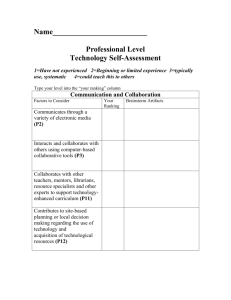
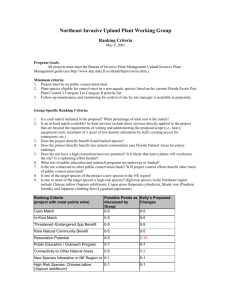
Why Not Allow Individuals to Rank Freely? Waste Management in Corsica
advertisement

1 2 3 4 Why Not Allow Individuals to Rank Freely? A Scaled Rank-Ordered Logit Approach Applied to Waste Management in Corsica Olivier Beaumais, Anne Casabianca, Xavier Pieri, Dominique Prunetti UMR CNRS 6240 LISA; Università di Corsica - Pasquale Paoli; Campus Mariani, BP 52, 20250 Corte, France. 5 September 2014 6 Abstract 7 Since the introduction of the rank-ordered logit model in the eighties, the cognitive e¤ort involved in a 8 ranking task has been the source of concerns. Despite the fact that the rank-ordered logit model provides 9 e¢ ciency gains, when compared to the basic multinomial logit model, respondents may not all be able to 10 provide a reliable full ranking of the alternatives they face. Unreliable or ’noisy’rankings result in estimate 11 biases, so that it has even been suggested that only the …rst three ranks to be used for estimation. In order 12 to deal with that ranking capabilities issue, we propose a survey design which allows the respondents to 13 provide freely incomplete rankings in accordance with their actual heterogeneous ranking capabilities. 14 Using the full-ranking of the alternatives and the accurate sub-ranking of the alternatives, we …rst 15 estimate a basic rank-ordered logit model. After testing for heteroscedasticity, we also estimate an 16 heteroscedastic rank-ordered logit à la Hausman and Ruud, 1987, and introduce a new scaled rank-ordered 17 logit which allows us to model further the sources of heteroscedasticity in the data. The methodology 18 is applied to the issue of waste management in Corsica. Using rankings of waste management options 19 given by a representative sample of the Corsican population (530 respondents) we provide estimates of 20 the willingness-to-pay for various options of waste management calculated from models estimated on 21 the full-ranking and on the sub-ranking data. We …nd strong evidence that estimations on the full- 22 ranking data set and on the accurate sub-ranking data set di¤er widely. Allowing individuals to provide Corresponding author: olivier.beaumais@univ-rouen.fr 1 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a 1 freely incomplete rankings eliminates a large part of the heteroscedasticity stemming from heterogeneous 2 ranking capabilities. 2 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a 1 1 Introduction 2 As recalled by Hoyos (2010), the econometrics of choice experiment is mainly based on the multinomial logit 3 model and its extensions. Amongst the extensions of the multinomial logit model, the rank-ordered logit 4 model has proven to provide e¢ ciency gains as an appropriate tool for analyzing ranking data obtained by 5 asking the respondents to a choice experiment to rank various alternatives instead of simply choosing the 6 one they consider to be the best. However, since the introduction of the rank-ordered logit model (Beggs et 7 al., 1981, Chapman and Staelin, 1982) the cognitive e¤ort involved in a ranking task has been the source 8 of concerns. Respondents probably do not rank accurately from top to bottom and are suspected to pay 9 more attention to their top preferred alternatives, so that a full-ranking data set probably includes ’noisy’ 10 (Chapman and Staelin, 1982) information which can bias the estimates. Thus, it is likely that only the …rst 11 few ranks provide reliable information for the estimation. As a consequence, Chapman and Staelin (1982) 12 suggest using the …rst three ranks, taking into account a trade-o¤ between improvements in the precision 13 of the parameter estimates and the e¤ect of the inclusion of ’noisy’observations (i.e. non-reliable ranking 14 information). They also suggest asking the respondents to provide ratings of the alternatives, arguing that 15 it may allow them to give tied ratings (instead of full rankings) more easily. Hausman and Ruud (1987) 16 propose a heteroscedastic rank-ordered model where ranks receive weights (scaling parameters) that "allow 17 the variance of the lower ranks to be di¤erent from those in the higher ranks". However, in Chapman and 18 Staelin (1982) so as in Hausman and Ruud (1987) estimations are run over the same ranking range for each 19 respondent. Ben Akiva et al. (1992) explore further the reliability of preference ranking data. They estimate 20 heteroscedastic rank-ordered logit models in which heteroscedasticity depends on the ranking depth along 21 with rank-ordered logit models that attempt to capture the e¤ects of actual choices and/or of the survey 22 design on the parameter estimates. They conclude that estimations from full-ranking data su¤er from 23 biases which cannot be fully corrected by observed and unobserved heteroscedastic model speci…cations. 24 Also dealing with the cognitive task of ranking multiple alternatives, Van Ophem et al. (1999) design a 25 questionnaire where the respondents …rst choose the 16 most preferred from 32 o¤ers of …ctitious classical 26 concerts, then select the 8 most preferred from the 16 classical concerts selected in the …rst step, and …nally 27 fully rank the resulting 8 o¤ers. They argue that such a design is more manageable than a design where the 28 respondents are asked to rank all the alternatives and show that the additional information provided by the 29 ranking of the 8 preferred o¤ers clearly yields more e¢ cient estimates of the parameters of their model. 30 Recent developments in the …eld of discrete choice experiment focus on ways to lessen the cognitive e¤ort 31 involved in a ranking task. Scarpa et al. (2011) argue that a best/worst approach provide high quality 3 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a 1 ranked-ordered data. A best/worst elicitation format consists in asking the respondents to state which 2 alternative they think is the best, and which alternative they think is the worst, out of the initial choice set. 3 Then, they perform the same task on the choice set obtained by withdrawing the …rst two choices from the 4 initial choice set and so on, until they have ranked all the alternatives. Estimating heteroscedastic ranked- 5 ordered logit models, Scarpa et al. (2011) …nd that the iterated best/worst elicitation format facilitates the 6 respondents’ranking task and hence provides better data and welfare estimates. 7 Likewise, in order to cope with the heterogeneous ranking capabilities, Fok et al. (2012) propose a latent- 8 class rank-ordered model which describes endogenously the ranking ability of the individuals. According to 9 their approach, the respondents belong to latent segments which capture the unobserved ranking capabilities. 10 The latent-class rank-ordered model allows to use all the rankings provided by the respondents and to reveal 11 their ability to rank. Using Monte-Carlo simulations, Fok et al. (2012) show that the latent-class rank- 12 ordered model provide e¢ ciency gains compared to the standard multinomial model when at least some 13 respondents are able to rank1 . However, they also conclude that: "In our approach the ranking ability is 14 considered to be unobserved. One can imagine a survey design in which respondents are asked to rank only 15 those options that they are able to rank. In such a survey the ranking ability would actually be observed." 16 Indeed, when the survey design allows to observe the ranking capability of each individual, the use of the 17 latent-class rank-ordered model proposed by Fok et al. (2012) has no motivation. 18 It should be noted that rank-ordered data have also been compared to data stemming from other elici- 19 tation formats, in the conjoint analysis/choice experiment literature. Boyle et al. (2001) use a split-sample 20 approach to assess whether recoding ratings to ranks or to a ’choose one’format results in di¤erent valua- 21 tions. After concluding that these three formats probably give di¤erent valuation results, they recommend 22 not to recode ratings to ranks or to ’choose one’, but assessing the ranking capability of the respondents is 23 beyond the scope of their work. 24 So far, and surprisingly enough, the literature devoted to the ranking capability issue rests on survey 25 designs that force the respondents to provide a full preference ranking of a given set of alternatives. Then, 26 sophitiscated econometric methods are invoked in order to capture the heteroscedastic nature of the data 27 generated. 28 As an exception, in her paper on the valuation of a nature reserve, Baarsma (2003) proposes a survey 29 design that includes three valuation questions: the …rst valuation question asks individuals to rank six cards, 30 the second valuation question asks individuals to rate the same cards and the third valuation question asks 1 Yoo and Doiron (2013) develop a model, the latent-class heteroskedastic rank-ordered model, that nests both the models of Hausman and Ruud (1987) and Fok et al. (2012). For now, their model has been estimated on data from a choice experiment in which nursing students have too rank hypothetical nursing jobs. 4 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a 1 individual which of the six cards (none, the …rst one, ..., all six) is/are the most acceptable to them. She 2 …nds that the three elicitation formats give quite similar valuation results but the ranking capability of the 3 respondents is beyond the scope of her work so that, from this point of view, she does not exploit the richness 4 of her data. As we argue further below, we suggest that a survey design à la Baarsma (2003) may provide 5 the information necessary to overcome the ranking capability issue. The main idea is to cross-compare the 6 answers to a series of ranking tasks, including a ranking task which allows the respondent to provide freely 7 incomplete rankings, in order to assess precisely the e¤ect of the heterogeneous ranking capabilities of the 8 respondents on the estimates. 9 Our methodology is illustrated with a multi-attribute stated preference survey focused on solid waste 10 management in Corsica. Although some studies have employed choice experiment to study preferences 11 relative to solid waste management in big countries, none of these have focused on a small island like Corsica 12 characterized by the pressure of tourism and scarcity of usable land. Recent attempts to comply with 13 French law and European directives on waste management have resulted in con‡icts between environment 14 and development, leading the local authorities to abandon an incinerator project without proposing any 15 other solution, despite the fact that the status quo could undermine the bedrock of the whole economy. 16 Thus, one of the motivations of the choice experiment we report in this paper was to provide up-to-date 17 information to the decision makers on the individuals’preferences regarding waste management options. In 18 particular, we compare rural and urban preferences for solid waste management options characterized by 19 their environmental impacts and the time spent on sorting and cleaning waste. 20 The rest of the paper is organized as follows. Section 2 o¤ers a brief review of the choice experiment 21 literature in the …eld of waste management. Section 3 gives a quick inventory of solid waste management 22 programs in Corsica. Section 4 presents the econometric strategy, the survey design and its implementation. 23 Section 5 discusses the empirical results, beginning with the assessment of the actual heterogeneous ranking 24 capability of the respondents. Section 6 concludes and proposes future directions as well as some policy 25 implications of the study. 26 2 27 Although recent surveys of literature have underlined the growing interest in environmental studies based 28 on choice experiment (Alriksson and Öberg, 2008; Hoyos, 2010), very few of the papers reviewed deal with 29 solid waste management issues. 30 Choice experiment and waste management: what do we know? As far as we know, Garrod and Willis (1998) are the …rst authors to apply choice experiment to solid 5 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a 1 waste management. Using a multinomial logit model allows them to determine marginal willingness-to- 2 pay to reduce noise, odor and dust from a land…ll site in the North-East of England. They implement an 3 elicitation method in two steps. In the …rst step, respondents are asked to make a choice between two cards 4 (alternatives). In the second step, they are asked to make another choice between the chosen card and two 5 new cards. As in Garrod and Willis (1998), the majority of choice experiment studies used for valuing 6 waste management externalities are based on the basic multinomial logit model and a simple choice task 7 consisting in asking respondents to choose the best alternative within sets of cards. This choice task can 8 consist in choosing one of two cards including status quo (Jamal, 2006 in Malaysia; Jin et al., 2006). The 9 choice can also be made between two cards and an opt-out option as in Karousakis and Birol (2008). Using 10 pair-wise choice experiment they estimate the households’willingness-to-pay for speci…c kerbside recycling 11 services in London. In some studies, the choice has to be made between three cards including status quo (Pek 12 and Jamal, 2011 in Malaysia examining a labelling e¤ect for solid waste management options on choice) or 13 between three cards plus an opt-out option (Sasao, 2004a, 2004b in Japan). Caplan et al. (2007) use a simple 14 logit model, a binary-choice logit model2 . In their study in Cache County (Utah), respondents are asked to 15 make four choices within sets of two cards. The method allows the authors to conduct compensation tests 16 between host and non-host communities. Two studies however use a probit model. Sakata (2007) estimates 17 a multinomial probit model3 to assess the residents’ utility for waste collection methods in Japan. Using 18 pair-wise choice experiment Nakatani et al. (2008) estimate on the basis of an ordered probit model the 19 households’ willingness-to-pay for municipal solid waste management options in Kawasaki City (Japan). 20 They notably report existence of respondents with dominant strategies. As far as we know, Caplan et 21 al. (2002) is the unique contribution employing a ranked-ordered logit model in the …eld of solid waste 22 management studying the willingness-to-pay for curbside waste disposal options in Ogden (Utah). The 23 authors use a survey where respondents are asked to rate a status quo option and two di¤erent options 24 (same two options for all individuals) in terms of curbside trash-separation services provided and price 25 attributes. 26 This brief review of the literature shows that the econometrics of choice experiment applied to the 27 valuation of waste management externalities is mainly based on the multinomial logit model and rarely on 28 its extensions, especially on the rank-ordered logit model. Before turning to theoretical considerations, the 29 next section provide more information on the survey area. 2 On the basis of the binary-choice probit model used by Bre- e and Rowe (2002) in a study addressing PCB-cased natural resource losses in Green Bay, Wisconsin. 3 Arguing the fact that this model permits to relax the restriction imposed by the multinomial logit model which requires the assumption of independence from irrelevant alternatives. Indeed, he argues that "[...] IIA assumption is a very strong restriction when using CA in policy studies." 6 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a 1 2 3 A quick inventory of the solid waste management programs in Corsica 3 The French island of Corsica lies in the Northern Mediterranean, only 7 miles north of the Italian island 4 of Sardinia. It has a land area of 3,350 square miles, and a permanent population of 305,674 in 20094 , 5 making for a rather low population density of 83 inhabitants per square mile. However, tourism in Corsica is 6 signi…cant, if seasonal: the island receives almost 2.5 million tourists annually, with a peak of around 450,000 7 visitors in the month of August alone. Though some studies have employed choice experiment to study 8 preferences relative to solid waste management in big countries, none of these have focused on a small island 9 like Corsica characterized by the pressure of tourism and scarcity of usable land. Like other mediterranean 10 islands, the Corsican economy is mainly based on tourism, which is driven by remarkable amenities and 11 also has signi…cant e¤ects on the share of the construction sector in the local gdp. Thus, as solid waste 12 management programs impact these amenities, their design has been, and still is, the source of concerns and 13 con‡icts in Corsica. As other French regions, Corsica had to de…ne its "Household and Assimilated Waste 14 Disposal Interdepartmental Plan"5 . This Plan, implemented by the Corsican Environment Agency (O¢ ce 15 de l’Environnement de la Corse), had to set technically and economically achievable targets of recycling 16 and recovery, as long as to determine facilities requirements and timeliness. It was established in a context 17 where available data report that Corsica was not in compliance with French and European institutional 18 framework6 . 315,000 tones of household and assimilated waste were produced in 2008 in Corsica: 145,000 19 tonnes were strictly household solid waste. This corresponds to 402 kg/yr per capita, while the French average 20 is 360 kg/yr per capita. A signi…cant part of this overproduction is due to the importance of the tourism 21 industry in the Corsican economy. Indeed, the quantities of waste (broadly de…ned) are respectively 58.5 22 kg/month per capita during tourist season (base: 360,000 inhabitants) and 51.3 kg/month per capita for 23 the rest of the year (base: 304,000 inhabitants), (SYVADEC, 2009). 7.3% of the household and assimilated 24 waste were separated and 79% were treated in controlled land…lls7 . Some of these controlled land…lls, still 25 in operation, are non-standard and some reached a saturation threshold. For sanitary reasons and to meet 26 current legislation, it was decided to built an incinerator in a rural area of the center of Corsica. This project 27 has met sti¤ opposition from various associations and civic society representatives (aggregated in a collective 4 INSEE (French National Institute of Statistics and Economic Studies), General Census of Population 2009. PIEDMA (2002). Revision of this Plan starded in June 2009 and should have been achieved before May, the 17, 2012. 6 Thereby, French law on waste from July 12, 1993 de…nes new principles relative to national solid waste management. Among these, a priority on valorization and the end of uncontrolled land…lls. "Voynet Circular" from 1998 set a recovery target of 50% of all waste collected. 7 Cf. SYVADEC (2009), it has to be noted that the destination of 13% of these solid waste is unknown! 5 Cf. 7 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a 1 action group named "Against Corsican Incinerator"). This opposition was based on three arguments: the 2 oversize and the inadequacy of this technological solution regarding the size of the island’s population and 3 its geographical characteristics, the cost of the project and, mainly, the potential environmental and health 4 impacts. In light of the protest against the project, it was …nally canceled in July 31, 2007 and no other 5 alternative solid waste management plan has been decided to date. 6 Thus, one of the motivations of the choice experiment we report in this paper was to provide up-to-date 7 information to the decision makers on the individuals’preferences regarding waste management options. In 8 particular, we compare rural and urban preferences for solid waste management options characterized by 9 their environmental impacts and the time spent on sorting and cleaning waste8 . 10 4 Econometric strategy, survey design and data collection 11 Because of the recent opposition to a particular solid waste disposal technology (the incinerator), it seemed 12 inappropriate to use an approach focusing on a particular new waste disposal technology. Instead, it seemed 13 more appropriate to present generic waste disposal technology alternatives in order to allow the identi…cation 14 of the trade-o¤s between various waste management attributes. In such a context, discrete choice experiment 15 appears to be the most relevant approach. As Hoyos (2010) recalls, various elicitation formats have been 16 proposed within the discrete choice experiment methodology. The most common approach probably consists 17 in asking the respondents to choose their most preferred option amongst a set of mutually exclusive alter- 18 natives which provides one-choice data which are usually analyzed using the well-known multinomial logit 19 model and its extensions. When respondents are asked to rank the alternatives they face instead of choosing 20 their most preferred one, this provides rank-ordered choice data which are commonly analyzed using the 21 little less-known rank-ordered logit model. 22 4.1 23 Like the multinomial logit model, the rank-ordered logit model (or exploded logit model) rests on the random 24 utility model (Caplan et al., 2002). Since the model was independently proposed by marketing researchers 25 (Chapman and Staelin, 1982) and by econometricians (Beggs et al., 1981) it has been used in many …elds 26 including environmental economics and waste management. The rank-ordered logit model 8 Bergmann et al. (2008) report sensibly di¤erent preferences between urban and rural dwellers but for energy projects in Scotland. Sasao (2004b) includes this comparison but for a particular waste management disposal technology (land…ll) and regarding di¤erent attributes (namely, geographical origin of waste, area of deforestation, proximity with sources of drinking water, distance from respondent’s house) from the ones considered in this paper. 8 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a 1 Each respondent i faces a choice set consisting in J alternatives, which are characterized by attributes. 2 Following partially the notations from Fok et al. (2012), let yij denotes the rank given by respondent i 3 to alternative j. The vector yi = (yi1 ; :::; yiJ )0 corresponds to the full ranking. Respondent ranks the 4 alternatives according to the level of utility that these provide. For each respondent i, the utility associated 5 with each alternative j is Uij which is assumed to be the sum of a deterministic component Vij and a random 6 component ij . That is: Uij = Vij + 7 The ij ’s (1) ij are independent and identically distributed with a type I extreme value distribution. Further0 0 8 more, Vij can be modeled as Vij = 9 describe the alternatives, and the wij contains interaction variables between the respondents characteristics 10 11 12 zj + wij where the zj vector contains variables (attributes) that (gender, age, etc.) and the zj variables. Given these assumptions, the likelihood of a given ranking for a single respondent i is given by (Allison and Christakis, 1994): Li = 2 3 J 6 7 Y exp(Vij ) 6 7 6 J 7 P 4 5 j=1 ijk exp(Vik ) (2) k=1 13 where ijk = 1 if yik yij , and 0 otherwise. As explained by Chapman and Staelin (1982), this likelihood 14 is strictly equivalent to the likelihood implied by a series of sequential choices with each choice governed 15 by a logit model, where the respondent …rst chooses his/her more preferred alternative among the entire 16 set of alternatives, then the most preferred alternative among the remaining set of J 17 so on. Thus, the rank-ordered model may be estimated via a conditional logit model over what Chapman 18 and Staelin (1982) call the ’exploded choice sets’or the ’exploded choice observations’: each individual rank 19 ordered choice set can be decomposed (exploded) into J 20 estimation. 21 i=1 j=1 23 1 choice sets or choice observations used for Furthermore, for a sample of n respondents, the log likelihood is simply given by: Ji n X X 22 1 alternatives and exp(Vij ) Ji n X X i=1 j=1 log " Ji X k=1 ijk # exp(Vik ) Note that, following Allison and Christakis (1994), we allow the depth of the ranking (Ji , 1 (3) Ji J) to vary across respondents. In other words, we allow for incomplete rankings. It should be underlined, as 9 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a 1 …rst pointed out by Allison and Christakis (1994), that the estimation of the rank ordered model can also 2 be accomplished by partial likelihood procedures in the spirit of the survival analysis. To be more speci…c, 3 a higher rank for an alternative may be interpreted as a higher rate of failure in the basic Cox regression 4 model. As modern econometrics packages usually include commands to estimate conditional logit models 5 and Cox regression models, the estimation of a rank-ordered model can be routinely accomplished9 . 6 It should be also noted that the previous likelihood function could be more generally written as: Ji n X X exp( Vij ) i=1 j=1 7 where Ji n X X log i=1 j=1 " Ji X ijk k=1 # exp( Vik ) (4) is a positive scale parameter, inversely proportional to the error variance 2 and usually nor- 8 malized to the unity. Relaxing the assumption that the error variance is constant across individuals allows 9 to specify a wide class of rank-ordered logit model. 10 11 First, the basic heteroscedastic rank-ordered logit model assumes that the scale parameter varies across individuals as follows: = exp( 0 xi ) (5) where xi is a vector of individual speci…c variables, and is a vector of parameters which re‡ects the i 12 13 in‡uence of those individual speci…c variables on the error variance. Within the context of a stated preference 14 survey, xi can include variables that capture design e¤ects, order e¤ects or ranking e¤ects (see Ben Akiva et 15 al., 1992; Caussade et al., 2005; Scarpa et al., 2011). 16 Second, in the spirit of recent developments in the choice experiment literature (Fiebig et al., 2010; Greene 17 and Hensher, 2010) and in order to explore further the ranking capability issue, we propose to extend the 18 basic heteroscedastic model to a scaled rank-ordered logit model. The basic idea is to allow observed and 19 unobserved heterogeneity in the scale parameter. If we considered only unobserved heterogeneity, the scale 20 parameter would be written as: i 21 22 where i 2 = exp( is random variation across individual, i =2 + i) N (0; 1) and the constant (6) 2 =2 is chosen so that E[ i ] = 1 (see Fiebig et al., 2010; Greene and Hensher, 2010). 9 Econometrics softwares usually provide speci…c commands to estimate rank-ordered models, but these commands rests ultimately on a conditional logit likelihood (see the package mlogit in R, see Croissant, 2012) or a partial likelihood procedure (see rologit in Stata). 10 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a 1 2 Combining observed and unobserved heterogeneity leads to the following speci…cation of the scale parameter: i 3 To sum up, with = 0 and 2 =2 + i + 0 xi ) (7) = 0, the scaled rank-ordered logit model reverts back to the rank-ordered 4 logit model; with 5 model. The rank-ordered logit model and the heteroscedastic rank-ordered logit model are estimated using 6 maximum likelihood, whereas the scaled rank-ordered logit model is estimated using simulated maximum 7 likelihood. 8 9 = 0 and = exp( 6= 0, this encompassing model collapses to the heteroscedastic rank-ordered As shown in the next section, our choice survey was speci…cally designed to assess the implications of heterogeneous ranking capabilities. 10 4.2 Survey design and data collection 11 Attributes of the choices and their corresponding levels were derived from the literature on waste manage- 12 ment, pretest studies and focus group. This step permits to exclude some previously considered attributes 13 regarding environmental impacts as irrelevant or involving task complexity and cognitive burden to respon- 14 dents10 , in line with the most recent advances in choice experiment (Caussade et al., 2005; Scarpa et al., 15 2011) which are strongly in favor of a reasonable number of attributes and alternatives. We used a change 16 in the current annual waste fee per household11 as payment vehicle as it appears to be the natural extension 17 of the actual tax payment for disposal services. Attributes and levels …nally selected given the con‡ict over 18 the incinerator and the aims of local authorities are presented in Table 1. Attribute FAC1 FAC2 FAC3 Table 1: Attributes and their levels Description Categorical variable (1-5) co ding the p ollution im pact Levels Degradation: Very High - High (environm ental degradation and health e¤ects) Interm ediate - Low - Very Low Categorical variable (1-5) co ding tim e households M ore than 30 m in. - 20 to 30 m in. weekly sp end on sorting and cleaning waste 10 to 20 m in. - less than 10 m in. - None Change in annual waste fee p er household -40e; -20e; 0e; +20e; +40e 19 1 0 The impacts of waste disposal technologies were initially divided in three components: nuisance from collecting waste, pollution, and toxicity. 1 1 TEOM: French waste fee. 11 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a 1 Each of the levels taken by attribute F AC1 which codes the pollution impact, i.e. the environmental 2 and health e¤ects, was precisely described to the respondents during the administration of the survey. To 3 be more speci…c, the pollution impact attribute was presented from "Very Low" to "Very High" using an 4 incremental formulation, as shown in Table 2, so that every respondent values the same good. Levels/Impacts Very Low Low Table 2: Description of attribute FAC1 Description M ild noise or visual nuisances (e.g. noise due to garbage trucks, visual p ollution caused by plastic bags) Previous level (Very Low) + low im pact p ollution (no health e¤ects) Interm ediate Previous level (Low) + disturbing p ollution High Previous level (Interm ediate)+health im pacts Very High Previous level (High)+heavy visual and o dor nuisances 5 6 A large number of unique solid waste disposal technology service descriptions can be constructed from 7 this number of attributes and levels. Given our 53 factorial structure, we constructed a design in 40 choice 8 sets of 6 cards12 . Table 3 gives an example of a card. Table 3: An example of a card Situation 1 Pollution impact Time weekly spent on Change in the annual sorting and cleaning waste waste fee more than 10 min. -20e High degradation 9 10 The …nal survey was conducted face-to-face by six well-trained interwievers. They surveyed a represen- 11 tative sample of the Corsican population (530 respondents) in November and December 2008. Respondents 12 were selected by strati…ed random sampling based on parameters of age, sex, population and location (IN- 13 SEE, General Census of Population 1999). 14 Survey implementation consisted of three steps. The …rst step gave a presentation of the current situation 15 of solid waste management in Corsica, a description of the various solid waste disposal technologies available 16 and an explanation of the aims of the study. The current situation was presented in terms of annual 17 volume of solid waste produced in Corsica, actual solid waste management used and health risks associated 18 and, …nally, requirements of compliance with institutional framework. Solid waste management options 1 2 Theory and methods regarding the construction of optimal stated choice experiments are fully described in Street and Burgess, 2007. 12 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a 1 were then discussed on the basis of a presentation of their relative advantages and disadvantages regarding 2 environmental impacts and health risks associated, potential for energy production and necessity to spent 3 time on sorting and cleaning waste. Four possible solid waste management options were described aloud 4 to each respondent: sanitary land…lling, incineration, sorting and recycling, composting. This …rst stage of 5 presentation ended with a description of the three attributes used and a presentation of the levels of these 6 attributes. All the information was read aloud during the questionnaire administration. 7 During the second step, each respondent was presented with one of the 40 choice sets of 6 cards and a list 8 description of the levels of the three attributes. On this basis, each respondent was asked to perform three 9 ranking tasks. Finally, in the third step, socio-demographic data about the respondents were collected13 . 10 Regarding the second step, we incorporated an opt-out option allowing the respondent to not choose any 11 of the alternatives in the choice set. This opt-out option can be considered as a status quo option and allows 12 to compute welfare measures consistent with demand theory14 , although it could also be considered simply 13 as a way-out for individuals reacting to the cognitive burden associated to choice experiment (see Caussade 14 et al., 2005). 15 16 As stated above, the design of the three ranking tasks was inspired by Baarsma (2003). The …rst ranking task was simply: 17 Ranking task 1: Please rank the previous cards according to your preferences, with one (1) 18 being most desirable and six (6) being least desirable 19 20 Two follow-up ranking tasks were asked which generate relevant information to assess the actual ranking capabitity of the respondents: 21 Ranking/Rating task 2: Please rate the previous cards (from 0 to 10), 10 being the ideal 22 situation and 0 the worst possible situation 23 Ranking task 3: Could you please now state which of the previous ranked six cards is/are 24 acceptable to you (meaning the policy measure(s) you are really willing to see implemented) 25 To be more speci…c, ranking task 3 was a single question composed of seven items (choices): only the …rst 26 card, the …rst and the second cards ... all six cards, and the opt-out answer: none of these cards. Ranking 1 3 The following individual-speci…c variables have been used: Gender (male; female); Age of the respondent; Municipality of residence (postal code); House type (individual house; apartment); Occupational status (owner; non owner); Knowledge of actual garbage fee (yes; no); Household composition (number of household members by age); Socio-professional categories (CSP in INSEE terminology); Activity sector; Education of respondent; Income (total household income); Preferred solid waste disposal technology; Actual time (mins) weekly spent on sorting and cleaning waste; Opposition to waste treatment plant (yes; no); SWM as a societal issue (yes; no); Belonging to an environmental association (yes; no). 1 4 See, amongst others, Louviere et al. (2000), Boyle et al. (2001) and Bridges et al. (2011). 13 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a 1 task 1 corresponds to the full-ranking tasks. Ranking task 3 asks the respondent to perform a sub-ranking 2 tasks so that she/he reveals her/his actual ranking capability for the current survey. Stated di¤erently, 3 ranking task 3 allows the respondent to extract freely incomplete rankings, from her/his initial full-ranking, 4 strictly in accordance with her/his ranking capability. Ratings resulting from question 2 can be recoded to 5 ranks in order to assess the consistency of the answers to question 1 and question 3, as shown in the next 6 section. 7 5 8 5.1 9 From the initial data set of 530 respondents, observations were excluded when: Empirical results A close inspection of the outcome of the three ranking tasks 10 the gender was not mentioned (two cases deleted), 11 the respondent’s location (rural/urban) was not available (four cases deleted), 12 the full-ranking task was not reported properly (three cases deleted). 13 Which leaves us with a data set of 521 respondents. Amongst them 26 (about 5%) chose the opt-out 14 item from the valuation question 3. In their choice experiment study on forest management practices in 15 Maine, using an opt-out question, Boyle et al. (2001) …nd that only 8% of the respondents would not choose 16 any of the four alternatives (four forest management plans) they face. They argue (Footnote 7, p. 450) 17 that this arises because of the general dissatisfaction with the status quo of forest management in Maine. 18 Unfortunately, Baarsma (2003) does not provide information about the distribution of answers to the opt-out 19 question of her survey. The low percentage of individuals choosing the status quo in our study re‡ects the 20 fact that people in Corsica are aware of the negative externalities associated with the status quo of waste 21 management on their island, and thus vote for a change. This low percentage also re‡ects the fact that the 22 controversial incinerator project was probably rejected because it was perceived as a "take it or leave it" 23 only option. 24 25 Recoding ratings to ranks gives us the possibility to assess the actual ranking capabilities of the individuals. 26 Firstly, out of the 521 cases, only three respondents used ties in their ratings and no one in its rankings. 27 Boyle et al. (2001) …nd numerous ties in the rating data of their study, but not in their ranking data, 28 whereas other studies (Alwin and Krosnick, 1985) …nd ties in their ranking data. Although no directions 14 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a 1 were given to respondents about the use of ties, we would have expected to get more respondents using ties, 2 but it seems that they have carefully distinguished between alternatives for the ranking and for the rating 3 questions. Thus, it o¤ers rather some evidence that the elicitation task was not a¤ected by fatigue. 4 Secondly, out of the 521 cases, 20 respondents (about 3.8% of the respondents) gave inconsistent answers 5 in the sense that their ratings (valuation question 2), recoded to ranks, were not the same as their full- 6 rankings (valuation question 1). Three of these 20 ’inconsistent’cases present ties, as explained just above. 7 The rest of these ’inconsistent’cases exhibit di¤erences in the ranks given to the less-preferred alternatives, 8 mainly for ranks deeper than 315 . It should be noted that the 26 respondents who chose further the opt-out 9 item in the valuation question 3 all gave consistent recoded ratings and full-ranking, so that we can infer 10 that their opt-out choice was not some kind of protest response. 11 Thirdly, the sub-ranking (valuation question 3) is found fully consistent with the recoded ratings. This 12 gives us strong evidence, coupled with the previous …ndings, that the sub-ranking derived from the valuation 13 question 3 provides accurate data in accordance with the actual ranking capabilities and the underlying 14 preferences of the individuals. Table 4 presents the distribution of the ranking depth in the sample, that is 15 the ranking capability stated by the individuals when they perform the third ranking task. For example, if 16 an individual stated, in response to ranking task 3, that only the …rst and second cards were acceptable to 17 her/him, then her/his ranking depth is 2. Notice that Section 5.3 o¤ers another interpretation of ranking 18 task 3, in which the ranking of the status quo is explicitly taken into account. Table 4: Ranking Depth Depth Frequency Percentage None 26 4.99 1 134 25.72 2 207 39.73 3 120 23.03 4 28 5.37 5 6 1.15 19 20 From Table 4, two main results are worth noting. First, none of the respondents gave a full rank of the 21 alternatives, that is, agreed to rank the six alternatives. Second, the distribution of the ranking depth over 22 the sample is clearly heterogeneous. Thus choosing the same ranking depth (for example a ranking depth 23 of three, as recommended by Chapman and Staelin, 1982) for each individual over the whole sample will 1 5 Which is in line with the recommendation of Chapman and Staelin (1982) to use the …rst three ranks of rank-ordered data for estimation. 15 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a 1 certainly lead to the inclusion of ’noisy’observations and thus will bias estimations. As we have checked the 2 consistency of the rankings stated by the respondents in response to the three ranking tasks, the next step 3 is to compare the estimation using the full-ranking data and the (observed) accurate sub-ranking data. 4 Since the 26 individuals who chose the opt-out item in the valuation question 3 do not contribute to 5 the likelihood function of the rank-ordered logit model (see, e.g., Allison and Christakis, 1994), they were 6 excluded from our …nal estimation data set (495 respondents). 7 5.2 8 Table 5 …rst presents two basic rank-ordered models. The full-ranking model is estimated from the full- 9 ranking data provided by the respondents. The sub-ranking model is estimated from the sub-ranking data 10 Estimation results which re‡ects the actual heterogeneous ranking capabilities of the respondents. 11 12 First, it should be noted that the attribute F AC1 (impact level of the waste management) was dis- 13 cretized. Curiously, although attributes are often, if not always, coded as categorical variables, they are 14 rarely discretized for estimation purpose. However, discretizing the variable F AC1, which is at the center 15 of our analysis, gives us the opportunity to capture subtle details of individuals preferences. Keeping in 16 mind that the reference category is ’Very High Degradation’the signs of the coe¢ cients associated with the 17 F AC1 items are positive, meaning that individuals do value the reduction of waste externalities. Here a 18 …rst di¤erence appears when comparing the full-ranking model with the sub-ranking model: the coe¢ cient 19 of the ’High Degradation’item of F AC1 is found signi…cant in the full-ranking model whereas it is not in 20 the sub-ranking model16 . Using the sub-ranking data tells us that individuals do not distinguish ’Very High’ 21 and ’High’degradation, whereas the opposite may have been wrongly concluded from the full-ranking data. 22 As expected, the sign of the coe¢ cient of F AC2 is positive and signi…cant: the rank of a card decreases 23 with the time spent sorting and cleaning waste, or, stated di¤erently, individuals value positively the time 24 devoted to sorting and cleaning waste. 25 26 Likewise, the coe¢ cient associated with F AC3 is negative and signi…cant. The change in the waste fee plays its expected role in the ranking of waste management policies. 27 Three individual characteristics were found signi…cant17 in interaction with the attributes’levels. Urban 28 respondents (51% of the sample) tend to be less sensitive to the degradation level (negative and signi…cant 1 6 In both the models, the hypothesis of equality of the coe¢ cients of the various items of F AC1 is strongly rejected: = 262:36 for the full-ranking model and 2 (3) = 196:37 for the sub-ranking model. 1 7 Joint tests where conducted to check the in‡uence of these characteristics on the rankings. Other speci…cations including individual characteristics such as gender, revenue, etc. were tested, without any success. 2 (3) 16 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a Table 5: Rank-ordered logit models Variable Intercept FAC1 a (high) FAC1 (intermediate) FAC1 (low) FAC1 (very low) FAC2 b FAC3 c Urban Dweller FAC1 FAC2 FAC3 Owner FAC1 FAC2 FAC3 Full-Ranking Model Coe¢ cient p-value (standard-error) 1.250 (0.116) 2.397 (0.149) 3.260 (0.187) 4.038 (0.227) 0.188 (0.036) -0.490 (0.038) 0.000 0.000 0.000 0.000 0.000 0.000 -0.064 (0.064) -0.114 (0.042) 0.085 (0.044) 0.315 0.147 (0.064) 0.004 (0.043) -0.010 (0.044) 0.022 0.008 0.052 0.909 0.821 Know ledge of the waste fee FAC1 Sub-Ranking Model Coe¢ cient p-value (standard-error) 0.155 (0.177) 0.679 (0.182) 1.531 (0.207) 2.762 (0.250) 0.314 (0.056) -0.803 (0.063) 0.000 0.000 0.000 0.000 0.000 -0.153 (0.066) -0.121 (0.066) 0.233 (0.069) 0.025 0.187 (0.068) -0.054 (0.066) 0.009 (0.068) 0.006 -0.090 0.246 -0.102 (0.077) (0.081) FAC2 -0.019 0.710 -0.058 (0.051) (0.077) FAC3 0.082 0.130 0.251 (0.054) (0.082) Cases 495 Cases LogLik -2,258.65 LogLik LR 2(15) 1,996.15 LR 2(15) a Pollution impact (level) - reference category is ’Very High Degradation’ b Weekly time on sorting and cleaning waste c Raise in annual waste fee per household 17 0.383 0.070 0.001 0.419 0.891 0.209 0.449 0.002 495 -1,188.95 1,067.95 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a 1 coe¢ cient of attribute F AC1), less sensitive to the time burden (negative and signi…cant coe¢ cient of 2 attribute F AC2), but also less sensitive to the monetary incentive (which could be interpreted as a revenue 3 e¤ect). Again, the comparison between the full-ranking model and the sub-ranking model shows that the 4 …rst e¤ect signi…cantly holds only for the second model. The result that urban respondents tend to be less 5 sensitive to the time burden of sorting and cleaning waste receives no straightforward interpretation: it may 6 mean that urban respondents value less the time devoted to waste than rural respondents, probably because 7 waste collection services are better designed in urban areas in Corsica (collection schedules, extra pick-ups, 8 etc.). 9 Homeownership (60% of the respondents own their home) in‡uences positively the perception of the 10 degradation level. Homeowners certainly pay more attention to the reduction of waste externalities because 11 these are known to impact negatively the real estate market and thus the value of their home. 12 Finally respondents who state that they know their actual waste fee (16% of the sample) do also react 13 more strongly to the monetary incentive. This result holds only for the sub-ranking model which shows 14 again that taking into account the heterogeneous ranking capabilities leads to di¤erent results. Thus, before 15 calculating welfare variations, we …rst need to address the following question: do the estimates from both 16 the models di¤er? 17 To answer this question, we …rst perform a Hausman test to compare the full-ranking and the sub-ranking 18 models: under the null hypothesis (H0: choosing the second best alternative is determined with the same 19 decision weight as the best, etc.), the full-ranking estimator is e¢ cient and consistent and the sub-ranking 20 estimator is consistent, but uses less information and is not e¢ cient. This Hausman test clearly rejects the 21 null-hypothesis ( 22 in the coe¢ cients. 2 (15) = 6716:16) calling for further investigation of the sources of systematic di¤erences 23 As stated above, the scaled rank-ordered logit model, both in constrained and unconstrained form, o¤ers 24 us a powerful tool to investigate the e¤ects of heterogeneous ranking capabilities. We recall (see above) that 25 the scaled rank-ordered logit model assumes that the scale parameter is written as: i = exp( 2 =2 + i + 0 xi ) (8) 26 We now have to speci…cy how the observed heterogeneity is captured, i.e., the variables included in vector 27 xi . Given that we focus on the ranking capability issue, that we want to assess rank order e¤ects, and to be 28 29 in line with the seminal work of Hausman and Ruud (1987), as well with the work of Ben Akiva et al. (1992), JX i 1 we set 0 xi = k where each parameter k is associated with a dummy coded indicator-function (Scarpa k=1 18 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a 1 et al., 2011) that denotes that the choice is made from choice set k in the exploded logit representation of 2 the rank-ordered logit model and Ji = maxi Ji . For example, the full-ranking data is exploded into …ve 3 choice sets, choice set 1 corresponding to the most prefered choice amongst the six alternatives, choice set 4 2 corresponding to the most prefered choice amongst the …ve remaining choices, etc. Obviously one of the 5 k has to be normalized to zero; again in line with Hausman and Ruud (1987), we set 6 k captures the rank e¤ect of rank k, on the individual scale parameter 7 i. Ji 1 = 0. Thus, Given our speci…cation, and putting aside the unobserved heterogeneity ( ) for the sake of clarity, the contribution of rank 1 choices to 8 i 9 Ji is simply exp( 1 ), the contribution of rank 2 choices to 1 choices to i is exp( Ji 1 ). i is exp( 2 ) ... and the contribution of rank If the top choices are more precise (rank 1 choices are more precise 10 than rank 2 choices, which are more precise than rank 3 choices, etc.), as the scale parameter is inversely 11 related to the error variance, we expect a scale parameter decreasing in the rank, i.e., given our speci…cation, 12 1 > 2 > ::: > Ji 1 = 0 (Hausman and Ruud, 1987, p. 98-99). 13 At this point of our analysis, we can re…ne our initial question regarding systematic di¤erences in the 14 estimates. First, do both the full-ranking and the sub-ranking models exhibit rank order e¤ects? Second, 15 do both the full-ranking and the sub-ranking models exhibit observed and unobserved heterogeneity. To answer these questions, we estimate two models: a heteroscedastic rank-ordered logit model (H-ROL; 16 17 imposing = 0) and a scaled rank-ordered logit model (S-ROL)18 . 18 Estimates of the H-ROL models are reported in Table 6. Estimates are qualitatively the same as those 19 in Table 5. A likelihood ratio test for null-hypothesis of no heteroscedasticity is reported at the bottom of 20 the Table 6. It shows that the full-ranking data are found to be heteroscedastic, whereas the sub-ranking 21 data are not ( 22 k ’s 23 1 2 (4) = 131:01 and 2 (3) = 6:79, respectively). This result is consistent with the fact that the are signi…cant in the full-ranking model, but are not signi…cant in the sub-ranking model. As expected, > 2 > ::: > 5 = 0 which shows that when respondents are forced to rank all the alternatives, they do it 24 less and less precisely. On the contrary, when we estimate the model on the sub-ranking data, taking into 25 account the heterogeneous ranking capabilities of the individuals, allowing them to choose the alternatives 26 that they really want to rank, we do not …nd any rank e¤ects. From one choice to another, the coe¢ cients 27 are found to be stable. 28 29 The results from the S-ROL models (Table 7) supports further this striking result. Again the results are qualitatively the same as the results from the basic rank-ordered logit (ROL) and H-ROL models. 1 8 The estimations were run using NLOGIT 5 (Greene, 2013). 50 Halton draws when estimating the S-ROL models. 19 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a Table 6: Heteroscedastic Rank-ordered logit models Variable Intercept FAC1 a (high) FAC1 (intermediate) FAC1 (low) FAC1 (very low) FAC2 b FAC3 c Urban Dweller FAC1 FAC2 FAC3 Owner FAC1 FAC2 FAC3 Know ledge of the waste fee FAC1 Full-Ranking Model Coe¢ cient p-value (standard-error) 2.500 (0.280) 5.383 (0.564) 7.591 (0.776) 9.326 (0.958) 0.415 (0.079) -0.975 (0.110) 0.000 0.000 0.000 0.000 0.000 0.000 -0.147 (0.153) -0.291 (0.088) 0.211 (0.093) 0.339 0.411 (0.158) 0.027 (0.084) -0.098 (0.093) 0.009 -0.268 (0.186) -0.032 (0.096) 0.176 (0.112) 0.001 0.024 0.742 0.293 0.149 Sub-Ranking Model Coe¢ cient p-value (standard-error) 0.170 (0.199) 0.760 (0.284) 1.746 (0.518) 3.086 (0.844) 0.342 (0.104) -0.876 (0.233) 0.394 0.008 0.001 0.000 0.001 0.000 -0.181 (0.090) -0.127 (0.079) 0.259 (0.099) 0.044 0.214 (0.091) -0.054 (0.073) 0.014 (0.076) 0.020 0.111 0.009 0.459 0.848 -0.108 (0.094) -0.060 (0.085) 0.267 (0.112) 0.250 1.142 0.000 0.136 (0.112) (0.264) 1.096 0.000 0.149 2 (0.114) (0.267) 0.655 0.000 -0.184 3 (0.111) (0.276) 0.499 0.000 4 (0.115) Cases 495 Cases LogLik -2,193.15 LogLik LR 2(4) 131.01 LR 2(3) a Pollution impact (level) - reference category is ’Very High Degradation’ b Weekly time on sorting and cleaning waste c Raise in annual waste fee per household 0.607 FAC2 FAC3 0.738 0.117 0.483 0.017 Observed heterogeneity 1 20 0.577 0.504 495 -1,185.56 6.79 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a Table 7: Scaled Rank-ordered logit models Variable Intercept FAC1 a (high) FAC1 (intermediate) FAC1 (low) FAC1 (very low) FAC2 b FAC3 c Urban Dweller FAC1 FAC2 FAC3 Owner FAC1 FAC2 FAC3 Know ledge of the waste fee FAC1 Full-Ranking Model Coe¢ cient p-value (standard-error) 4.597 (0.749) 9.768 (1.539) 13.571 (2.162) 16.356 (2.670) 0.675 (0.145) -1.536 (0.260) 0.076 (0.435) -0.560 (0.155) 0.332 (0.174) 0.623 (0.439) 0.064 (0.127) -0.114 (0.165) 0.000 0.000 0.000 0.000 0.000 0.000 0.861 0.000 0.056 0.156 0.614 0.489 Sub-Ranking Model Coe¢ cient p-value (standard-error) 0.146 (0.148) 0.568 (0.169) 1.259 (0.236) 2.274 (0.348) 0.254 (0.056) -0.665 (0.098) 0.325 0.001 0.000 0.000 0.000 0.000 -0.131 (0.058) -0.100 (0.056) 0.205 (0.060) 0.025 0.159 (0.058) -0.047 (0.055) 0.011 (0.057) 0.007 0.074 0.001 0.394 0.837 -0.080 (0.068) -0.040 (0.064) 0.213 (0.071) 0.243 -0.350 (0.164) -0.170 (0.143) -0.241 (0.145) - 0.033 -0.087 0.716 0.000 (0.203) (0.064) Cases 495 Cases LogLik -2,150.92 LogLik a Pollution impact (level) - reference category is ’Very High Degradation’ b Weekly time on sorting and cleaning waste c Raise in annual waste fee per household 0.667 FAC2 FAC3 -0.624 (0.529) -0.084 (0.139) 0.345 (0.186) 0.238 1.534 (0.153) 1.420 (0.154) 0.694 (0.147) 0.425 (0.147) 0.000 0.544 0.064 0.530 0.003 Observed heterogeneity 1 2 3 4 0.000 0.000 0.004 0.235 0.097 - Unobserved heterogeneity 21 495 -1,186.16 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a Table 8: Information criteria Full-Ranking Models ROL H-ROL N. of parameters 15 19 LogLik -2258 -2193 BIC 4634 4534 CAIC 4649 4553 1 2 Sub-Ranking Models ROL H-ROL S-ROL 15 18 19 -1188 -1185 -1186 2482 2496 2504 2497 2514 2523 S-ROL 20 -2150 4458 4478 The S-ROL full-ranking model shows strong evidence of both observed and unobserved heterogeneity: the k ’s are still signi…cant, following the expected pattern, and the parameter, which captures the unobserved 3 heterogeneity, is highly signi…cant. As for the H-ROL model, the estimation of the S-ROL sub-ranking model 4 does not reveal any scale heterogeneity stemming from the data. 5 As Fiebig et al. (2010) recommend it, we use information criteria (Bayesian (BIC) and Consistent Akaike 6 (CAIC)) to compare the models estimated on the same data set (Table 8). According to the BIC and the 7 CAIC, the S-ROL model clearly …ts better the full-ranking data. According to the same criteria, however, the 8 basic ROL model performs better than its heteroscedastic counterparts when it comes with the sub-ranking 9 data. 10 Taken together these results allow us to calculate welfare changes. 11 As it is well known from the literature, measures of compensating variation can be simply derived from 12 multinomial or rank-ordered logit model. Turning back to the deterministic component of the utility equation: Vij = 13 zj + 0 wij (9) The compensating variation associated with a change in an attribute k is given by: CV 14 0 where e k = k zk + k wik e + e wie (10) is the coe¢ cient of the monetary incentive/attribute (change in the waste fee), 15 coe¢ cient of attribute k, 16 involving attribute k and 17 level of attribute k, 18 e and 19 attribute. e zk is the change in the level of attribute k, k k is the is a vector of interaction coe¢ cients wik is the change in the interaction variables consistent with the change in the is a vector of interaction coe¢ cients involving the monetary attribute F AC3 denoted wie is the change in the interaction variables consistent with the change in the level of the monetary 20 As the information criteria led us to select the S-ROL full-ranking model and the ROL sub-ranking 21 model, we provide in Table 9 welfare variations calculated only from these models. As written above, the 22 discretization of the F AC1 variable permits the calculation of detailed WTP for the reduction of waste 22 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a Table 9: Compensating Variation - annual WTP (e)a Full-Ranking Model (S-ROL) Sub-Ranking Model (ROL) High Degradation e2.99 [2.50,3.47] (p-value: 0.000) e0.19 [-0.23,0.62] (p-value: 0.381) e6.35 [5.48,7.22] (p-value: 0.000) e0.84 [0.40,1.28] (p-value: 0.000) e8.83 [7.68,9.97] (p-value: 0.000) e1.90 [1.38,2.42] (p-value: 0.000) e10.64 [9.25,12.03] (p-value: 0.000) e3.43 [2.78,4.08] (p-value: 0.000) a For a change in environmental degradation compared to the reference level (Very High Degradation). 95% con…dence bounds are provided in brackets (delta method). p-values refer to the point estimates. 1 externalities (environmental and health impacts). Point estimates reported in Table 9 (with no interaction 2 e¤ects) for the full-ranking model and the sub-ranking model di¤er in magnitude and estimation on the 3 sub-ranking data show that individuals are not willing to pay for a ’High Degradation’compared to a ’Very 4 High Degradation’. From these data, re‡ecting actual ranking capabilities of the respondents, signi…cant 5 and positive WTP are only found for waste management options that really depart from negative impacts. 6 Beyond the point estimates, careful attention has to be paid to the con…dence intervals. Again, comparing 7 con…dence intervals obtained with both the models, shows that these con…dence intervals do not overlap thus 8 con…rming strong di¤erences between the S-ROL full-ranking model and the ROL sub-ranking model. As 9 the ROL sub-ranking model gives more conservative welfare measures and also as we have shown that there 10 is no heteroscedasticity in the data when the heterogeneous ranking capability of the respondents is taken 11 into account, we suggest that the welfare measures calculated from the ROL sub-ranking model are more 12 reliable than those calculated from the S-ROL full-ranking model. However, one could argue that ranking 13 task 3 could be interpreted di¤erently than the way we do it in Section 4.2. 14 5.3 15 So far, and in line with what can be found in the seminal as well as in the recent literature (Chapman and 16 Staelin, 1982; Fok et al., 2012), we have indeed considered that unranked alternatives are less preferred than 17 the ranked alternatives, without making any assumption regarding the ordering of the unranked alternatives. 18 What if we assume, instead, that ranking task 3 implies that the status quo is actually ranked immediately 19 after the last ranked alternative derived from ranking task 3? For example, if an individual states a ranking 20 depth of 2, then the status quo is assumed to be ranked 3, more preferred than the remaining unranked An alternative speci…cation 23 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a 1 alternatives19 . 2 Testing this alternative speci…cation requires …rst to recall that the status quo was described, during 3 the administration of the questionnaire, in terms of the following levels of the three attributes: Very high 4 Degradation (F AC1), no change in the time devoted to recycling (F AC2), and no change in the waste fee 5 (F AC3). Notice that the questionnaire included a question regarding the actual time weekly devoted to 6 recycling by the respondents (about 41% of the respondents stated that they did not devote anytime to 7 recycling). As the status quo is now explicitly considered, we also have to introduce an alternative speci…c 8 constant (ASC) which takes a value of one when the status quo is chosen and a value of 0 otherwise. The 9 ASC is usually introduced, in the choice experiment literature, to control for a potential status quo bias (see 10 Crastes et al., 2014). More generally, the ASC will capture intangible aspects of the status quo, including, 11 when relevant, protest behavior, design e¤ects, fatigue e¤ects, etc. (see Fiebig et al., 2010 for an insightful 12 discussion on ASCc). Then we follow the same econometric strategy as in Section 5.2, estimating a basic 13 ROL model, a H-ROL model and a S-ROL model on the alternative sub-ranking data. Table 10 compares the 14 initial sub-ranking model with the alternative sub-ranking model. Estimates are quite similar, except that 15 the ASC coe¢ cient is found highly signi…cant and positive, which is not surprising given that the assumption 16 regarding the ranking of the status quo weighs heavily in favor of the status quo. Indeed, referring back to 17 Table 4 above, 134 individuals are now considered to rank the status quo 2, 207 to rank it 3 and so on. We 18 should nonetheless keep in mind that only 26 respondents actually chose the opt-out option. 19 Table 11 reports the estimates of the H-ROL and S-ROL models on the alternative sub-ranking data. 20 Again, and in both models, the ASC coe¢ cient is highly signi…cant and positive, capturing the e¤ect of our 21 assumption regarding the ranking of the status quo. Estimation of the H-ROL shows that, contrary to the 22 sub-ranking data, the alternative sub-ranking data are clearly heteroscedastic: a likelihood ratio test leads 23 to the rejection of the null-hypothesis of no heteroscedasticity ( 24 and positive. 25 However, the k ’s 2 (4) = 84:46), whereas the do not exhibit a clear pattern: a one-sided test of 2 (1) > 1 gives a p-value of 0.994, 2 (1) is 27 to these test results, second choices would be more precise than other choices, …rst and third choices would 28 be similarly precise, and fourth choices would be the less precise. But, given that the alternative sub-ranking 29 data set results from an assumption regarding the ranking of the status quo, and does not stem from an 30 actual behaviour of the respondents, such an interpretation remains quite hazardous. 4 ( 1 not statistically di¤erent from 31 = 1:02) and is statistically di¤erent from are signi…cant 26 3 ( 2 k ’s = 10:55). According Also, the S-ROL model was found to be unstable: we were not able to estimate a model with both 1 9 We thank the Editor for suggesting us this alternative interpretation. 24 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a Table 10: Rank-ordered logit models Variable ASC Intercept FAC1 a (high) FAC1 (intermediate) FAC1 (low) FAC1 (very low) FAC2 b FAC3 c Urban Dweller FAC1 FAC2 FAC3 Owner FAC1 FAC2 FAC3 Sub-Ranking Model Coe¢ cient p-value (standard-error) - 0.155 (0.177) 0.679 (0.182) 1.531 (0.207) 2.762 (0.250) 0.314 (0.056) -0.803 (0.063) 0.383 0.000 0.000 0.000 0.000 0.000 -0.153 (0.066) -0.121 (0.066) 0.233 (0.069) 0.025 0.187 (0.068) -0.054 (0.066) 0.009 (0.068) 0.006 0.070 0.001 0.419 0.891 Know ledge of the waste fee FAC1 Alternative Sub-Ranking Model Coe¢ cient p-value (standard-error) 1.688 0.000 (0.135) 0.284 (0.172) 0.599 (0.168) 1.705 (0.178) 2.971 (0.201) 0.242 (0.048) -0.804 (0.056) 0.000 0.000 0.000 0.000 0.000 -0.083 (0.043) -0.066 (0.054) 0.224 (0.060) 0.057 0.059 (0.044) -0.059 (0.054) -0.003 (0.061) 0.174 -0.102 0.209 -0.032 (0.081) (0.053) FAC2 -0.058 0.449 -0.020 (0.077) (0.067) FAC3 0.251 0.002 0.176 (0.082) (0.079) Cases 495 Cases LogLik -1,188.95 LogLik LR 2(15) 1,067.95 LR 2(16) a Pollution impact (level) - reference category is ’Very High Degradation’ b Weekly time on sorting and cleaning waste c Raise in annual waste fee per household 25 0.099 0.222 0.000 0.279 0.961 0.548 0.759 0.026 495 -1,747.41 1,258.76 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a Table 11: Alternative Heteroscedastic and Scaled Rank-ordered logit modelsd Variable ASC Intercept FAC1 a (high) FAC1 (intermediate) FAC1 (low) FAC1 (very low) FAC2 b FAC3 c Urban Dweller FAC1 FAC2 FAC3 Owner FAC1 FAC2 FAC3 Know ledge of the waste fee FAC1 FAC2 FAC3 H-ROL Coe¢ cient p-value (standard-error) 5.360 0.000 (0.720) 0.457 (0.487) 1.337 (0.467) 4.000 (0.583) 7.213 (0.823) 0.529 (0.128) -1.917 (0.230) 0.348 0.004 0.000 0.000 0.000 0.000 -0.164 (0.097) -0.042 (0.132) 0.536 (0.159) 0.093 0.120 (0.100) -0.179 (0.139) 0.032 (0.152) 0.230 0.747 0.001 0.200 0.830 -0.002 (0.119) 0.187 (0.176) 0.400 (0.211) 0.986 1.139 (0.130) 1.437 (0.164) 1.017 (0.164) 0.666 (0.173) - - S-ROL Coe¢ cient (standard-error) 1.688 (0.135) 0.284 (0.172) 0.599 (0.168) 1.706 (0.178) 2.972 (0.201) 0.242 (0.048) -0.804 (0.056) p-value 0.000 0.098 0.000 0.000 0.000 0.000 0.000 -0.083 (0.043) -0.066 (0.054) 0.225 (0.060) 0.057 0.059 (0.044) -0.059 (0.055) 0.002 (0.061) 0.176 0.22 0.001 0.278 0.962 -0.032 (0.053) -0.021 (0.067) 0.176 (0.079) 0.551 0.000 - - 0.000 - - 0.000 - - 0.000 - - 0.288 0.059 0.757 0.026 Observed heterogeneity 1 2 3 4 Unobserved heterogeneity -0.024 (0.077) Cases 495 Cases LogLik -1,705.18 LogLik a Pollution impact (level) - reference category is ’Very High Degradation’ b Weekly time on sorting and cleaning waste c Raise in annual waste fee per household d As stated in the text, the unconstrained model failed to converge 26 0.753 495 -1,147.36 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a Table 12: Information criteria Alternative Sub-Ranking Models ROL H-ROL S-ROL N. of parameters 16 20 17 LogLik -1747 -1705 -1747 BIC 3612 3557 3619 CAIC 3628 3577 3636 1 observed and unobserved heterogeneity. To be more precise, when and were both left free, the model 2 failed to converge, although various vectors of initial values, more simple speci…cations, etc., were tested. 3 Moreover, a simple S-ROL model does not reveal any scale heterogeneity related to the alternative sub- 4 ranking data (the 5 model …ts better the alternative sub-ranking data (see Table 12). parameter is not signi…cant). Finally, according to BIC and CAIC criteria, the H-ROL 6 At this point, it would be very interesting to assess which of the interpretations of ranking task 3 is the 7 best, using an appropriate test to compare the ROL sub-ranking and the H-ROL alternative sub-ranking 8 models. However, by construction the choice sets associated with the sub-ranking and the alternative sub- 9 ranking data are di¤erent, so that it rules out the possibility to run a test like the Vuong test (Vuong, 1989), 10 or the Clarke test (Clarke, 2007) which can both be used to assess which of two nonnested models is closer 11 to the true model, but which also both require that the models to be compared are …tted using exactly the 12 same set of response values. One relevant way to deal with the interpretation of ranking task 3 would be to 13 modify the survey design and to use a split sample approach, in order to rigorously analyze data obtained 14 from alternative formulations of "ranking task 3 like" questions. Given our survey design, and considering 15 that the sub-ranking data are not found to be heteroscedastic, we advocate that the basic ROL sub-ranking 16 model provides relevant welfare estimates. Allowing the respondents to rank freely is a good way to address 17 the ranking capability issue while at the same time collecting more information by individual. 18 6 19 Since the introduction of the rank-ordered logit model in the 1980s as an appropriate tool for analyzing 20 ranking data, the ranking capability of the respondents has been a source of concerns. Extensions of the 21 rank-ordered logit model continue to be proposed, through heteroscedastic and/or latent class models which 22 seeks to capture the implicit heterogeneous ranking capabilities of the individuals. Conclusions 23 In this article, we propose to address the ranking capability issue through the survey design: appropriate 24 valuation and follow-up questions allow to obtain data which re‡ect the actual heterogeneous ranking capa- 25 bilities of the individuals. Taken together, the results of our analysis suggest that the scale heterogeneity, 27 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a 1 observed and unobserved, vanishes when the respondents are left free to rank a number of alternatives which 2 is stricly in accordance with their heterogeneous ranking capabilities and their preferences. 3 We …nd that WTP estimates on the ’noisy’full-ranking data do di¤er signi…cantly from WTP estimates on 4 the accurate sub-ranking data: for instance, total WTP estimations (based on 129,000 Corsican households, 5 INSEE, 2009) for a very low impact are e1,372,560 and e442,470 respectively for full-ranking (S-ROL model) 6 and sub-ranking data (ROL model). As the acceptability of policy measures is also of great concern to public 7 decision makers, the need for reliable information is obvious. 8 Regarding waste management on the ’Island of Beauty’(Corsica), we …nd that people are not satis…ed 9 with the status quo. Homeowners and urban dwellers are found to be more willing to pay for the reduction 10 of waste externalities. We also …nd that individuals who are aware of the waste fee are more likely to accept 11 a rise in the waste fee, and hence show a greater willingness-to-pay for the reduction of waste externalities. 12 Although only 16% of the respondents stated that they knew how much they pay for waste management, 13 this …nding suggests that the fee is perceived as a legitimate tool for covering waste management costs. 14 According to our study, a rise of about 10% of the actual waste fee should be acceptable. 15 To conclude, the empirical results presented in this article may be data speci…c. However, the pro- 16 posed methodology is relevant to any ranking data and could be used to assess the advantages of recent 17 developments in the choice experiment literature, such as the best-worst preference elicitation approach. 18 19 20 21 22 23 24 25 26 27 28 29 30 References Allison, P. D., Christakis, N., 1994. Logit models for sets of ranked items. In Vol. 24 of Sociological Methodology, ed. P. V. Marsden, Oxford: Blackwell, 123–126. Alriksson, S., Öberg, T., 2008. Conjoint analysis for environmental evaluation. Environmental Science and Pollution Research. 15 (3): 244-257. Alwin, D. F., Krosnick, J. A. , 1985. The Measurement of Values in Surveys: A Comparison of Ratings and Rankings. The Public Opinion Quarterly. 49 (4): 535-552. Baarsma, B. E., 2003. The Valuation of the IJmeer Nature Reserve using Conjoint Analysis. Environmental and Resource Economics. 25: 343–356. Beggs S., Cardel S., Hausman J., 1981. Assessing the potential demand for electric cars. Journal of Econometrics. 16:1-19. Bergmann, A., Colombo, S., Hanley, N., 2008. Rural versus urban preferences for renewable energy developments. Ecological Economics. 65(3): 616-625. 28 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a 1 2 3 4 5 6 Ben Akiva, M., Takayuki, M., Fumiaki, S., 1992. Analysing of the Reliability of Preference Ranking Data. Journal of Business Research. 24: 149-164. Bre- e, W.S., Rowe, R.D., 2002. Comparing Choice Question Formats for Evaluating Natural Resource Tradeo¤s. Land Economics. 78 (2): 298-314. Boyle, K. J., Homes, T. P., Teisl, M. F., Roe, B., 2001. A Comparison of Conjoint Analysis Response Formats. American Journal of Agricultural Economics. 83(2): 441-454. 7 Bridges, J.F.P.A., Hauber, B., Marshall, D., Lloyd, A., Prosser, L.A., Regier, D.A., Johnson, F.R., Mauskopf, J., 8 2011. Conjoint Analysis Applications in Health— a Checklist: A Report of the ISPOR Good Research Practices for 9 Conjoint Analysis Task Force. Value in Health. 14 (4): 403-413. 10 11 12 13 14 15 Caplan, A.J., Grijalva, T.C., Jakus, P.M., 2002. Waste not or want not? A contingent ranking analysis of curbside waste disposal options. Ecological Economics. 43 (2–3): 185-197. Caplan, A.J., Grijalva, T., Jackson-Smith, D., 2007. Using choice question formats to determine compensable values: The case of a land…ll-siting process. Ecological Economics. 60 (4): 834-846. Chapman, R. G, Staelin, R. , 1982. Exploiting rank ordered choice set data within the stochastic utility model. Journal of Marketing Research. 19: 288–301. 16 Clarke, K.A., 2007. A Simple Distribution-Free Test for Nonnested Hypotheses, Political Analysis. 15:3: 347-363. 17 Crastes, R., Beaumais, O., Arkoun, O., Laroutis, D., Mahieu P.-A., Rulleau, B., Hassani-Taibi, S., Barbu, V.S., 18 Gaillard, D., 2014. Erosive runo¤ events in the European Union: Using discrete choice experiment to assess the 19 bene…ts of integrated management policies when preferences are heterogeneous. Ecological Economics. 102: 105-112. 20 Caussade, S., Ortúzar, J. D., Rizzi, L. I., Hensher, D. A., 2005. Assessing the In‡uence of Design Dimensions on 21 22 23 24 25 26 27 28 29 Stated Choice Experiment Estimates.Transportation Research Part B. 39: 621–640. Croissant Y., 2012. Estimation of multinomial logit models in R: the mlogit package. Vienna: R Foundation for Statistical Computing. Fok D., Paap R., van Dijk B., 2012. A Rank-Ordered Logit Model with Unobserved Heterogeneity in Ranking Capabilities. Journal of Applied Econometrics. 27(5): 831-846. Fiebig D.G., Keane M.P., Louviere J.J., Wasi N., 2010. The generalized multinomial logit model: Accounting for scale and coe¢ cient heterogeneity. Marketing Science. 29: 393–421. Garrod, G., Willis, K., 1998. Estimating lost amenity due to land…ll waste disposal. Resources, Conservation and Recycling. 22: 83–95. 30 Greene W.H., 2013. Nlogit 5. Econometric Software, New York and Sydney. 31 Greene W.H., Hensher D.A., 2010. Does scale heterogeneity across individuals matter? An empirical assessment 32 of alternative logit models. Transportation. 37: 413-428. 29 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Guikema, S.D., 2005. An estimation of the social costs of land…ll siting using a choice experiment. Waste Management. 25(3): 331-333. Hausman J. A., Ruud P. A., 1987. Specifying and testing econometric models for rank-ordered data. Journal of Econometrics 34: 83–104. Hoyos, D., 2010. The state of the art of environmental valuation with discrete choice experiments. Ecological Economics. 69(8): 1595-1603. INSEE, 2009. Tableaux de l’economie Corse. Paris: National Institute of Statistics and Economic Studies. (In french) Jamal, O., 2006. Economic Valuation of Household Preference for Solid Waste Management in Malaysia: A Choice Modeling Approach. International Journal of Management Studies. 13(1): 1-23. Jin, J., Wang, Z., Ran, S., 2006. Comparison of contingent valuation and choice experiment in solid waste management programs in Macao. Ecological Economics. 57(3): 430-441. Karousakis, K., Birol, E., 2008. Investigating household preferences for kerbside recycling services in London: a choice experiment approach. Journal of Environmental Management. 88(4): 1099-1108. Louviere, J.J., Hensher, D., Swait, J., Adamowicz, W., 2000. Stated Choice Methods: Analysis and Applications. Cambridge University Press, Cambridge. Nakatani, J., Aramaki, T., Hanaki, K., 2008. Evaluating source separation of plastics waste using conjoint analysis. Waste Management. 28: 2393-2402. Ophem, H. van, Stam, P., van Praag, B. M. S., 1999. Multichoice Logit: Modelling Incomplete Preference Rankings of Classical Concerts. American Journal of Business and Economic Statistics. 17 (1): 117–128. Pek, C.-K., Jamal, O., 2011. A choice experiment analysis for solid waste disposal option: A case study in Malaysia. Journal of Environmental Management. 92 (11): 2993-3001. PIEDMA, 2002. Plan Interdépartemental d’Elimination des Déchets Ménagers et Assimilés approuvé par arrêté interpréfectoral n.02-919 en date du 17 décembre 2002, 260p. (In french) Sakata, Y., 2007. A choice experiment of the residential preference of waste management services –The example of Kagoshima city, Japan. Waste Management. 27 (5): 639–644. Sasao, T., 2004a. An estimation of the social costs of land…ll siting using a choice experiment. Waste Management. 24 (8): 753-762. Sasao, T., 2004b. Analysis of the socioeconomic impact of land…ll siting considering regional factors. Environmental Economics and Policy Studies. 6 (2): 147-175. 31 Scarpa, R., Notaro S., Louviere J.J., Ra¤aelli, R., 2011. Exploring Scale E¤ects of Best/Worst Rank Ordered 32 Choice Data to Estimate Bene…ts of Tourism in Alpine Grazing Commons. American Journal of Agricultural Eco- 30 W h y N o t A llo w In d iv id u a ls t o R a n k Fr e e ly ? A S c a le d R a n k -O r d e r e d L o g it A p p r o a ch A p p lie d t o W a s t e M a n a g e m e n t in C o r s ic a 1 2 3 4 5 nomics. 93(3): 813–828. Street D.J., Burgess L., 2007. The Construction of Optimal Stated Choice Experiments: Theory and Methods. New York: Wiley. SYVADEC, 2009. Gestion durable des déchets ménagers et assimilés de Corse - Orientations techniques, Rapport d’étape 4 mai 2009. SYndicat de Valorisation des DEchets ménagers de Corse, 16p. (In french) 6 Vuong, Q., 1989, Likelihood ratio tests for model selection and non-nested hypotheses, Econometrica. 57: 307-334. 7 Wagner, J., 2005. An estimation of the social costs of land…ll siting using a choice experiment. Waste Management. 8 9 10 25(3): 329-330. Yoo, H., Doiron D., 2013. The use of alternative preference elicitation methods in complex discrete choice experiments. Journal of Health Economics. 32: 1166-1179. 31