Embedding Tree Computations
into the RAW Chip
by
Adrian Mihail Soviani
Submitted to the Department of Electrical Engineering
and Computer Science
in Partial Fulfillment of the Requirements for the Degree of
Master of Engineering in Electrical Engineering and Computer Science
at the
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
February 2002
© 2002 Adrian M. Soviani. All rights reserved.
The author hereby grants to M.I.T. permission to reproduce and
distribute publicly paper and electronic copies of this thesis
and to grant others the right to do so.
MASSAC HUSETTS INSTITUTE
OF TECHNOLOGY
JUL 3 1 2002
LIBRARIES
........
....................
Department of Electrical Engineering
and Computer Science
February 1, 2002
A
A uthor .
..................
Anant Agarwal
Associate Director,_MIT Laboratory for Computer Science
Certified by......
Thspis Supervisor
Accepted by ..........
..
... .- ...
.....
Arthur C. Smith
Chairman, Department Committee on Graduate Theses
2
Embedding Tree Computations into the RAW Chip
by
Adrian Mihail Soviani
Submitted to the Department of Electrical Engineering and Computer Science
February 1, 2002
in Partial Fulfillment of the Requirements for the Degree of
Master of Engineering in Electrical Engineering and Computer Science
Abstract
The main goal of this thesis is to provide coarse grain parallelism for the RAW chip.
Coarse grain parallelism can be expressed by using instrumented function calls which
are queued and executed on other processors. Function calls are reassigned to adjacent
processors only. Subsequently, a computation tree is dynamically embedded into the
processor mesh (Chapter 3).
A C library interface was developed to provide this mechanism: applications can
spawn function calls, and wait at synchronization points (Chapter 4). Two implementations of the spawn interface were built as part of the thesis project: i) a system
that runs on the RAW chip using interrupting messages to implement work scheduling
and synchronization (Chapter 5); ii) a generic spawn library based on POSIX threads
that uses shared memory and locking (Chapter 6).
Embedding computation trees into 2D processor meshes proved to be successful
for a selection of tree structures and mesh sizes. Two models were used for testing:
a perfect binary tree, and a Fibonacci tree.
On RAW both benchmarks produced similar speedups: 3.5 - 4 for 2 x 2; 7 - 8
for 3 x 3 when parallelism exceeds 2' - 29; 12 - 13 for 4 x 4 when P > 29 - 210.
These numbers varied as a function of mesh size, problem size, work granularity, and
system settings - spawn stack size, work scheduler policy. System overhead becomes
negligible once granularity is sufficiently large.
On the other hand, simulations using the POSIX system showed speedups of
35 - 50 for 8 x 8, 20 - 30 for 6 x 6, and 95 - 110 for 12 x 12. Empirically, we can
conclude that the spawn framework is efficient for large processor meshes.
Thesis Supervisor: Anant Agarwal
Title: Associate Director, MIT Laboratory for Computer Science
3
4
Acknowledgments
I would like to thank Prof. Anant Agarwal for his support and guidance throughout
all stages of my research. I would also like to thank Walter Lee for his advice and
long discussions that provided me invaluable feedback on the project. Finally I would
like to thank the people from the Computer Architecture Group who developed the
tools needed to build and benchmark the system.
5
6
Contents
1
Introduction
1.1
15
Thesis Organization.
. . . . . . . . . . . . . . . . . . . . . . . . . . .
2 The RAW Project
2.1
2.2
3
Design Overview
16
19
. . . . . . . . . . . . . . . . . . . . . . . . . . . . .
19
2.1.1
Static and Dynamic Networks . . . . . . . . . . . . . . . . . .
19
2.1.2
Deadlocks . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
20
2.1.3
I/O Ports . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
21
2.1.4
Memory . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
22
Instruction Level Parallelism . . . . . . . . . . . . . . . . . . . . . . .
22
2.2.1
23
Benchmarks . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Coarse Grain Parallelism
25
3.1
C Dialects . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
25
3.2
Computation Structures . . . . . . . . . . . . . . . . . . . . . . . . .
26
3.2.1
. . . . . . . . . . . . . . . . . . . . . . . .
26
Work Scheduler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
27
3.3.1
Master-Slave Model . . . . . . . . . . . . . . . . . . . . . . . .
28
3.3.2
Randomized Work Stealing
. . . . . . . . . . . . . . . . . . .
28
3.3.3
Randomized Tree Embedding
. . . . . . . . . . . . . . . . . .
28
Design Alternatives . . . . . . . . . . . . . . . . . . . . . . . . . . . .
29
3.4.1
Load Balancing . . . . . . . . . . . . . . . . . . . . . . . . . .
29
3.4.2
Synchronization . . . . . . . . . . . . . . . . . . . . . . . . . .
30
3.3
3.4
Search Algorithms
7
3.4.3
4
M emory Footprint, Locality . . . . . . . . . . . . . . . . . . .
The Spawn System
31
4.1
Fibonacci Example . . . . . . . . . . . . . . . . . . . . . . . . . . . .
32
4.2
Heap Traversal Embedding . . . . . . . . . . . . . . . . . . . . . . . .
33
4.3
C Interface . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
34
4.4
The Spawn Stacks
. . . . . . . . . . . . . . . . . . . . . . . . . . . .
36
4.5
Shared M emory . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
37
39
5 RAW Spawn
5.1
Interface Specification
. . . . . . . . . . . . . . . . . . . . . . . . . .
39
5.2
Design Description . . . . . . . . . . . . . . . . . . . . . . . . . . . .
40
5.2.1
M essages . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
40
5.2.2
Tile Life Cycle
. . . . . . . . . . . . . . . . . . . . . . . . . .
41
5.2.3
Deadlock Avoidance
. . . . . . . . . . . . . . . . . . . . . . .
42
5.2.4
RAW -Spawn Interface
. . . . . . . . . . . . . . . . . . . . . .
43
5.2.5
Spawn Layer
. . . . . . . . . . . . . . . . . . . . . . . . . . .
43
5.2.6
Efficiency
. . . . . . . . . . . . . . . . . . . . . . . . . . . . .
44
Performance Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . .
45
5.3.1
Tests . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
45
5.3.2
Terminology . . . . . . . . . . . . . . . . . . . . . . . . . . . .
45
5.3.3
Base Case . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
46
5.3.4
Spawn Overheads . . . . . . . . . . . . . . . . . . . . . . . . .
46
5.3.5
Parallelism . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
48
5.3
6
30
53
Pthreads Spawn
. . . . . . . . . . . . . . . . . . . . . . . . . .
53
. . . . . . . . . . . . . . . . . . . . . . . . . . . .
54
. . . . . . . . . . . . . . . . . .
54
. . . . . . . . . . . . . . . . . . . . . . . . . . . . .
55
Performance Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . .
55
6.1
Interface Specification
6.2
Design Description
6.3
6.2.1
M emory and Synchronization
6.2.2
Efficiency
8
7
Conclusion
59
7.1
60
Future W ork . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
A RAW Spawn Interface
61
B RAW Spawn Examples
65
C RAW Spawn Source Code Extracts
69
D RAW Spawn Outputs
79
E Pthreads Spawn Interface
83
F Pthreads Spawn Examples
87
G Pthreads Spawn Outputs
91
9
10
List of Figures
2-1
The RAW processor is a 2D mesh of tiles, each consisting of a main
processor and a programmable switch . . . . . . . . . . . . . . . . . .
20
4-1
Definition of a "spawnable" function: fib . . . . . . . . . . . . . . . .
32
4-2
Processor state history: traversing a 1023 size heap on 4 x 4 . . . . .
33
4-3
Heap traversal: work scheduling on 2 x 2 tiles . . . . . . . . . . . . .
36
5-1
The 3 phases of a RAW tile: stealing, working, and reporting . . . . .
41
11
12
List of Tables
2.1
Speedup benchmark: rawcc vs. Machsuif MIPS compiler . . . . . . .
23
5.1
RAW spawn message types . . . . . . . . . . . . . . . . . . . . . . . .
40
5.2
Average leaf work - Bin . . . . . . . . . . . . . . . . . . . . . . . . . .
46
5.3
Average leaf work - Fib . . . . . . . . . . . . . . . . . . . . . . . . . .
46
5.4
Overhead of spawn function calls - Bin . . . . . . . . . . . . . . . . .
47
5.5
Overhead due to steal requests - Bin .....
47
5.6
Constant cost overheads for P
23 - Bin . . . . . . . . . . . . . . . .
47
5.7
Increasing parallelism for constant granularity - Bin . . . . . . . . . .
49
5.8
Tradeoff between granularity and parallelism - Bin . . . . . . . . . . .
49
5.9
Tradeoff between granularity and parallelism - Fib . . . . . . . . . . .
49
-
5.10 Increasing spawn stack size - Fib
..................
. . . . . . . . . . . . . . . . . . . .
50
5.11 Increasing parallelism and stack size for constant granularity - Fib . .
50
6.1
Speedup for binary heap traversal . . . . . . . . . . . . . . . . . . . .
56
6.2
Speedup for Fibonacci tree traversal . . . . . . . . . . . . . . . . . . .
57
13
14
Chapter 1
Introduction
The RAW architecture represents a simple, highly parallel VLSI architecture that
exposes its low level resources to the software layer. Only a minimal set of mechanisms
are implemented in hardware, greatly decreasing the complexity of the hardware layer.
The software layer - a compiler for instance - has a great flexibility in programming
the parallel chip, possibly allowing for an optimal resource allocation for a specific
task
[1].
The RAW multi-tile chip is somewhat similar to FPGAs; both architectures use
a 2D mesh of programmable cells which are interconnected by fast communication
logic. However, FPGAs have a finer cell granularity, do not include a large distributed
memory, and do not support instruction sequencing.
RAW machines are also similar to Very Long Instruction Word processors. Both
architectures have a large register name space, a distributed register file and multiple
memory ports [7].
Moreover, RAW machines have individual instruction streams
for each tile, providing a greater flexibility. Mapping an algorithm to one of these
architectures is based on exploiting Instruction Level Parallelism by partitioning,
placing, routing and scheduling the code on the 2D tile mesh. Rawcc is an effective
compiler based on this technique [2].
A different approach to exploiting parallelism on the RAW architecture is relying
on coarse grain parallelism. This thesis employs this approach. Some disadvantages
of ILP can be overcome by explicitly partitioning the code and data structures at a
15
higher level. The difficulty of this method consists of finding a good way to expose
coarse grain parallelism.
Solving this problem has been a persisting research issue, and significant progress
has been made. Existing solutions for network connected clusters and shared memory
machines involve designing a language extension and/or a communication library Implicitly Parallel C, Data Parallel C, mpC programming language, MPI, Cilk. A
desirable goal is to model the performance of specific algorithms for a given machine
topology and software layer. Unfortunately, applications need to be modified to use
the above interfaces. Moreover, some systems are not well suited to all classes of
algorithms.
1.1
Thesis Organization
The research supporting my thesis will address a less general problem: executing
computation trees on the RAW chip. Allowing little slack regarding shared memory,
most search problems fall into this category. By narrowing down machine topology
and computation structure we can build a better system than in the general case.
The thesis project attempts to reach this goal by developing the Spawn system.
Spawn exploits coarse grain parallelism inherent to recursive computations: function
calls can be executed concurrently on different processors. Spawn takes advantage of
RAW topology by embedding computation trees into the 2D mesh: function calls are
reassigned to adjacent processors only, paying constant parent-child communication
cost for any mesh size. In order to use Spawn, applications need to add spawn function
calls and synchronization points. These primitives add a significant overhead, which
becomes negligible once work granularity is sufficiently large. Shared memory is not
supported by the system, but it can be used if applications enforce their own policies
suitable to specific hardware.
Load balancing might not be optimal due to work
assignment restrictions.
This thesis is organized in the following main sections: Chapter 2 presents the
RAW chip and its ILP compiler. Exploiting coarse grain parallelism on 2D processor
16
meshes is discussed in Chapter 3.
The Spawn system is described in Chapter 4.
Chapter 5 outlines the RAW implementation of Spawn, and it analyzes experimental
results. The pthreads implementation of Spawn and simulation results are presented
in Chapter 6. Finally, Chapter 7 concludes this thesis, also discussing follow-on work.
17
18
Chapter 2
The RAW Project
2.1
Design Overview
This section outlines the design specification of RAW, the architecture on which the
Spawn system is implemented.
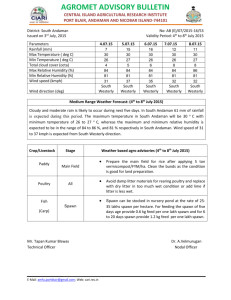
The RAW chip is a 2D mesh of replicated tiles.
Each tile is connected point-to-point to its neighbors via two static and two dynamic
networks. A tile consists of a main MIPS-like processor, a programmable static switch,
and a dynamic router. Main processors have data and instruction memories; switches
have only instruction memory (Fig. 2-1, [1]).
Main processors use an augmented MIPS 2000 instruction set - special registers
access switches or hold configuration settings. Static switches use a subset of the MIPS
instruction set, supporting only routes and control-flow operations. Each individual
main processor and static switch is programmed separately - a n x n RAW machine
requires 2n
2
programs.
Messages passing on the switch don't interrupt the main
processor. However, it is possible to setup interrupt handlers that are triggered by
messages received from the dynamic network.
2.1.1
Static and Dynamic Networks
RAW provides two static networks - cst, cst2, and two dynamic networks - cgn, cmn.
cmn is typically reserved for memory access, while the other networks are available
19
RawpP
Q OQ
O
MEMDMEM
SPC REGS
SM
M
kSWITC
Figure 2-1: The RAW processor is a 2D mesh of tiles, each consisting of a main
processor and a programmable switch
to the user.
Messages sent via static network are routed according to switch programs that
are typically generated at compile time. Each tile processor knows the order and
destination of incoming and outgoing data words; no headers are used by static messages. The static scheduling of messages guarantees infrequent stalls if the switches
are loaded with correct code. However, dynamic messages might delay execution of
static transfers, skewing synchronization of static message scheduling [6].
Messages sent via dynamic network start with a header.
The header contains
destination tile address, funny bits (direction of output port for edge tiles), message
length (up to 31 words), 4 user bits, and source tile address. The header is used for
routing, and it is dropped at destination unless it exits one of the I/O ports. Globally,
routing is based on coordinate order. The message is forwarded from one dynamic
router to the next one, until it reaches its destination. No more than a single tile is
traversed every clock cycle.
2.1.2
Deadlocks
Reading from the switch ports is blocking, as well as writing when buffers are full.
Circular dependencies between tiles can result in deadlock if each processor blocks
either i) reading from the next processor in the chain while no data is available; or
ii) writing to the next processor while buffers are full. For the static network it is the
20
responsibility of the compiler to avoid static scheduling deadlocks. For the dynamic
network there are a few protocols that guarantee deadlock-free communication:
1. Making sure all messages are sinkable. Every processor has to be able to fully
read all received messages without blocking. Using an interrupt handler, incoming messages can be dispatched by storing values, or by copying the entire
message to local memory.
2. Making sure reads and writes don't block indefinitely. Such an example is a
client-server protocol where servers and clients are disjoint sets; client-server
and server-client links are disjoint, too. All clients have only one outstanding
message. After sending a request clients wait for the answer, therefore server
writes will not block indefinitely. Request messages are not blocked by reply
messages, therefore server reads can succeed. One example is partitioning tiles
in North (client) and South (server) tiles. The memory network follows a similar
protocol.
2.1.3
I/O Ports
The 2D processor mesh has a boundary that corresponds to the pins of the chip
package.
These pins are connected to some of the static and dynamic network links that
connect the tiles. Depending on package type, all network links are connected to pins,
or only a few of them can be connected. In the latter case the compiler will take into
consideration the configuration of the chip, and it will not use the network for the
pins that don't exist.
The I/O design has a great flexibility and scalability; in the worst case the communication limitation is 2n for a n x n tile processor. The compiler has direct access
to the I/O interface, an application being able to use the full bandwidth of the pins.
21
2.1.4
Memory
Each main processor has 32 Kb SRAM of data memory, and 32 Kb of instruction
memory. The RAW chip typically has DRAM memory banks connected to the East
and South I/O ports. The RAW tiles access the memory banks to map large memory
spaces from external memory to the small local memory/cache. Reading and writing
memory pages is performed using the memory dynamic network, following the clientserver deadlock protocol. This imposes some restrictions on what memory banks can
be used by each tile.
In software caching mode each tile processor uses the memory network to virtualize
data memory; any access to an invalid address (greater than 32K) returns invalid data.
In hardware caching mode the RAW chip implements a 2-way set associative cache.
Cache misses freeze the tile processor until data is available
[6].
Instruction memory
is always used in software caching mode.
2.2
Instruction Level Parallelism
Both coarse and fine grain parallelism can be exploited on the RAW chip. If Spawn
relies on coarse grain parallelism, the Rawcc compiler uses fine grain parallelism. This
section describes how instruction level parallelism can be exploited on RAW.
The RAW architecture is related to the VLIP machines; both architectures rely
on statically scheduling ILP. If VLIPs have a single flow of control, the RAW machine
allows a different flow of control for each tile. Moreover, the RAW machine provides
a software exposed scalable interconnect between the tiles [2].
Instruction level parallelism is exploited on the RAW chip by partitioning a sequential C
/
Fortran program into sets of instructions that can be executed con-
currently. There are as many code partitions as tiles on the chip. Analyzing data
dependencies, communication cost between partitions is minimized. This operation
corresponds to the following stages of Rawcc: "Initial Code Transformation", "Instruction Partitioner" [2]. These partitions are generated using a greedy clustering
algorithm.
22
The next step is "Global Data Partitioner". Data elements that need to be shared
among basic blocks are clustered in blocks that will be mapped to tiles. The goal
is to preserve data locality: data that is accessed more frequently by a thread is
clustered together. The task of partitioning data is distinct from the task of placing
the partitions.
The previous steps assumed all code and data partitions are connected by a full
interconnect; unfortunately this assumption doesn't hold in practice.
Having the
data and code partitions, the "Data and Instruction Placer" maps one-to-one virtual
data/code tiles to physical tiles. The cost of communication corresponds to the physical properties of the network. A greedy algorithm is used to minimize communication
cost: two tiles are swapped if this operation reduces the overall cost.
The last step represents routing the messages on the 2D network and computing
a global schedule that minimizes the overall runtime: "Communication Code Generator" and "Event Scheduler".
Routing is done using dimension-ordered routing;
this ensures that any scheduling that doesn't deadlock for an event sequence doesn't
deadlock on a scheduling that maintains the same order of events [2]. This is particularly useful if we consider dynamic network events that add delays, such as cache
misses.
2.2.1
Benchmarks
Benchmark
fppp-kernel
btrix
mxm
life
jacobi
N=1
0.48
0.83
0.94
0.94
0.89
N=2
0.68
1.48
1.97
1.71
1.70
N=4
1.36
2.61
3.60
3.00
3.39
N=8
3.01
4.40
6.64
6.64
6.89
N=16
6.02
8.58
12.20
12.66
13.95
Table 2.1: Speedup benchmark: Rawcc vs. Machsuif MIPS compiler
Using the Rawcc compiler proved to be successful for many real applications. The
results presented in Table 2.1 are taken from "Memory Bank Disambiguation using
23
Modulo Unrolling" [1]. Looking at Figure 2.1, we notice speedup is super-linear for
'jacobi", it is almost linear for "life" and matrix multiplication, and it decreases
for "fpp-kernel".
This suggests ILP speedup efficiency varies significantly for each
application type. If the communication pattern is relatively simple for "life" - each
node interacts with its closest neighbors, "fppp-kernel" data dependencies are not
obvious. This added complexity can account for the decrease in speedup.
24
Chapter 3
Coarse Grain Parallelism
Exploiting coarse grain parallelism is an alternative to fine grain parallelism. Typically this is done by defining an extension to a familiar language, or by providing a
communication library. This chapter first outlines a few commonly used parallel systems. Second, it is shown that search algorithms perform well on Spawn, as opposed
to other parallel systems. Third, alternative dynamic work schedulers are analyzed.
Finally, a discussion on design alternatives for Spawn ends this chapter.
3.1
C Dialects
There are many C dialects that provide parallelism on multi-processor machines;
these languages use specialized compilers. Spawn and MPI provide a library interface
instead. Computation can be mapped statically or dynamically to processors.
1. Data Parallel C defines new data types that are shared across all processors,
while the control flow is unique. This language maps well matrix operations,
and more generally scientific computations.
2. Implicitly Parallel C implements a mechanism of locking shared resources and
synchronization based on data structures semantics. IPC is designed for shared
memory systems.
3. The Message Passing Interface offers C primitives for building a network of
25
nodes, and exchanging messages between nodes according to a specified pattern.
Each communication activity is typically performed by all nodes at the same
time, followed by global synchronization.
4. The Cilk programming language adds "spawn" and "sync" points to the control
flow of a program. At spawn points idle processors can be assigned a subproblem, while sync points require all subproblems to be solved before continuing
execution. Cilk is currently supported for shared memory systems; distributed
Cilk was supported earlier. See
[5]
for a detailed manual on the Cilk language.
Semantically the Spawn interface resembles a subset of the Cilk C extension.
3.2
Computation Structures
The Spawn framework doesn't perform the best for all problems. This section shows
why search algorithms are better suited to Spawn, as opposed to other parallel systems.
Computation structures can be analyzed in terms of data-flow or control-flow. A
typical scientific computing problem like Jacobi or matrix multiplication have a simple
data-flow. Such computations can easily be mapped onto n x n processor meshes by
mapping equal slices of data to tiles, and preserving locality of data access. The
communication pattern is predictable, and the amount of work is equal for all tiles.
This type of coarse grain parallelism can be expressed nicely in Data Parallel C, or
using a messaging library like MPI.
There are problems that have an unpredictable data-flow, but which can be described easier using the control-flow paradigm; such an example is searching for the
best move in a chess game, or finding the maximum flow in a graph.
3.2.1
Search Algorithms
This section presents some of the most common search algorithms, showing why a
dynamic work scheduler is required to exploit coarse grain parallelism.
26
Search algorithms explore a large search space, trying to find an optimal solution.
Searching consists of generating a tree of possible events. A priori knowledge about
the problem can be used to prune the search tree. Many times the optimal solution is
computationally hard to find. Alternatively, approximations of the optimal solution
are found using heuristics or approximation algorithms.
A few standard search algorithms are: i) alpha-beta cut exploration of min-max
game trees; ii) A* - "branch and bound" a search tree, using a pessimistic heuristic
estimator for the distance to the solution; iii) IDA* - iterative deepening A* having
the advantage of not storing the search boundary; and iv) back-tracking - the most
general algorithm for traversing a search tree.
Parallelizing such algorithms can be done by concurrently computing the outcome
of each subtree, waiting for subtree computation to finish, then merging the results.
However, data dependencies between branches can stall computation. Also, the performance of pruning the search tree might depend on the order in which the tree is
evaluated. But most importantly, the structure of a search tree is not known before
the tree is actually generated. Consequently, it is hard to evaluate the work load
associated with each subtree, and statically map work to processors.
The Spawn system is well suited to this class of problems since its work scheduler
is dynamic. Furthermore, the search tree is embedded into the 2D processor mesh,
achieving constant cost parent-child communication. The parallel languages presented
in Section 3.1 don't allow dynamic work scheduling or don't preserve locality of parentchild communication.
3.3
Work Scheduler
Due to the indeterministic' nature of most search algorithms, a dynamic work scheduler is required to balance work among processors. We will study how alternative
schedulers map work on the RAW chip, underlining the advantages of randomized
tree embedding that is used by Spawn.
'i.e. it is hard to approximate outcome given the input
27
3.3.1
Master-Slave Model
The master-slave model is a standard all purpose solution for dynamically distributing
work to a number of processors. For the RAW chip, one tile could act as a master
assigning tasks to the other slave tiles.
However, each time a task is assigned or results are reported the master and the
slave tiles exchange data. The 2D mesh used by RAW provides a high communication
bandwidth between any two tiles. Still, bandwidth can become a bottleneck for the
links close to the master tile, especially when the number of tiles is large. Also, such
a mapping algorithm doesn't use in any way the properties of the 2D interconnect:
any 2 tiles are seen identical.
3.3.2
Randomized Work Stealing
Each idle tile tries to steal a task from a randomly selected tile. If the attempt is not
successful, another tile is selected, and so on. This strategy is used by Cilk for its
SMP implementation. Load balancing is very good, since any idle tile can steal any
available task. However, for a large number of processors this strategy can result in
significant communication overhead - O(n 2). Neither in this case it is taken advantage
of the 2D topology of the mesh.
3.3.3
Randomized Tree Embedding
Any computation expressed as a parallel tree traversal can be embedded into a 2D
mesh of processors paying little parent-child communication cost; for dilation 1 communication is minimized while load balancing might be an issue.
The Spawn project uses this framework, and it allows only neighbor tiles to steal
work. Load balancing is achieved by random stealing, as opposed to statically embedding a tree in the mesh. Therefore, a tree is dynamically generated by randomly
adding leaf tiles to the tree of already selected tiles.
Randomized tree embedding is more tolerant to some worse case scenarios. Imagine a computation tree is drastically unbalanced, and n-th level node X is assigned
28
most work. The static tree embedding will probably keep idle all tiles not in X's
subtree.
On the other hand, randomly generated trees will keep idle only the n
tiles connecting root to X. See Chapter 5 and Chapter 6 for experimental results of
embedding Fibonacci and binary trees.
Computing Fibonacci recursively doesn't require significant memory overhead.
On the other hand, a typical search problem relies on shared memory to keep its
global state. A machine that consist of a large 2D array of processors with large local
memories can still achieve good results. The entire state can be copied from parent
to child while no shared memory is used. Assuming state data has constant size or
is proportional to problem size, inter-tile communication has a constant cost for any
mesh size. Subsequently, memory access doesn't become a scalability bottleneck.
3.4
3.4.1
Design Alternatives
Load Balancing
The tree embedding scheduler doesn't guarantee each tile has work to do. We only
know for sure the root tile runs until the entire problem is solved; the adjacent
tiles have a good chance of getting work from root, unless the tree is significantly
unbalanced.
A possible improvement is requiring "center" tiles not to spawn too small a task.
This would increase chances for tiles far from center to receive tasks. Unfortunately,
it is hard to approximate the size of a task.
Increasing the reach of each tile by redefining the notion of "closest neighbors"
can be helpful. By considering neighbors all tiles at L1 distance 2, the depth of the
tile tree is reduced by a factor of 2; each node has 12 neighbors. Increasing this
parameter trades bandwidth for connectivity [4].
29
3.4.2
Synchronization
After finishing, a tile waits for its children to finish. The wait state is undesirable,
under-utilizing resources. In the worse case only "leaf tiles" are doing work, while all
others are waiting to aggregate data. If work granularity and problem size are well
chosen, this scenario can be avoided (Section 5).
The synchronization step is not computationally intensive, allowing a tile to run
other tasks, too.
Having tiles run multiple tasks avoids the wait state problem.
However, only one task can be active, all others waiting to aggregate data. This
solution can lead to a blowup in memory access, since local memory will be insufficient
for the needs of all tasks.
The waiting problem can be avoided by delegating the aggregation operation to
a child who still works on its job. The ownership of the parent is transferred to the
child, and all tiles involved in the computation need to be informed. Unfortunately,
this algorithm doesn't preserve locality of data transfers.
3.4.3
Memory Footprint, Locality
Each tile has 32Kb local memory; this is probably insufficient to store all local data.
The simpler solution is using local memory as caches backed up by the external
memory. Each time a task is assigned or reported, the communication between tiles
translates to a copy between caches and memories.
limitations, not scaling with the number of tiles
Such a solution has various
[3].
A possible improvement is managing data memory explicitly and faulting pages
from neighbor tiles as well as external memory. The fact that neighbors access the
same read-only data can be exploited - all local memories can be seen as a large
distributed cache. In order to have a consistency mechanism that is easier to analyze,
We can consider a weaker memory model: the parent tile aggregates data reported
by children and all children tiles have read-only access to it.
30
Chapter 4
The Spawn System
A computation that consists of traversing or searching a tree can be executed in
parallel by allowing processors to delegate subtree computation to other processors.
The Spawn system follows this framework while trying to optimize communication for
a 2D array of processors: work delegation is allowed only between adjacent processors,
the tree being dynamically embedded into the 2D array.
The Spawn system implements the delegation mechanism by allowing function
calls to be postponed and executed by another processor. Each processor generates
a stack with jobs that can be reassigned: adjacent processors can be assigned jobs at
the top of the stack; the local processor executes the jobs at the bottom of the stack
(see Fig. 4-3). This policy ensures reassigned jobs are large - the first jobs spawned
correspond to the top levels of the tree.
New jobs are created by spawning functions - calling instrumented versions of a
function that essentially create a job on the spawn stack. Synchronization points can
be used to wait for all functions spawned since the last sync point. A more detailed
description of the spawn mechanism is presented in Section 4.3, and Section 4.4.
I will first present a simple Fibonacci example for Spawn; then I will illustrate
how a binary heap traversal is embedded into the 2D mesh. Finally I will describe
the C interface, and the inner mechanisms of the Spawn system.
31
/* Define an instrumented version of fib - spawn-fib */
spawndefine (fib, int, int, int);
1
2
3
/* Compute Fibonacci recursively */
void fib (const spawn-voidt* dummy, int* x, int* result)
{
int xnew, res[2];
4
5
6
7
8
if (*x <= 1)
9
10
11
12
13
{
*result = 1;
}
else
{
14
/* Recursion: 2 children are spawned */
xnew = *x-1;
spawn-fib (0, &xnew, &res[01);
xnew = *x-2;
spawn-fib (0, &xnew, &res[11);
15
16
17
18
19
20
/* Synchronization: wait for both children to return */
spawn-sync 0;
21
22
23
24
/* Use children's results only after sync */
*result = resE] + resEll;
25
26
}
}
27
Figure 4-1: Definition of a "spawnable" function: fib
4.1
Fibonacci Example
Figure 4-1 shows a recursive Fibonacci function that spawns its recursive calls:
1. an instrumented function wrapper is defined: spawn-fib (line 1)
2. 1st argument is ignored (line 5), since fib doesn't require state data.
3. 2nd argument x holds the argument to the Fibonacci function (lines 5, 9, 16)
4. 3rd argument result will hold the result of the computation (lines 11, 2)
32
5. if computation is recursive, two children are spawned (lines 17, 19). Each child
writes its result to a different temporary location, res[0,1].
6. a sync point waits for spawned children to finish (line 22)
7. only after the sync point the partial results can be used to compute the final
result (line 25).
Note that it is not necessary to have all spawn calls and sync points in the same
function body; these are C functions calls which are independent of context.
4.2
Heap Traversal Embedding
1*
3*
2
2*
1:
2:
3
4*
3:
6*
4:
3
4
5:
6
5*
3s
4
7:
7
6
3
4
7*
26
6s
11
27
28*
15
9
6:
6
5
3s
8*
7
12
10
3s
16
8:
Figure 4-2: Processor state history: traversing a 1023 size heap on 4 x 4
A computation tree is embedded into the mesh by starting with the middle tile
as the root of the tree. All edges of the tree correspond to links to adjacent tiles, or
to the same tile. Figure 4-2 shows the embedding of a binary heap traversal into a
4 x 4 tile array1 . We notice how the children of a node are expanded to the neighbor
tiles, or to the same tile. Symbol description:
*
marks new expansions
'the output is produced by running a sample program using the pthreads Spawn system; see
Appendix F
33
s marks nodes waiting for remote children to finish
. marks idle tiles
num marks a tile working on heap node num. As for any binary heap, the children
of x are 2x and 2x + 1
4.3
C Interface
Implementing the Spawn system can be done by writing a compiler, or by adding an
extension to an existing language. My approach was to write a C library interface
that defines the main operations required by the system. An implementation of the
interface needs to define the following core primitives 2:
spawn-define (fname, ct-in-t, in-t, out-t) is a macro defining a spawnable version of the function given as first argument. An instrumented version of the
original function fname is defined as a new function symbol spawn-fname.
The new function has the same signature as the original function; at the same
time fname is required to be defined with the following signature:
void fname () (const ct-int*, in_t*, out-t*)
spawn-define-callback (fname, ct-inAt, in-t, out-t, agg-t) is similar to
spawn-define but all resulting values are aggregated to a single value by a specialized function. These updates are atomic with respect to function returns.
The same result is achieved if all spawned children write to a vector of return
values which is aggregated after all values are reported.
spawn-sync
()
adds a synchronization point, waiting for all spawns from the current
sync frame to finish. A sync frame consists of all code executed between two
consecutive sync points; entering a spawned function is considered a sync point.
We call a spawnable function a function that can be given as the first argument
to spawn-define. The meaning of its arguments are:
2
additional primitives are specific to each implementation / system, and will be discussed in the
corresponding section
34
1. The first argument of type ct-in-t* is a pointer to a data structure that is
not changed throughout the current sync frame. The system assumes sync() is
called before this data is changed. As a result, no copies of this structure are
made when the function is spawned.
2. The second argument of type int* is pointer to a data structure that can
be changed by the children as well as by the parent. Each time a function is
spawned, a copy of this structure is made; if the function is executed immediately, the copy should be made on the stack.
3. The third argument of type out-t* is a pointer to a data structure where the
result is written when the function call returns. The parent can access this
structure only after the first sync point after the spawn function call.
Two implementations for the Spawn interface were developed as part of the thesis
project:
Pthreads Spawn creates n x n threads that communicate to each other as if they
were a 2D mesh. They share the same memory space, and can use memory locks.
An operating system with multi-processor support can schedule the threads to
run in parallel on different processors. A simulation of any n x n configuration
can be performed if sleep cycles are added as leaf and node computation.
RAW Spawn takes advantage of the 4 x 4 MIPS processors to schedule work in
parallel on RAW. The system doesn't implement locks, or shared memory and
cache coherency protocols; these protocols can be enforced at user level. Realtime simulations of performance are available using the RAW simulation tools.
Semantically the Spawn framework is similar to a subset of the Cilk language developed at LCS. Its implementation has some draw-backs - efficiency, memory footprint, and some advantages - portability, simplicity. Being a C library, the pthreads
implementation can be recompiled on any POSIX system. The RAW library works
close to the hardware, implementing fast messaging and using limited signaling and
no locking.
35
The Spawn Stacks
4.4
Each tile maintains a local stack with jobs that can be scheduled to run on adjacent
tiles, or on the tile itself; these are called spawn stacks (Fig. 4-3). Most of the additional work done by spawn function calls consists of accessing data on the local spawn
stack, or executing functions on the fly. On the other hand, idle tiles communicate
with neighbor tiles trying to steal jobs from their spawn stacks. The following actions
update the spawn stack:
local execution This is the most frequent case of spawn function execution. After
the spawn stack size limit is reached, function calls are executed on the fly.
Such executions are the most efficient, using the C local stack to save data.
This action will suspend the current sync frame, and will push a new sync
frame on the local stack.
saved spawn When a spawn function is executed and the spawn stack has empty
slots, a spawn function call will save its state on the stack and return. The
saved state provides data necessary for a later local or remote execution. The
size of this state is not much larger than the size of the int function argument.
local steal When the local processor reaches a sync point, it will wait for the remote
executions to finish, if any. However, if there are available jobs on the stack
these will be stolen and executed locally; such executions are similar to local
2
A
3
A
B
C
D
1
3
5
7
Sync
B
Sf
C
D
4
5
A
C
6
7
B
4 5
D
Remote steal
Local steal
Processor
configuration
Tree traversal
Spawn stack
Figure 4-3: Heap traversal: work scheduling on 2 x 2 tiles
36
rames
executions.
remote steal If an idle tile succeeds in stealing a job from another tile's spawn
stack, the saved spawn state is transferred and the idle tile starts execution. As
expected, the original owner of the job will not execute it; instead, sync points
might wait for the stolen job to finish.
Taking Fig. 4-3 as an example, Processor A spawns 2, 3; it locally steals 2 and
spawns 4, 5; it locally steals 4 and returns; at node 2 it waits for 5 to finish; at node
1 it waits for 3 to finish. Processor B steals remotely 3 from A and spawns 6, 7; and
so on until at node 3 it reports results to A and becomes idle.
From the programmer's perspective a spawned function call behaves like a regular
function call which is executed concurrently with the current sync frame. The spawn
function call is guaranteed to return and write its results by the time the control
passes the first sync point that follows the spawn. Dealing with inter-processor communication, spawn stack management, and work scheduling are hidden in the spawn
layer. On the other hand, all reads and writes done by spawned functions can happen concurrently. Unless locks are used for protection, exclusion policies have to be
enforced at user level.
4.5
Shared Memory
One notices that the Spawn interface doesn't address shared memory support. Different machines implement various memory models; it is extremely difficult, if not
impossible to define a C interface that guarantees the same properties on any machine. However, if the user has access to a shared memory space, he or she can follow
the memory consistency rules for a DAG of computation as described in [5]. Briefly,
this policy requires that two threads that might be executed concurrently don't read
and write, or write and write at the same memory location; sync points should be
used to mutually exclude these operations. In particular, such two threads are two
children spawned in the same sync frame, or the parent and an active spawned child.
37
The above exclusion policy can be avoided by using standard locking mechanisms.
However, deadlocks might occur in such conditions. A good way of avoiding deadlocks
is holding no more than one lock at the same time by each thread.
If for some SMPs shared memory is fully implemented in hardware, other machines
need additional help from the Spawn system. For instance, RAW Spawn flushes a
child's cache lines before returning, and it invalidates the parent's cache lines after a
return. It is the responsibility of the user to understand each system's particularities,
and design proper shared memory policies.
38
Chapter 5
RAW Spawn
The RAW implementation of Spawn is designed to run on the RAW chip and requires
no underlying software layer.
After the boot sequence, the Spawn system starts
running. The user application has to define an entry point function similar to mainO
that starts executing on the root tile; calling spawn functions will ensure that work
is assigned to the other RAW tiles. Most RAW libraries can still be used, unless they
interfere with interrupts used by Spawn.
5.1
Interface Specification
spawn-define(fidx, fname, ct-in-t, ini, outit) is a macro defining a spawnable
version of fname. See Section 4.3 for details. The only difference is the addition
of the first argument; fidx an integer representing the position of fname in the
spawn register Jn declaration.
spawnregister-fn (fnamel, ...) registers all the spawn functions which are defined using spawn-define. See Appendix B for examples using these macros.
spawnsync() adds a synchronization point, waiting for all spawns from the current
sync frame to finish. See Section 4.3 for details.
spawn-intonO, spawn-off() are primarily used by the Spawn system to commit
atomic changes to the spawn stack - both interrupts and the main execution
39
thread access it. A critical code sequence can be inserted between intoff - inton
to disable stealing/reporting, acting as a system-wide lock. This way the main
thread can access data written by spawned functions before the sync point.
spawn-main() is a function that has to be defined by the application. After the
spawn system boots up, this function is called on the root tile starting the user
program.
raw.h defines miscellaneous functions specific to the raw system: raw-test-fail/pass/done,
print int/string, raw-get-cycle, etc. These functions can be used by applications
as long as they don't interfere with interrupt handlers and messages used by
the Spawn system.
Design Description
5.2
5.2.1
Messages
Stealing and reporting between tiles is implemented using the gdn dynamic network,
and interrupting messages. All received messages trigger an interrupt handler that
takes a certain action depending on the type of message, and the phase of a tile's life
cycle (Table 5.1).
Each tile has a main thread of computation that follows the three phases described
in Section 5.2.2. Interrupts are enabled only at certain times - a message might have
to wait before being serviced. Section 5.2.3 shows why all messages are eventually
read, and no deadlock can occur.
type
MI
M2
M3
M4
description
try to steal
reject steal
accept steal
report results
content
none
none
fn arguments
fn results
phase I action
loop, send M2
wait, send M1
loop, phase II
FAIL
phase II action
interrupt-steal, send M2 or M3
FAIL
FAIL
interrupt-report
Table 5.1: RAW spawn message types
40
5.2.2
Tile Life Cycle
Each tile's life cycle consists of three phases. After boot, all but the root tile start in
phase I. The latter starts in phase II; when it exists the computation has finished or
an error has occurred.
During each phase the gdn interrupt handler routes incoming messages differently;
transitions between phases require that interrupts are disabled. Fig.5-1 presents what
operations happen at each phase, and how transitions occur.
Phase
I: Try Steal
M1 M4 -+
flag
FAIL
flag-
M2
Waiting
M
ntoff
Phase
Ill: Report Results
Ae 0
No msg
-
send M1
intoff
M2
Phase
Accept
M4
11: Run Spawn
M1 -interrupt-steal
M2,M3
FAIL
M4 -+interrupt- report
Reject
intoff
M
M3
J
.
Figure 5-1: The 3 phases of a RAW tile: stealing, working, and reporting
I: Try Steal A tile is idle and it tries to steal work. All messages are received by
the interrupt handler and dealt with immediately: MI messages set a flag that
asks the main thread to respond to the sender tile; M2 and M3 messages are
recorded for later use; M4 messages generate an error.
The main thread loops, checking flags and sending messages: it responds to all
MI messages received with M2; it sends Ml messages, then it waits until M2 or
M3 answers are received. If M2 is received, Ml is resent after a customizable
number of loop cycles. If M3 is received, it jumps to phase II after all M2
replies have been sent. Note all M1 messages have been replied to by the time
the transition happens. (see pseudo-code in Appendix C)
41
II: Run Spawn A tile works on a job and it allows other tiles to steal jobs. The
main thread runs the computation, disabling interrupts when accessing the
spawn stack. When the job ends it jumps to phase III. A job should not end
unless all stolen jobs have reported back.
All messages are received and sent by the interrupt handler. If Ml is received,
interrupt-steal() is called: M2 is sent if there are no available jobs on the spawn
stack; otherwise M3 is sent along with the spawn function arguments. If M4
is received, interrupt-report() is called: function results are written to local
memory. Receiving M2 or M3 generates an error, since no MI message was
sent.
III: Report Results A tile has finished a job and it reports the results. All interrupts are disabled; the incoming messages will be dealt with by the next phase I.
The main thread sends a M4 message to the parent, then it jumps to phase I.
5.2.3
Deadlock Avoidance
We will show that messages are sinkable throughout all 3 phases. This is sufficient to
show deadlocks cannot occur (see Section 2.1.2).
In phase I the interrupt handler either sets a flag or it records the message, therefore messages are sinkable.
In phase II, M4 messages are sunk; MI messages call interrupt.-steal().
This
handler returns M2 or M3 to the requesting tile, then it returns. The requesting tile
is in phase I, and it will sink this message. No network congestion can be caused by
a 3rd party, since only neighbor tiles talk to each other. Therefore interrupt-steal
always returns, sinking the message.
In phase III, a M4 message is sent to the parent tile. Parent is in phase II, and
will sink the message. All messages received during this period are postponed until
next phase I sinks them.
42
5.2.4
RAW-Spawn Interface
The messaging protocol described so far is generic: a new system can be built if
each tile defines means of executing and generating jobs. This allows a very efficient
implementation for particular problems.
All functions marked with
t
need to be
implemented by the above software layer.
This interface uncouples the mechanism of messaging and stealing for 2D RAW
meshes from the software layer implementing spawn stacks, sync points, and spawn
function wrappers.
void spawn-run (void* msg, int* msgilen)t runs a stolen job taken from its argument. The result should be written to the same location before exiting.
void spawn-main ()t entry point of program
int spawn-interrupt-steal (void* msg, int* msgilen)t writes a new job to be
sent to another tile; use NULL if not available.
void spawn-interrupt-report (void* msg, int* msg-len)t reads the result of a
stolen job
void spawn-inton
() turns
void spawn-intoff
()
interrupts on
turns interrupts off
void spawn-sync-wait
() waits until
spawn-sync-signal is called. Interrupts are
disabled before calling the function and upon exit.
void spawn-sync-signal
5.2.5
()
causes spawn-sync-wait to exit
Spawn Layer
This layer is written in C, allowing portability. The most important component is the
spawn stack: sync frames and spawn calls are pushed or popped from the stacks. Each
spawn call corresponds to a sync frame; the stack keeps track of how many spawn
calls are executed locally or remotely for each sync frame. The spawn stacks are used
43
by spawnifn to add jobs; by spawn-sync to execute jobs and query sync frame status;
by spawn-interrupt-steal to remove jobs; and by spawn-interrupt..report to update
sync frame status.
All accesses to data structures shared by the main thread and interrupt handlers
are controlled by disabling and enabling interrupts; this protocol is similar to acquiring
and releasing a system wide lock: intoff acquires the lock, inton releases it. The wait
- signal mechanism is used when a sync point waits for remote tiles to report data.
5.2.6
Efficiency
In terms of memory usage, the spawn stack uses 12 additional bytes for each saved
function call. Unfortunately, the CPU takes significantly more cycles due to aligning
data, following pointers, updating sync frame status, etc. Consequently, spawning
functions is relatively expensive compared to calling native C functions (Section 5.3
estimates a slowdown factor of 2-3).
CPU performance could be improved if function wrappers are written directly in
assembly. The best performance could be achieved if code is automatically generated
by an auxiliary program.
Moreover, the code could be suited to each function's
arguments, no longer requiring a fixed signature format.
There are two optimizations that speedup spawn calls: i) spawn calls that exceed
the stack limit are executed directly on the C stack; ii) after a certain depth level all
spawn and sync statements are replaced with their C equivalent - in particular, there
is no spawn spawn stack activity, and no possibility to steal work beyond this level.
Repeatedly trying to steal is another reason for overhead. Each time the handler
is called a constant cost is paid - saving and restoring registers, querying the spawn
stack, etc. Customizing the frequency of steal requests affects both raw performance
and load balancing.
Finally, stealing and reporting adds a constant overhead. If the granularity of the
stolen job is not sufficiently large, the steal-report overhead can become significant.
44
5.3
Performance Analysis
The overheads of the RAW Spawn system are first analyzed in this section. A speedup
benchmark is later performed, showing how problem size and work granularity influence speedup for a given mesh size.
5.3.1
Tests
Traversals of two tree configurations are used as benchmarks: i) bin - a perfect binary
tree having all leafs at the same level; ii) fib - the Fibonacci tree. These tests recursively count the number of leafs, and compare it with a precomputed number; if the
numbers don't match, the test fails. Each test case takes the following parameters:
1. name - fib, bin
2. n - depth of binary tree, or fib argument
3. stealwait - number of loops waited before resending M1 (approx. 40 cycles/loop)
4. Clevels - the depth of leaf subtrees computed in C
5. spawnlevels - the maximum depth of the spawn stack
6. mesh size
5.3.2
Terminology
Work granularity is defined as the smallest job that can run on a single tile. Looking
at Appendix B we notice that the spawn function calls a native C function when the
argument is less than Clevels. In other words, only n - Clevels levels are available
to Spawn, and the leaf computation is a subtree of size Clevels.
Parallelism is defined as P = T 1 /To,
where T represents ideal runtime on i pro-
cessors. Considering how Clevels affects work granularity, we have Pin
2
n-Clevels
and Pfib < fib(n - Clevels + 1). If spawn levels < n - Clevels parallelism is further
decreased.
Efficiency is defined as E = T 1 /PTp, where T is running time on i processors,
and P is the number of processors.
45
test
no.
n
C
cycles
cycles
1 leaf
Al
10
39,256
38.33
A2
A3
A4
A5
12
13
14
15
156,056
311,736
623,064
1,245,688
38.09
38.05
38.02
38.015
Table 5.2: Average leaf work - Bin
test
no.
n
C
cycles
cycles
1 leaf
GI
G2
G3
G4
G5
10
12
15
20
26
3,960
9,928
40,938
449,417
8,053,961
44.49
42.60
41.47
41.05
41.00
Table 5.3: Average leaf work - Fib
5.3.3
Base Case
By using the C only function on 1 x 1, the Ccycles base case is computed for several
mesh sizes. Since the RAW simulator has a constant overhead for any mesh size, it is
hard to compute base cases for very large n. Table 5.2 and Table 5.3 show the number
of C cycles per leaf node. We notice that this number converges as problem size
increases. It is safe to assume for large n we can compute Ccyclesbir(n) = 38.015*2',
and Ccyclesfib(n)
5.3.4
=
41.0 * fib(n). All values computed this way are marked with t.
Spawn Overheads
Overall speedup is influenced by the following factors:
1. constant cost overheads: spawn function calls, interrupting try-steal messages
(Ml), accept-steal and report-results messages (M3, M4)
2. improper load balancing: bad tree embedding, lack of parallelism i.e. n - Clevel
is too small'
I
-
22, is typically needed for a
n x n mesh. See Section 6.3
46
test
no.
n
C
levels
BI
B2
14
14
1
4
1,262,359
703,159
B3
14
7
633,207
0.98
B4
14
10
624,439
0.998
C
cycles
spawn speedup
1 x 1
0.49
0.89
Table 5.4: Overhead of spawn function calls - Bin
test
no.
n
steal
wait
C
cycles
CI
C2
C3
C4
C5
15
15
15
15
15
10
25
50
100
200
1,616,001
1,425,025
1,342,254
1,296,142
1,271,435
spawn speedup
1 x 1
steal every
# cycles
0.77
0.87
0.93
0.96
0.98
2,300
4,250
8,150
Table 5.5: Overhead due to steal requests - Bin
test
no.
Dl
D2
D31
D32
D33
D34
D35
D36
D41
D42
D43
D44
D45
D5
n
13
14
15
15
15
15
15
15
17
17
17
17
17
20
C
levels
10
11
12
12
12
12
12
12
14
14
14
14
14
17
steal
wait
200
200
200
150
100
75
50
25
200
100
75
50
25
200
C
cycles
311,736
623,064
1,245,688
1,245,688
1,245,688
1,245,688
1,245,688
1,245,688
4,982,752
4,982,752
4 ,9 8 2 ,7 5 2 t
4 ,9 8 2 ,7 52t
4,982,752t
39,862,016t
lx 2
1.87
1.93
1.96
1.99
speedup
3x 3
2.67
3.20
3.55
6.21
6.64
3.74
7.15
7.08
3.87
7.61
3.92
7.56
7.30
3.97
Table 5.6: Constant cost overheads for P = 23 - Bin
47
4 x4
4.01
5.34
6.39
6.67
6.96
6.84
7.04
6.90
7.50
7.62
7.60
7.58
7.20
7.87
Table 5.4 shows how the overhead of spawn function calls decreases as granularity
increases. The base case is compared to Spawn running on 1 x 1; since only the root
tile runs, there are no interrupting messages that come with their own overhead. The
maximum slowdown factor is 2, but for Clevels = 10 there is virtually no overhead.
The corresponding granularity is 40K cycles (see Table 5.2).
The overhead generated by steal interrupts is tested in Table 5.5. The root tile
runs the C version in a 3 x 3 configuration. As a result all neighbor tiles unsuccessfully
send try-steal messages. As expected, we notice that overhead decreases as steal wait
increases. For values 50 - 200 the overhead is small. Moreover, in practice not all
neighbor tiles try stealing and fail, and keep trying again.
The experiment from Table 5.6 keeps P = 8 for all tests. Therefore, all factors
that cause bad performance are analyzed, except parallelism. The 23 tree can easily
be embedded into the 3 x 3 and 4 x 4 meshes assigning one leaf to a distinct tile.
Subsequently, we are expecting a speedup of 8, unless we have bad tree embeddings.
For 4 x 4 we notice that increasing granularity up to 14 helps. At the same
time, best performance is achieved for stealwait = 50 - 100. This tendency becomes
more obvious for 3 x 3: stealwait = 100 - 200 drastically affects load balancing,
probably due to bad embeddings 2 . We conclude stealwait = 50 is most suitable, and
Clevel = 14 virtually removes constant cost overheads - 7.58 (D44). Clevel
=
10 is
doing almost as well - 7.04 (D35).
5.3.5
Parallelism
We have established that sufficiently large granularity diminishes constant system
overheads. We will study how parallelism influences speedup for various mesh sizes.
In most of the following experiments stealwait = 50 and spawnlevels = 10.
Table 5.7 illustrates how increasing parallelism for constant granularity improves
speedup. Clevels = 14 was chosen to ensure that constant overheads don't play a
big role. For 4 x 4 speedup is not much improved after n > 24, P
2
=
210.
(E34,
ideally a tree is randomly embedded like a water drop that "spills" on a surface. Large steal
wait periods might generate artifacts on small meshes
48
test
no.
Eli
E12
n
17
19
C
levels
14
14
steal
wait
200
200
C
cycles
4,982,752t
19,931,008t
E21
17
14
100
E22
E23
E31
E32
E33
E34
E35
19
21
17
19
21
24
26
14
14
14
14
14
14
14
E4
17
E5
20
speedup
3 x3
3.87
5.27
4 x 4
7.50
7.87
4, 9 8 2 ,7 5 2 t
7.61
7.62
100
100
50
50
50
50
50
19 , 9 3 1,00 8 t
79 ,724,0 3 2 t
4 ,9 8 2 ,7 5 2 t
19, 9 3 1,008t
7 9 ,7 2 4 ,0 3 2 t
6 3 7 ,7 9 2 , 25 6 t
,
2 5 5 1,l 6 9 ,02 4 t
6.29
7.45
7.56
6.29
7.46
7.98
8.00
7.91
10.62
7.59
7.91
11.41
13.18
13.34
10
100
4, 9 8 2 ,7 5 2 t
6.64
9.36
10
100
3 9 ,8 6 2 ,016t
7.63
11.79
2 x 2
3.98
3.99
4.00
Table 5.7: Increasing parallelism for constant granularity - Bin
test
no.
Fl
F2
F3
F4
F5
n
20
20
20
20
20
C
levels
8
9
10
11
12
steal
wait
50
50
50
50
50
C
cycles
39,862,016t
3 9 ,86 2 ,016t
3 9 ,86 2 ,016t
39,862,016t
3 9 ,8 6 2 ,016t
2x 2
3.93
3.94
3.95
3.97
3.99
speedup
3x 3
7.55
7.68
7.72
7.68
7.61
4x 4
11.78
12.18
12.47
12.44
11.55
Table 5.8: Tradeoff between granularity and parallelism - Bin
test
no.
n
C
levels
steal
wait
Hi
26
9
50
8,053,961
HI
26
12
50
8,053,961
HI
26
15
50
8,053,961
HI
26
18
50
8,053,961
C
cycles
Ix 2
speedup
2 x 2
3 x 3
4 x 4
10.01
1.97
3.68
7.84
10.87
8.03
11.08
7.86
10.00
Table 5.9: Tradeoff between granularity and parallelism - Fib
49
test
no.
n
C
levels
steal
wait
spawn
levels
11
12
26
26
15
15
50
50
8
10
13
26
15
50
12
speedup
3 x 3
4 x 4
1,245,688
1,245,688
6.58
8.03
10.81
11.08
1,245,688
8.03
11.35
C
cycles
Table 5.10: Increasing spawn stack size - Fib
test
no.
n
J1
J2
J3
J4
26
28
29
30
C
levels
steal
wait
spawn
levels
15
15
15
15
50
50
50
50
12
13
14
15
C
cycles
1,245,688
1,0
2
8 5 ,5 4 3 t
3 4 ,11 7 ,1 2 6 t
55, 2 0 2 ,6 6 9 t
speedup
3 x 3
4 x 4
8.03
8.46
8.56
8.46
11.35
12.04
12.73
12.76
Table 5.11: Increasing parallelism and stack size for constant granularity - Fib
35); for 3 x 3 n = 21..24, P = 27 - 29 approaches the upper bound (E33, E34); for
2 x 2 speedup is perfect for n= 17, P = 23.
We notice again how large stealwait
negatively influence speedup on 3 x 3 for small P (E12, E22). On the other hand,
comparing E4 to E21 we conclude that parallelism takes precedence over granularity.
Experiments described in Table 5.8 and Table 5.9 try to optimize speedup for a
certain problem size n. We already know larger granularity and parallelism improve
speedup, and Clevel = 14, P = 210 give good results on 4 x 4. However, the user
has to make a tradeoff if n < 24. For n = 20 F3, F4 show P = 29 - 210 is the most
important factor, not larger granularity. For fib the problem size is even smaller:
fib(26) = 217
cycles), and P
-
218.
Best performance is achieved for Clevel = 12 - 15 (10-40K
200 - 700 (HI).
The last experiments increase parallelism for the fib computation, keeping constant granularity. In Table 5.10 we study how spawnlevels affect performance; indeed
increasing spawnlevels improves performance for constant problem size (13). In Table 5.11 we see how increasing n = 26..30 improves speedup, which reaches its upper
bound for n = 29, P =
f ib(14) - fib(15)
=
29 - 210
To summarize the results, we have concluded that i) constant system overhead
can be avoided for granularity greater than 40K cycles ii) stealwait = 50 is the best
setting for small and large problems; iii) for 4 x 4, P = 29 - 210 gives a remarkable
50
speedup of 12 - 13 for both tree traversals - bin(20) Clevel = 10, fib(29) Clevel = 15;
iv) if problem size is small, it is better to increase P as long as granularity is not
smaller that 210.
51
52
Chapter 6
Pthreads Spawn
The pthread implementation of the Spawn system works on any POSIX system. The
library creates pthreads corresponding to each virtual processor; on a real multiprocessor system these threads are typically mapped to individual processors, therefore
utilizing the full capacity of the hardware.
6.1
Interface Specification
spawn-define(fname,
ct_in_t, in_t, out-t) is a macro defining a spawnable ver-
sion of fname. See Section 4.3 for details.
spawn-sync()
adds a synchronization point, waiting for all spawns from the current
sync frame to finish. See Section 4.3 for details.
spawn-init(int xdim, int ydim, int xinit, int yinit, int size, int depth, int len)
initializes the Spawn system, setting the size of the 2D array, the coordinates of
the starting tile, the maximum spawn stack size, the maximum stack depth, and
the size of the labels. No spawn functions can be used before calling spawn-init.
spawn-cookie()
returns a pointer to the string associated with the current tile.
spawn-cookieiJen()
returns the size of the cookie string; this size is specified when
calling spawn-init.
53
spawn-print-cookies() prints a graphical representation of all tiles and their labels; this function can be used to illustrate what each processor is working on
(Appendix F).
spawn-done() frees all resources used by the Spawn system; no spawn functions
can be used after this point.
6.2
6.2.1
Design Description
Memory and Synchronization
All data structures are shared by all threads but only adjacent threads interact with
each other. Each thread uses a spawn stack and two locks with condition variables.
The opsilock is used to control access to the spawn stack; the owner thread adds
and removes spawned functions and sync frames. The only exception is when another
thread does a remote steal.
The sig-lock is used to control signaling. When a thread tries to remote steal it
locks its own signal lock, then it checks the surrounding opsilock. If it steals a job it
releases sig-lock, otherwise it waits for it. On the other hand, when a thread spawns a
job it tries to signal this event to all neighbors: it grabs their sigilock, then it signals
them. This lock is also used at synchronization points where spawn-sync waits for
remote steals to finish.
This implementation heavily relies on using mutexes for every operation. The most
demanding task is signaling available spawns (8 mutex ops, 4 signals) and accessing
local data structures (2 mutex ops).
The advantage of this approach is that all
threads are either working or waiting for work to become available. A pool based
mechanism adds some lag, but it can be cheaper in terms of CPU for working tiles.
Another design alternative is using interrupts rather then locks, similar to the RAW
implementation.
54
6.2.2
Efficiency
The most common operations are spawning functions and synchronizing. The overhead of these functions is relatively high compared to the standard C function call:
when spawning a copy of the 2nd argument is created, the spawn stack is locked and
updated, etc. This impediment can be avoided if the spawn functions are used only
at the higher levels of the tree, and regular C calls are used for the the computation intensive leafs. The Spawn system limits the depth of the spawn stack, but the
programmer needs to consider this issue as well.
A related issue is tailoring the stack size; a larger stack decreases chances that
neighbor processors run out of work, but it increases memory footprint.
6.3
Performance Analysis
The pthread implementation of the Spawn system was tested by traversing two simple
tree structures: i) a binary heap ii) a Fibonacci tree (Appendix F). The experiments
were aimed at testing whether the system is running as planned, and evaluating the
scalability of the Spawn framework on different processor configurations. Measuring
the overhead generated by the pthreads system was not a priority.
All tests were performed on a single processor box running Linux. How is it
possible to evaluate a multi-processor system on a single CPU machine ? To solve
this issue sleep cycles were added to the tree traversal: the same program runs slow
motion, allowing the operating system to switch between threads. The sleep cycles
are a few orders of magnitude larger than the real CPU usage. The shortcomings of
this approach are not being able to
i) measure the overhead of the Spawn implementation;
ii) scale pthreads overhead with CPU number - only one CPU runs all threads;
iii) obtain a scheduling of threads similar to that of a multiprocessor machine.
Runtime speedup was computed by measuring the real runtime vs. the sum of
all sleep cycles over the tree. Table 6.1 summarizes the speedups for traversing the
binary heap using different leaf/node sleep cycles and mesh sizes.
55
2x 2
3.66
3.67
3.67
4 x4
12.71
12.80
12.79
112.6
153.5
204.7
2047.0
7.0
9.5
12.7
3.53
3.53
3.50
12.71
12.18
11.43
6 x 6
25.32
25.61
25.58
25.59
25.25
23.24
22.00
3.48
3.40
3.33
8.40
8.24
7.46
14.96
12.63
11.52
speedup
8 x8
36.32
37.75
37.86
37.91
36.72
32.99
30.56
30.55
17.13
12.72
11.57
10
10
7.0
14.0
3.51
3.50
8.51
10.22
14.83
19.45
17.35
20.92
100
100
100
100
10
10
10
10
28.1
56.3
112.6
225.2
3.51
3.50
3.53
3.54
10.02
12.13
12.70
13.04
20.61
23.60
25.30
24.93
27.97
31.27
36.69
40.10
100
100
100
100
10
10
10
450.5
1802
7208
13.14
26.43
24.58
28.07
D1O
212
214
216
216
1 0 1h
D11
218
100
10
7208
28835
D12
218
100
0
26214
heap
size
1023
1023
1023
1023
1023
1023
1023
1023
63
63
63
leaf
(ms)
10
100
300
1000
100
100
100
1000
100
100
100
node
(ms)
0
0
0
0
10
50
100
1000
10
50
100
work
(ideal)
10.2
102.4
307.8
D2
26
27
100
100
D3
D4
D5
D6
28
29
210
211
D7
D8
D9
test
no.
Al
A2
A3
A4
B1
B2
B3
B4
C1
C2
C3
D1
12 x 12
16 x 16
44.36
45.94
49.1
97.06
119.98
48.79
51.07
97.51
107.76
118.83
127.96
151.67
Table 6.1: Speedup for binary heap traversal
Experiments A1-A4 aim at determining the magnitude of the sleep cycles. For
leaf > 100ms the performance is not affected; we assume 100 is reasonably large.
Experiments B1-B4, C1-C4 add node weights studying how different leaf/node
weight ratios affect the speedup. For small heaps, speedup is affected for any mesh size
(predominantly for large n).
For large heaps
If U(n, heap - size, node - leaf - ratio)
can say
-
only large n are affected.
p,,d"p measures the CPU utilization, we
$< 0, aheap size > 0, and Onode-laf -_,to < 0.
Experiments D1-D12 measure how speedup is affected by problem size. I assumed
the 1/10 leaf/node weight ratio is realistic'. We notice that speedup increases with
'the program should be designed to minimize Spawn overhead; moreover, Spawn helps by limiting
the depth of the spawn stack
56
test fib(x)
no.
El
17
E2
20
E3
22
E4
27
E5
29
work
(ideal)
284
1204
3152
34959
91524
2x2
3.46
4x4
12.66
12.85
6x6
29.69
30.69
30.99
speedup
8x8
41.00
50.41
50.99
12x12
46.79
64.32
76.24
104.02
113.39
16x16
46.19
64.71
78.59
115.54
133.90
Table 6.2: Speedup for Fibonacci tree traversal
heap size for any mesh size, reaching an upper bound at large heap sizes. For 4 x 4
the limit is 13 at 210, for 6 x 6 the limit is 26 at 212, for 8 x 8 the limit is 50 at 216.
These numbers suggest a speedup of 0.75n 2 is achieved for problem size
2 2n.
A 4'
tree has 4 children and depth n; the tile graph has maximum distance n (middle to
corner), while each tile has 4 neighbors. It is easy to prove this correlation for a ID
mesh when the root is one end (there is always one possible steal). Using statistical
arguments the same could be proved for 2D.
Experiments El-E5 from Table 6.2 show similar speedup limits for the Fibonacci
tree traversal 2 . This gives us hope the above experiments are representative for a
larger class of problems, and the Spawn framework could work successfully for most
search problems.
Future testing needs to be done on a multi-processor machine. Such tests would
show what low level optimizations are required to make the pthreads Spawn system
effective in terms of real speedup.
210Oms
leaves, 10ns nodes
57
58
Chapter 7
Conclusion
This thesis has presented a system that exploits coarse grain parallelism on 2D processor meshes.
Experimental results proved the system achieves good performance
on the RAW chip. Moreover, a simulation of large processor meshes showed constant
efficiency up to 12 x 12.
A C library has been developed, allowing applications to spawn function calls and
wait at synchronization points. As opposed to parallel languages that use specialized
compilers, the Spawn system uses the existing C infrastructure. This approach allows
better portability, and simplicity of use. On the other hand, efficiency of spawn function calls becomes an issue. Experimental results have shown that work granularity
of 40K cycles highly diminishes constant cost overheads.
The two benchmarks used for testing are traversals of perfect binary trees, respectively Fibonacci trees. These tests showed good speedups for the RAW chip, as well
as for the pthreads simulation. On RAW, speedups of 12 - 13 are achieved for 4 x 4
when parallelism exceeds 29
-
210; for 3 x 3 speedups of 7 -8
are obtained for problems
with parallelism 2' - 29. Moreover, pthreads simulation results showed speedups of
35 - 50 for 8 x 8, 95 - 110 for 12 x 12, and 120 - 150 for 16 x 16. Empirically, we
can generalize that a speedup of 0.75n 2 is achieved for n x n meshes when parallelism
reaches
2 2n.
If this is correct, the Spawn computation model is efficient.
For large processor meshes point to point communication is the only alternative.
Relying on main memory is no longer possible due to scalability issues. The natural
59
tendency is keeping data and computation local; as communication is point to point,
work partitioning needs to be local in order to maintain locality of data access. Dynamically embedding computation trees into 2D processor meshes is an alternative
that reaches this goal.
7.1
Future Work
The Spawn system for RAW has constant cost overheads incurred when spawning
function calls, and synchronizing. Efficiency can be improved by automatically generating C code that is tailored to each spawn function signature. Considering the
capabilities of modern compilers, saving data on the spawn stack should be no slower
that pushing data on the C stack. Another optimization is using fast interrupt handlers when no jobs are available on the stack - there is no need to save registers, since
the code path is simple for this case.
There are several possible extensions to the RAW Spawn library: i) an initialization function that sets up configuration at runtime - spawn stack size and depth,
steal frequency, and C-level depth; ii) a define-callback macro that aggregates data
when calls return, avoiding the hassle of keeping vectors with results; iii) support for
locking and shared memory allocation, allowing the implementation of more complex
algorithms such as scientific computing.
Quantifying system overheads and analyzing how they affect performance would
help choosing optimal configuration parameters. A related research problem is proving a statistical lower bound on speedup given mesh size, tree structure, and problem
size.
60
Appendix A
RAW Spawn Interface
#ifndef SPAWN-H
#define SPAWN-H
#ifdef __cplusplus
extern "C" {
#endif
#include "spawn-c2asm.h"
#ifndef SPAWN-OFF
#include "spawn-stack.h"
10
* INIT
static inline void spawn-init
{
pinit ();
spawn-stack-init (;
spawn stack-push-sync
0
0;
}
static inline void spawn-done
{
spawn-stack-pop-sync
}
()
20
0;
* SYNC
*
*
*
*
*
Adds a synchronization point, waiting for all spawns from the
lowest sync frame to finish. Possible actions:
- steal locally
- wait for all remote spawns to finish
static inline void spawn-sync
{
()
spawn-t *sp;
if (spawn stack-cexec) return;
spawn-intoff ();
61
30
#ifdef DEB-SPAWN
pstr("syncB "); spawn stack-print
0;
#endif
40
loop & local steal
//
while ((sp = spawn-stack-local-steal-push-sync
0))
{
spawn-inton
0;
if ( SPAWN-IN-NULL(sp->flags)
(*spawn-functions[sp->fn]) (sp->ct-p, 0, sp->outp);
else
(*spawn-functions[sp->fn]) (sp->ctp, sp->data, sp->out-p);
50
spawn-intoff ();
spawn-stacklocal-steal-pop-sync ();
}
// wait for remote steals
while (!spawn-stack-sync-is-done
spawn-sync-wait ();
0)
60
if (spawn-stack-sync-is-remote
spawn invalidate-cache (;
0)
#ifdef DEBSPAWN
pstr("syncE "); spawn-stack-print (;
#endif
spawn-inton
}
0;
70
* SPAWN
*
*
*
*
*
spawn-define & spawn-callback-define are macros defining a
spawnable version of the function given as argument. A new function
symbol is defined - spawn-fn - where fn is the original name of the
function.
*
*
*
Forward declaration
void fn-name (const ctt*, int *, out_t *);
*
spawn-fn: write result to local frame; no access allowed to out-t
80
* before sync().
*
spawn-define (fnname, ct_t, in_t, out-t)
*
=> spawn
fn-name (const ctt *, int *, outJ *)
*
*
Possible actions of spawn (used by spawn fn, spawn-callback-fn):
*
*
-
C execute
-
spawn execute (if the policy preffers earlier spawns)
*
-
save spawn
90
62
#define spawn-register_fn(fns...) spawnable-fn-t spawn-functions[] = {fns};
typedef struct
{} spawn-void_t;
#define spawn-define(num, fnname,
in-t, outt)
ct-t,
\
/*
Forward declaration */ \
void fn-name (const ctt*, int *, outt *);
\
100
/* Define custom function *7 \
inline void spawn- ## fn-name (const ct-t *ct-a, in-t *in-a, outt *out-a)
\
f \
if (spawn-stack-cexec) \
{ /* fastest - C exec */
\
if (sizeof(in-t) > 0 && in-a)
{ \
int saved-in = *in-a; \
fn-name (ct-a, &saved-in, out-a);
} else \
fn-name (ct-a, 0, out-a); \
else if (spawn stack-sexec)
\
110
\
{ /* almost as fast - local exec - create sync on stack (no save) *7 \
spawn-intoff (; \
spawn stack-push-sync (); \
spawn-inton (); \
if (sizeof(in-t) > 0 && in-a)
{\
in-t saved-in = *in-a; \
fn-name (ct-a, &saved-in, outa);
} else \
fn-name (ct-a, 0, outa); \
\
120
spawn-intoff 0; \
spawn-stack-pop-sync (); \
spawn-inton 0;
else
\
{ /* save spawn *7 \
spawn-intoff ();
130
SPAWNSTACKSAVESPAWN
(num, ct_t, ct_a, in_t, ina, out-t, out-a);
\
spawn-inton (;
}
spawn-intoff(); \
/* pstr("spawn "); spawn-stack-print); *7
spawn-intonO; \
\
#else // SPAWN-OFF, no stack
140
typedef struct
{} spawn-void_t;
#define spawn-init()
#define spawn-done()
#define spawn-sync()
{}
{}
{}
63
#define spawn-registerfn(fns...)
#define spawn-define(num, fnname, ct_t, int, out_tA)\
/* Forward declaration */\
void fn-name (const ctt*, int *, outt *);\
150
/* Define custom function */\
inline void spawn_ ## fn-name (const ct-t *ct_a, int *in_a, out-t *out-a)
I \
if (sizeof(in-t) > 0 && in-a)
\
{ \
int saved-in = *in-a; \
fn-name (ct-a, &saved-in, out-a);
} else \
fn-name (ct-a, 0, out-a); \
\
}
160
#endif
#ifdef __cplusplus
}
#endif
#endif // SPAWNH
64
Appendix B
RAW Spawn Examples
Definition of Fibonacci function:
#include "spawn.h"
#include "raw.h"
int fib-c(int n)
{
if (n <= 1)
return 1;
else
return fib-c(n-1)
+ fib-c(n-2);
}
10
/* Compute Fibonacci recursively */
spawn-define(O, fib, spawn-voidt, int, int);
spawn-register fn((spawnable_fnt)&fib);
void fib (const spawn-void-t* dummy, int* x, int* result)
{
int xnew, res[2];
if (*x <= ARGCLEVEL)
20
{
/* Use C function for last levels */
*result = fib-c(*x);
}
else
{
/* Recursion: 2 children are spawned */
xnew = *x-2;
spawn-fib (0, &xnew, &res[1]);
xnew = *x-1;
spawn-fib (0, &xnew, &res[0]);
/*
30
Syncronization: wait for both children to return */
spawn-sync ();
/* Use children's results only after sync */
*result = res[0] + res[1];
65
}
}
40
int main()
{
unsigned long long int t1, t2;
int i, a = 1, b = 1;
int n = ARGN, res;
/* Computing Fibonacci iteratively */
for (i=0; i<n-1; i++)
{
b = a+b; a = b-a;
}
50
/* Computing Fibonacci recursively */
ti = raw-get-cycle();
if (ARGCLEVEL < 0){
/* C only */
res = fib-c (n);
}
else
{
/* Spawn */
spawn-fib (0, &n, &res);
spawn-sync (;
}
60
t2 = raw-get-cycle();
/* Check & report results */
if (b != res) raw-test-fail (18999);
pinit(;
pstr("RESULTS: fib("); pint(n); pstr(")="); pint(res);
pstr(" clevel="); pint(ARGCLEVEL);
pstr(" cycles="); pint((int)(t2-t1));
pstats(; pstr("\n"); pflusho;
return 0;
}
66
70
Definition of binary tree traversal:
#include "spawn.h"
#include "raw.h"
int bin-tree-c (int depth)
{
if (depth <= 0)
return 1;
else
return bin-tree-c (depth-1) + bin-tree-c (depth-1);
10
}
/* Count binary tree leafs recursively */
spawn-define(O, bin-tree, spawn-void-t, int, int);
spawn-register_fn((spawnablefn-t)&bin-tree);
void bin-tree (const spawn-void-t* dummy, int* depth, int* result)
{
int res[2], ndepth;
if (*depth <= ARGCLEVEL)
{
20
/* Use C function for last levels */
*result = bin Aree-c(*depth);
}
else
{
/*
Recursion: 2 children are spawned */
ndepth = *depth - 1;
spawn-bin-tree (0, &ndepth, &res[0]);
spawn-bintree (0, &ndepth, &res[i]);
30
/*
Syncronization: wait for both children to return */
spawn-sync (;
/*
Use children's results only after sync */
*result = res[0] + res[1];
}
}
int main()
{
40
unsigned long long int ti, t2;
int n = ARG_N, res;
/*
Count the leafs of a binary tree recursively */
tI = raw-get-cycle();
if (ARGCLEVEL < 0)
/* C only */
{
res = bin-tree-c (n);
} else {
/* Spawn */
50
spawn-bin-tree (0, &n, &res);
spawn-sync ();
67
}
t2 = raw-get-cycle();
/* Check results, report settings */
if (res != (1<<n)) raw-test-fail (18999);
pinit();
pstr("RESULTS: bintree("); pint(n); pstr(") ="); pint(res);
pstr(" clevel="); pint(ARGCLEVEL);
pstr(" cycles='); pint((int)(t2-t1));
pstatsO; pstr("\n"); pflush(;
return 0;
}
68
60
Appendix C
RAW Spawn Source Code Extracts
Spawn stack source code:
#ifndef SPAWN-STACKH
#define SPAWNSTACK-H
#include "spawn-c2asm. h"
#define SPAWNMAX-SYNCSPAWNS 4
#define SPAWNMAXSPAWNS SPAWN-MAXSYNC-SPAWNS*SPAWN-MAXSYNCS
#define SPAWNMAXFUNCTIONS 8
#define SPAWNMAXSPAWN-DATA SPAWNMAXSPAWNS*100
#define SPAWNMAXMESSAGE 120
#define
#define
#define
#define
10
SPAWN-IN-NULL(a) (a & spawn-flag-in-null)
SPAWNCT-SIZE(a) ((a>>8) & Oxff)
SPAWN-INSIZE(a) ((a>>16) & Oxff)
SPAWNOUT-SIZE(a) (a & Oxff)
#define SPAWNT(a) ((spawn-t*)&spawn.st.spawn-data[spawn st.spawn-idx[a]])
static
static
static
static
const
const
const
const
int
int
int
int
spawn-flag-in-null = 1<<31;
spawn-flagilocal = 1<<30;
spawn-flag-remote = 1<<29;
spawn-flag-done = (1<<30) 1 (1<<29);
20
typedef void (*spawnable-fn-t) (const void*, void*, void*);
extern spawnable-fn-t spawn-functions[SPAWN-MAX-FUNCTIONS];
/* Data for each spawn
* optimized for local execution
* steal converts it to job-t
* in-t data is kept on the stack during fn call, until sync:
* - mem limited by #spawns/sync and #spawns-total
*
-
only after steals #spawns/sync is greater > max
typedef struct
int fn;
int flags;
{
// in-null or in-t, ct-t, out-t (8 bit)
69
30
}
int sync;
const void *ct-p;
void *out-p;
char data[0];
spawn-t;
// can be null
// can be null
// content of in-t (open ended)
40
/* Data for each sync */
typedef struct {
int pending, remote, isremote;
int no-spawn;
} sync-t;
/* Spawn stack structures */
typedef struct {
// 1..no-sync (0 not used)
int cur-sync;
// next spot (not used)
int no-spawn;
50
sync-t sync [SPAWN.MAXSYNCS];
char spawn-data [SPAWN-MAXSPAWNDATA];
int spawn-idx [SPAWNMAX-SPAWNS];
} spawn-stack-t;
extern spawn-stack-t spawn-st;
60
/* execute locally (C call):
* depth > max
extern int spawn-stack-cexec;
/* steal locally (create sync):
* #spawns-total >= max or #spawns/sync > max
0;
static const int spawn-stack-sexec
70
/* initialize empty stack */
static inline void spawn-stack init
()
{
0; // spawn-stack-sexec = 0;
spawn-stack-cexec
spawn st.cur-sync = 0;
spawn-st.no-spawn = 0;
spawn st.spawn-idx[0] = 0; // first spawn pointer
spawn-st.sync[0].no-spawn = 0;
spawn st.sync[0].remote = -1;
spawn st.sync[0].isremote = -1;
spawn st.sync[0].pending = -1;
80
}
/* push new empty sync
* update: cexec
static inline void spawn-stack-push-sync
0
{
syncit *p;
90
70
#ifdef DEBSTACK
if (spawn-stack-cexec)
spawn-error(" spawn- stack-push-sync: cexec");
if (spawn st.cur-sync < 0)
spawn-error( "spawn stack-push sync: invalid cur-sync");
if (spawn st.cur-sync >= SPAWN-MAXSYNCS)
spawn-error("spawn-stack-push.sync:
too many syncs");
#endif
100
// save spawn pointer
spawn-st.sync [spawn st. cur-sync]. no-spawn = spawn-st.no-spawn;
// new sync
p = &spawn-st.sync [++spawn-st.cur-sync];
p->pending = p->remote = p->isremote = 0;
if (spawn st.cur-sync >= SPAWNMAXSYNCS
-
1)
spawn stack-cexec = 1;
}
/* pop sync
* update; cexec
* error: not empty
110
static inline void spawn-stack-pop-sync
0
{
spawn-t *s;
#ifdef DEB-STACK
if (spawn st.cur-sync <= 0)
spawn-error ("spawn-stack-pop-sync: no syncs");
if (spawn..st.cur-sync >= SPAWN-MAXSYNCS)
spawn-error(" spawn-stack-pop-sync: too many syncs");
120
#endif
s = SPAWN-T(spawn-st.no-spawn -
1);
#ifdef DEB-STACK
if (spawn-st.no-spawn > 0 &&
! (s->flags & spawn-flag-remote) &&
s->sync == spawn st.cur-sync)
spawn-error ("spawn-stack-pop-sync: sync not empty");
if (spawn-st. sync [spawn-st. cur-sync]. remote > 0)
spawn-error ("spawn-stack-pop-sync: remote not empty");
#endif
spawn st.cur-sync
130
-
// restore spawn pointer
spawn st.no-spawn = spawn-st.sync [spawn-st. cur-sync].no-spawn;
if (spawn-st.cur-sync < SPAWNMAXSYNCS - 1) spawn-stack-cexec
=
0;
I
/* all spawns are finished ? (last sync) */
static inline int spawn-stack-sync-is-done
()
{
140
return (spawn-st. sync [spawn-st. cur-sync].pending == 0) &&
(spawn-st.sync[spawn st.cur-sync] remote == 0);
I
71
/* any remote steals ? (last sync) */
static inline int spawn stack-sync-is-remote
0
{
return spawn-st. sync[spawn st. cur-sync]. isremote;
}
150
/* print the stack in readable format */
void spawn-stack-print 0;
/*
*
*
*
allocate space for new spawn in last sync
update: pending, sexec
return spawn pointer
error: no syncs, #spawns>>, out of space
static inline spawn-t* spawn stack-save-spawn (int in-size)
160
{
spawn-t *p;
int tmpl, tmp2;
#ifdef DEB-STACK
if (spawn st.cur-sync <= 0)
spawn-error ("spawn stacksave-spawn: no syncs");
if (spawn-st.no-spawn >= SPAWN-MAXSPAWNS - 1)
spawn-error ("spawn stacksave-spawn: too many spawns");
#endif
spawn-st.spawn-idx [spawn-st.no-spawn++];
tmpl = tmp2
(spawn-t) + in-size);
+=
(sizeof
tmp2
spawn-st.spawn-idx [spawn-st.no-spawn] = tmp2;
170
#ifdef DEBSTACK
if (tmp2 >= SPAWN-MAXSPAWN-DATA)
spawn-error ("spawn-data out of space");
#endif
spawn-st.sync [spawn-st. cur-sync].pending ++;
p = (spawn-t*) &spawn-st.spawn data[tmp1];
p->sync
=
180
spawn st.cur-sync;
return p;
}
/*
deactivate last spawn; create new sync
* update: pending, sexec
* return NULL (empty sync) or spawn
static inline spawn-t* spawn stack-local-steal-push-sync
0
{
spawn-t *p;
if (spawn st.sync[spawn st.cur-sync]. pending <= 0)
return 0;
#ifdef DEBSTACK
if (spawn st.no-spawn <= 0)
spawn-error ("spawn stacklocalsteal-push-sync: pending, but no spawns");
#endif
p = SPAWNT (spawn st.no-spawn - 1);
#ifdef DEB-STACK
72
190
if (p->flags & spawn-flag-done)
spawn-error ("spawn stacklocal-steal-push-sync:
if (p->sync != spawn-st.cur -sync)
spawn-error ("spawn stacklocalsteal-push-sync:
#endif
last spawn not valid");
200
last spawn not in current sync");
p->flags = p->flags I spawn-flag-local;
spawn-st.sync [spawn _st.cursync]. pending
spawn st.no-spawn -- ;
spawn-stack-push-sync 0;
spawn st.no-spawn ++;
210
return p;
}
/* move up the stack: skip executed spawn & remote steals
* pop sync
static inline void spawn-stack-local-steal-pop-sync
{
spawn-stack-pop-sync
0
0;
}
220
/* take first available spawn (keep 1 good spawn)
* if none available, remote = spawn-no = 0
* update: remote, sexec
* return spawn pointer or NULL
static inline spawn-t* spawn-stack-remote-steal (int *syncID)
{
spawn-t *p;
sync-t *s;
int idx = 0;
while (idx < spawn st.no-spawn p = SPAWN-T (idx);
if (p->flags & spawn-flag-done)
idx ++;
230
1)
{
{
else
// not the last spawn
p->flags
p->flags I spawn-flag-remote;
*synclD = p->sync;
s
=
&spawn-st.sync[p->sync];
s->remote ++;
s->isremote
s->pending
return p;
}
240
1;
}
//
no good spawns
return 0;
}
250
/* update counter for stolen sync
* update: remote, done
73
* error: invalid syncID, no remotes
static inline void spawn-stack-remote-done (int syncID)
{
int tmp;
#ifdef DEBSTACK
if (syncID > spawn st.cur-sync)
spawn-error ("spawn stackdoneremote: invalid syncID");
#endif
tmp = -- spawn st. sync[syncID]. remote;
260
#ifdef DEBSTACK
if (tmp < 0)
spawn-error
#endif
("spawn stackdoneremote: too many reports");
}
#define SPAWNSTACK_-SAVE-SPAWN(num,
ctt,
ct-a, in_t, in_a, out_t, out-a)
\
270
1 \
spawn-t *sp = spawn-stack save-spawn (sizeof(in-t));
sp->fn = num; \
sp->ct-p = (const void*) ct-a; \
(void*) out-a; \
sp->out-p
if (in-a) { \
sp->flags
(sizeof(int)<<16) I (sizeof(ctt)<<8)
*(in-t*)&sp->data = *in-a;
}
else
I sizeof(out-t);
\
\
sp->flags = spawn-flag-in-null
280
(sizeof(ct_t)<<8)
}
#endif SPAWNSTACKH
74
I sizeof(out-t);
Implementation of tile phases in assembly:
.text
Phase 1:
starts uintoff, ends uintoff & msg ACCEPT
reg 16. 18,20. .22 used but not saved (running as top)
- Handlers:
handler ml -> set RREJECT[i]
handler m4 -> FAIL, freeze
handler m2, m3 ->
10
if RSTATUS != WAITING => FAIL, set error
if m2 => RSTATUS = REJECT
if m3 => RSTATUS = ACCEPT, read msg
- Main:
RSTATUS = NO-MSG, RCOUNTER = RREJECT
cur-neighbor =
0
0
inton
20
loop
for every i, RREJECT[i] =>
send M2 to neightbor[i], reset RREJECT/i]
intoff
if !RREJECT and RSTATUS == ACCEPT => j Phase2
inton
if RSTATUS
== REJECT or RSTATUS == NOMSG
RCOUNTER ++
if RCOUNTER == MAX =>
RCOUNTER = 0
30
cur-neighbor++ modulo no-neighbors
RSTATUS = WAITING
send M1 to cur-neighbor
end loop
.global phase-1
.ent phase-1
phase_1:
MTSRI PASS, 4100
la
$8,phase
la
$9,PH1
sw
$9,0($8)
la
move
move
RSTATUS, NOMSG
RCOUNTER, $0
RREJECT, $0
40
la
$8, cur-neighbor
sw
$0, 0($8)
uinton
50
_loop-pl:
# send M2s
75
$16, neighbors # $1 = p += 4
$8, no-neighbors
no-neighbors
# $1
$17, 0($8)
lw
# $18 = '1
move $18, $0
#MTSRI PASS, 4105
#mtsr PASS, RCOUNTER
#mtsr PASS, RSTATUS
#mtsr PASS, RREJECT
#mtsr PASS, $17
la
la
60
loop-m2:
la
sll
and
beq
$10,
$10,
$11,
$11,
1
$10, $18
$10, RREJECT
$0, _nextm2
# neigh bit
# send M2 to i
lw
$4, 0($16)
$5, M2
la
MTSRI PASS, 4110
RREJECT, RREJECT, $10
xor
jal
send-msg
70
next-m2:
addiu $16, $16, 4
addiu $18, $18, 1
$18, $17, Jloop-m2
bne
80
# Accept ?
uintoff
bne
RREJECT, $0, -skip-accept
$8, ACCEPT
la
#MTSRI PASS, 4199
beq
RSTATUS, $8, phase_2
_skip-accept:
uinton
# send
la
beq
la
beq
Ml ?
$8, REJECT
RSTATUS, $8, _next-counter
$8, NOMSG
RSTATUS, $8, _next-counter
j
_loop-pl
90
_next-counter:
MTSRI PASS, 4120
addiu RCOUNTER, RCOUNTER, 1
la
$8, MAX-COUNTER
bne
RCOUNTER, $8, Aloop-pl
100
# send Ml
move RCOUNTER, $0
$8, cur-neighbor
la
# $9 = cur-neighbor
$9, 0($8)
lw
76
la
Lw
$10, no-neighbors
$11, 0($10)
# $11 = no-neighbors
addiu
$9, $9, 1
bne
move
$9, $11, _no-adjust
$9, $0
# cur-neighbor ++
110
_no-adjust:
sw
$9, 0($8)
# write cur-neighbor
sl1
$10, $9, 2
la
$8, neighbors
addu $10, $10, $8
$4, 0($10)
1w
# $4 = neighbor + cur-neighbor<<2
la
$5, MI
la
RSTATUS, WAITING
MTSRI PASS, 4150
jal
send-msg
j
120
-loop-pl
Phase 2:
starts intoff - ends intoff
130
- Handlers:
handler ml -> call spawn-interrupLsteal (msg)
handler m2,m3 -> FAIL, freeze
handler m4 -> call spawn-interrupt-report(msg)
- Main:
call spawn-run (msg)
140
phase-2:
MTSRI PASS, 4200
la
$8, phase
la
$9, PH2
$9, 0($8)
sw
uintoff
la
$4, msg
la
$5, msg-len
jal
spawn-run
# check intoff
uintoff
# retun data in msg, msg-len
150
MTSRI PASS, 4299
phase_3
j
Phase 3:
no uints - delayed until Phase 1
no deadlock since parent always listens
160
77
- Main:
send msgM4 to cur-neighbor
j Phase 1
phase_3:
MTSRI PASS, 4300
la
$8, phase
la
$9, PH3
sw
$9, 0($8)
170
la
lw
sll
la
addu
$8, cur-neighbor
$9, 0($8)
$9, $9, 2
$10, neighbors
$10, $10, $9
lw
$4, 0($10)
# $4 = neighbors[cur-neighbor]
la
$5, M4
MTSRI PASS, 4310
MTSR PASS, $4
jal
send-msg
MTSRI PASS, 4399
i
phase_1
.end phase_1
78
180
Appendix D
RAW Spawn Outputs
cagfarm-26
\/starsearch\/module-test s\/dynamic\/s2results>tail
-n 20 bin-tree-44-n26-C14-slO-c50
##* PASSED: 00015004 00003a9c [x,y] = [0, 1]
### PASSED: 00016000 00003e80 [x,y] = [1, 1]
PASSED: 00016004 00003e84 [x,y] = [1, 1]
[11: 00b65cc18]:
RESULTS: bin-tree(26)=67108864 clevel=14 cycles=191216684 xy=44 max-counter=50 spawnnmax-syncs=10
###
### PASSED: 00017002 0000426a [x,y] = [1, 1]
### PASSED: 00017003 0000426b [x,y] = [1, 1]
### PASSED: 00001888 00000760 [x,y] = [1, 1]
### DONE : 00000001 00000001 [x,y] = [1, 1]
\/\/
*** interrupted [191223218\/inf]
stopped.
\/*[469710566] 1*\/ rm spawnstack.s spawn-c2asm.s testbin-tree.s
spawn-asm.s
make[2]: Leaving directory '\/am\/cag-server\/vol\/volO\/cag\/home\/ugradsOO\/soviani\/starsearch\/
module-tests\/dynamic\/spawn2'
Mon Jan 28 04:25:16 EST 2002
cagfarm-26
~\/starsearch\/module-tests\/dynamic\/s2results>cat
fib-12-n26-C15-slO-c50
\/\/ welcome to beetle
]
[NUMBER
DEVICE NAME
RESET ROUTINE
CALC ROUTINE
PARAM
[084059d0
[0840d380
[08407a48
[0815a498
[084387d8
[084094e8
Serial Rom
Print Service
DRAM
DRAM
DRAM
DRAM
dev-serial-rom-reset
dev-print-service-rese
dev-dram-reset
dev-dramreset
devdramreset
dev-dram-reset
devserialromncalc
dev-print-service-calc
devdramcalc
dev-dram-calc
dev-dram-calc
dev-dram-calc
084058c8]
08404418]
08406490]
08423a20]
08401d30]
08402550]
\/*[0] 0*\/ running...
\/\/
[ serial rom : finished test.rbf -- > static port 15
\/\/
*** interrupted [30898\/inf]
stopped.
running...
Interrupted tile 0, pc = 0x16c0
stopped.
running...
### PASSED: 00001100 0000044c
[x,y]
= [0,
0]
79
1
### PASSED: 00001100 0000044c [x,y] = [1, 0]
### PASSED: 00000000 00000000 [x,y] = [0, 0]
### PASSED: 00000001 00000001 [x,y] = [1, 0]
### PASSED: 00001110 00000456 [x,y] = [1, 0]
### PASSED: 00001110 00000456 [x,y] = [0, 0]
### PASSED: 00001200 000004b0
[x,y] = [1, 0]
### PASSED: 00001201 000004b1
[x,y] = [0, 0]
### PASSED: 00017000 00004268 [x,y] = [0, 0]
### PASSED: 00017001 00004269 [x,y] = [0, 0]
### PASSED: 00014000 000036b0
[x,y] = [0, 0]
### PASSED: 00014005 000036b5 [x,y] = [0, 0]
### PASSED: 00015000 00003a98 [x,y] = [1, 0]
### PASSED: 00015004 00003a9c
[x,y] = [1, 0]
### PASSED: 00016000 00003e80
[x,y] = [0, 0]
### PASSED: 00016004 00003e84 [x,y] = [0,
### PASSED: 00014000 000036b0
0]
[x,y] = [0, 0]
### PASSED: 00014005 000036b5 [x,y] = [0, 0]
### PASSED: 00015000 00003a98 [x,y] = [1, 0]
PASSED: 00015004 00003a9c [x,y]
=
[1, 0]
### PASSED: 00016000 00003e80 [x,y]
=
[0, 0]
[x,y]
=
[0, 0]
###
### PASSED: 00016004 00003e84
### PASSED: 00014000 000036b0 [x,y] = [0,
### PASSED: 00014005 000036b5 [x,y]
### PASSED: 00015000 00003a98
=
0]
[0, 0]
[x,y] = [1, 0]
### PASSED: 00015004 00003a9c [x,y] = [1, 0]
### PASSED: 00016000 00003e80 [x,y]
= [0, 0]
### PASSED: 00016004 00003e84 [x,y]
= [0, 0]
[x,y]
= [0,
0]
### PASSED: 00014005 000036b5 [x,y]
= [0,
0]
### PASSED: 00015000 00003a98 [x,y]
= [1, 0]
### PASSED: 00015004 00003a9c [x,y]
= [1, 0]
### PASSED: 00016000 00003e80 [x,y]
= [0,
### PASSED: 00014000 000036b0
0]
### PASSED: 00016004 00003e84 [x,y] = [0, 0]
### PASSED: 00014000 000036b0 [x,y]
= [0,
0]
80
### PASSED: 00014000 000036b0 [x,y] = [0, 0]
[00: 0003e5c97]:
RESULTS:
###
fib(26)=196418 clevel=15 cycles=4082644 xy=21 max-counter=50
PASSED: 00017002 0000426a
[x,y]
=
spawn-max-syncs=10
[0, 0]
### PASSED: 00017003 0000426b [x,y] = [0, 0]
##
PASSED: 00001888 00000760 [x,y] = [0, 0]
### DONE
: 00000001 00000001 [x,y] = [0, 0]
*** interrupted [4089372\/inf]
stopped.
\/*[605504704] 1*\/ rm spawnstack.s spawnc2asm.s spawn-asm.s test-fib.s
make[2]: Leaving directory '\/am\/cag-server\/vol\/volO\/cag\/home\/ugradsOO\/soviani\/starsearch\I
module-tests\/dynamic\/spawn3'
Tue Jan 22 03:59:43 EST 2002
cagfarm-26
~\/starsearch\/module-tests\/dynamic\/s2results>grep -h RESULTS *
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
bin-tree(20)=1048576 clevel=10 cycles=3382240 xy=44 max-counter=100 spawn-max-syncs=10
bintree(20)=1048576 clevel=10 cycles=3197268 xy=44 max-counter=50 spawn-max-syncs=10
bintree(20)=1048576 clevel=ll cycles=3406390 xy=44 max-counter=100 spawn-max-syncs=10
bin-tree(20)=1048576 clevel=ll cycles=3203797 xy=44 max-counter=50 spawn-max-syncs=10
bin-tree(20)=1048576 clevel=12 cycles=3414413 xy=44 max-counter=100 spawn-max-syncs=10
bin-tree(20)=1048576 clevel=12 cycles=3451109 xy=44 max-counter=50 spawn-max-syncs=10
bin-tree(20)=1048576 clevel=13 cycles=3767168 xy=44 maxcounter=100 spawn-max-syncs=10
bintree(20)=1048576 clevel=14 cycles=4402972 xy=44 max-counter=100 spawn-max-syncs=10
bin-tree(20)=1048576 clevel=17 cycles=5063695 xy=44 max-counter=200 spawn-max-syncs=10
bin-tree(20)=1048576 clevel=8 cycles=3383517 xy=44 max-counter=50 spawn-max-syncs=10
bin-tree(20)=1048576 clevel=9 cycles=3272545 xy=44 max-counter=50 spawn-max-syncs=10
bin-tree(21)=2097152 clevel=14 cycles=7506803 xy=44 max-counter=100 spawn-max-syncs=10
bin-tree(21)=2097152 clevel=14 cycles=6987775 xy=44 max-counter=50 spawn-max-syncs=10
bin-tree(24)=16777216 clevel=14 cycles=48383067 xy=44 max-counter=50 spawn-maxsyncs=10
bin-tree(26)=67108864 clevel=14 cycles=191216684 xy=44 max-counter=50 spawn-max-syncs=10
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
RESULTS:
fib(26)=196418 clevel=18 cycles=1024048 xy=33 max-counter=50 spawnmmax-syncs=10
fib(28)=514229 clevel=15 cycles=2492737 xy=33 max-counter=50 spawn-max.syncs=13
fib(29)=832040 clevel=15 cycles=3983571 xy=33 max-counter=50 spawn.max-syncs=14
fib(30)=1346269 clevel=15 cycles=6525914 xy=33 max-counter=50 spawn-max-syncs=15
fib(26)=196418 clevel=12 cycles=741023 xy=44 maxcounter=50 spawn-max-syncs=10
fib(26)=196418 clevel=15 cycles=688419 xy=44 max-counter=10 spawnmmax-syncs=10
fib(26)=196418 clevel=15 cycles=750822 xy=44 max-counter=100 spawn-max-syncs=10
fib(26)=196418 clevel=15 cycles=774725 xy=44 maxcounter=200 spawn-max-syncs=10
fib(26)=196418 clevel=15 cycles=691229 xy=44 max-counter=25 spawn-max-syncs=10
fib(26)=196418 clevel=15 cycles=726768 xy=44 max-counter=50 spawnmmax-syncs=10
fib(26)=196418 clevel=15 cycles=754226 xy=44 maxcounter=75 spawn-max-syncs=10
fib(26)=196418 clevel=15 cycles=709515 xy=44 maxcounter=50 spawn-max-syncs=12
fib(26)=196418 clevel=15 cycles=744798 xy=44 max-counter=50 spawn-max-syncs=8
fib(26)=196418 clevel=18 cycles=805341 xy=44 max-counter=50 spawn-max-syncs=10
fib(26)=196418 clevel=9 cycles=804948 xy=44 max-counter=50 spawnmmax-syncs=10
fib(28)=514229 clevel=15 cycles=1750652 xy=44 max-counter=50 spawnmmax-syncs=13
fib(29)=832040 clevel=15 cycles=2679580 xy=44 max-counter=50 spawn-max-syncs=14
fib(30)=1346269 clevel=15 cycles=4325533 xy=44 max-counter=50 spawn-max-syncs=15
81
82
Appendix E
Pthreads Spawn Interface
#ifndef SPAWN-H
#define SPAWNH
#include <stdio.h>
#ifdef __cplusplus
extern "C" {
#endif
*
Spawn HEADER file
*
Any application using these functions needs to link in a spawn
library specific to a system / implementation. The interface is not
implementation dependent; the application can run on different
platforms by linking different libraries.
10
*
*
*
* Terminology
*
*
*
spawn -spawned function call
sync - all spawns at the same level (between syncs)
thread - all syncs built by a thread entity, stack, etc.
20
*
*
*
*
local execution save spawn
local steal
remote steal -
the spawn is executed right away, no state recorded
save the state of a spawn for later execution
the spawn is executed from the local state (sync)
a spawn is taken from another thread, then executed
* INIT, DONE
*
*
30
Init the spawn system. More threads will be created; the main
thread continues execution, while all the others will try to remote
* steal spawns.
*
*
spawn-init_2D initializes the spawn system setting the size of the
2D array, the coordinates of the starting tile, the maximum spawn
83
*
*
*
*
stack size, the maximum stack depth, and the size of the labels. No
spawn functions can be used before calling spawn-init.
Topology: xdim*ydim threads, communication is allowed only between
adjacent threads i.e. Ixl-x2| + |y1-y2| == 1.
40
*
* spawn-done frees all resources used by the spawn system; no spawn
* functions can be used after this point.
*/
void spawn-init_2D (int xdim, int ydim, int xinit, int yinit,
int max-spawns, int max-depth,
int cookieilen);
50
void spawn-done (void);
7*
* SYNC
*
*
*
*
*
Adds a synchronization point, waiting for all spawns from the
lowest sync frame to finish. Possible actions:
- steal locally
- wait for all remote spawns to finish
*7
void spawn-sync ();
60
7*
* SPAWN
*
*
*
*
*
spawn-define & spawn-callback define are macros defining a
spawnable version of the function given as argument. A new function
symbol is defined - spawn-fn or spawn-callback-fn where fn is the
original name of the function.
*
* Forward declaration
*
void fn-name (const
*
spawn
70
ctt*, in-t *, out_t *);
fn: write result to local frame; no access allowed to out-t
* before sync().
*
spawn-define (fn-name, ct_t, in_t, out-t)
*
=> spawnrfn-name (const ctt *, in-t *, outt
*
*
*)
spawn-callback-fn: aggregate results to local frame. All function
calls associated with a thread fight for a single lock. The parent
thread and these functions don't share data. No access to agg-t
*
* before sync().
*
*
*
80
spawn-callback-define (fn-name, ct_t, in_t, out_t, agg-t)
=> spawn-callbackfn-name (const ct-t *, int
* Possible actions of
* - execute locally
*, agg-t*,
void (*) (out-t*, agg-t*))
spawn (used by spawnrfn, spawn-callback-fn):
- save spawn
* - steal locally
*
(if the policy prefers earlier spawns)
*7
typedef void (*spawnable-fn-t)(const void*, void*, void*);
84
90
void spawn (spawnable-fnt fn,
const void *ct, size-t cts, void *in, size-t ins,
void *out, size-t outs);
void spawn-callback (spawnable-fn-t,
const void*, size-t, void*, size_t, size_t,
void*, size-t, void (*) (void*, void*));
100
* CALLBACK FNs
*
input value, i/o value
*7
void add-int (const int*, int*);
void add-float (const float*, float*);
void add-double (const double*, double*);
110
* Access cookie string for current tile.
* Get maximum length of cookie (set by spawn-init-X)
*7
char* spawn-cookie 0;
int spawn cookie-len 0;
/*
* Print a graphical representation of the tile graph.
* For each tile its corresponding cookie is printed.
120
*/
void spawn-print-tiles (FILE* fp);
/* MACRO definitions */
#define spawn-define(fn-name, ct-t, int, out-t)
/* Forward declaration */ \
void fnrname (const ct-t*, int *, outt *); \
\
130
inline void spawn_ ## fn-name (const ct-t *a, int *b, out-t *c)
spawn ((spawnable_fn_t)&fn_name, \
a, sizeof(ct-t), b, sizeof(in-t), c, sizeof(out-t)); \
{ \
I
#define spawn callback-define(fn-name, ct_t, in-t, out-t, aggt)
/* Forward declaration */ \
void fn-name (const ct-t*, in-t *, outt *); \
\
140
/* Aggregate the result to aggt *7 \
inline void spawn-callback- ## fn-name (const ctt *a, int *b, agg-t* c,\
void (*d) (out-t*, agg-t*)) {\
spawn-callback ((spawnable-fn_t)&fn-name, \
a, sizeof(ctt), b, sizeof(in-t), sizeof(out-t), \
85
c, sizeof(agg-t), d);
\
}
#ifdef __cplusplus
}
150
#endif
#endif // SPAWNH
86
Appendix F
Pthreads Spawn Examples
Definition of Fibonacci function:
#include <stdio.h>
#include
#include
#include
const int
<stdlib.h>
"spawn.h"
"timing.h"
sleep-node = 10000, sleep-leaf
/* Define an instrumented version of fib
spawn-define (fib, int, int, int);
100000;
-
spawn-fib
*
/* Compute Fibonacci recursively *7
10
void fib (const int* notused, int* x, int* result)
int xnew, res[2];
if (*x <= 1)
{
sleep-uint64 (sleep-leaf); /* leaf "computation" *7
*result = 1;
I
else
20
{
sleep-uint64 (sleep-node); /* node "computation"
/* Recursion: 2 children are spawned
xnew = *x-1;
spawn-fib (0, &xnew, &res[0]);
xnew = *x-2;
spawn-fib (0, &xnew, &res[1]);
*/
*/
/* Synchronization: wait for both children to return
spawn-sync 0;
/* Use children's results only after sync
*result = res[0] + res[1];
}
*7
}
87
*7
30
int main(int argc, char** argv)
{
long long int ti, t2;
int x, y, n, a=1, b=1, i;
double runtime, work;
int fib-res;
40
/* Argument parsing */
if (argc!=4) {
fprintf (stderr, "%s xdim ydim n\n",argv[0]); exit(1);
I
x
=
atoi(argv[1]); y = atoi(argv[2]); n = atoi(argv[3]);
50
/* Computing Fibonacci iteratively
for (i=0; i<n-1; i++) {
b = a+b; a = b-a;
*/
}
printf ("x=%d y=%d n=Xd fib (%d) =X.d\n",x,y,n,n,b);
/* Starting the spawn system */
spawn-init-2D (x,y, x/2,y/2, 30,20, 16);
/* Spawning fib */
tI = gettime-uint64();
spawn-fib (0, &n, &fib-res);
spawn-sync 0;
t2 = gettime-uint64 (;
printf ("f inished: fib (Xd) = %d\n",n,fib-res);
/* Stopping the spawn system
spawn-done 0;
60
*7
/* Reporting *7
runtime = (double) (t2-tl)/1000.0;
work = fib-res*(sleep-leaf/1000.0) + (fib-res-1)*(sleep-node/1000.0);
printf ("runtime: %g ideal rt: %g work: %g speedup: %g\n",
runtime, work/(x*y), work, work/runtime);
return 0;
}
88
70
Definition of binary heap traversal:
#include <stdio.h>
#include <stdlib.h>
#include "spawn.h"
#include "timing.h"
int sleep-leaf = 10000, sleep-node = 1000;
bool print-on = false;
int *heap;
spawn-define (sum-heap, int, int, int);
10
void sum-heap (const int* heap-size, int *index, int *sum)
{
if (print-on) {
sprintf(spawn-cookie()," %4d*" ,*index);
spawn-print-tiles (stdout);
sprintf(spawn-cookie(),"X%4d ",*index);
}
if (*index > *heap-size)
{
20
/* Leaf node - fake computation by sleeping *7
*sum = 0;
sprintf(spawn-cookieo, "%4d. ",*index);
sleep-uint64 (sleep-leaf);
}
else
{
/* Recursively compute sum of children
sum = f(2*b) + f(2*b+1) *7
int save-ch [2], newidx;
sprintf(spawn-cookie(), "%4d.
30
",*index);
sleep-uint64 (sleep-node);
new-idx = 2 * *index;
spawn-sum-heap (heap-size, &newidx, &save-ch[0]);
sprintf(spawn-cookie(),"X%4d ",*index);
new-idx++;
spawn-sum-heap (heap-size, &new-idx, &save-ch[1]);
40
sprintf(spawn-cookie()," %4dS",*index);
spawn-synco;
sprintf(spawn-cookie(,"X4d ",*index);
/* Compute partial sum */
*sum = save-ch[0] + save-ch[1] + heap[*index-1];
if (print-on)
printf ("sum_heap(Xd) = %d\n", *index, *sum);
}
}
89
50
int main(int argc, char** argv)
{
long long int ti, t2, t3;
int x, y, n, start;
double runtime, work;
int sum;
60
/* Argument parsing *7
if (argc<6) {
fprintf (stderr, "%s xdim ydim n sleep-leaf sleep-node [-print]\n", argv[0]);
exit(1);
}
x = atoi(argv[1]); y = atoi(argv[2]); n = atoi(argv[3]);
sleep-leaf = 1000*atoi(argv[4]); sleep-node = 1000*atoi(argv[5]);
if (argc>6 && !strcmp(argv[6],"-print")) print-on = true;
/* Initializing heap *7
70
heap = new int[n];
for (int i=0; i<n; i++) heap[i] = 1;
printf ("x=%d y=%d n=Xd sleaf=%d snode=Xd\n",
x, y, n, sleep-leaf, sleep-node);
/* Initialize spawn system *7
ti = gettime-uint64();
spawn-init_2D (x,y, x/2, y/ 2 , 30,15, 5);
t2 = gettime-uint64();
printf ("Done spawninit_2D (%dus)\n",(int)(t2-tl));
80
/* Start recursive process *7
start = 1;
spawn-sumrheap (&n, &start, &sum);
spawn-sync ();
t3 = gettime-uint64();
printf ("Done computation (%dus): sumheap(%d)=Xd\n",
(int)(t3-t2),n,sum);
/* Stopping the spawn system *7
90
spawn-doneo;
/* Reporting *7
runtime = (double)(t3-t2)/1000.0;
work = (n+1)*(sleepileaf/1000.0)+n*(sleep-node/1000.0);
printf ("runtime: Xg ideal rt: %g work: Xg speedup: Xg\n",
runtime, work/(x*y), work, work/runtime);
return 0;
}
90
Appendix G
Pthreads Spawn Outputs
~\/spawn\/src>.\/fib 6 2 20
x=6 y=2 n=20 fib(20)=10946
finished: fib(20) = 10946
runtime: 124431 ideal rt: 100338
work: 1.20405e+06 speedup: 9.67641
25.
18*
21.
sumnheap(12) = 1
13*
29.
18.
21.
26*
-
2*
-
-
3*
2.
-
-
3*
4*
-
-
3.
4.
5*
6*
7*
8*
5*
6*
7*
16*
5*
6.
7*
16*
5*
12*
7*
16*
5*
12*
7*
16.
5*
24*
7.
16.
5*
24.
14*
16.
5*
24.
28*
16.
5.
24.
28.
16.
10*
24.
28.
16.
20*
24.
28.
17*
20.
25*
28.
17.
20.
25.
29*
17.
20.
25.
29.
17.
21*
sum_heap(8) = 1
25.
29.
9*
29.
18.
sum-heap(14) = 1
26.
15*
18.
~\/spawn\/src>.\/heap 4 1 15 100 10 -print
x=4 y=1 n=15 sleaf=100000 snode=10000
Done spawn-init_2D (626us)
1*
-
29.
21.
21.
18.
21.
sum-heap(10) = 1
26.
30.
18.
11*
26.
30*
26.
30.
18.
22*
26.
30.
19*
22.
27*
30.
19.
22.
27.
31*
19.
22.
27.
31.
19.
23*
sum-heap(9) = 1
sum_heap(4) = 3
1
sumheap(13)
sum_heap(6) = 3
sum-heap(15) = 1
sum-heap(7) = 3
sumheap(3) = 7
sum-heap(11) = 1
sum-heap(5) = 3
sum-heap(2) = 7
sum-heap(1) = 15
Done computation (591000us): sum-heap(15)=15
runtime: 591 ideal rt: 437.5
work: 1750 speedup: 2.96108
~\/spawn\/src >.\/heap 6 6 1023 100 100 -print
skipped ...
21.
91
-
-
-
-
6.
-
3
4.
7*
-
skipped
5.
...
-
24.
-
25.
12S
18*
26.
6S
9.
27.
3S
16.
28.
29.
30.
10.
31.
11.
13.
48.
49.
36.
-
51.
50.
12S
37.
75*
-
53.
104*
6S
38.
39*
-
55.
54.
3S
64*
34*
35*
56.
58.
60.
40.
42*
43*
57.
59.
62.
44*
46*
47*
skipped ...
824. 816. 1696* 1760*
768. 1600* 1664* 1728*
6S
3S
784.
12S
576* 592* 608* 1024*
584* 600* 624* 544*
588* 604* 632* 560*
896.
928.
960*
640*
672*
688*
912.
944.
992*
352.
736*
752*
1*
-
2*
-
3*
2.
-
-
3.
4*
-
-
6*
-
4.
-
6.
-
4.
12.
8.
14.
-
13.
10.
12.
8.
14.
9*
13.
10.
11*
12.
8.
14.
9.
-
-
13.
10.
11.
12.
16*
14.
9.
-
-
105.
81.
89.
97.
65.
92.
113.
73.
77*
105.
81.
89.
97.
65.
93*
113.
73.
77.
sumheap(48) =
105.
49*
81.
33.
89.
93.
1
113.
73.
77.
sum-heap(52) = 1
53*
49. 113.
81.
33.
73.
77.
93.
89.
sum-heap(56) = 1
53.
49.
57*
81.
33.
73.
89.
93.
77.
7*
7.
-
6.
7.
5.
8*
13*
13.
10*
sumnheap(32) = 1
105.
97.
113.
81.
33*
73.
89.
93.
77.
-
6.
4.
5.
-
-
5*
-
14*
8.
skipped ...
~\/spawn\/src>.\/heap 3 3 63 100 10 -print
x=3 y=3 n=63 sleaf=100000 snode=10000
Done spawninit_2D (1068us)
-
-
12.
5.
12, 6, 3 wait on sync i.e. all outstanding
children are executed remotely
8.
sum-heap(40) = 1
53.
49.
57.
41*
33.
73.
89.
93.
77.
-
12*
8.
7.
12.
7.
sumnheap(36) = 1
53.
49.
57.
41.
33.
37*
89.
93.
77.
sumheap(44) = 1
53.
49.
57.
41.
33.
37.
45*
93.
77.
92
sumheap(38) = 1
53.
49.
57.
41.
33.
37.
45.
93.
39*
skipped ...
sum-heap(60) = 1
110.
102. 118.
111.
2
61*
43
63.
125.
sum-heap(62) = 1
110.
102. 118.
111.
2
61.
126*
63.
62
110.
111.
126.
102.
2
127*
118.
61.
62
110.
111.
126.
102.
2
127.
118.
122*
62
110.
111.
126.
103*
2
127.
118.
122.
62
110.
111.
126.
103.
2
127.
119*
122.
62
sumnheap(55) =
sum-heap(27) =
sum-heap(13) =
sum-heap(63) =
sum-heap(31) =
13
103.
111.
2
126.
63
1
3
7
1
3
119.
122.
123*
sum-heap(51) = 1
sum-heap(25) = 3
sum-heap(12) = 7
sum-heap(6) = 15
sum-heap(59) = 1
sum-heap(29) = 3
sum-heap(14) = 7
sum-heap(61) = 1
sum-heap(30) = 3
sum-heap(15) = 7
sum-heap(7) = 15
sum-heap(3) = 31
sum-heap(1)
63
Done computation (591000us): sumnheap(15)=15
runtime: 591 ideal rt: 437.5
work: 1750 speedup: 2.96108
93
94
Bibliography
[1]
Rajeev Barua, Walter Lee, Saman Amarasinghe, and Anant Agarwal. Memory
bank disambiguation using modulo unrolling for raw machines. Proceedings of
the Fifth International Conference on High Performance Computing, December
17-20, 1998.
[2] Walter Lee, Rajeev Barua, Matthew Frank, Devabhaktuni Srikrishna, Jonathan
Space-time scheduling of
Babb, Vivek Sarkar, and Saman Amarasinghe.
instruction-level parallelism on a raw machine. Proceedings of the Eighth International Conference on Architectural Support for ProgrammingLanguages and
Operating Systems (ASPLOS-VIII), 1998.
[3] Csaba Andras Moritz, Matthew Frank, Walter Lee, and Saman Amarasinghe.
Hot pages: Software caching for raw microprocessors. MIT/LCS Technical Memo
LCS-TM-599, 1999.
Exploring
[4] Csaba Andras Moritz, Donald Yeung, and Anant Agarwal.
performance-cost optimal designs for raw microprocessors. Proceedings of the
InternationalIEEE Symposium on Field-ProgrammableCustom Computing Machines, FCCM98, 1998.
[5] Supercomputing Technologies Group, MIT Laboratory for Computer Science. Cilk
5.3.1 Reference Manual, June 2000.
[6] Michael Taylor. The Raw Prototype Design Document. PhD thesis, Massachusetts
Institute of Technology, 2000.
[7] Elliot Waingold, Michael Taylor, Devabhaktuni Srikrishna, Vivek Sarkar, Walter
Lee, Victor Lee, Jang Kim, Matthew Frank, Peter Finch, Rajeev Barua, Jonathan
Babb, Saman Amarasinghe, and Anant Agarwal. Baring it all to software: Raw
machines. IEEE Computer, September 1997, pages 86-93, 1997.
95