for Causal and Acausal Systems*
advertisement

LIDS- P 2027
March, 1991
Research Supported By:
AFOSR grant 88-0032
ARO contract DAAL03-86-K-0171
ONR grant N00014-9 1-J-1004
Parallel Smoothing Algorithms for Causal and Acausal Systems*
Taylor, D.
Willsky, A.S.
LIDS-P-2027
Parallel Smoothing Algorithms for Causal and
Acausal Systemsi
Darrin Taylor and Alan S. Willsky
Abstract
In this paper we describe parallel processing algorithms for optimal smoothing for
discrete time linear systems described by two point boundary value difference equations. These algorithms involve the partitioning of the data interval with one processor for each subinterval. The processing structures considered consists of independent
parallel processing on each subinterval, followed by an information exchange between
processors and then a final sweep of independent subinterval processing. The local processing procedures that we describe produce maximum likelihood (ML) estimates in
which dynamics and a priori conditions play the same role as measurements, i.e. they
are all noisy constraints. Consideration of such ML procedures for descriptor systems
requires that we develop a general procedure for recursive estimation in situations in
which neither the error covariance nor its inverse is well defined. This leads among
other things to a generalization of the well known Mayne-Fraser two filter algorithm in
which the two directions of processing are treated symmetrically,. Furthermore using
an ML procedure for the local processing step leads to considerable simplification of
the subsequent interprocessor information exchange step. We present both a two filter
implementation of this step as well as a highly parallel implementation exactly matched
to the hypercube computer architecture. This algorithm by itself yields a newr parallel
smoothing algorithm and also, significantly, is extendible to higher dimension- offering
the promise of even more significant computational savings for applications involving
the estimation of random fields.
!,.
uail Ih ,rs : I,,
w iti,'
Inflorimatlioll all I),-ciSio S
l),1
,, ,
1) l', rl',ri':l
-;
, irt, '., ri,: -r,I.g,( 'II ,I)ItrS ,i' .,,,.1
1,
1
,,.,III
yMtiTs. Il! ( 'alibridg'. NI.A 21'9. 'I Iis work was silpport,,ld iln
lo(rce ()Olicci(o( ScicIIti li lccsarchIt tider ( r:al, I\ l1()SH1-Ss-o0(32. aIid in pr;ll I., lite I S Army
nii(ler ('onltraet I)!\A I,(:{-;-I%- - 0ll.7, auid by Ilie ()Olice ot NavalI tiesearchl
mitner (4,rati N0
I b,i .. r: l I;,r
parl Iy Ihei \il
{ls .arl h( )Ilic(,,
)!1.I-!I-.1--l- I).I.
2
1
Introduction
In this paper we describe algorithms for parallel optimal smoothing for systems described
by two point boundary value descriptor systems (TPBVDS's), a class that includes btoth the
standard causal model as well as a rich class of acausal models. There are several reasons for
interest in parallel smoothing algorithms. First, the processing environment has changed
substantially over the years to allow for multiprocessor computational enviromnents. The
popular recursive estimation algorithms which were developed based on the Kalman filter,
were designed to function in a single processor environment. In addition estimation of multidimensional processes nearly necessitates a multiprocessor environment. Specifically, while
the boundary of a one dimensional process does not increase when the interval of consideration increases, a two dimensional system has a boundary that grows at a rate no smaller
than the square root of the size of the region being considered. This is significant since the
size of the boundary gives an indication of the complexity of the system. In particular, if
we think of the dimension of the 'state' of a system as both a measure of the complexity of
the system (e.g. in terms of required storage), and as a set of required boundary conditions
needed for further computation, we see that there is a dramatic difference between the l-D
and the 2-D cases. Thus, for large regions partitioning the data and processing it separately
makes sense in order to reduce the complexity of the entire algorithm. This not only yields
timne savings, in 1-D as well as in 2D, but also may be essential ill 2-D in order to keep the
computational burden on individual processors within reason.
Althcug!, ,.his paper considers cnlr thbe one dimensional problem, multidimensional estimation considerations are a guide to judge which approaches to consider for parallel estimation. In particular we wish to develop algorithms motivated by and (hopefully) generalizable
to higher dimensions and which demonstrate the promise of efficient multidimensional estimation algorithms. Also, another criteria by which to guide us in consideration of parallel
estimation algorithms is the notion of fault tolerance. In the event that a processor fails, do
the remaining processors produce useful information? It is not enough to take an algorithm
and parallelize it. It is important that the local processing involves computing meaningful
information so that alternate strategies can be employed to recover useful information in
the event of processor or communication failure. In particular we seek algorithms in which
each processing step has a precise interpretation as producing an optimal estimate in some
sense. Furthermore, we also wish to obtain algorithms that are capable of providing estimation error covariances. Such information not only allows performance assessment but
also is essential for fault tolerant operation in which the absence of one or more information
source must be accounted for in a statistically optimal fashion.
The two parallel estimation algorithms described here have common characteristics.
First, the data is partitioned among the processors. Local calculations are performed by
processors on their own sets of data. Local information is then exchanged between processors
and this is followed by a parallel post processing step in which each processor updates
the estimates on its subinterval to produce the final globally optimal estimate over thle
entire data interval. While a variety of approaches have been developed for various optimnal
estimation problems [1-7], only two of these [6,7] employ a similar data partitioning structure
for parallel filtering and smoothing for causal systems. In [6] a square root algorithm is
used for parallel filtering on the subintervals assuming perfect knowledge of the state at
3
one endpoint. This is followed by an interprocessor information exchange and computation
step. This step which is based on a change of initial condition formula in order to correct
for imperfect endpoint knowledge, is similar in structure to the Mayne-Fraser two filter
smoother in orde:' to obtain optimal smoothed estimates at the boundaries of the data
intervals and to allow subsequent parallel computation of smoothed estimates within each
subinterval. A somewhat more efficient algorithm, with a similar structure, is described
in [7]. This procedure deals symmetrically with the two endpoints of each subinterval by
initially processing data outward toward and in the final step inward from the boundary
points (essentially using in each interval a joint model for x(t) and x(-t), with t = 0
corresponding to the center of the interval). The interprocessor exchange steps makes use
of the so called partition theorem [10], resulting again in a two-filter sweep from processor
to processor in both directions to produce optimal estimates at all boundary points.
The algorithms we describe here bear some similarity to these approaches (in particular,
and as we have indicated, they also use the same data partitioning and three step structure),
but they also have some significant differences. First of all we deal here with the more general
class of TPBVDS's. Also at each stage of our processing we compute maximum likelihood
(ML) estimates based on the available information. Here as in [12], we essentially adopt the
perspective that a priori statistics, dynamical relationships, and actual observations all play
the same role, namely as noisy constraints. The use of this formalism has several important
implications, perhaps most notably in the simplification and greatly enhanced flexibility it
provides us in the interprocessor exchange step. However, let us first conmment on some of
the implications for the local procetaineg step.
Specifically as discussed in [11] we can without any loss of generality restrict our attention to so called separable TPBVDS's (STPBVDS's) in which independent boundary
conditions are specified at two ends of the interval, say , t = +T. In particular, if we do not
have such separable conditions on x(t), we can obtain them by considering the evolution
of z(t) = [xT(t), T(--t)lT, so that the original boundary condition is now a condition on
z(t), and we acquire a separate condition on z(0), namely that its two components must
be exactly equal. Obviously this construction points to a connection with the model in [7].
Note also that as is clear from this construction and as must be true for any well posed
TPBVDS, only partial boundary conditions are available at each end. Viewing these as
initial measurements for recursive ML estimation procedures starting at either end of the
data interval, we see that at least initially only incomplete information is available, which
would seem to imply that we should use the information form in any recursive procedure,
i.e to propagate P-', and P-'l. This could be carried out at least until P- 1 is invertible so
that P is well defined. However as discussed in [13], the consideration of descriptor dynamics with possibly singular dynamic matrices, also means that we may have some noiseless
constraints or as in the boundary constraints on the two components of z(O), implying that
p-l is not well defined either!
The preceding discussion makes clear that in considering recursive ML estimation for
TPBVDS's we must directly confront the problem of estimation in the face of degenieracy,
where the linear equations yielding the ML estimate need not have a unique solution (so t hat
at least some part of x(t) is unconstrained by available information) but may yield perfect
estimates of other parts of x(t). The generalized framework of such generalized estimation
in the static case is developed in [9] (see also [8]). In [12] the results of [9] are used to develop
4
recursive filtering procedures for TPBVDS in the case when all variables are estimable, (so
that P is well defined). What we describe in the next section are algorithmns for optimal
STPBVDS smoothing in the general case. In particular we describe generalizations of
the well known Mayne-Fraser and Rauch-Tung-Striebel algorithmts and in fact provide a
completely symmetric version of the first of these in which each of the two filters is initialized
with the independent boundary information available to it. The algorithms described in
Section 2, in addition to being of interest in their own right, also provide us with the first
and third local processing steps for our data partitioned parallel processing procedure. Two
new algorithms for the second, interprocessor data step are described in Section 3. As in
[6,7], we can view the output of the first step as producing 'measurements' of x(t) at the
boundaries. However in the Bayesian approaches of [6,7], the errors in these 'measurements'
are correlated since each local processor makes use of common prior information. This leads
to the comparatively involved two filter procedure in [6,7] for exchanging and fusing endpoint
information among processors. In contrast, by adopting the ML formalism we guarantee
that the result of out first local processing step produces independent 'measurements' of
boundary points. This leads to an algorithm, similar in structure but far simpler than the
approach in [7],or[6].
However, it is the second algorithmic structure described in Section 3 that we feel is
most novel and noteworthy. First of all, unlike the data exchange steps in [6,7] and our
first algorithm, the data exchange structure of our second algorithm is itself highly parallel
in nature and is in fact perfectly matched to the hypercube architecture. Secondly this
ran bc applied to the original discrete data without 3c*t'
processing steps befort
and after it, yielding by itself a new highly parallel smoothing algorithm matched to a
very different computer architecture than that in [6,7] Finally, the basic structure of this
algorithm can be extended to multiple dimensions, offering the promise of achieving the
needed efficiencies mentioned previously. We comment on this a bit more as we conclude
the paper in Section 4.
^.l~r:hhtc.
2
2.1
Maximum Likelihood Recursive Estimation for TPBVDS's
Maximum Likelihood Estimation
In this section we describe algorithms for recursive filtering and smoothing for TPBVDS's
As we indicated in the introduction, we adopt an ML perspective in part with an eye
toward the parallel processing procedures of Section 3 and in part because such a formalism
is particularly natural for descriptor systems in which the dynamics are more appropriately
thought of as constraints rather than the basis of recursion. Also, as we have indicated,
the problems of interest to us require that we examine, situations in which neither the
estimation error covariance nor its inverse are well defined. To this end, let us begin with a
brief look at a static ML estimation problem. Specifically consider the problem of estimlatiing
an unknown vector x based on the observations
y = He + v
(I)
where v is a zero mean Gaussian random variable, with possibly singular covariance R,
and where H need not have full columnm rank, so that some part of x may be perfectly
5
reconstructed while another part remains completely unknown.
optimal estimate
;ML
What we mean by an
in this case is a linear function of y so that if cTx is estimable ( i.e
if a finite variance estimate of it can be constructed), then cT;iML is a mlinimum variance
estimate of cTx. Note that in general iML is not unique, as no constraint is placed on the
non-estimable portion of x. The solution we choose is the minimum norm solution given by
;rML =
0
Y
R H
]
[HT
I |
(2)
[ °
where # denotes the Moore-Penrose pseudoinverse. As developed thoroughly in [9], (see
also [12]) other generalized inverses can be used to obtain other valid choices for the ML
estimate. However, this is the one we require for purposes we now outline, without proof
(see [13] for details)
Note that the range space of the symmetric projection matrix
P, = (HTH)#(HTH)
determines the estimable subspace of x. Then P:x~ML =
COV(PX - XML)= [
'0T
R
HT
H
(3)
XML and furthermore
]0 1
0
(4)
Note also that
P,Cov(Px - XML)P,
= Cov(Pzx - XML)
(5)
Furthermore the following properties of ;ML are critical in deriving the recursive structure
described later in this section:
a) Consider the problem of ML estimation of x and z based on the data in (3) together
with the measurements
w = Gz + Jz + u
(6)
where u is a zero mean random vector uncorrelated with v . Then the optimal ML estimate
for this problem is the same as that based on (6) and the observation
iML = PZx +
±ML
(7)
where :ML is a zero mean Gaussian random vector independent of u with covariance given
by (4)
b) Suppose that
= Ax
(s)
The ML estimate of z based on (3) is given by
ZML = PzA.IML
(9)
Cov(PWz - iML) = PZA Cov(Pz - iML)ATP,
(10)
6
where Pz is the largest rank symmetric projection matrix such that
PzA(I - P,) = 0
(11)
Pz = I - (A(I - P?)AT)#(A(I - P.)AT)
(12)
and is given by the following
Note that one implication of (a) is that we can use our formalism for the recursive
incorporation of information (so if in particular J = 0 in (6), and x is estimable based
on (3), and (6), this procedure yields the unique optimal estimate of all of z). Also if A is
invertible in (8), then P, has the same rank as P,. However, if A is singular, it is possible
that P, will have larger rank because A may kill some of the non-estimable portions of x.
2.2
Two Point Boundary Value Descriptor Systems
A general TPBVDS has the following form:
E(t + l)x(t + 1) = A(t)x(t) + Btu(t) -T < t < T - 1
y(t) = C(t)x(t) + v(t)
-T < t < T
E(-T)x(-T) = A(T)x(T) + BTu(T)
(13)
(14)
(15)
where [uT(t), vT(t)]T] is a whii,; noise process with
Co
c[
u(t)
v(t)
I
0
(16)
[ 0 R(t + 1)
Note that written in this form, we have made little distinction between the boundary condition (15) on the process and the dynamics (13). We assume for simplicity, that the
system (13), (15) is well-posed, i.e. that (13), (15) admits a unique solution for any choice
of u(t), although, as in [12], the results here can be extend to a more general setting in
which (13), (15) simply provide either an over- or under-constrained set of noisy constraints
(and where, in fact x(t) may vary in dimension).
In general the boundary conditions (15) couple the values of x(t) at the two endpoints
t = ±T. An important subclass of TPBVDS's are those that are separable in which (15)
specifies independent constraints of x(-T) and x(T). (In the well-posed case (15) is a set
of constraints of dimension equal to that of x(t), so that in the separable case (15) provides
incomplete constraints of at least one of the two boundary points). As shown in [11] it is
always possible to transform a TPBVDS to one that is separable by considering the joint
evolution of x(t) and x(-t):
0 E(-tt)
,
[
E(t + 1)
0
10
Af-to 1)
(-t)
0
1 [
-B-t-1
O
(t + 1)
X- t- 1)
11
(17)
- 1)
7
-][
[I
(-0) =o0
(19)
(20)
[ -A(T)ET)] [ (-TT(T) ]=BTu(T)
y(t)
C(t)
0
y(-t)
(t)
C(-t)
t)(21)
[ x(-t)
[ r(-t)
21
where (17)is defined for 0 < t < T-1, (21)for 0 < t < T, and the boundary conditions (19)
and (20) are indeed separable. Note that (17), (19),and (20) represent the original system
starting from the center, then moving outward. Thus any smoothing algorithm based on
this model will involve processing outward toward and inward from the boundaries. Note
also that the boundary conditions (19),and (20) provide only partial information about
the states [xT(t), zT(-t)] at t = 0, and t = T and furthermore the boundary condition at
t = 0 provides perfect information about part of the state [XT(0), xT(_)].
To continue, let us revert to a simpler notation for a general STPBVDS:
E(t + 1)x(t + 1) = A(t)x(t) + Btu(t) 0 < t < T - 1
y(t) = C(t)x(t) + v(t)
0 <t <T
[ v(t +
Cov
)
=
(22)
(23)
0 Rt+l
(24)
Here, consistent with our ML perspective, we have incorporated the independent boundary
conditions on x(0) and x(T) into the measurements (23) at t = 0, and t = T. Viewing (22)
through (24) as providing a set of noisy constraints, we can apply the ML estimation results
of Subsection 2.1 to obtain recursive estimation algorithms. In presenting these algorithms
it is useful to define two auxiliary (forward and backward prediction) variables.
zf(t) = E(t)x(t)
zb(t) = A(t)ax(t)
(25)
(26)
Let XML[sO, t] denote the ML estimate of x(s) based on (22) for 0 < r < t - 1,and (23)
for 0 < r < t, and iMfL[S10, t] denote the ML estimate of z(s) based on (22) for 0 < r <
t,and (23) for 0 < T < t. We then obtain the following forward ML filter (FMLF) equations:
T
tlO
]
Ef[tl, t-
0
]
0
I Pzf (t)
ET(t)
0 -
I
ZML[tIOt
y(t)
0
I-Pzf(t)
E(t)
R(t)
0
C(t)
0
0
0
0
CT(t)
0
0
0
-1
(27)
where
[
]- T
-
[tl0o. t-1]
]
IL
II
0
R(t)
0
(I -
PZ(t))
ET(t)
o
(I-Pf(t))
0
E(t)
C(t)
0
0
0
IJ
0 o o
CT(t)
O
8
Pf(t) = (E T (t)Pf (t)E(t))#(ET(t)P, (t)E(t))
(29)
dM [t + 10, t] = Pf(t + 1)A(t)0ML[tlO , t]
Ef[t + 110, t] = Pf(t + 1)(A(t)UEf[tJO, t]AT(t) + B(t)BT(t))Pzf(t + 1)
T
(31)
T
Pz,(t + 1) = I - (A(t)(I - Pf(t))A (t))#(A(t)(I - PI(t))A (t))
(32)
where Pf (t) indicates the symmetric projection matrix which defines the estimable part of
x(t) based on data through time t, and Pf (t) is the symmetric projection matrix which
defines the estimable part of zf(t). Equations (27) through (31) represent the generalization
of [12] to allow for the possibility that z(t) and / or zf(t) are not completely estimable.
Also 4[tJ0, t] can be thought of as the error covariance in the estimate of iML[t1O, t] in the
sense of (4). U [tl0, t] represents the corresponding error covariance for the estimable part
of x(t) The matrix Ef [t + 110, t] has a similar interpretation for 4M[t
f
+ 110, t].
Similarly we can define the backward ML filter (BMLF) where XML[Slt, TJ denotes the
ML estimate of x(s) based on (22), for t < r < T and (23) for t < r < T, and ZbML[SIt, T]
denotes the ML estimate of zb(s) based on (22), for t-1 < r < T and (23) for t < r < T.The
BMLF is then given by
T
0
R(t)
I-Pb(t)
0
E
iL[tt,
ML[tl, =
vb[tlt + 1, T]
I0 0
0
A T(t)
~I
'-'ft
'
0o
-
0
I
]=
0
CT(t)
ML[tt + 1,T]
#
y(t)
0
o
0
O
O
(33)
Oi0b[tlt +
f [tt, T] =
I- Pb(t) A(t)
0
C(t)
1,T]
0
(I - Pzb(t))
AT(t)
0
(I - Pb(t)) A(t)
R(t)
0
0
CT(t)
0
0
C(t)
0
0
0
I
P?(t) = (A T (t)Pf(t)A(t))#(AT (t)Pf(t)A(t))
MbL[t-
lt, T]
(34)
(35)
= Pzb(t)E(t)iML[tIt, T]
,zb[tlt + 1, T] = Pb(t)(E(t + 1) [[t + lt + 1, T]E(t + 1)T + B(t)BT(t))Pb(t)(36)
Pzb(t + 1) = I - (E(t)(I - P.(t))E(t)T )#(E(t)(I - P,(t))E(t)T )
(37)
Also the FMLF and the BMLF can be combined to produce the optimal smoothed estimate using one of two forms. The first combines forward filtered with backward predicted
estimates, and the second combines forward predicted with backward filtered estimates.
iML[tIO,
E- [tJl, t]
0O
0
0
0
(38)
T] =
0
I -P(t)
0
I
iML[tIO, T]
I
0
zb[tt + 1, T]
0
I - Pb(t
AT(t)
I-
Pf (t)
0
0
0
0
0
I
I - Pb(t) A(t)
A(t)
0
0
0
0
0
0
#
AML[tO. t]
51L[tt --- i, T])
0
0
0
(39)
9
oT
-
0
o
,Zf[to0,t-1]
O
I- PIf(t)
I
-
I
P,(t) E(t)
O
O
I-Pb(t)
0
IO
0
0
I/ - Pb(t)
0
/
O
I
CSb[tlt,T]
ET(t)
MAL[tlt,T]
0
I-ML[t10, t-
1])
O
0
0
0
0
0
0
O
O
The smoothed error covariances are given by the following
0
-
-
T
0
uE[t0, T] =
-
[tl, t]
0
0
O
P.(t)
o
o
Pzb(t)
I
I
AT(t)
o
o0
E,[tl0,T ] =
0
I
T
P,(t)
0
I
0
0
0
0
0
Pb(t)
0
0
0
A(t)
0
0
0
0
0
0
I
0
I
E(t)
~zb[tlt + 1, T]
0
vb[tit, T]
0
0
PT(t)
szf[tlo, t-1]
0
I
P,f(t)
ET(t)
0
P0(t)
_
0
0
o0
0
P, (t)
0
0
0
(40)
#
0
0
O
0
(41)
0
I
The FMLF and the BMLF together with either (38), or (39) form a generalization of the
Mayne-Fraser two filter formulas for optimal smoothing on STPBVDS's in the case where
x(t) may not be estimnabl:', while portions of it are specified perfectly. Specifically if E=I
and only initial conditioI.s are specified (making the system well posed), the FMLF and the
BMLF and (39) reduce to the usual Mayne-Fraser equations. As a result, the generalization
to STPBVDS deals in a symmIetric way with information available at the two ends of the
interval.
It is also possible to generalize the Rauch-Tung-Striebel algorithml to STPBVDS's. This
algorithm involves a forward sweep to compute xML[tO0, t] for each t producing the smoothed
estimate i,(T) = iML[TI0, T] at one endpoint, which initiates a reverse sweep to compute
x.(t) = xML[tlO, T] over the entire interval. The key to this backward sweep is again to
interpret it as the computation of ML estimates based on an appropriate set of observations.
In particular suppose that we have computed x,(t+1) and its corresponding error covariance
v [t + 110, T], where EV[t + 110, T] is interpreted as in (4) if x(t) is not estimable. Then
as shown in [13] the computation of x,(t) and E,[t + 110, T] can be obtained by solving the
following ML estimation problem which captures all relevant information relating x(t) to
x(t + 1) and the available estimates of of each of these:
iML[tl0, tj]
wL[t + 110, t]
0
E(t + 1)x,(t + 1)
Pf (t)
0
(I - P,f(t + 1))A(t)
O
0
P, (t + 1)
(I - P(t(t
I
x(t)
+ 1))
+
+
(t)(2)
By choosing appropriate change of variables this can be partitioned into two indlepelentlt
observations.
[
M L' [ t O t ]
,
- { v '[ t O t ]A T ( [t)
[
lO
1
]ttM ; f L
t + 110, t ]
{(I- Pf (t + 1))BT(t)B(t), Zf [t + 10,tfif
t]}
+ 110,
l0 t]
t]
]}t110L[tt +
10
p~f~t)
-vrttlO t]AT(t)E# [t + 110, t]
(Pzf (t + 1) - I)A
(I - P, (t + 1))(A(t) - BT(t)B(t)Ef [t + 110, t])
|
MLIt ±+1 0,t]
ir
P~f(t + 1)
E(t + 1)f[t + 110, T] I
(t)
[
z(t
zf(t + 1) + V2 (t)
1
+ 1)
(44)
where v 1 (t) has a covariance given by
C(OV[vl(t)]ll =- f[to0, t] CoV[Vl
(t)]l
2
= -f
Cov[vl(t)]2 1 = -(I
-
,[tlO,t]A(t)TE# [t + 110, t]A(t)f [tlJ, t]
[tlO, t]A(t)TE# [t +
(45)
10, t]BT(t)B(t)(I - Pf (t + 1))
(46)
Pf (t + 1))BT(t)B(t),# [t + 110, t]A(t)Ef[tO, t]AT(t)
(47)
Cov[vi(t)]2 2 = (I - Pzf (t + 1))BT(t)B(t) - BT(t)B(t)3*, [t+110, t]BT(t)B(t)(I - P,,) (48)
In equation (44) two observations are provided of the estimate of zf(t + 1) since one
of the measurements is the smoothed estimate no additional information is contained in
ftL[t + 110, t]. The estimate is therefore equal to Ei[t + 110, T] with error covariance given
by E(t + 1)ESf[t + 110, T]ET(t + 1).
The resulting ML estimate of x(t) is precisely f,(t). In the causal case in which E=I and
all covariances are well defined and invertible, this rep'ices to the usual Rauch-Tung-Striebel
algorithm. We refer the reader to [13] for explicit computations in the more general case.
3
Parallel Smoothing Algorithms
In this section we describe two highly parallel algorithms for optimal smoothing for TPBVI)S as in (13) - (15). Amplifying on our discussion in Section 1, our algorithms have the
following structure. First the overall data interval of definition is partitioned into disjoint
subintervals. In each such subinterval we define the STPBVDS model (17), (19),(21) with
the time origin taken at the center of the subinterval and perform outward filtering using
the FMLF described in the preceding section. At the end of this stage information must be
exchanged among the subinterval processors. From the perspective of any individual subinterval, the relevant information from all other subintervals can be interpreted as providing
additional measurements of x(t) at the boundaries of this interval. Once this information is
incorporated, each subinterval processor can proceed independently with either the BMLF
/ Mayne-Fraser procedure or the Rauch-Tung-Striebel algorithm described in the preceding
section in order to produce optimal smoothed estimates across the entire subinterval. At
this stage the advantage of the Rauch-Tung-Striebel algorithm is that the original data is
not necessary to recover smoothed estimates.
The preceding description requires several additional commlents. First since the itmost
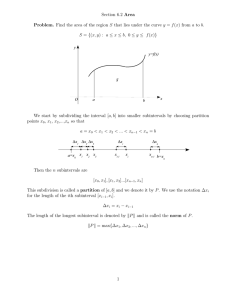
general boundary conditions for TPBVDS (15) couples x(-T) with x(T). our partitioning
into subintervals must in essence view the points -T and T as neighbors. Thus for exanmple if
we partition our data into two subintervals, the natural choice of partition is [-T/2, T/2] and
[-T, (-T/2)-1] U[(T/2)+1, T]. In this case the outward processing over the first subinterval
(
t=T/2
t=T
t = -T/2
t = -T
t=O,
Figure 1: Combining data at ±T/2
incorporates the boundary measurement (19) while that for the other interval has as its
'center' the pair of points [( -T), x(T)] and incorporates the boundary 'measurement' (20),
In general this boundary condition couples the two components of the state [xT(t), xT(-t]T
over the interval t E [T/2 + 1, T]. However, if the original system is separable, these
two components are completely decoupled implying as illustrated in Figure 1 that we in
fact have a three interval decomposition with outward processing in the central interval
and completely decoupled processing at the two ends. For simplicity in the subsequent
discussion we will assume that the processing in the end intervals is also outward front
their centerr. 1f fi'rt;hr :,khbinterval decomposition is performed the additiona l !r.-te;vals also
employ outward processing.
Because of the discrete nature of our time index, a general comment is required concerning the precise nature of the data exchange step. To illustrate this consider the case of an
STPBVDS and the three interval decomposition described in the preceding paragraph. In
this case one might expect the outward processing in the central interval to culminate with
the filtered estimates ML[T/21 - T/2, T/2], and ML[--T/21 - T/2, T/2] while the two outer
interval culminate in iML[(T/2) + 11(T/2) + 1, T] and .ML[-(T/2) - 11 - T, -(T/2) - 1].
However if we wish to view neighboring intervals as providing 'measurements' at subinterval endpoints then we need to produce predicted estimates as well. Note in particular
that these prediction steps in essence incorporate the final dynamic constraints not used
in the first local processing step, namely those relating boundary points of the neighboring
subintervals.
E((T/2) + 1)x((T/2) + 1) = A(T/2)x(T/2) + B(T/2)u(T/2)
(49)
E(-T/2)x(-T/2)= A(-T/2) - 1)x((-T/2) - 1) + B(-T/2) - 1)u((-T/2) - 1)
(50)
To simplify the discussion in the remainder of this section, we focus on the case of
STPBVDS's (17). Furthermore we assume that the values of x(t) at subinterval boundlary
endpoints are estimable based on the data in the subinterval. As a result it is no longer
necessary to propagate pseudo-inverses in our subsequent discussion since all covariainces
are well defined. The results of Section 2 can of course be used in the more general case. By
making the assumption of strong observability introduced in [12] we are able to guarantee
the estimability of x(t) at the end points. In the case of constant coefficients systems the
assumption of strong observability implies that x(t) and x(-t) are jointly estimable based
12
on data over the interval [-t, t]( so that the joint error covariance is well defined) as long
as t > n where n is the dimension of x(t). 2 . In addition it is useful to adopt simplified
notation describing only those variables of interest in the exchange step. Specifically, again
using an ML perspective, we have the following unknowns which we wish to estimate.
[
[
X1 J
x
1[
X3 'j
x4
X5
[
.
'
2m-4
X2m-3
]
X2m- 2
[
1
(51)
2
L2m-1
X2k-2 represents the left most internal boundary point of the (k)th subinterval, and
X2k-1 represent the right most boundary point of the (k)th interval. The time indices indi-
where
cate that the indicated quantities are appropriate samples of X(t) at the various endpoints.
In our three interval example, [x T ,
is given by [xT(O), XT((-T/2) - 1)], [ T , x T ] is given
by [xT(-T/2),xT(T/2)] and finally [xTm_2, T_l] is given by [xT((T/2) + 1),T]. Our
estimates of these variables are based on the following 'measurements'
4T]
[X 2i-2
Y2i-2
Y2i-1
J
[
2i-1
E2i-2
(52)
E2i-1
(53)
as well as the following additional noisy constraints.
E2iX2i = A2i- 1 x2i- 1 + B 2 i-lU2i- 1
where
Ei,
(54)
and u, are independent Gaussian random variables with the following covariances.
Cov(u) = I
Co
[E-2
]=
E2i-1
R2i-2
R 2 i-1,2i-2
(55)
R2i-2,2i-1
R2i-1
(56)
Here the 'measurements' (52) correspond to the independent endpoint estimates produced by each subinterval processor during the first stage, while the constraints (54) correspond to the dynamics (22) across subinterval boundaries. Note that because of our
adoption of an ML procedure for the first stage, the zero mean gaussian variables ei, and
uj are mutually independent. In contrast to the approaches in [6,7] this leads to dramatic
simplifications in terms of interpretations of the result, computations, and preprocessing.
Note also that (52), and (54) looks very much like our original STPBVDS. The only
difference being the fact that the system (52), and (54) is trivially estimable since (54)
provide complete measurements of each xi and the special form of the dynamics linking the
bottom half of one state to the top half of the next. This form allows us to describe two
procedures for the data exchange step, one of which is a natural application of the mllethods
in Section 2 and the other of which offers some new possibilities for parallel processing.
Algorithm #
1:
We use a Mayne-Fraser or a Rauch-Tung-Striebel procedure to exchange information between subintervals. In particular let us describe a version of the FMLF tailored to this
2
Nole Ithat this implies thaIIt th(e irojf(clio Iliatrices Pr(t) aId Pi(t) 1teed oily .,e propar;lgate;l ,e'r a
limit ed intterval of Icllgt h of at most 2n before they are equal to tile idlentity
13
model. In particular thanks to the form of this of the dynamics (54) our FMLF propagates
estimnates of the odd numbered z(t)'s , i.e. the bottom halves of each state vector. 3 Also
let zilj denote the ML estimate of zi based on Yk, k < j. Then
1il = Y1
(57)
ELI1 = R
(58)
We can then compute i2k-112k-1 the estimates of Z2k-1 based on on Yl through Y2k-1, and
equations (54) for i < k - 1. recursively as solutions to the ML estimation problems
r2k-312k-3
Z[
I
Y 2k-
0
Y
Y2k-2
Y2k-1
0
-A2k-3
L
0
0 i-
0
E 2k- 2
T
XI
°
0
0
X2k.312k3
o0
X2k-312k-3
L2k-312k-3
I J
L2k-1
B2k-3U2k-3
2k-112k-1
12k-3
(59)
E k-2
J
where x2i-312i-3, the error in i2k-112k-3, is uncorrelated with u 2k- 3 , E2k-2, and e2k-1
and has covariance E.2i3_I2k3,.Equation (59) is of the form (3), and the solution i2k-112k-1
is directly obtained in the form given by (2). Finally, at the last stage we compute the full
smoothed estimate of X2ml1 will have been obtained. This FMLF can then be combined
either with an analogous BMLF to yield a Mayne-Fraser procedure or with a backward
Rauch-Tung-Striebel step. Note that the extension to the case of non-estimable systems
can be readily accomplished using the formalism in Section 2. However, even in the case
of estimable variables it is still necessary in ueneral to use pseudo-inverses to solve the ML
problems since the noise covariances needed to solve (59) are in general singular. 4
The computational structure of Algorithm # 1 involves essentially serial processing from
subinterval to subinterval and thus takes time proportional to m the number of subintervals
and in fact does not make use of the parallel computing power of the array processors,
although it does only require nearest neighbor connectivity for the subinterval processors.
Also the use of a purely serial formalism indicates that this approach is naturally associated
with 1D processes. In contrast our second approach is highly parallelizable, although it uses
more dense interprocessor communication, corresponding most naturally to a hypercube
architecture. Also this approach, which involves propagation from fine to coarse partitions(
of the data), is naturally extended to higher dimensions. Furthermore since the subinterval
interchange step is itself a TPBVDS smoothing problem, this second approach also provides
an alternate parallel processing algorithm for our original TPBVDS smoothing problem.
The statistical interpretation of our second algorithm is best understood by contrasting
it with that of Algorithm #1. Specifically in the FMLF step of Algorithml
#1 we essentially
use the Markovian nature of the TPBVDS to obtain a recursion for the best estimate
i2i-_l2i- 1 of the boundary point of a data interval of increasing size based on all of the
data within the interval. However this same philosophy leads to the idea of simultalleolsly
obtaining recursions for estimates over several disjoint data intervals of increasing size.
3
'fIe I .fo1thie. 1,:,.ldl calculatI, e estii - es. o[
Of Ithle
i to hfileop Imleal(jui.± Ito a stly %Ilmlu
or
, irvllc,,l {'lrl
for the step forrcomliinuig the FIILJ" and B3ILF estimaites. Tlhe I
!{.ih-'liifl-g-Stri
l ,le
:lg itIt
i i .iil:lyki
mI.
modified. See [13] for (letails.
41For examplle vevtn in causal sySttlilS the tdyn. ic constraints [] does not necessaril'
process w.
haIve' a f1ll ralk niois'
14
where the estimates are merged as data intervals are joined. Taking this to it full limit, we
obtain the following.
Algorithm# 2:
We suppose, for simplicity that m = 2 K so that the number of vectors to be estimated
in (51) is a power of 2. To initialize the algorithm we use the measurements yi, in pairs as
independent ML estimates of the following 2 K quantities.
[ 2 - 21
]
0
[ Y2i-2
i 2i-l1o J
i = 2, 4,..., m
(60)
Y2i-1
with the corresponding estimation error given by the appropriate Ej's with the estimation
error covariances given in (56). Then the first step of the algorithm merges the estimates in
non-overlapping pairs together with the appropriate intervening dynamic constraint (54).
Specifically, we can solve in parallel the following 2 K ML estimation problems:
[2i-210
00I
I0
00
i2i-110
0
0
I0
O
i2i0O
2i+110
0
O
-A2i
E
]
[
X2i-2
X0
I
0
[
1
E2i2
(61)
Ei-1
2i
e2i
2i+1
0
2i1
2i+lB2i-1U2i-1
where i is an odd integer. Because of the block diagonal nature of the noise covariances
in clese ML
v estimation problems, and the special structure of the measurement matrices
(i.e. each consists of an identity block together with one dynamic coupling constraint),
these ML problems can be solved efficiently (see [13]). Furthermore the resulting estimates,
which we denote by z2i-2(1, x2ij-ll, Z2ill, and x 2i+1 11, etc., have independent errors from
ML problem to ML problem ( e.g. the error in carrying out the estimation indicated in
equation (61) for i=1 is uncorrelated with the error in from the same equation when i=3).
Note also that we have used half of the dynamic constraints in this first step. To continue
the process it is important to realize that we essentially have the same problem as we did
at the first stage! To make this more explicit, consider the estimate resulting from (61),
for i = 3, i.e.i 411, i511, x6 11, and i 7 11 which the best estimates of Z4 , x$, z 6, and z7 based
on the corresponding data from (52) and the intervening dynamic constraint from (54).
However, thanks to the Markovian nature our system- or equivalently the local nature of
the dynamic constraints- it is only the boundary elements of this set of estimates ii4I1, and
2i711 that are relevant to the estimation of variables outside this data interval when the
remaining dynamic constraints from (54) are taken into account. Thus for the next step of
the problem we wish to estimate the variables,
[O
[3
X4
[I,X
X8
][
...
X2mn-
11
(62)
X2?n-4
X2m-5
2n-1
]
(2)
based on the measurements
[
X311
X31
I
L3 11
1
(63)
15
lI
I
.
__
II 11*
II I
I 'I
Processor Processor Processor Processor Processor Processor Processor Processor
·#000
#001
#010
#011
#100
#101
#110
#111
Figure 2: Combining Independent Boundary Data in a Tree Structure
[411
;L71l
I=
]1+
[ 4
X711
..
4[ 1]
(64)
711j
(65)
and the remaining dynamic constraints (i.e (54) for i=2,4, m) Thus we have half as many
variables to estimate based an half as many independent dynamic constraints, and half as
many 'measurements' representing the accumnulated information over intervals of twice the
length as before. The complete processing structure is as depicted in Figure 2. Specifically,
we have a tree of computations producing estimates at boundary points of merged intervals
that double in size as we move up the tree indicating a coarsening of the data partitioning
and a concomitant thinning of the required estimates. All of the computations in going fromt
one level to the next can be calculated in parallel. Since the number of such complpltations
is halved at each level, we have a natural pyramidal structure for the computations. Such
a structure is perfectly well-suited to a hypercube architecture in which processors are
placed at the vertices of a unit cube in an L-dimensional space and are directly connected
to processors at nodes connected by edges. For our problem ideally we would like to use
16
a K-dimensional hypercube so that no processing steps required communication with any
latency (i.e., communication between non-adjacent nodes). For example as illustrated in
Figure 2, for the case of m = 3, the initialization step (corresponding to the initial local
processing within each data subinterval) is carried out in parallel on all 8=23 processors.
The next step involves pairings of processors that differ in only one bit (i.e. (000, 001), (010,
011), (100, 101), (100,111)) with processing accomplished in the first element of each pair
incorporating the data for each of the two processors as well as the intervening dynamic
constraint (which is then removed at the next step). At the next level, the remaining active
processors are again paired so that there is only one bit difference ((000, 010) and (100,
110)), etc.
Note that when we have reached the top of the tree, we have computed the full optimal
estimate at only a pair of the xi boundary points. However, the procedure we have described
is exactly the same in structure as the recursive method outlined in Section 2, except that
here the recursion is indexed by the resolution of the data partitioning - i.e., we have
described a fine-to-coarse recursion. It is not difficult to see then that what remains is
the Rauch-Tung-Striebel back-substitution step, proceeding back down the tree,in parallel
at each level, until at the end we have distributed appropriately the optimal smoothed
estimates based on all data of the end points of each subinterval, which is exactly the
same as the result of Algorithm # 1, although in this case the time required to do this is
proportional to log(m) since we have been able to use parallel rather than serial operations.
4
Conclusion
In this paper we have described new parallel algorithms for optimal smoothing for the class
of two-point boundary value descriptor systems, which includes not only standard causal
linear state models but also a rich class of noncausal models. Our approach is based on
a partitioning of the data into subintervals with parallel local processing, followed by an
interprocessor exchange step, and a subsequent parallel local processing step. The desire
to simplify the problem of merging estimates and the nature of TPBVDS's led us to adopt
an ML philosophy throughout our development, necessitating a generalization of recursive
ML estimation procedures to allow for the possibility that neither the estimation error
covariance nor its inverse may be well defined. This led us to a generalization of the MayneFraser two-filter smoothing algorithm, in which the two ends of the data interval are treated
synnmmetrically, and of the Rauch-Tung-Striebel algorithm.
As we have shown, the data interchange step of our parallel processing algorithms can
itself be viewed as a smoothing problem for a TPBVDS whose "state" represents the boundaries of the subintervals used in the first, local processing stage. This led naturally to one
class of algorithmic structures using the ML version of Mayne-Fraser or Rauch-Tung-Striebel
that we have derived. An important point to note here that in this structure the estimates
produced by the first local processing stage play the role of "mleasurements", with the sdynamic relationships between subinterval boundaries playing the role of dynamics. Note tlhat
the interval dynamic relationships have in a sense been absorbed into the "measurements".
This emphasizes not only the fact that measurements and dynamics play essentially identical roles as noisy constraints in the ML formalism but also that the key to essentially all
efficient (and in our case parallel) estimation algorithms is the judicious choice of the order
7
in which these constraints are applied and in which variables are eliminated.
This is perhaps even more apparent in our second algorithm which can serve either
as the interprocessor interface step or as a stand-alone parallel smoothing algorithm. In
this algorithm, the individual estimates from the first local processing stage (or the new
data in the stand-alone mode) serve as initial condition for our dynamic model which
evolves finer to coarser subinterval partitions by merging subintervals and keeping track
only of the resulting exterior boundaries - i.e., the dynamics in this case are essentially
nothing more than decimation! Moreover, the dynamic relationships between subinterval
boundaries in this case essentially play the role of measurements! This leads us naturally
to the consideration of dynamic models on dyadic trees, a topic that has also arisen quite
independently, from the development of statistical filtering methods related to the wavelet
transform. We refer the reader to [14] for complete expositions of this topic.
Finally, as we indicated in the introduction, the structure of Algorithm # 2 can be
easily extended to multiple dimensions. For example consider a Markov random field [15]
on a 2-D rectangular grid, and suppose we partition the data array into many smaller
rectangles. A natural parallel processing structure in this case is a first, parallel, outward
processing step within each sub-rectangle, followed by an exchange of boundary information
and a subsequent parallel inward processing step. Looking more carefully at the boundary
exchange step, we can imagine performing it in exactly the same way as in Algorithm # 2:
merging smaller rectangles into larger ones (in parallel) and propagating information about
the resulting outward boundaries. Note that t his also can be organized to have a dyadic
-ese structure
and thus is naturally matched to the hypcaube architecture. Obvi .:!y;
while what we have just described is superficially identical to what we have discussed in this
paper, there are substantial differences since outward and inward processing on rectangles is
quite different from that on intervals and the same is obviously true about the relationship
between rectangle and interval boundaries! Thus, the development of methods for 2-D
smoothing that realize the structure we have described is far from. trivial. An investigation
of this problem is currently underway and will be reported on in [13].
References
[1] Bello, Martin G., Alan S. Willsky, Bernard C. Levy, and David A. Castanon, Smoothing
Error Dynamics and Their Use in the Solution of Smoothing and Mapping Problems,
IEEE Transactions on Information Theory, Vol IT-32, No.4, July 1986
[2] Levy, Bernard C., David A. Castanon, George C. Verghese, and Alan S. Willsky, A
Scattering Framework for Decentralized Estimation Problems, Automatica Vol 19, No
4, pp373-384, 1983
[3] Speyer J.L., Computation and Transmission Requirements for a Decentralized LinearQuadratic-GaussianControl Problem, IEEE Transactions on Automatic Control, Vol
AC-24, pp266, 1979
[4] Willsky, Alan S., Martin G. Bello, David A. Castanon, Bernard C Levy and George
C Verghese, Combining and Updating of Local Estimates and Regional Maps (along
18
one Dimensional Tracks, IEEE Transactions on Automatic Control, Vol AC-27, No.4,
pp799-813, August 1982
[5] Hashemipour, Hamid R., Stunit Roy, and Alan J. Laub, Decentralized Structures for
ParallelKalman Filtering,IEEE Transactions on Automatic Control, Vol AC-33, No.1,
January 1988
[6] Morf, M., J.R. Dobbins, B. Freidlander, and T. Kailath, Square Root Algorithms for
ParallelProcessingin Optimal Estimation, Automatica, Vol-15, pp. 299-306, 1979
[7] Tewfik, A.H., B.C. Levy, and A.S. Willsky, A New Distributed Smoothing Algorithm,
MIT Laboratory for Information and Decision Systems, (LIDS-P- 1501), Aug 1988
[8] Catlin, Donald E.,Estimation of random States in General Linear Models, IEEE Transactions on automatic control, Vol. 36, No.2, February 1991
[9] Campbell, S.L., and C.D. Meyer, Generalized Inverses of Linear Transformations. London: Pitman, 1979
[10] Ljung Lennart, and Thomas Kailath , A Unified Approach to Smoothing Formulas,
Automatica, Vol. 12, ppl 4 7-157, 1976
[11] Nikoukah, Ramine A Deterministic and Stochastic Theory for Two-point Boundary
Value Descriptor Systems, MIT-Laboratory for information and Decisi(?n Systemq
LIDS-TH-1820
[12] Nikoukhah, R., A.S. Willsky, and B.C. Levy, Kalman Filtering and Riccati Equations
for Descriptor Systems Proceedings of the 2 9 th IEEE Conference on Decision and
Control, Dec 1990
[13] Taylor, Darrin ParallelEstimation on Two Dimensional Systems Ph.D. Thesis, MIT,
Aug 1991
[14] Chou, K.C., A Stochastic Modeling Approach MultiScale Signal ProcessingPh.D Thesis,
MIT, Jun 1991
[15] Levy, B.C., M.B. Adams, A.S. Willsky, Solution and Linear Estimation of 2-D Nearest
neighbor Models Proceedings of the IEEE Vol.78, No. 4, April 1990