Notes on Multigrid Methods Qinghai Zhang September 30, 2013
advertisement

Notes on Multigrid Methods
Qinghai Zhang
September 30, 2013
Motivation of multigrids.
• The convergence rates of classical iterative method depend on the grid spacing, or problem size.
In contrast, convergence rates of multigrid methods does not.
• The complexity is O(n).
Book: Brigg, Henson, and McCormick 2000 A multigrid tutorial, SIAM, 2nd ed.
Encyclopedic website: www.mgnet.org
1
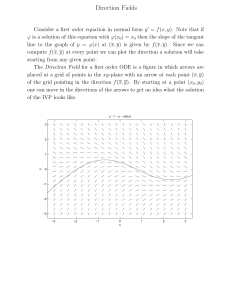
The model problem: 1D Possion equation.
On the unit 1D domain x ∈ [0, 1], we numerically solve Poisson equation with homogeneous boundary
condition
∆u = f,
x(0) = x(1) = 0.
(1)
Discretize the domain with n cells and locate the knowns fj and unknowns uj at nodes xj = j/n =
jh, j = 0, 1, . . . , n. We would like to approximate the second derivative of u using the discrete values
at the nodes. Using Taylor expansion, we have
∂ 2 u uj+1 + uj−1 − 2uj
=
+ O(h2 ).
(2)
2
∂x jh
h2
Definition 1. The one-dimensional second-order discrete Laplacian is a Toeplitz matrix A ∈ R(n−1)×(n−1)
as
i=k
2,
−1, i − k = ±1
aij =
(3)
0,
otherwise
Then we are going to solve the linear system
Au = f ,
(4)
where fj = h2 f (xj ).
Proposition 2.
1
(Au)j − (∆u)|xj = O(h2 ),
∀j = 1, . . . , n − 1.
h2
Proposition 3. The eigenvalues λk and eigenvectors wk of A are
λk (A) = 4 sin2
wk,j = sin
where j, k = 1, 2, . . . , n − 1.
1
kπ
,
2n
jkπ
,
n
(5)
(6)
(7)
Proof. use the trigonmetric identity
sin α + sin β = 2 sin
α+β
α−β
cos
.
2
2
(8)
Remark 1. The 2D counterpart of A is A ⊗ I + I ⊗ A.
Note that this is not true for variable coefficient Poisson equation.
2
The residual equation
Definition 4. For an approximate solution ũj ≈ uj , the error is e = u − ũ, the residual is r = f − Aũ.
Then
Ae = r
(9)
holds and it is called the residual equation.
As one advantage, the residual equation lets us focus on homogenuous Dirichlet condition WLOG.
Question 1. For inexact arithmetic, does a small residual imply a small error?
Definition 5. The condition number of a matrix A is cond(A) = kAk2 kA−1 k2 . It indicates how well
the residual measures the error.
kAxk2
kAk2 = sup
= sup
x6=0 kxk2
x6=0
s
(Ax, Ax)
= sup
(x, x)
x6=0
s
(x, AT Ax)
=
(x, x)
q
λmax (AT A)
(10)
Since A is symmetric, kAk2 = λmax (A). kA−1 k2 = λmax (A−1 ) = λ−1
min (A). To give you an idea about
the magnitude of cond(A), for n = 8, cond(A)=32, for n = 1024, cond(A)=4.3e+5.
Theorem 6.
1
krk2
kek2
krk2
≤
≤ cond(A)
cond(A) kf k2
kuk2
kf k2
(11)
Proof. Use kAxk ≤ kAkkxk and the equations Ae = r, A−1 f = u.
3
Fourier modes and aliasing
Hereafter Ωh denote both the uniform grid with n intervals and the corresponding vector space.
Wavelength refers to the distance of one sinusoidal period.
Proposition 7. The kth Fourier mode wk,j = sin(xj kπ) has wavelength Lw = k2 .
Proof. sin(xj kπ) = sin(xj +
L
2 )kπ
implies xj kπ = (xj +
L
2 )kπ
− π. Hence k =
2
Lw .
The wavenumber k is the number of crests and troughs in the unit domain.
Question 2. What is the range of representable wavenumbers on Ωh ?
For n = 8, consider k = 1, 2, 8. krep ∈ [1, n). What happens to modes of k > n? E.g. the mode
with k = 3n/2 is represented by k = n/2. Plot the case of n = 4.
Proposition 8. On Ωh , a Fourier mode wk = sin(xj kπ) with n < k < 2n is actually represented as
the mode wk0 where k 0 = 2n − k.
Proof. − sin(xj kπ) = sin(2jπ − xj kπ) = sin(xj (2n − k)π) = sin(xj k 0 π) = wk0 .
Definition 9. On Ωh , the Fourier modes with wavenumbers k ∈ [1, n/2) are called low-frenquency
(LF) or smooth modes, those with k ∈ [n/2, n − 1) high-frenquency (HF) or oscillatory modes.
2
4
The spectral property of weighted Jacobi
The scalar fixed-point iteration converts the problem of finding a root of f (x) = 0 to the problem of
finding a fixed point of g(x) = x where f (x) = c(g(x) − x) c 6= 0.
Classical iterative methods split A as A = M − N and convert (4) to a fixed point (FP) problem
u = M −1 N u + M −1 f . Let T = M −1 N , c = M −1 f . Then fixed point iteration yields
u(`+1) = T u(`) + c.
(12)
e(`) = T ` e(0) .
(13)
After ` iterations
Obviously, the FP iteration will converge iff ρ(T ) = |λ(T )|max < 1.
Decompose A as A = D + L + U . Jacobi iteration has M = D, N = −(L + U ), T = −D−1 (L + U ),
i.e.
1
2 , i − j = ±1
(14)
tij =
0, otherwise
Here ρ(T ) = 1 − O(h2 ). As h → 0, ρ(T ) → 1, and Jacobi converges slowly.
Consider a generalization of the Jacobi iteration.
Definition 10. The weighted Jacobi is given by the following.
u∗ = −D−1 (L + U )u(`) + D−1 f,
u(`+1) = (1 − ω)u(`) + ωu∗ ,
(15)
(16)
Setting ω = 1 yields Jacobi.
Proposition 11. The weighted Jacobi has the iteration matrix
Tω = (1 − ω)I − ωD−1 (L + U ) = I −
ω
A,
2
(17)
whose eigenvectors are the same as those of A, with the corresponding eigenvalues as
λk (Tω ) = 1 − 2ω sin2
kπ
,
2n
(18)
where k = 1, 2, . . . , n − 1.
See Fig. 2.7. For n = 64, ω ∈ [0, 1], ρ(Tω ) ≥ 0.9986. Not a great iteration method either.
Why? P
Look more under the hood to consider how weighted Jacobi damps different modes. Write
e(0) = k ck wk , then
X
e(`) = Tω` e(0) =
ck λ`k (Tω )wk .
(19)
k
No value of ω will reduce the smooth components of the error effectively.
λ1 (Tω ) = 1 − 2ω sin2
ωπ 2 h2
π
≈1−
.
2n
2
(20)
Having accepted that no value of ω damps the smooth components satisfactorily, we ask what value
of ω provides the best damping of the oscillatory modes.
Definition 12. The smoothing factor µ is the smallest factor by which the HF modes are damped per
iteration. An iterative method is said to have the smoothing property if µ is small and independent of
the grid size.
3
For weighted Jacobi, this leads to an optimization problem
µ=
min
k∈[n/2,n)
λk (Tω ),
for ω ∈ (0, 1].
(21)
λk (Tω ) is a monotonically decreasing function, and the minimum is therefore obtained by setting
λn/2 (Tω ) = −λn (Tω ) ⇒ ω =
2
.
3
(22)
Exercise:
2
1
⇒ |λk | ≤ µ =
(23)
3
3
See Figure 2.8 and 2.9. Regular Jacobi is only good for modes 16 ≤ k ≤ 48. For ω = 23 , the modes
16 ≤ k < 64 are all damped out quickly.
ω=
5
Two-grid correction
Proposition 13. The kth mode on Ωh becomes the kth mode on Ω2h :
h
2h
wk,2j
= wk,j
.
(24)
However, the LF modes k ∈ [ n4 , n2 ) of Ωh will become HF modes on Ω2h .
Proof.
h
wk,2j
= sin
2jkπ
jkπ
2h
= sin
= wk,j
,
n
n/2
(25)
where k ∈ [1, n/2). Because of the smaller range of k on Ω2h , the mode with k ∈ [ n4 , n2 ) are HF by
definition since the highest wavenumber is n2 on Ω2h .
Definition 14. The restriction operator Ih2h : Rn−1 → Rn/2−1 maps a vector on the fine grid Ωh to
its counterpart on the coarse grid Ω2h :
Ih2h v h = v 2h .
(26)
A common restriction operator is the full-weighting operator
vj2h =
1 h
h
h
(v
+ 2v2j
+ v2j+1
),
4 2j−1
(27)
where j = 1, 2, . . . , n2 − 1.
h
Definition 15. The prolongation or interpolation operator I2h
: Rn/2−1 → Rn−1 maps a vector on
2h
h
the coarse grid Ω to its counterpart on the fine grid Ω :
h 2h
I2h
v = vh .
(28)
A common prolongation is the linear interpolation operator
h
v2j
h
v2j+1
= vj2h ,
2h
).
= 21 (vj2h + vj+1
(29)
The key idea is that the weighted Jacobi with ω = 32 damps HF modes effectively, we can exploit
this on a series of successively coarsened grides to eliminite HF modes.
Definition 16. For Au = f , the two grid correction scheme
v h ← MG(v h , f h , ν1 , ν2 )
consists of the following steps:
4
(30)
1) Relax Ah uh = f h ν1 times on Ωh with initial guess v h : v h ← Tων1 v h + c0 (f ),
2) compute the fine-grid residual rh = f h − Ah v h and restrict it to the coarse grid by r2h = Ih2h rh :
r2h ← Ih2h (f h − Ah v h ),
3) solve A2h e2h = r2h on Ω2h : e2h ← (A2h )−1 r2h ,
h 2h
4) interpolate the coarse-grid error to the fine grid by eh = I2h
e and correct the fine-grid approxih
h
h 2h
mation: v ← v + I2h e ,
5) Relax Ah uh = f h ν2 times on Ωh with initial guess v h : v h ← Tων1 v h + c0 (f ).
Proposition 17. Let T G denote the iteration matrix of the two-grid correction scheme. Then
h
T G = Tων2 I − I2h
(A2h )−1 Ih2h Ah Tων1 .
(31)
Proof. By definition, the two-grid correction scheme replaces the initial guess with
h
(A2h )−1 Ih2h f h − Ah (Tων1 v h + c0 (f )) ,
v h ← Tων1 v h + c0 (f ) + I2h
(32)
which also holds for the exact solution uh . Subtracting the two equations yields (31).
5.1
The spectral picture
Our objective is to show that T G ≈ 0.1 for ν1 = 2, ν2 = 0. For this purpose, we need to examine the
intergrid transfer operators.
Definition 18. wkh (k ∈ [1, n/2)) and wkh0 (k 0 = n − k) are called complementary modes on Ωh .
Proposition 19. For a pair of complementary modes on Ωh , we have
Proof. wkh0 ,j = sin (n−k)jπ
n
h
wkh0 ,j = (−1)j+1 wk,j
h
= sin jπ − kjπ
= (−1)j+1 wk,j
.
n
(33)
Lemma 20. The action of the full-weighting operator on a pair of complementary modes is
Ih2h wkh = cos2
kπ 2h
w = ck wk2h ,
2n k
kπ 2h
w = −sk wk2h ,
2n k
h
where k ∈ [1, n/2), k 0 = n − k. In addition, Ih2h wn/2
= 0.
Ih2h wkh0 = − sin2
(34a)
(34b)
Proof. For the smooth mode,
Ih2h wkh =
1
(j − 1)kπ 1
jkπ 1
(j + 1)kπ
1
kπ
jkπ
kπ 2h
sin
+ sin
+ sin
= (1 + cos
) sin
= cos2
w ,
4
n
2
n
4
n
2
n
n
2n k
where the last step uses Proposition 14. As for the HF mode, follow the same procedure, but replace
k with n − k, use Proposition 9 for aliasing, and notice that j is even.
The full-weighting operator thus maps a pair of complementary modes to a multiple of the smooth
mode, which might be a HF mode on the coarse grid.
Lemma 21. The action of the interpolation operator on Ω2h is
h
I2h
wk2h = ck wkh − sk wkh0 ,
where k 0 = n − k.
5
(35)
Proof. Proposition 20 and trignometric identities yield
kπ
kπ
wkh ,
j is even,
ck wkh − sk wkh0 = cos2
+ (−1)j sin2
wkh =
h
w
,
j is odd.
cos kπ
2n
2n
k
n
On the other hand, by Definition 16, we have
(
h
I2h
wk2h j ==
kπ(j−1)/2
1
+
2 sin
n/2
1
2
wkh ,
j is even,
kπ h
sin kπ(j+1)/2
=
cos
w
,
j is odd.
k
n/2
n
Hence, the range of the interpolation operator contains both smooth and oscillatory modes. In
other words, it excites oscillatory modes on the fine grid. However, if k n, the amplitudes of these
2
HF modes sk ∼ O( nk 2 ).
Theorem 22. The two-grid correction operator is invariant on the subspaces Wkh = span{wkh , wkh0 }.
T Gwk = λνk1 +ν2 sk wk + λkν1 λνk20 sk wk0
(36a)
T Gwk0 = λνk10 λνk2 ck wk + λνk10 +ν2 ck wk0 ,
(36b)
where λk is the eigenvalue of Tω .
Proof. Consider first the case of ν1 = ν2 = 0.
Ah wkh = 4sk wkh
⇒Ih2h Ah wkh
=
(37a)
16ck sk wk2h
⇒(A2h )−1 Ih2h Ah wkh =
(37b)
16ck sk
wk2h = wk2h
kπ
4 sin2 n/2
(37c)
h
⇒ − I2h
(A2h )−1 Ih2h Ah wkh = −ck wkh + sk wkh0
h
⇒ I − I2h
(A2h )−1 Ih2h Ah wkh = sk wkh + sk wkh0 ,
(37d)
(37e)
where the additional factor of 4 in (37b) comes from the fact that the residual is scaled by h2 and the
trigonmetric identity sin(2θ) = 2 sin θ cos θ is applied in (37c). Similarly,
Ah wkh0 = 4sk0 wkh0 = 4ck wkh0
⇒Ih2h Ah wkh0
=
(38a)
−16ck sk wk2h
⇒(A2h )−1 Ih2h Ah wkh0
(38b)
16ck sk
wk2h = −wk2h
=−
kπ
4 sin2 n/2
(38c)
h
⇒ − I2h
(A2h )−1 Ih2h Ah wkh0 = ck wkh − sk wkh0
h
⇒ I − I2h
(A2h )−1 Ih2h Ah wkh0 = ck wkh + ck wkh0 .
(38d)
(38e)
Note that in the first equation we have used ck = sk0 .
Adding pre-smoothing incurs a scaling of λνk1 for (37e) and λνk10 for (38e). In contrast, adding postsmoothing incurs a scaling of λνk2 for wkh and a scaling of λkν20 for wkh0 in both (37e) and (38e). Hence
(36) holds.
(36) can be rewritten as
ν1 +ν2
wk
λ
s
TG
= kν1 ν2 k
wk 0
λk0 λk ck
For k n, although λνk1 +ν2 ≈ 1, sk ∼
Figure 1 for four examples.
λkν1 λνk20 sk
λkν10 +ν2 ck
k2
n2 ,
wk
c
= 1
wk0
c3
c2
c4
wk
.
wk 0
(39)
hence c1 1. Also, λνk10 1, hence c2 , c3 , c4 1. See
6
1
1
c1
c2
c3
c4
0.9
c1
c2
c3
c4
0.9
0.8
0.8
0.7
0.7
0.6
0.6
0.5
0.5
0.4
0.4
0.3
0.3
0.2
0.2
0.1
0.1
0
0
0
10
20
30
40
50
60
70
0
10
20
(a) ν1 = 0, ν2 = 0
30
40
50
60
70
(b) ν1 = 0, ν2 = 2
0.12
0.35
c1
c2
c3
c4
c1
c2
c3
c4
0.3
0.1
0.25
0.2
0.08
0.15
0.06
0.1
0.05
0.04
0
−0.05
0.02
−0.1
0
−0.15
0
10
20
30
40
50
60
0
70
10
20
(c) ν1 = 1, ν2 = 1
30
40
50
60
70
(d) ν1 = 2, ν2 = 0
0.12
0.07
c1
c2
c3
c4
c1
c2
c3
c4
0.06
0.1
0.05
0.08
0.04
0.06
0.03
0.04
0.02
0.02
0.01
0
0
0
10
20
30
40
50
60
70
0
(e) ν1 = 2, ν2 = 2
10
20
30
40
50
60
70
(f) ν1 = 4, ν2 = 0
Figure 1: The damping coefficients of two-grid correction with weighted Jacobi for n = 64. The x-axis
is k.
7
5.2
The algebraic picture
Lemma 23. The full-weighting operator and the linear-interpolation operator satisfy the variational
properties
h
I2h
= c(Ih2h )T , c ∈ R.
(40a)
h
Ih2h Ah I2h
= A2h .
(40b)
(40b) is also called the Galerkin condition.
h
Proposition 24. A basis for the range of the interpolation operator R(I2h
) is given by its columns,
n
h
h
hence dim R(I2h ) = 2 − 1. N (I2h ) = {0}.
h
h 2h
h
Proof. R(I2h
) = {I2h
v P : v 2h ∈ Ω2h }. The maximum dimension of R(I2h
) is thus n2 − 1. Any v 2h can
2h
2h 2h
h
be expressed as v = vj ej . It is obvious that the columns of I2h are linearly-independent.
Corollary 25. For the full-weighting operator,
dim R(Ih2h ) =
n
− 1,
2
dim N (Ih2h ) =
n
.
2
(41)
Proof. The fundamental theorem of linear algebra states that for a matrix A : Rm → Rn ,
Rm = R(A) ⊕ N (AT ),
n
T
R = R(A ) ⊕ N (A),
(42)
(43)
where R(A) ⊥ N (AT ) and R(AT ) ⊥ N (A). If A has rank r, from the singular value decomposition
A = U ΣV T , we have
R(A) = span{U1 , U2 , . . . , Ur },
(44)
N (A) = span{Vn−r+1 , Vn−r+2 , . . . , Vn },
(45)
T
(46)
T
(47)
R(A ) = span{V1 , V2 , . . . , Vr },
N (A ) = span{Um−r+1 , Vm−r+2 , . . . , Vm }.
See Figure 5.7 on page 85. The rest of the proof follows from (40).
Proposition 26. A basis for the null space of the full-weighting operator is given by
N (Ih2h ) = span{Ah ehj : j is odd},
(48)
where ehj is the jth unit vector on Ωh .
Proof. Consider Ih2h Ah . The jth row of Ih2h has 2(j − 1) leading zeros and the next three nonzero
entries are 1/4, 1/2, 1/4. Since Ah has bandwidth
of 3, it suffices to only consider three columns of Ah
P 2h
for potentially non-zero inner-product j (Ih )ij (Ah )jk . For 2j ± 1, these inner products are zero, for
2j, the inner product is −1/2.
The basis vector of N (Ih2h ) are thus of the form
(0, 0, . . . , −1, 2, −1, . . . , 0, 0)T .
Hence N (Ih2h ) consists of both smooth and oscillatory modes.
Theorem 27. The null space of the two-grid correction operator is the range of interpolation:
h
N (T G) = R(I2h
).
8
(49)
h
h 2h
Proof. If sh ∈ R(I2h
), then sh = I2h
q .
h 2h
h
T Gsh = I − I2h
(A2h )−1 Ih2h Ah I2h
q = 0,
where the last step comes from
(40b).
h T
Consider th ∈ N (I2h
) = N (Ih2h ). By Proposition 27, th ∈ N (Ih2h Ah ). Hence
h
T Gth = I − I2h
(A2h )−1 Ih2h Ah th = I,
h
i.e., TG is the identity operator when acting on N (Ih2h ). This implies that dimN (T G) ≤ dimR(I2h
),
which completes the proof.
Now that we have both the spectral decomposition Ωh = L ⊕ H and the subspace decomposition
h
h
Ω = R(I2h
) ⊕ N (I2h
), the combination of relaxation with TG correction is equivalent to projecting
the initial error vector to the L axis and then to the N axis. Repeating this process reduces the error
vector to the origin; see Figure 5.8-Figure 5.11 for an illustration.
h
6
Multigrid cycles
Definition 28. The V-cycle scheme is an algorithm
vh ← V h (vh , f h , ν1 , ν2 )
(50)
with the following steps.
1) relax ν1 times on Ah uh = f h with a given initial guess vh ,
2) if Ωh is the coarsest grid, go to step 4), otherwise
f 2h ← Ih2h (f h − Avh ),
v2h ← 0,
v2h ← V h (v2h , f 2h ).
h 2h
3) interpolate error back and correct the solution: vh ← vh + I2h
v .
4) relax ν2 times on Ah uh = f h with the initial guess vh .
Definition 29. The Full Multigrid V-cycle is an algorithm
vh ← F M Gh (f h , ν1 , ν2 )
(51)
with the following steps.
1) If Ωh is the coarsest grid, set vh ← 0 and go to step 3), otherwise
f 2h ← Ih2h f h ,
v2h ← F M G2h (f 2h , ν1 , ν2 ).
h 2h
2) correct vh ← I2h
v ,
3) perform a V-cycle with initial guess vh : vh ← V h (vh , f h , ν1 , ν2 ).
See Figure 3.6 for the above two methods. Note that in Figure 3.6(c) the initial descending to the
coarsest grid is missing.
9