure 6: SCI LAN hubs and switched backbone 3 Initial studies of SCI LAN topologies for local area clustering 4. Results and Analysis We start with the two suggested implementations of a hub, a ring and a switched scheme, and discuss this for the random traffic and for the central server case. The mixed topology of interconnected hubs are then considered for the two traffic distributions random and central server case, respectively. 4.1 Ring and switch topology with random traffic Figure 7 shows the raw throughput X of the system versus the workstation to hub length L. When the traffic pattern in the systems is totally random, i.e. every node sends packets randomly to the other nodes with a uniform distribution, we can see that the system with 16 nodes connected by a switch has much higher throughput than the ring based topology as might have been expected. The results of the ring topology conform with analytical work and the simulations that has been performed by other simulators [Scott92, Bothner92]. The maximum throughput can not exceed approx. 1.5*125 Mbyte/s, i.e. 190 Mbyte/s for low values of L. It is also clear from the figure that even for a system with a Workstation to hub distance up to 1000 meters, the total raw throughput of the switch based system can still approach 150 Mbyte/s. The latency for the two cases (figure 8) shows an approximate linear increase for a switch based system, which can be interpreted by the physical line delay. Remember that in our model, the speed of the transmission is 20 cm/ns and a long distance will limit the system from saturation. The echo will have to travel long way back to acknowledge the success of sending, and then free the FIFO in the sender’s interface. The latency for the switch based system is only of tens of micro seconds. Figure 8: Average system latency versus WS to hub distance, random traffic We are not too surprised to see that even the switch based system will not have a high throughput in this configuration, the 220 Mbyte/s maximum in figure 9 is reasonable. The 90% of total traffic can not be taken by the server, 125 Mbyte/s is the peak throughput that can be consumed on this single link, while the rest 95 Mbyte/s is contributed by other links. The ring based system does not suffer very much from the client-server traffic pattern. The observed throughput reduction is due to the lower utilization of the ring after the server, because most of the packets are received by the server. This leads to a bottleneck on the input link of the server, while the output link has a very low utilization. Figure 7: Raw system throughput versus WS to hub distance, random traffic Figure 9: Raw system throughput versus WS to hub distance, 90% load on server 4.2 Ring and switch topology, central server case For the central server case, we suspect the input and output links of the server to be the bottleneck. We are interested to study how the ring based system and the switch based system can tolerate a traffic pattern where 90% of the total traffic is taken by the server, while the rest 10% is evenly distributed among the remaining 15 nodes (16 nodes together). 4 We are surprised to see the much longer latency for the switch based system in figure 10, while the ring based system enjoy the same order of latency as it has in random traffic. The explanation is that when a switch is used, each client send its packets to the server via the switch, the packets are buffered in Initial studies of SCI LAN topologies for local area clustering the queues of the switch and an echo will be returned immediately. This echo frees the client queue and results in a new packet being stored in the queue. However, the former packets that are stored in the switch queues can not be forwarded to the destination, because of the contention on the server. Thus, the new packets in the clients’ queues will get echo.busy all the time until the corresponding queue in the switch is freed (it will get through at last, a round robin scheme is used). So the reason of the high latency for the switch based system is due to our definition of latency as described in section 2.5 since busied packets in the switch are contributing to the latency, while busied packets in the CLAD’s do not contribute. We could achieve better throughput and latency if the central server was situated close to the switch. The link to the server would be a bottleneck anyway, but we would get faster access to the server. Figure 11: Raw system throughput versus distance between two switches Figure 10: Average system latency versus WS to hub distance, 90% load on server 4.3 Mixed topology of interconnected hubs It is likely that each hub-based system will be contained in a building, while remote sites will be connected using a bidirectional link. We discussed such a model in section 3.3. For the mixed topology, we compare two traffic scenarios as earlier: 1) random destination is selected, and 2) the traffic generated in each node consist of 90% traffic to a local server (local hub), and 10% traffic to a destination connected to the remote hub. In both cases, we choose the local hub to be switch-based. There is only one server in each local hub-based network and 15 clients. The workstation to hub distance is set to 10 meter. The throughput of the two scenarios compared in figure 11 shows that a system with the random traffic pattern has a very high throughput for short switch to switch distance L2, but this throughput decrease very fast with increasing L2. Figure 12 shows that a system with the random traffic pattern experience the highest latency. This is because the random traffic is random over all nodes in the system, which means that fifty percent of the traffic goes across the long distance connection, which makes the average latency larger than in the 90% local traffic case where most of the packets are sent to a local destination. Figure 12: Average system latency versus distance between two switches 5. Conclusion Generally, all topologies give poor performance when the workstation to hub distance L increases. This is due to a low link utilization when transmission distance increases. The throughput could be increased by means of larger FIFO buffers, but this will again increase latency. The detailed conclusions for the simulated topologies are given in the following sections. 5.1 Ring/switch based hubs, random traffic pattern With a workstation to hub distance of 1000 m, the switch-based hub throughput is more than 150 Mbyte/s with a latency of ~ 14 µs. In contrast, the ring-based hub give a very low throughput for this distance, but the mean latency experienced is still fairly low (~ 70 µs). 5 Initial studies of SCI LAN topologies for local area clustering A switch based hub gives much better throughput than a ring when the traffic is randomly distributed. For short workstation to hub distances, X is over 1.4 Gbyte/s while the ring based system cannot achieve more than 190 Mbyte/s. This is still a high total throughput for the 16 nodes in the system. 5.2 Ring/switch based hubs, central server case With a workstation to hub distance of 1000 m, the latency experienced is about 160 µs for the switch and about 70 µs for the ring case. Corresponding system throughput is 30 Mbyte/s and 10 Mbyte/s. This is much lower than in the random traffic case, but a central server case are thought to be a more realistic traffic scenario. Again, switch based hubs give the best throughput performance, but get a latency penalty because of server contention (see section 4.2 for discussion). For short workstation to hub distances, latency decrease to less than 30µs and throughput increase to more than 200 Mbyte/s and 130 Mbyte/s, for the switch and ring case, respectively. One solution to the bottleneck problem in the central server case, would be to distribute the server responsibility among the attached nodes. This way of sharing server responsibility would lead to a more even traffic pattern, and thus increase performance. 5.3 Mixed topology with interconnected hubs The analysis of the mixed topology with interconnected hubs leads to the following conclusions: Traffic must be kept as local as possible to utilize local troughput and avoid the bidirectional link interconnecting the hub-based local systems. A random traffic pattern leads to much traffic between the two hubs, and as L2 increase, both X and τ are strongly affected by the interconnection bottleneck. In the central server case, more traffic is local and the interconnection bottleneck is not as obvious as in the random traffic case. 5.4 General conclusion A general conclusion would be to keep L as low as possible in all topologies. In some cases, we would prefer rings to keep L short, but this can be in conflict with modern cabling principles (e.g. structured cabling are star-based) and as we have seen, switched hub solutions generally give us better throughput and latency. The simulated throughput and latencies in a distributed SCI interconnect using the candidate topologies show that a SCI LAN can be designed and high performance can be achieved. The main challenge is now to find a good architecture for cluster adapters to give applications in the end-systems access to this estimated interconnect performance. Acknowledgements We give special thanks to professor Stein Gjessing, University of Oslo, for comments on the paper. Both authors are supported by the Norwegian Research Council. 6 Terminology CSMA/CD Carrier Sense Multiple Access/Collision Detect FIFO A buffer implementing a First In, First Out queue. LACE Local Area Computing Environment LAN Local Area Network NodeChipTM SCI Interface Chip from Dolphin Interconnect Solutions (Dolphin ICS AS, Norway) SCI Scalable Coherent Interface TCP/IP Transport Control Protocol / Internet Protocol References [Bertsekas93] Bertsekas, D., Data Networks, 2nd edition, Prentice Hall, 1992, ISBN 0-13-201674-5, pp 373. [Bothner93] Bothner, J.W., Hulaas, T. I., Topologies for SCI-based systems with up to a few hundred nodes, Master Thesis, University of Oslo, Norway 1993. [Cheriton94] Cheriton, R., Kutter, R. A., Optimized Memory-Based Messaging: Leveraging the Memory System for High-Performance Communication, Technical Report, CS-TR-94-1506, Stanford University, 1994. [CLAD] SCI Cluster Adapter (a P1596 study-group activity), SCI 2-page summary from the hplsci.hpl.hp.com server, 21. april 1994. [Delp88] Delp, G., The Architecture and Implementation of Memnet: a High-Speed Shared-Memory Computer Communication Network. PhD thesis, University of Delaware, Department of Electrical Engineering, Newark, DE, 1988. [HUBS] Hubs: Collections of SCI Bridges (a P1596 study-group activity), SCI 2-page summary from the hplsci.hpl.hp.com server, 21. april 1994. [MODSIM] Modsim II Reference Manual, CACI Inc., USA, 1991. [Scott92] Scott, S.L., Goodman, J. R., Vernon, M. K: Performance of the SCI Ring, International symposium on Computer Architecture, May 1992. [Tanenbaum87]Tanenbaum, A., Operating Systems - Design and Implementation, Prentice Hall, 1987, ISBN 0-13-637331-3, pp. 51-70 [Wu94] Wu, B, Bogaerts, A, Kristiansen, E.H., Muller, H, Ernesto, P, Skaali, B, Applications of the Scalable Coherent Interface in Multistage Networks, to be appeared on IEEE TENCON’94, “Frontiers of Computer Technology”, Aug. 22-26, 1994, Singapore. (paper available on anonymous ftp server: fidibus.uio.no, under /incoming/SCI).