Variable selection: Variable (or model) selection: Suppose for the -th observational unit (case)
advertisement
 selection: Suppose for the -th observational unit (case)")
Variable selection:
Suppose for the i-th observational unit (case)
you record
(
Yi = 01 failure
success
and explanatory variabales
Z1i Z2i Zri
Variable (or model) selection:
{ subject matter theory and expert opinion
{ t models to test hypotheses of interest
{ stepwise methods
Consider a logistic regression model
i = Pr(Yi = 1Z1i Z2i Zri)
backward elimination
and
stepwise selection
the user supplies a list of potential variables
consider \diagnostics"
forward selection
!
i
log 1 ; = 0 + 1Z1i + 2Z2i + + rZri
i
maximize a \penalized" likelihood
Which explanatory variables should be included
in the model?
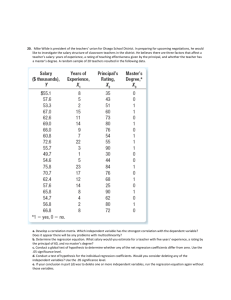
1101
Retrospective study of bronchopulmonary dysplasia (BPD) in new born infants.
Observational Units:
248 infants treated for respiratory distress
syndrome (RDS) at Stanford Medical
Center between 1962 and 1973, and
who received ventilatory assistance by
intubation for more than 24 hours, and
who survived for 3 or more days.
Binary response:
(
stage III or IV
BPD = 12 state
I or II
Suspected causes:
Duration and level of exposure to oxygen therapy and intubation.
1103
1102
Background variables:
Sex
0 = female
1 = male
YOB year of birth
APGAR one minute APGAR score (0{10)
GEST gestational age (weeks 10)
BWT birth weight (grams)
AGSYM age at onset of respiratory symptoms
(hrs 10)
ROS severity of initial X-ray for RDS
on a 6 point scale from
0 = no ROS seen
to
5 = very severe case of RDS
1104
Methods for assessing the adequacy of models:
INTUB duration of endotracheal intubation (hrs)
VENTL duration of assisted ventilation (hrs)
LOWO2 hours of exposure to 22{49% level of
elevated oxygen
MED02 hours of exposure to 40{79% level of
elevated oxygen
HI02
hours of exposure to 80{100% level of
elevated oxygen
AGVEN age at onset of ventilatory assistance
(hours)
1. Goodness-of-t tests
2. procedues aimed at specic alternatives
such as tting extended or modied models.
3. Use of residuals and other diagnostic statistics designed to detect anomalous or inuencial cases or unexpecte3d patterns.
This may involve inspection of graphs, inspection of tables of values of diagnostic
statistics, and application of formal statistical tests.
1106
1105
Overall assesment of t:
An overall measures similar to R2 for regression
log-likelihood !
for the
tted model
LM ;L0
LS ;L0
= G0G;2GM
2
2
!
0
% -
log-likelihood
for saturated
model
log-likelihood
for model
containing only
an intercept
This becomes L0;L0LM (since LS = 0) when
there are n observational units that provide n
independent Bernoulli observations.
For the BPD data and the model selected with
backward elimination
L0 ; LM
L0
Logistic regression model for the BDP
data:
; 97:770 ; :681
= ;2L0;;2(L;2LM ) = 306:520
306:520
log 1 ;^i^ = ;12:729 + 0:7686 LNL
i
;1:7807 LNM + :3543 (LNM)2
;2:4038 LNH + :5954 (LNH)2
+ 1:6048 LNV
3
2
66 concordant = 97:0% 77
4 discordant = 2:9% 5
GAMMA = 0:941
0
1107
1108
When each response is an independent
Bernoulli observation
8
<
Yi = : 10 success
failure i = 1; 2; : : : ; n
and
Goodness of t tests:
H0 : proposed model is correct
(
i = Pr Yi = 1
HA : any other model
Pearson chi-squared test:
X2 =
n (Y ; n n X
2 (Yij ; ni^ij )2 X
2
X
ij
i ^ij )
=
ni^ij
^ij (1 ; ^ij )
i=1 ni
i=1 j =1
Deviance:
G2 = 2
n X
2
X
i=1 j =1
Yij log Yij =ni^ij
)
Z ; ; Z
ri
1i
and there is only one response for each
pattern of covariates (Z1i; : : : ; Zri)
Then, for testing
0
1
i
H0 : log @1 ; A = 0+1Z1i+ +kZki
i
versus
HA : 0 < i < 1 (general alternative)
1109
1110
neither
0 1
n
X
2
G = 2 Yi log @ Y^i A
i
i=1
0
1
n
X
1
;
Y
i
@
+2 (1 ; Yi) log 1 ; ^ A
i
i=1
nor
In this situation, G2 and X 2 tests
for comparing two (nested) models
may still be well approximated by chisquared distributions when k+1 =
= r = 0.
H0 : log 1;ii = 0 +1Z1i + +kZki
HA : log 1;ii = 0+1Z1i+ +kZki
+ k+1Zk+1;i + + rZr;i
n i ; ^i)2
X 2 = X ^(Y(1
i=1 i ; ^i)
is well approximated by a chi-square
distribution when H0 is true, even for
large n.
1111
1112
Deviance:
0
1
n
X
m
^
i;A
2
G = 2 Yi log @ m^ A
i;0
i=1
Pearson statistic
n mi;A ; m
^ i;0)2
X 2 = X (^
m^ i;0
i=1
have approximate chi-squared distributions with r ; k degrees of freedom
when
(S. Haberman, 1977 Annals of Statistics.).
(r ; k)=n is small
k+1 = = r = 0
1113
Hosmer-Lemeshow test:
Insignicant values of G2 and X 2
1. Only indicate that the alternative
model oers little or no improvement over the null model
2. Do not imply that either model is
adequate.
These are the types of comparisons you make with stepwise
variable selection procedures.
1114
Collect the n cases into g groups. Make
a 2 g contingency table
1
(i=1) Y = 1 011
(i=2) Y = 2 021
n0i
Groups
2
012 022 n02 g
01g
02g
n0g
Compute a Pearson statistic
2
2 g
C = X X (0ik E; Eik)
ik
i=1 k=1
1115
Hosmer and Lemeshow recommend
g = 10 groups
formed as
The "expected counts" are
group 1
E2k = n0k(1 ; k)
group 2
0
E1k = nkk
where
..
group 10
0
nk
k = 10 X ^j
nk j =1
..
all observational units with
0 < ^j :1
all observational units with
.1 < ^j :2
all observational units with
:9 < ^j < 1
Reject the proposed model if
C > Xg2;2;
1116
1117
For the BPD example:
^i values
.4-.5 .5-.6
0-.1
.1-.2
.2-.3
.3-.4
3
3
5
3
6
128
18
6
8
1
.6-.7
.7-.8
.8-.9
.9-1.0
2
6
2
1
46
1
5
1
1
1
131
4.95
126.05
3.14
17.86
2.67
8.33
\Expected" Counts
3.56 3.11 1.67 7.18
7.44 3.89 1.33 3.82
2.38
0.62
1.72
0.28
46.59
0.41
170
The \lackt" option to the model statement
in PROC LOGISTIC make 10 groups of nearly
equal size
BPO=1
(yes)
BPD=2
(No)
0
0
0
0
1
4
9
16
25
22
25
25
25
25
25
25
25
25
24
25
21
25
16
25
9
25
0
25
0
22
0
1
X A
@
"Expected" counts
^i
i
C = 12.46 on 8 d.f. (p-value =
0.132)
* This test often has little power
* Even when this test indicates that
the model does not t well, it says
little about how to improve the
model.
1118
.03
.09
.25
.53
1.25
2.67
7.64
18.1
24.5
22.0
25.0
25
24.9
25
24.7
25
24.5
25
23.7
25
22.3
25
17.4
25
6.9
25
0.50
25
0.01
22
C = X 2 = 3.41 on 8 d.f. p-value =
.91
1119
Diagnostics:
Cook, and Weisberg (1982) Residuals and Inuence in Regression, Chapman Hall.
Belsley, Kuh, and Welsch (1980) Regression Diagnostics: Identifying Inuential Data and
Sources of Collinearity, Wiley.
Pregibon (1981) Annals of Statistics 9, 705{724.
Hosmer and Lemeshow (1989) Applied Logistic Regression. Wiley.
Collett, D. (1991) Modelling Binary Data, Chapman and Hall, London
Lloyd, C. (1999) Statistical Analysis of Categorical Data, Wiley, Section 4.2.
Kay, R. and Little, S. (1986) Applied Statistics,
35, 16{30 (case study).
Fowlkes, E. B. (1987) Biometrika 74, 503{515
Cook, R. D. (1986) JRSS-B, 48, 133{155.
Miller, M. E., Hui, S. L., Tierney, W. M. (1991)
Statistics in Medicine 10 1213{1226.
1121
1120
Residuals and other diagnostics:
Pearson
0
n 21
X
2
@
residuals: X = ri A
i=1
ri = q Yi ; ni^i
ni^i(1 ; ^i)
adjusted residuals:
OBS - PRED S.E. RESID
^
ri = q ^Yi ; nipii
V (Yi ; ni^i)
= q Yi ; ni^i
ni^i(1 ; ^i)(1 ; hi)
0
n 21
X
2
@
Deviance residuals: G = di A
i=1
q
di = sign(Yi ; ni^i) jgij
where"
!
!#
Y
n
;
Y
i
i
i
gi = 2 Yi log n ^ + (ni ; Yi) log n (1 ; ^ )
i i
i
1
1122
1123
Adjusted Pearson residual:
ri = p1r;i h
i
Compare residuals to percentiles of
the standard normal distribution
cases with residuals larger than 3 or
smaller than -3 are suspicious.
None of these \residuals" may be
well approximated with a standard
normal distribution.
Adjusted deviance residual:
di = p1d;i h
i
where
hi is the \leverage" of the ith observation
They are too \discrete".
1125
1124
What is leverage?
Residual plots
{ versus each explanatory variable
{ order (look for outliers or patterns across time)
{ versus expected counts: ni^i
0
log @
1
i A = + X + 0
1 1i
1 ; i
+kXki i = 1; : : : ; n
2 66 log 1; 66 log 1;
4 ..
1
1
2
Smoothed residual plots
2
log (n=(1 ; n))
1126
3
77
77 =
5
=
21 X
66 1 X1112
4 .. .
1
X1n
. .
Xk 1
Xk 2
Xkn
32 3
77 66 01 77
5 4 .. 5
k
X
"
model matrix
1127
In linear regression the \hat matrix" is
H = X (X 0X );1X 0
which is a projection operator onto the
column space of X , and
Pregibon (1981) uses a generalized
least squares approach to logistic regression which yields a hat matrix
H = V 1=2Z (Z 0V Z );1Z 0V 1=2
where V is an n n diagonal matrix
with i-th diagonal element
Y^ = HY
ni^i(1 ; ^i) = Vii
and ni is the number of cases with the
i-th covariate pattern.
residuals = (I ; H )Y
V (residuals) = (I ; H )2
1128
The i-th diagonal element of H is
called a leverage value
Cases with large values of hi may be cases with
vectors of covariates that are far away from the
mean of the covariates.
However, such cases can have small hi values
if
^i << :1 or ^i >> :9
Call this element hi.
Note that
1129
n
X
hi = k + 1
i=1
%
number of coecients
When there is one individual for each
covariance pattern, the upper bound
on hi is 1.
1130
An alternative quantity that gets larger as the
vector of covariates gets farther from the mean
of the covariates is
bi = ni^i(1hi;^i)
see Hosmer + Lemshow
pages 153{155
Look for cases with large leverage values and
see what happens to estimated coecients
when the case is deleted.
1131
INFLUENCE (analogous to Cook's D for linear
regression)
Dene:
the m.l.e. for using all n observations
the m.l.e. for when the i-th case
is deleted
A \standardized" distance between b and b(i)
is approximately
Inuence(i) = (b ; b(i))0(Z 0V Z );1(b ; b(i))
b
b(i)
called Ci in
Proc. Logistic
2
=: (1 r;i hhi )2
i
2
= (ri ) 1 ;hih
i
% %
squared adjusted monotone function of
residual
leverage
1132
PROC LOGISTIC approximates the
m.l.e. for with the i-th case deleted
as
1(i) = b ; b1(i)
where
0
1
Y
;
n
^
i
i
i
1
0
;
1
b(i) = (Z V Z ) Xi @ 1 ; h A
i
Then an approximate measure of inuence is
Ci = ri2 (1 ;hih )2
i
%
square of the Pearson residual
1133