Generic Access to Synapses EHCR Data
advertisement

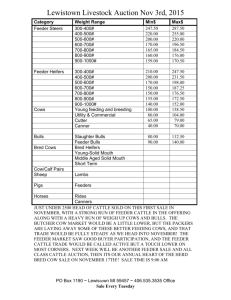
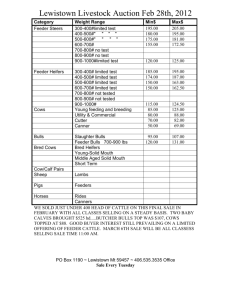
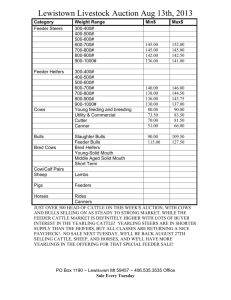
Generic Access to Synapses EHCR Data Jesús Bisbal, Gaye Stephens, Jane Grimson Department of Computer Science, Trinity College Dublin, Ireland. Abstract: The idea of collecting data from various sources and federating them in an open, generic and secure way to form a welldefined electronic healthcare record (EHCR) was the focus of the Synapses project. These data sources are referred to in Synapses terms as Feeder Systems. This paper reviews common types of Feeder Systems supported by current healthcare information systems, it describes the data they contain and presents a uniform mechanism of retrieving this data. 1. Introduction Synapses [Grimson98] was an ambitious project funded under the fourth framework of EU projects. The project ran for three years and was completed in January 1999. The focus of the project was to collect data from a variety of heterogeneous data sources and federate them in an open, generic and secure way to form a well-defined Electronic Patient Record (EPR). In Synapses terms, the data sources from which the EPR takes its data are known as Feeder Systems. These feeder systems are autonomous and highly heterogeneous, e.g. laboratory instruments, Laboratory Information Systems, Digital Imaging Systems, Patient Monitors, and even other Synapses servers. Two main concepts underpinning Synapses are the Synapses Object Model, or SynOM, and the Synapses Object Dictionary, or SynOD [Grimson98]. These ensure the flexibility needed in order to allow data from various medical fields to be represented and yet have the required consistency and security to ensure that patient records are transferred faithfully. The SynOM, rather than being a static model, is a collection of building blocks together with rules indicating how these blocks must be aggregated. Using these blocks and the aggregation rules, a healthcare organisation, department or professional can define their own healthcare record. It is this definition which comprises the SynOD. The SynOD contains the following information: • a definition of the structure of a particular record • details of where to source data to populate the defined structure • the type of access required to retrieve data from the appropriate Feeder System • the query to be issued to retrieve the relevant data It is important to note that a SynOD does not contain any patient data. The patient specific data is retrieved from the feeder systems in response to appropriate queries from the server and are appended to the EPR at runtime. In summary each site uses the same SynOM, while each SynOD is site specific. In the Synapses project there were five sites each representing different aspects of the medical domain and each building a Synapses server based on a common SynOM. The Synapses server referred to in this paper was designed and implemented by the site comprising institutions based in Dublin and Uppsala and was concerned with a healthcare record for the Intensive Care Unit (ICU). The reference site was St. James’s Hospital, Dublin. The Server which was designed and implemented by this group is known as the Dublin Synapses Server. As an additional part of the Synapses Server a software tool, the Record Structure Builder [Grimson98], or RSB, was designed and implemented (see Figure 1). An enduser (e.g. clinician) can use the RSB to specify the record components which comprise a SynOD. A data administrator can use it to specify the Feeder System(s) and query(s) to be used to populate the specified record components. It should be noted that the specification of the healthcare record and the queries can only reflect what the Feeder system returns. Feeder Systems are autonomous. They are also commonly legacy systems [Bisbal99], which means they are frequently inflexible providing data to external systems in one single pre-defined format. It is not therefore either feasible or desirable for a Synapses Server to dictate new requirements or expect the Feeder System to be re-engineered simply to ease co-operation with the Server. CGI Server Wrapper HTTP XML Client IIOP Web Server IIOP CORBA Server Wrapper IIOP Synapses Server Kernel ... IIOP Visual Basic Client Feeder systems C++ Client SynOD Record Structure Builder (RSB) Figure 1. Dublin Synapses Server Context Diagram Figure 1 shows a context diagram including the Synapses server, the set of clients currently implemented, the feeders systems containing patient data, the Record Structure Builder, and the SynOD. This Figure represents the architecture of the Server, showing how it interacts with the clients, the SynOD, the RSB, and the Feeder Systems. This remainder of the paper is organised as follows. The next section outlines the problems which arise from the need to access different types of Feeders Systems. Section 3 describes the different types of data from which the Dublin Synapses Server is currently retrieving data. The tool that provides a uniform access to this data, the Generic Adapter, is analysed in section 4. The final section summarises the paper and gives a number of future directions for this research. 2. Accessing Disparate Feeder Systems Types In hospitals and at healthcare providers’ sites there is an increasing trend to store patient data in electronic format. It is even possible nowadays to store this type of data in ambulatory situations or even in palm held devices. Healthcare data is inherently distributed and heterogeneous, varying, for example, in terms of content, storage format, and location. Integrating these disparate types of data would ease the data access possibilities of healthcare providers, assisting the decision making process, and ultimately improving the service offered to end users. In some instances integration engines [March90] have been used and in other situations proprietary (ad-hoc) solutions have been applied. Integration engines provide an interim solution to the problem of facilitating the exchange of data. Ad-hoc solutions, based on proprietary interfaces, are usually feasible for small healthcare centers and where the number of different types of data to be integrated is small. However neither approach is sufficiently generic or scaleable and would lead to considerable work and complexity when adding new feeder systems or adapting to changes in existing feeders. To deal with the storage format and location issues, Synapses has taken the following approach: 1. All Feeder Systems must provide their registered name and the access method(s) they support, e.g. ODBC (see section 3). These details are entered into a Feeder Systems information database (see section 4). 2. At runtime the Synapses server can use these details to determine Feeder System location and the type of connection to make. As these details are not used until runtime it means that the location or the access method can be changed as long as the new details are entered into the Feeder Systems information database. The third issue concerns the shape or organisation of the retrieved data. This is an important issue in Synapses as the EPR and the queries to retrieve the data populate the EPR are defined independently and can be redefined as required without changing the server. To address this issue, a generic data container (referred to in Section 4 as Generic Adapter) was designed to hold the data and its metadata. Using this data container the Synapses server can: • determine what the Feeder Systems returns (data/metadata) • populate the record by matching the metadata to the definition of record components provided by the end-user in the SynOD. Before the means of accessing Feeder Systems is described it is of interest to take a look at the type of Feeder Systems accessed by the Synapses server and the type of data they contain. 3. Feeder Systems Accessed by the Synapses Server The medical domain of interest to the Dublin Synapses server during the project was the Intensive Care Unit (ICU) and as a result the majority of Feeder Systems accessed reflected the type of data produced, required and stored in this domain. Table 1 shows the Feeder System names and the type of medical data accessed in Synapses. The Patient Management System (PMS) is a MS-Access application that is used in the ICU and comprises a database, a graphical user-interface and data processing. It is only the database part of the application that is of concern in this paper. In the case of the Laboratory Information System (LIS) the hospital runs a batch program to download information from the Telepath LIS into an MS-Access database. The Hospital Information System (HIS) was an emulated Feeder System as access to the hospital’s HIS was not possible. The Blood Gas Analyser and the Merlin Monitor downloaded their results to MS-Access databases which could then be used as Feeder Systems. Feeder System Name Patient Management System Hospital Information System Laboratory Information System Blood Gas Analyser Merlin Monitor Medical Data retrieved Admissions details Prognosis details Social details Demographic details Laboratory investigation results Laboratory investigation results performed at near bedside blood gas analyser Vital signs collected from monitors attached to patient. Table 1. Data Types Accessed in Synapses As far as the Synapses Server is concerned, all five Feeder Systems are MS-Access databases, although the data may have originated from other databases. An MS-Access database uses the Relational Model [Codd70] where data are contained in tables and each table is described by columns and rows. For all these Feeder Systems the type of medical data varies but the data format is the same. This means that the names of the columns, the type of data they could contain and the actual data values contained in the rows varies for each Feeder System. However, the fact that the data are stored in tables with rows and columns is the same for each, which reduces the level of syntactic heterogeneity facilitating concentration on the more difficult semantic issues surrounding interoperability between systems. The access method used to retrieve data from these Feeder Systems is Open Database Connectivity (ODBC), a de facto standard for data access. For each ODBC retrieval from a Feeder system, the Synapses server determined the type of data in each column and the name of the column. Since the end of the Synapses project, work has continued on the Synapses Server under a new project Synex [SynEx99, Ferrara99]. Synex is concerned with integrating a selection of components which were developed in previous EU projects. As a result of this collaboration, the Server has been used to access two other types of Feeder Systems not directly linked with the ICU, namely Distributed Health Environment (DHE) [Gesi99] based Feeder Systems and eXtensible Markup Language (XML) [Connolly97] based Feeder Systems. These two types of Feeder Systems are described in the next Sections. 3.1 DHE-Based Feeder Systems The Distributed Health Environment (DHE) is an implementation of the Health Information System Architecture (HISA) [HISA97] standard and is currently being used in a number of European hospitals. DHE is a system architecture used to encapsualte healthcare information and services provided on this data. This type of system could be used in a hospital department to encapsulate data or it could be used to encapsulate the data of an entire hospital or group of hospitals. At present Synapses views DHE as a Feeder System, i.e. a source of data. In the initial prototype, the Synapses server will support the retrieval of patient demographic data from DHE. 3.2 XML-Based Feeder Systems The second Feeder System type to which an interface has been developed is eXtensible Markup Language [Connolly97] (XML) based Feeder Systems. From Synapses point of view, an XML-based Feeder System is one which can provide data in XML format. It is unlikely that the actual feeder systems themselves will actually store the data as XML documents. But rather in the same way as SQL interfaces have been provided to nonrelational databases, so there is increasing interest in providing tools which extract data from a variety of different databases and present it in the form of standard XML Documents. XML is becoming the de facto standard for universal structured document format. An XML document contains both data and a description of its organisation, that is, its metadata. The organisation is achieved using tags in much the same way as tags are used in HTML to generate web pages. In HTML tags could be used to specify that a piece of text is to be presented in boldface, e.g. <bold> boldtext </bold> where <bold> and </bold> are the tags. In HTML the tags are prespecified whereas in XML new tags can be created and used. The definition of the tags and rules governing their usage are entered into a file called a Document Type Definition, or DTD. The XML-based Feeder System being used for the SynEx project prototype supplies Renal laboratory investigation results. In summary, the Synapses server can issue queries to ODBC, DHE and XML-based Feeder Systems. In each case the returned data is accompanied by its metadata thereby ensuring that the data can be correctly interpreted by the Synapses Server. In this way the Feeder Systems can to some extent evolve independently of the Synapses server. The Synapses Server component which performs connections to these three types of feeder systems, retrieves data from them and passes it back to the Synapses Server is called the Generic Adapter. This component is described in the next section. 4. Generic Adapter – Uniform Access to Data Sources As the functionality of the Dublin Synapses Server was extended it required access to a wider variety of data sources was required. The initial architecture of the Server, shown in Figure 1 of Section 1, assumed that the Server itself would handle the connections to these Feeder Systems and would retrieve the appropriate data. This architecture, therefore, required that the Synapses Server implemented a significant amount of functionality that was not directly related to creating EPRs. Also, this approach was not flexible since adding support for a new Feeder System type involved making changes to the Server, leading to a significant amount of additional work and increased complexity. For all these reasons, a new component has been incorporated into the architecture of the Dublin Synapses Server. This module, called the Generic Adapter, isolates the Server from the details of connecting to Feeder Systems and retrieving data. It also provides a well-defined interface through which the Server retrieves the required data, independently of the type of Feeder System. The ultimate goal of the Generic Adapter is to provide the Server with a Uniform View to the data in the Feeder Systems, making the overall architecture more modular, flexible, extensible, and scaleable. The resulting architecture is shown in Figure 2. This figure focuses on how the Synapses Server accesses Feeder System data. All clients shown in Figure 1 of Section 1, as well as the RSB, remain as before, although for simplicity they are not included in Figure 2.. When the Server needs to retrieve data from any Feeder System it will send a Generic Query to the Generic Adapter. This Generic Query contains information about the Feeder System to be queried and the information needed to retrieve the appropriate data. For example, in case of a relational database this Generic Query would contain the y IIOP ... DHE IIOP CORBA Server Wrapper DHE Data DHE API Generic Query Synapses Server Kernel ODBC API Generic Adapter Generic Result Relational Database XML Feeder Interface SynOD Feeder Info Mediator Data Source Figure 2. Dublin Synapses Server Architecture with the Generic Adapter name of the database and an SQL query. All this information is stored in the SynOD and can therefore be accessed directly by the Server. The Generic Adapter stores the information required to connect to the specified data source (location, IP address, password, etc.) in a database called Feeder Info in Figure 2. It also stores information about the type of data source to which the query refers, so that it can use the appropriate query mechanism. Figure 2 shows the three different types of data sources accessed by the current implementation of the Synapses server, as explained in Section 3. Relational data is accessed via ODBC Application Program Interface (API); DHE provides its own API to be used to retrieve its data; and finally an interface to an XML-based data source, called Mediator [Xu99], is currently under development. The query submitted to the Mediator is wrapped in XML, and the result is also in XML format. Potentially, the Mediator service can access any type of data source, which potentially allows the Server to retrieve data from a wide range of additional Feeder Systems. The Generic Adapter will handle the details of retrieving the data from each particular type of Feeder System, and will return this data structured as defined by a Generic Result type (see Figure 2). This type has been designed (see section 4.1) so that it can represent all the different types of data sources currently under consideration, i.e. relational data, DHE data and XML documents. It can be seen how, from the point of view of the Synapses Server Kernel, there is only one type of query, Generic Query, and one type of result, Generic Result. This greatly simplifies the workings of the Server and leads to a more flexible and extensible architecture. Adding support for a new data source would now only require expanding the functionality of the Generic Adapter so that it can query this type of data source, and then map the resulting data into the Generic Result type. The important benefit of this architecture is that the Server would does not need to know about the incorporation of this new Feeder System type. One last component of this architecture is what in Figure 2 is termed Feeders Interface. This module, tightly coupled with the Synapses Server Kernel, is responsible for interpreting the Generic Results returned by the Generic Adapter. The Generic Adapter is used to populate the healthcare electronic records the clients request from the Server. However, this is a generic module, without knowledge of the healthcare domain or healthcare records. The results it returns must be interpreted in different ways, depending on which kind of Feeder System supplied the data. This interpretation is done by the Feeder Interface, which maps data from the Generic Result into Record format. This module is clearly separated form the Server, although tightly related to it. Using this module, all the Server needs to request is for a particular part of a Record to be populated. The Feeder Interface will request the data from the Generic Adapter, and then interpret the result appropriately to map it into Record format. The combination of the Generic Adapter and Feeder Interface provides uniform access to disparate data sources, and gives this data the appropriate semantics to be used to build an EPR. 4.1 Generic Adapter Design The overall design of the Generic Adapter is shown in Figure 3. This is a UML Class Diagram representing the fact that different kind of queries (termed Statements) can be executed, namely queries to ODBC, DHE, or XML –based Feeder Systems. A connection to each of these Feeder Systems will therefore be required, which is also represented as different specialisation of the abstract class Connection in Figure 3. It is likely that the Server will send multiple queries to the same Feeder System over time (to populate different records, for example). Each of these queries would require a Connection to the Feeder System. In order avoid creating a new connection for each query, and therefore to reduce the overall time involved in connecting to Feeder Systems, another class, termed Connection Manager, has been introduced in Figure 3. This class will manage all existing connections, so that when a new query is executed it will re-use existing connections if possible. Source Manager contains Connection Manager 0..* Connection Statement produces ODBCConnection DHEConnection MediatorConnection ODBCStatement DHEStatement XMLStatement ResultSet +data +metadata 1..* 1..* describes Element 1..* Tuple XMLDocument 0..* Attribute MetaElement 1 TupleMetadata DTD 1..* AttributeMetadata Figure 3. Generic Adapter Design (Core) - UML Class Diagram As explained in the previous section there is a database, called FeederInfo, which is used to store details of the particular Feeder Systems available to the Server. A class, termed Source Manager in Figure 3, has been used to manage this database and provide an easy interface to the Connection Manager when it requires information in order to connect to a particular Feeder System. Finally, the Generic Result, referred to above, is shown in this Figure 3 as a class termed ResultSet. It can be seen how this consists of a list of type Elements (e.g. Tuple), each of them associated with their own description (termed MetaElement). This list of elements does not need to be homogenous, i.e. the design allows for one single ResultSet to store tuples, XML documents, etc, as a single result if required. The design of this Generic Result type is believed to be highly flexible. Only experience and the addition of support for new Feeder System types which have not yet been envisaged will prove whether it really is sufficiently flexible. The most clear design pattern that appears in this UML Class Diagram is the heavy use of inheritance in order to keep the design as extensible as possible, abstracting the different types of queries, connections and results. For example, if a new Feeder System type was to be added, all that would only be required would be new specialisations for types Connection and Statement. Although not shown in Figure 3, these two classes define an Interface which all specialisations must implement if they are to inherit from them. Once this interface is implemented, newly developed classes can be seamlessly integrated in this design providing access to a new Feeder System type. The generic adapter was implemented using Visual C++ v5.0 on a Windows NT 4.0 platform. It was compiled into a Library (.LIB) which could be accessed by the Synapses server. The Library is a separate piece of compiled code from the calling application and thus has the advantage of being developed independently of the caller so long as the interface to the methods remains unchanged. In the case of the XML-based and DHE-based Feeder Systems the Common Object Request Broker Architecture (CORBA) [Orfali97] communication handler was used. 5. Conclusions The Generic Adapter was designed and implemented as part of the Synapses server. It is capable of retrieving data from a number of disparate Feeder Systems. These Feeder Systems differ in the following ways 1. Location 2. Type of medical data they contain. 3. Storage format of the data. 4. Arrangement of the data. Through the use of a common interface offered by the Generic Adapter the Synapses server can issue queries to these types Feeder Systems in a uniform fashion. The result of the queries which includes the data and the metadata is transferred to the Synapses server in a uniform way. The Synapses server can use the metadata to interpret the result of the query. As well as addressing access to different types of Feeder Systems the Generic Adapter has focused on two other issues namely performance and extendibility: 1. Through its policy of managing the Feeder System connections, the number of Open and Close operations issued to the Feeder System is minimised 2. The Generic Adapter has been designed with a view to ease the incorporation of other Feeder System types The next type of Feeder system to be connected is one that contains images – a completely new data type - and this will provide a significant test of the genericity and flexibilty of the Generic Adapter. Finally the Generic Adapter was designed and implemented as a component of the Synapses server for the medical domain. It could, however, be applied to any other domain in which integrated access to heterogeneous, autonomous, distributed data sources was required. It must be emphasised that the objective when developing the Generic Adapter was only to provide a flexible and efficient solution to the problem at hand, that is, accessing different data sources to provide data to the Synapses Server. The Generic Adapter does not pretend to be a solution to the problems presented by more sophisticated approaches of dealing with distributed information, like distributed and heterogeneous databases [Bell92][March90]. 6. References [Bell92] D. Bell, and J. Grimson. ‘Distributed Database Systems’, Addison-Wesley Longman, Reading, Mass., 1992. [Bisbal99] J. Bisbal, D. Lawless, B. Wu, and J. Grimson. ‘Legacy Information Systems: Issues and Directions’, IEEE Software, 16(5), pp.103-111, Sep./Oct. 1999. [Codd70] E.F. Codd. ‘A Relational Model of Data for Large Shared Data Banks’, Communications of the ACM, 13(6), pp. 377-387, 1970. [Connolly97] D. Connolly, Editor. ‘XML – Principles, Tools and Techniques’, World Wide Web Journal, 2(4), Fall 1997. [Ferrara99] Ferrara, F.M., Grimson, B., The holistic architectural approach to integrating the healthcare record in the overall system, Proceedings MIE99, IOS Press, pp. 847-852, 1999. [Gesi99] http://www.gesi.it. [Grimson98] J. Grimson, W. Grimson, D. Berry, G. Stephens, E. Felton, D. Kalra, P. Toussaint, and W. Weier. ‘A CORBA-based integration of distributed electronic healthcare records using the Synapses approach’, IEEE Trans. on Information Technology in Biomedicine, 2(3), pp. 124-138, Sep. 1998. [HISA97] ‘Healthcare Information System Architecture’, CEN/TC251 prENV12967. [March90] S.T. March, Editor. ‘Special Issue on Heterogeneous Databases’, ACM Computing Surveys, 22(3), 1990. [Orfali97] R. Orfali, D. Harkey, J. Edwards. ‘Instant CORBA’, Wiley, 1997. [Synex99] SynEx Homepage, http://www.gesi.it/synex/. [Xu99] Y. Xu, D. Sauquet, E. Zapletal, and P.P. Degoulet. ‘Using XML in a Generic Model of Mediators’, Proceedings of XML Europe’99, pp. 697705, April 1999, Granada, Spain.