Fault Tolerant Distributed Systems: Park 'n Park Presentation
advertisement

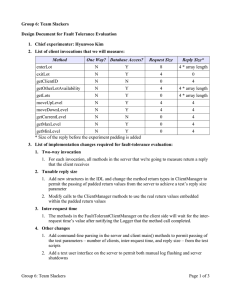
Team 6: Slackers 18749: Fault Tolerant Distributed Systems Team Members Puneet Aggarwal Karim Jamal Steven Lawrance Hyunwoo Kim Tanmay Sinha Team Members URL: http://www.ece.cmu.edu/~ece749/teams-06/team6/ Team Slackers - Park 'n Park 2 Overview • • • • • • • • • • • Baseline Application Baseline Architecture FT-Baseline Goals FT-Baseline Architecture Fail-Over Mechanisms Fail-Over Measurements Fault Tolerance Experimentation Bounded “Real Time” Fail-Over Measurements FT-RT-Performance Strategy Other Features Conclusions Team Slackers - Park 'n Park 3 Baseline Application Team Slackers - Park 'n Park 4 Baseline Application What is Park ‘n Park? • A system that manages the information and status of multiple parking lots. • Keeps track of how many spaces are available in the lot and at each level. • Recommends other available lots that are nearby if the current lot is full. • Allows drivers to enter/exit lots and move up/down levels once in a parking lot. Team Slackers - Park 'n Park 5 Baseline Application Why is it interesting? • Easy to implement • Easy to distribute over multiple systems • Potential of having multiple clients • Middle-tier can be made stateless • Hasn’t been done before in this class • And most of all…who wants this? Team Slackers - Park 'n Park 6 Baseline Application Development Tools • Java – Familiarity with language – Platform independence • CORBA – Long story (to be discussed later…) • MySQL – Familiarity with the package – Free!!! – Available on ECE cluster • Linux, Windows, and OS X – No one has the same system nowadays • Eclipse, Matlab, CVS, and PowerPoint – Powerful tools in their target markets Team Slackers - Park 'n Park 7 Baseline Application High-Level Components • Client • Server • Client Manager • Client Manager Factory • Database • Naming Service – – Provides an interface to interact with the user Creates an instance of Client Manager – – Manages Client Manager Factory Handles CORBA functions – – – Part of middle tier Manages various client functions Unique for each client – – Part of middle tier Factory for Client Manager instances – – Stores the state for each client Stores the state of the parking lots (i.e. occupancy of lots and levels, distances to other parking lots) – Allows client to obtain reference to a server Team Slackers - Park 'n Park 8 Baseline Architecture Team Slackers - Park 'n Park 9 Baseline Architecture High-Level Components 6. Invoke service method Client Manager Client 7. Request data 5. Create instance 4. Create client manager instance Client Manager Factory 1. Create instance Database 3. Contact naming service Server Middleware Legend Processes and Threads 2. Register name x Naming Service Team Slackers - Park 'n Park y Data Flow 10 FT-Baseline Goals Team Slackers - Park 'n Park 11 FT-Baseline Goals Main Goals • Replicate the entire middle tier in order to make the system faulttolerant. The middle tier includes – Client Manager – Client Manager Factory – Server • No need to replicate the naming service, replication manager, and database because of added complexity and limited development time • Maintain the stateless nature of the middle tier by storing all state in the database • For the fault tolerant baseline application – 3 replicas of the servers on clue, chess, and go • Naming service (boggle), Replication Manager (boggle) and Database (previously on mahjongg, now on girltalk) on the sacred servers – Have not been replicated and are single point-of-failures Team Slackers - Park 'n Park 12 FT-Baseline Goals FT Framework • Replication Manager – – – – Responsible for checking liveliness of servers Performs fault detection and recovery of servers Can handle an arbitrary amount of server replicas Can be restarted • Fault Injector – kill -9 – Script to periodically kill primary server • Added in the RT-FT-Baseline implementation Team Slackers - Park 'n Park 13 FT-Baseline Architecture Team Slackers - Park 'n Park 14 FT-Baseline Architecture High Level Components 8. Request data 7. Invoke service method Client Manager Client 6. Create instance 5. Create client manager instance 4. Contact naming service Naming Service 2. Register name Client Manager Factory Database 1. Create instance Server poke() Middleware Legend bind() / unbind() 3. Notify of existence Processes and Threads x y Replication Manager Data Flow Team Slackers - Park 'n Park 15 Fail-Over Mechanism Team Slackers - Park 'n Park 16 Fail-Over Mechanism Fault Tolerant Client Manager • Resides on the client side • Invokes service methods on the client Manager on behalf of the client • Responsible for fail-over – Detects faults by catching exceptions – If an exception is thrown during a service call/invocation, it gets the primary server reference from the naming service and retries the failed operation using the new server reference Team Slackers - Park 'n Park 17 Fail-Over Mechanism Replication Manager • • • • Detects faults using method called “poke” Maintains a dynamic list of active servers Restarts failed/corrupted servers Performs naming service maintenance – Unbinds names of crashed servers – Rebinds name of primary server • Uses the most-recently-active methodology to choose a new primary server in case the primary server experiences a fault Team Slackers - Park 'n Park 18 Fail-Over Mechanism The Poke Method • “Pokes” the server periodically • Not only checks whether or not the server is alive, but also whether the server’s database connectivity is intact or is corrupted • Throws exceptions in case of faults (i.e. can’t connect to database) • The replication manager handles faults accordingly Team Slackers - Park 'n Park 19 Fail-Over Mechanism Exceptions Handled • • • • • • • • • • • • • COMM_FAILURE: CORBA exception OBJECT_NOT_EXIST: CORBA exception SystemException: CORBA exception Exception: Java exception AlreadyInLotException: Client is already in a lot AtBottomLevelException: Car cannot move to a lower level because it's on the bottom floor AtTopLevelException: Car cannot move to a higher level because it's on the top floor InvalidClientException: ID provided by Client doesn’t match the ID stored in the system LotFullException: System throws exception when the lot is full LotNotFoundException: Lot number not found in the database NotInLotException: Client's car is not in the lot NotOnExitLevelException: Client is not on an exit level in the lot ServiceUnavailableException: Exception that gets thrown when an unrecoverable database exception or some other error prevents the server from successfully completing a client-requested operation Team Slackers - Park 'n Park 20 Fail-Over Mechanism Response to Exceptions • • • Get new server reference and then re-try the failed operation when the following exception occurs – – – COMM_FAILURE OBJECT_NOT_EXIST ServiceUnavailableException – – – – – – – AlreadyInLotException AtBottomLevelException AtTopLevelException LotFullException LotNotFoundException NotInLotException NotOnExitLevelException – – – InvalidClientException SystemException Exception Report error to user and prompt for next command when the following exceptions occur Client terminates when the following exceptions occur Team Slackers - Park 'n Park 21 Fail-Over Mechanism Server References • The client obtains the reference to the primary server when – it is initially started – it notices that the server has crashed or been corrupted (i.e. COMM_FAILURE, ServiceUnavailableException) • When the client notices that there is no primary server reference in the naming service, it displays an appropriate message and then terminates Team Slackers - Park 'n Park 22 RT-FT-Baseline Architecture Team Slackers - Park 'n Park 23 RT-FT-Baseline Architecture High Level Components 8. Request data 7. Invoke service method Client Manager Client 6. Create instance 5. Create client manager instance 4. Contact naming service Naming Service Client Manager Factory 1. Create instance 2. Register name bind()/unbind() poke() Database Server Middleware 3. Notify of existence Legend Replication Manager Processes and Threads x y x y Launches Testing Manager Data Flow Team Slackers - Park 'n Park 24 Fault Tolerance Experimentation Team Slackers - Park 'n Park 25 Fault Tolerance Experimentation The Fault Free Run - Graph 1 While the mean latency stayed almost constant, the maximum latency varied Team Slackers - Park 'n Park 26 Fault Tolerance Experimentation The Fault Free Run - Graph 2 This demonstrates the conformance with the magical 1% theory Team Slackers - Park 'n Park 27 Fault Tolerance Experimentation The Fault Free Run - Graph 3 Mean latency increases as the reply size increases Team Slackers - Park 'n Park 28 Fault Tolerance Experimentation The Fault Free Run - Conclusions • Our data conforms to the magical 1% theory, indicating that outliers account for less than 1% of the data points • We hope that this helps with Tudor’s research Team Slackers - Park 'n Park 29 Bounded “Real Time” Fail Over Measurements Team Slackers - Park 'n Park 30 Bounded “Real-Time” Fail Over Measurements The Fault Induced Run - Graph High latency is observed during faults Team Slackers - Park 'n Park 31 Bounded “Real-Time” Fail Over Measurements The Fault Induced Run - Pie Chart Client’s fault recovery timeout causes most of the latency Team Slackers - Park 'n Park 32 Bounded “Real-Time” Fail Over Measurements The Fault Induced Run - Conclusions • We noticed that there is an observable latency when a fault occurs • Most of the latency was caused by the client’s fault recovery timeout • The second-highest contributor was the time that the client has to wait for the client manager to be restored on the new server Team Slackers - Park 'n Park 33 FT-RT-Performance Strategy Team Slackers - Park 'n Park 34 FT-RT-Performance Strategy Reducing Fail-Over Time • Implemented strategies – Adjust client fault recovery timeout – Use IOGRs and cloning-like strategies – Pre-create TCP/IP connections to all servers • Other strategies that could potentially be implemented – Database connection pool – Load balancing – Remove client ID consistency check Team Slackers - Park 'n Park 35 Measurements after Strategies Adjusting Waiting time • The following graphs are for different values of wait time at the client end • This is the time that the client waits in order to give the replication manager sufficient time to update the naming service with the new primary. Team Slackers - Park 'n Park 36 Measurements after Strategies Plot for 0 waiting time Team Slackers - Park 'n Park 37 Measurements after Strategies Plot for 500ms waiting time Team Slackers - Park 'n Park 38 Measurements after Strategies Plot for 1000ms waiting time Team Slackers - Park 'n Park 39 Measurements after Strategies Plot for 2000ms waiting time Team Slackers - Park 'n Park 40 Measurements after Strategies Plot for 2500ms waiting time Team Slackers - Park 'n Park 41 Measurements after Strategies Plot for 3000ms waiting time Team Slackers - Park 'n Park 42 Measurements after Strategies Plot for 3500ms waiting time Team Slackers - Park 'n Park 43 Measurements after Strategies Plot for 4000ms waiting time Team Slackers - Park 'n Park 44 Measurements after Strategies Plot for 4500ms waiting time Team Slackers - Park 'n Park 45 Measurements after Strategies Observations after After Adjusting Wait times • The best results can be seen with 4000ms wait time. • Even though there is a lot of reduction in fail-over time for lower values, we can observe significant amount of jitter. • The reason for the jitter is that the client doesn’t get the updated primary from the naming service. • Since our primary concern is bounded fail-over, we chose the strategy that has the least jitter, rather than the strategy that has the lowest latencies. • The average recovery time is reduced by a decent amount (from about 5-6 secs to 4.5-5 sec for 4000ms wait time). Team Slackers - Park 'n Park 46 Measurements after Strategies Implementing IOGR • Interoperable Object Group Reference • In this, the client gets the list of all active servers from the naming service • The client refreshes this list if all the servers in the list have failed • The following graphs were produced after this strategy was implemented Team Slackers - Park 'n Park 47 Measurements after Strategies Plot after IOGR strategy (same axis) <<COMMENTS>> Team Slackers - Park 'n Park 48 Measurements after Strategies Plot after IOGR strategy (different axis) Team Slackers - Park 'n Park 49 Measurements after Strategies Pie Chart after IOGR strategy Team Slackers - Park 'n Park 50 Measurements after Strategies Observations after IOGR Strategy • The recovery time is significantly reduced, from between 56 seconds to less than half a second • The time to get the new primary from the naming service is eliminated • Most of the time is spent in obtaining an object of client manager • The graph that is plotted on the different axis shows some amount of jitter, since, when all the servers in the client’s list are dead, then the client will have to go to the naming service Team Slackers - Park 'n Park 51 Measurements after Strategies Implementing Open TCP/IP Connections • This strategy was implemented since, after implementing the IOGR strategy, most of the time was spent in establishing a connection with the next server and getting the client manager • In this, the client maintains the open TCP/IP connections with all the servers • So the time to create a connection is saved • The following graphs were produced after the open TCP/IP connections strategy was implemented Team Slackers - Park 'n Park 52 Measurements after Strategies Plot after maintaining opening connections (same axis, 1 client) Team Slackers - Park 'n Park 53 Measurements after Strategies Plot after maintaining opening connections (different axis, 1 client) Team Slackers - Park 'n Park 54 Measurements after Strategies Pie Chart after maintaining opening connections (1 Client) Team Slackers - Park 'n Park 55 Measurements after Strategies Plot after maintaining opening connections (same axis, 10 clients) Team Slackers - Park 'n Park 56 Measurements after Strategies Plot after opening connections (different axis, 10 clients) Team Slackers - Park 'n Park 57 Measurements after Strategies Pie Chart after Opening Connections (10 Clients) Team Slackers - Park 'n Park 58 Measurements after Strategies Observations after implementation of open connections for 1 client • The recovery time is reduced compared to the cloning strategy • Maximum time taken in is still in obtaining an object of client manager • There is noticeable jitter when observed from different axis Team Slackers - Park 'n Park 59 Measurements after Strategies Observations after implementation of open connections for 10 clients • Significant reduction is observed in fail-over time • Maximum time taken in is still in obtaining an object of client manager • It can also be observed that a significant amount of time is taken in waiting for acquiring a lock on the thread Team Slackers - Park 'n Park 60 Other Features Team Slackers - Park 'n Park 61 Other Features The Long Story - EJB 3.0 • It’s actually not that long of a story…we tried to use EJB 3.0 and failed miserably. The End. • The main issues with using EJB 3.0 are – It is a new technology, so documentation on it is very sparse – It is still evolving and changing, which can cause problems (e.g. JBoss 4.0.3 vs 4.0.4) – The development and deployment is significantly different from EJB 2.1, which introduces a new learning curve – It is not something that can be learned in one weekend… Team Slackers - Park 'n Park 62 Other Features Bells and Whistles • Replication manager can be restarted • Replication manager can handle an arbitrary number of servers • Any server can be dynamically added and removed due to no hard-coding • Cars can magically teleport in and out of parking lots (for testing robustness) • Clients can manually corrupt the server’s database connection (for testing robustness) • Use the Java Reflection API in the client to consolidate fault detection and recovery code • Prevents Sun’s CORBA implementation from spewing exception stack traces to the user • Highly-modularized dependency structure in the code (as proved by Lattix LDM) • Other stuff that we can’t remember … Team Slackers - Park 'n Park 63 Other Features Lessons Learned • • • • • • • • • It’s difficult to implement real-time, fault tolerance, and high performance, especially if it is not factored into the architecture from the start Choose an application that will permit you to easily apply the concepts learned in the class Don’t waste time with bells and whistles until you have time to do so Run your measurements before other teams hog and crash the server Set up your own database server Kill the server such that logs are flushed before the server dies Catch and handle as many exceptions as possible It’s a good thing that we did not use JBoss! Use the girltalk server because no one else is going to use that one … Team Slackers - Park 'n Park 64 Other Features … Painful Lessons Learned • Most painful lessons learned: 1. 2. 3. The EJB concept takes time to learn and use EJB 3.0 introduces another learning curve JBoss provides many, many configuration options, which makes deploying an application a challenging task 4 – 10. Don’t try to learn the concepts of EJB… …and EJB 3.0… …and JBoss… …all at the same time… …in one weekend… …especially when the project is due the following Monday… …!!!!!!!!!!!!!!!!!!!! Team Slackers - Park 'n Park 65 Conclusions Team Slackers - Park 'n Park 66 Conclusions If we had the Time Turner!! • We would start right away with CORBA, (100+ hours were a little too much) • And we just found out… … would have counted the number of invocations in the experiments before submitting Team Slackers - Park 'n Park 67 Conclusions …the final word. Yeayyyyyyyyyyyyyyyyyyyyyyyyyy!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! Team Slackers - Park 'n Park 68 Thank You. Team Slackers - Park 'n Park 69