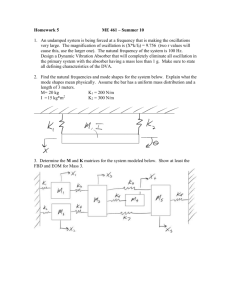
Randomly Generating Computationally Stable Correlation Matrices Mark Simon Advisors: Jo Hardin, Stephan Garcia
advertisement

Randomly Generating Computationally Stable Correlation
Matrices
Mark Simon
Advisors: Jo Hardin, Stephan Garcia
Contents
List of Figures
5
Chapter 1.
7
Motivation
Chapter 2. Derivation of the Algorithm
1. The eigenvalues of E, Σ and S
9
10
Chapter 3. Simulations Conducted to Evaluate the Algorithm
1. The effects of our algorithm on the condition numbers of matrices
2. How different are S and Σ?
15
15
20
Chapter 4. Extensions of our algorithm
1. Multiple δi
2. Block Diagonal Correlation Matrices
3. Make some ρij for Σ negative
4. Some concluding remarks
23
23
24
26
26
Bibliography
27
3
List of Figures
1
Pairs plot of the dimension of our matrices (Dimension.S) versus the true value of κ(S) (True.K)
and our estimate of the upper bound of κ(S), κmax (S) (Upper.Bound.K). The dimension of S was
varied over [500,1000] in increments of 50 and 100 matrices were generate from each set of parameter
values.
15
2
Pairs plot of the dimension of our matrices (Dimension.S) versus R’s estimate of κ(S) (R.Estimate.K)
and our estimate of the upper bound for κ(S), κmax (S) (Upper.Bound.K). The dimension of S
was varied over [500,1000] in increments of 50 and 100 matrices were generate from each set of
parameter values.
16
3
Pairs plot of the δ used to generate each matrix S (Delta.S) versus the true value of log(κ(S))
(Log.True.K) and log(κmax (S)) (Log.Upper.Bound.K). The plot was done on log scales for condition
numbers and estimates of condition numbers because of the wide range of observed condition
numbers in these simulations.
16
Pairs plot of the δ used to generate each matrix S (Delta.S) versus R’s estimate of κ(S)
(R.Estimate.K) and log(κmax (S)) (Log.Upper.Bound.K). The plot was done on log scales for
condition numbers and estimates of condition numbers because of the wide range of observed
condition numbers in these simulations.
17
4
5
Plot of the average true condition number for matrices constructed by increasing δ + ρ = c from
c = .8 to c = .99 while letting δ, ρ be uniformly distributed random variables over [0.0, c]
18
6
Plot of the average true condition number for matrices constructed varying δ from 0 to .99 while
setting ρ = 0.8. Note that the values of c = ρ + δ will still go from c = .8 to c = .99 in this set of
simulations
18
7
The average condition numbers found from matrices with randomly varied ρ + δ subject to the
constraint ρ + δ = c (red) and the average condition numbers of matrices generated from ρ = .8 and
δ increasing monotonically (blue) plotted against the values of c used to generate each set of 100
matrices from c = [.8, .99]
19
8
The Frobenius norm distance between S, Σ0 (Frobenius.Norm.Distance), the values of δ used to
generate S (Delta.S) and the P-value of Box’s M test for the hypotheses that S and Σ0 are different
(Box.M.Test.pvalue)
21
9
The Modulus norm distance between S, Σ0 (Frobenius.Norm.Distance), the values of δ used to
generate S (Delta.S) and the P-value of Box’s M test for the hypotheses that S and Σ0 are different
(Box.M.Test.pvalue)
22
5
CHAPTER 1
Motivation
Correlation is a measure of the strength of the linear relationship between two variables. A correlation
matrix is a p × p matrix whose entries are pairwise correlations. They are important for studying the
relationships between random variables in many contexts ranging from modeling portfolio risk in finance
to understanding the interactions between genes in microarray data from genetics. Many applications of
statistics involve large data sets and the correlation structure of the data is sometimes a topic of primary
interest [2]. As a result, it would be useful to be able to randomly generate realistic correlation matrices to
perform simulation studies in order to gain a deeper understanding of correlation structures. One approach
to performing simulation studies on a particular correlation structure is to generate random variables and
determine the correlation structure of the random variables. However, generating random variables and
computing matrices from them is a highly inefficient way of randomly generating correlation matrices and
would not necessarily produce every possible correlation matrix because of distributional assumptions which
must be made about the random variables in order to generate the correlation matrices from them.
A different tactic is to try to generate a random correlation matrix directly. This is more difficult
than it might first appear. Correlation matrices have a number of required properties and using them for
simulations further requires that they be invertible in a computationally feasible manner. Four criteria
characterize correlation matrices:
(1) each entry of the matrix must have absolute value less than or equal to 1,
(2) each entry on the main diagonal must be 1,
(3) the matrix must be real symmetric, and
(4) the matrix positive semi-definite.
Further, every matrix with these properties is a correlation matrix (see Remark 2). We impose an additional
requirement, namely that a correlation matrix be computationally invertible. This creates the constraint
that our correlation matrix must have a lowest eigenvalue which is bounded away from zero and a greatest
eigenvalue which is bounded below infinity. Matrices which cannot be inverted computationally cannot be
used for simulation studies. We seek to design an algorithm which will allow us to satisfy the necessary
criteria as well as our additional desired property of computational invertibility.
The approach we take to generating random correlation matrices is to provide an algorithm to perturb
an initial correlation matrix with known eigenvalues. We derive this algorithm in Chapter 2. We then
evaluate the effectiveness of our algorithm by conducting simulations in Chapter 3. Finally, we conclude
with a number of natural generalizations of our method in Chapter 4.
7
CHAPTER 2
Derivation of the Algorithm
Our goal in this section is to describe a method which allows us to generate random computationally
invertible correlation matrices and to prove that the matrices which we create will have a controlled degree
of computational instability. First we consider what it means for a matrix to be positive.
Definition 1. Let T be a matrix or vector, then T ∗ is the conjugate transpose of T . For real symmetric
matrices T , T ∗ = T . A square matrix is self-adjoint if T ∗ = T .
Definition 2. A p × p self-adjoint matrix, T , is positive semi-definite if z ∗ T z ≥ 0
is positive definite if z ∗ T z > 0 ∀ z ∈ Cp such that z 6= 0.
∀
z ∈ Cp and T
Obviously, it would be impractical to check if z ∗ T z > 0 for all z 6= 0, so instead we rely on an alternative
characterization of positivity for matrices.
Definition 3. Let T be a p × p matrix. Denote the eigenvalues of T repeated by their multiplicity in
decreasing order as
λ1 (T ) ≥ . . . ≥ λp (T ).
Remark 1. [3, Observation 7.1.4] T is positive definite if and only if all eigenvalues of T are positive
real numbers.
Therefore, we can randomly generate positive definite matrices if we can control the eigenvalues of the
random matrix. We now consider in more detail the criteria which characterize correlation matrices. In
particular, we will derive a sufficient criteria to ensure that a matrix is a correlation matrix.
Remark 2. Every real symmetric positive semi-definite matrix with a main diagonal of 1s and off
diagonal entries with absolute value less than or equal to 1 is a correlation matrix.
Proof. First, observe that every positive semi-definite matrix is a covariance matrix [6]. Now, note
that every covariance matrix with unit variance is a correlation matrix. Matrices with unit variance have a
main diagonal of 1’s and off diagonal entries with absolute value less than or equal to 1.
Now that we understand the most relevant characterizations of positivity for matrices and the sufficient
criteria to ensure a matrix is a correlation matrix, we can begin to design our algorithm to generate correlation matrices. We begin with a correlation matrix having all off diagonal entries equal to ρ where 0 < ρ < 1.
Then, we perturb the matrix by adding noise of at most magnitude δ where 0 < δ < 1 to each term. Further,
we choose ρ and δ subject to the constraint ρ + δ < 1. Now, construct a matrix Σ ∈ Mp×p with all off
diagonal entries equal to ρ and all diagonal entries equal to 1 − δ. That is:
Σ=
1−δ
ρ
..
.
ρ
1−δ
..
.
...
...
..
.
ρ
ρ
..
.
ρ
ρ
...
1−δ
9
10
2. DERIVATION OF THE ALGORITHM
√
Then we randomly choose p ei ’s ∈ Rm such that kei k = δ and construct their Gram matrix, E
δ
he1 , e2 i . . . he1 , ep i
he2 , e1 i
δ
. . . he2 , ep i
E=
..
..
..
..
.
.
.
.
hep , e1 i hep , e2 i . . .
δ
Note that choosing the ei from Rm with p > m will tend to produce a Gram matrix with off diagonal entries
with magnitude closer to δ than choosing ei from Rm with p < m at the expense of introducing linear
dependence to the rows of the E. However, if we draw p ei ’s from Rm with p < m, then hei , ej i will tend to
be closer to zero because it is more likely we will choose mutually orthogonal ei ’s.
Now, define S = Σ + E. The absolute value of each off diagonal entry of S is strictly less than 1 because
|hei , ej i| ≤ δ for i 6= j, so we are adding at most δ to each off diagonal entry ρ. We chose δ such that
ρ + δ < 1, so we know that each off diagonal entry must be less than or equal to 1 in absolute value.
. . . ρ + he1 , ep i
. . . ρ + he2 , ep i
..
..
.
.
ρ + hep , e1 i ρ + hep , e2 i . . .
1
Thus, all that remains in order to show that S is a correlation matrix is to establish that S is positive
semi-definite. However, we will actually establish a stronger result. We argue that S is positive definite. In
order to show that S is positive definite, we will need to establish a bound on λp (S) which is strictly greater
than zero. To establish a bound on λp (S), we will consider the eigenvalues of E and Σ.
1
ρ + he2 , e1 i
S=
..
.
ρ + he1 , e2 i
1
..
.
1. The eigenvalues of E, Σ and S
In order to find a bound for λp (S) we will find bounds for each of λp (E) and λp (Σ). Consider the
matrix E first. We argue that all Gram matrices are positive semi-definite, so E must be at least positive
semi-definite. To see why all Gram matrices are positive semi-definite, consider that E can be factored as
E = A∗ A where A∗ , A ∈ Mp×p and A is the matrix with columns composed of the vectors ei .
A = e1 e2 · · · ep
Clearly, A∗ is the matrix with the vectors ei as rows. Note that A∗ A is positive semi-definite because, for
for all v ∈ CP , hA∗ Av, vi = hAv, Avi = kAvk2 ≥ 0 by positivity of the norm. Therefore, E is positive
semi-definite which implies that λp (E) ≥ 0.
Now, we argue that Σ is positive definite. First, we re-write Σ:
Σ = (1 − ρ − δ)Ip×p + P
where P is the p × p matrix of ρ’s.
ρ
ρ
P = .
..
ρ
ρ
..
.
...
...
..
.
ρ
ρ
..
.
ρ ρ ... ρ
Further, rank(P ) = 1, so p − 1 of the eigenvalues of P are zero and the only non-zero eigenvalue of P can be
readily computed as pρ. The only eigenvalues of (1 − ρ − δ)Ip×p are equally easy to find, they are p copies of
1 − ρ − δ. Now we consider the eigenvalues of Σ = (1 − ρ − δ)Ip×p + ρP . We observe that adding a multiple
of the identity to a matrix linearly shifts the eigenvalues of the matrix.
1. THE EIGENVALUES OF E, Σ AND S
11
Remark 3. Let A be a p × p matrix with eigenvalue λi (A) for i = 1, 2, . . . , p and let c ∈ R, then
λi (A + cI) = λi (A) + c
i = 1, 2, . . . , p.
Proof. If Avi = λi (A)vi for some λi (A) with vi 6= 0 then to find the eigenvalues of A + cI:
(A + cI)vi = Avi + cIvi
= λi (A)vi + cvi
= (λi (A) + c)vi
(A + cI)vi = (λi (A) + c)vi
∀ λi (A).
Therefore, the eigenvalues of A + cI are λi (A) + c.
We apply this result to Σ and find that c = 1 − ρ − δ and A = (1 − ρ − δ)Ip×p . Thus, we know all the
eigenvalues of Σ because Σ = (1 − ρ − δ)Ip×p + P . In particular, the eigenvalues of Σ are the eigenvalues of
P shifted by 1 − ρ − δ.
Remark 4. The spectrum of Σ is:
λ1 (Σ) = pρ + 1 − ρ − δ,
λ2 (Σ) = . . . = λp (Σ) = 1 − ρ − δ
So, we find that the lowest eigenvalue of Σ is 1 − ρ − δ. Note that we chose ρ + δ < 1, so this is greater than
zero. Therefore, Σ is positive definite. We now argue, by establishing bounds on λp (S) that S is, in fact,
positive definite. In particular, we claim that 1 − ρ − δ ≤ λp (S). Our argument will utilize a form of Weyl’s
Inequalities [1, Cor. III.2.2].
Theorem 1 (Weyl’s Inequality). Let A, B be p × p self-adjoint matrices, then for 1 ≤ j ≤ p:
λj (A) + λp (B) ≤ λj (A + B) ≤ λj (A) + λ1 (B)
Result 1. Let S = Σ + E. Then 1 − ρ − δ ≤ λp (S).
Proof. From Weyl’s Inequality, we set A = Σ and B = E, so that the statement of the theorem
becomes
λj (Σ) + λp (E) ≤ λj (S = Σ + E).
Now set j = p, and we have that
λp (Σ) + λp (E) ≤ λp (S)
As previously showed, λp (Σ) = 1 − ρ − δ. Further, recall that λp (E) ≥ 0 because E is positive semidefinite. We can now find a lower bound for λp (S) by combining inequalities
λp (Σ) ≤ λp (Σ) + λp (E) ≤ 1 − ρ − δ ≤ λp (S). We have now finished our proof of the bound on the smallest eigenvalue of S and demonstrated that S is
positive definite because this lower bound is strictly positive. This means that we have now established
that S is a correlation matrix because it satisfies the required properties for correlation matrices Remark
2 However, we have not yet defined what it means for a matrix S to be computationally stable formally,
let alone shown that our S will be computationally stable, so while we are guaranteed based on our work
thus far that S will be a positive definite correlation matrix, it would not necessarily be computationally
12
2. DERIVATION OF THE ALGORITHM
invertible. We will first formalize notions of computational stability and then show that S is computationally
stable in the next section.
1.1. Bounds for the Condition Number of S. The computational stability of a matrix can be
thought of intuitively as a means of measuring the impact of small errors on the solutions to a system of
linear equations. We provide an example to help build intuition.
Example 1 ([4]). Let
11 10 14
A = 12 11 −13, then
14 13 −66
−557 842 −284
A−1 = 610 −922 311
2
−3
1
Consider the solutions to Ax = b for
−.683
1.001
b = .999 , x = .843
.006
1.001
Now let
1.00
1
b0 = 1.00 then x0 = −1
1.00
0
0
This is a large change in the solution from x to x for a seemingly minuscule change from b to b0 . Matrices
which are sensitive to rounding errors cannot be inverted computationally and are said to be computationally
unstable.
There is a measurable quantity which will allow us to determine the extent to which a matrix will exhibit
sensitivity to small changes such as the one in the previous example and whether or not the matrix can be
computationally inverted.
Definition 4. Let T be a positive semi-definite matrix, then the condition number of T is defined as
λ1 (T )
.
λp (T )
Denote the condition number of T as κ(T ).
Recall that S is positive definite. Thus, our construction of S will let us impose a bound on κ(S) if we
can bound both λp (S) and λ1 (S). We have already found that λp (S) is bounded below by 1 − ρ − δ. Thus,
all that remains is to bound λ1 (S) from above.
We claim that λ1 (S) ≤ pδ + pρ + (1 − δ − ρ). However, we will need to mimic the approach we used to
bound λp (S) and first estimate λ1 (Σ) and λ1 (E). We begin with λ1 (E) using Gerschgorin’s disk theorem [3,
Theorem 6.1.1] and the Cauchy-Schwarz-Buniakovsky Inequality [3, Theorem 0.6.3].
Definition 5. Let A be a p × p matrix with entries (aij ), then
Ri (A) =
p
X
j=1,j6=i
|aij |.
1. THE EIGENVALUES OF E, Σ AND S
13
Also, let the ith Gerschgorin disk of A be D(aii , Ri ), where D(aii , Ri ) denotes a disk centered at aii with
radius Ri .
Theorem 2 (Cauchy-Schwarz-Buniakovsky Inequality). Let x, y be vectors in an inner product space
V , then
khx, yik2 ≤ hx, xihy, yi
Theorem 3 (Gerschgorin Disk Theorem [3]). For a p × p matrix A, every eigenvalue of A lies inside
at least one Gerschgorin disk of A.
Now we apply Gershgorin’s Disk Theorem to E to find an upper bound for λ1 (E).
Remark 5. The largest eigenvalue of E is bounded above. In particular, λ1 (E) ≤ pδ.
Proof. Applying Gerschgorin’s Disk theorem to E, we find that aii = hei , ei i = δ and Ri (E) ≤ (p − 1)δ
because each of the p − 1 off diagonal entries in row i of E will have absolute value less than or equal to δ
by Theorem 2. Therefore, if λj (E) ∈ σ(E), then λj (E) ∈ D(δ, Ri ).
|δ − λi (E)| ≤ Ri (E)
p
X
Ri (E) =
|hei , ej i|
j=1,j6=i
p
X
|hei , ej i| ≤ (p − 1)δ
j=1,j6=i
∴ |δ − λi (E)| ≤ (p − 1)δ
Recall that δ > 0, so |δ| = δ and use the triangle inequality on |λi (E) − δ| to find that:
|λi (E)| − δ ≤ |λi (E) − δ| ≤ (p − 1)δ
⇒ |λi (E)| − δ ≤ (p − 1)δ
∴ |λi (E)| ≤ pδ
Further, E is positive, so |λi (E)| = λi (E) and we conclude that λi (E) ≤ pδ
λ1 (E) ≤ pδ.
∀ λi (E). In particular,
Now that we have established a bound for λ1 (E), recall that we previously showed that λ1 (Σ) = pρ +
(1 − ρ − δ). Now that we have bounds for λ1 (E) and λ1 (Σ) we can move on to finding a bound for λ1 (S).
Result 2. Let S = Σ + E, then λ1 (S) ≤ (p)δ + pρ + (1 − δ − ρ).
Proof. We apply Weyl’s inequality with j = 1 to S
λ1 (S) ≤ λ1 (A) + λ1 (B)
∴ λ1 (S) ≤ (p)δ + pρ + (1 − δ − ρ)
Applying results 1 and 2, we now have bounds for both the lowest eigenvalue of S and the greatest eigenvalue
of S. Obviously, by definition λp (S) ≤ λ1 (S), so we have bounds ∀λi ∈ σ(S)
0 < 1 − ρ − δ ≤ λp (S) ≤ λ1 (S) ≤ pδ + pρ + (1 − δ − ρ).
Further, we now have an upper bound on the condition number κ(S).
14
2. DERIVATION OF THE ALGORITHM
Result 3.
pδ + pρ + (1 − δ − ρ)
= κmax S
1−ρ−δ
Also, let the upper bound we derived for λ1 (S) be denoted λmax
(S) and the lower bound we derived for
1
λp (S) be denoted λmax
(S).
p
κ(S) ≤
κmax (S) scales linearly with the dimension of our matrix, p. This means that we can control how easily we
can invert S is through our choice of ρ and δ for a particular matrix size. Further, κmax (S) is the optimal
upper bound for κ(S).
Definition 6. An inequality is sharp if there exist values for which equality is attained.
Our inequality κ(S) ≤ κmax (S) is sharp because we can find values of S for which κ(S) = κmax (S). In the
two dimensional case it is easily shown:
Example 2. Fix ρ, δ such that ρ + δ < 1, then:
1−δ
ρ
δ
Let Σ =
, E=
ρ
1−δ
δ
1
ρ+δ
⇒S=
ρ+δ
1
δ
δ
2ρ + 2δ + (1 − ρ − δ)
ρ+δ+1
=
1−ρ−δ
1−ρ−δ
which is exactly our estimate of the condition number κmax (S) for S in this instance.
κ(S) =
Thus, our algorithm produces matrices which are positive definite and have bounded condition numbers.
As a final note, we observe that S has controlled off diagonal entries. We now proceed to perform simulations
in order to estimate the effects of inputs ρ,δ and p on κ(S), as well as the true condition number of the
matrix.
CHAPTER 3
Simulations Conducted to Evaluate the Algorithm
1. The effects of our algorithm on the condition numbers of matrices
In order to evaluate the performance of our technique computationally, simulation were performed in
R generating matrices with dimensions of between 500 and 1000, with a step size of 50, with ρ = .8 and
δ = .1. A second set of simulations was performed varying δ from δ = 0 to δ = .199999 with a step size of
9
for 2 ≤ l ≤ 10 for ρ = .8. Each combination of parameters had 100 matrices generated from it and
10−l
we calculated three quantities for each matrix, our upper bound on the condition number κmax (S), the true
condition number of each matrix and R’s built in estimate of the condition number of S.
Figure 1. Pairs plot of the dimension of our matrices (Dimension.S) versus the true value
of κ(S) (True.K) and our estimate of the upper bound of κ(S), κmax (S) (Upper.Bound.K).
The dimension of S was varied over [500,1000] in increments of 50 and 100 matrices were
generate from each set of parameter values.
15
16
3. SIMULATIONS CONDUCTED TO EVALUATE THE ALGORITHM
Figure 2. Pairs plot of the dimension of our matrices (Dimension.S) versus R’s estimate
of κ(S) (R.Estimate.K) and our estimate of the upper bound for κ(S), κmax (S) (Upper.Bound.K). The dimension of S was varied over [500,1000] in increments of 50 and 100
matrices were generate from each set of parameter values.
Figure 3. Pairs plot of the δ used to generate each matrix S (Delta.S) versus the true value
of log(κ(S)) (Log.True.K) and log(κmax (S)) (Log.Upper.Bound.K). The plot was done on
log scales for condition numbers and estimates of condition numbers because of the wide
range of observed condition numbers in these simulations.
1. THE EFFECTS OF OUR ALGORITHM ON THE CONDITION NUMBERS OF MATRICES
17
Figure 4. Pairs plot of the δ used to generate each matrix S (Delta.S) versus R’s estimate
of κ(S) (R.Estimate.K) and log(κmax (S)) (Log.Upper.Bound.K). The plot was done on log
scales for condition numbers and estimates of condition numbers because of the wide range
of observed condition numbers in these simulations.
As can be clearly seen from the results of these simulations, p has a linear effect on the true condition number
of the the matrix, our estimate of κ(S) and R’s built in estimate, while varying δ has non-linear effect on all
of these quantities. This is what the theoretical work we did in Chapter 1 would suggest ought to be true,
so these results are consistent with our earlier theory.
We performed all the simulations used to generate the previous figures varying δ, we did not vary ρ
independently for this set of simulations. This is justified for two reasons. First, our theory suggests that
ρ + δ determines the condition number of S (Result 3). Second, the simulations reported in Figures 5,6,7
indicate experimentally that ρ, δ have similar effects on κ(S). We begin by making the theoretical argument
that ρ, δ will have identical effects on κmax (S).
Consider λ1 (S) and λp (S) separately for our estimate of κmax (S). Our upper bound for λ1 (S) was
pδ + pρ + (1 − ρ − δ) which will obviously be equally affected by changes in ρ, δ. Likewise our lower bound
λp (S) is 1 − ρ − δ which displays the same property.
Now, we move on to describing how we tested the actual effects of ρ, δ on κ(S). We performed a
simulation varying the sum ρ + δ = c from c = 0.8 to c = 0.99 using a step size of .001, while allowing
δ ∼ U [0, c] and making ρ = c − δ. 100 matrices were generated from each value of ρ + δ ∈ [0.8, 0.99] with each
matrix having a different randomly generated combination of ρ and δ. It is important to stress that in these
simulations each of the 100 different matrices generated for a particular value of c had a different value of ρ, δ.
Note that in this simulation, ρ, δ are completely dependent random variables and δ ∼ U [0, c], ρ ∼ U [0, c].
Thus, ρ, δ were varied in such a way that ρ and δ were equally likely to be any value in the interval [0.0, c] for
each c we tested in the interval [.8, .99]. The true condition number of each of these 100 matrices was then
calculated, with the results for each value of c averaged and presented in Figure 5. Compare these results
to those presented in Figure 6. In Figure 6, we created 100 matrices for each δ from δ = 0 to δ = .19,
with a step size of .001, setting ρ = 0.8 for all the matrices. We then calculated the condition numbers of
the matrices which resulted from this method of choosing ρ, δ and averaged them for each value δ.
18
3. SIMULATIONS CONDUCTED TO EVALUATE THE ALGORITHM
Figure 5. Plot of the average true condition number for matrices constructed by increasing
δ + ρ = c from c = .8 to c = .99 while letting δ, ρ be uniformly distributed random variables
over [0.0, c]
Figure 6. Plot of the average true condition number for matrices constructed varying δ
from 0 to .99 while setting ρ = 0.8. Note that the values of c = ρ + δ will still go from c = .8
to c = .99 in this set of simulations
1. THE EFFECTS OF OUR ALGORITHM ON THE CONDITION NUMBERS OF MATRICES
19
While Figures 5 and 6 appear similar on inspection, a more informative graph might be constructed
by directly comparing the condition numbers of the matrices generated by randomly varying ρ and δ and
monotonically increasing δ for constant ρ. We did this in Figure 7. The results of this graph are interesting,
because it appears that those matrices with random ρ and δ have, on average, lower condition numbers than
matrices with fixed ρ and monotonically increasing δ (most red dots are below most blue dots). This may
seem odd given that our upper bound for the condition numbers of both matrices will be the same.
Figure 7. The average condition numbers found from matrices with randomly varied ρ + δ
subject to the constraint ρ + δ = c (red) and the average condition numbers of matrices
generated from ρ = .8 and δ increasing monotonically (blue) plotted against the values of c
used to generate each set of 100 matrices from c = [.8, .99]
However, the results of this simulation do not contradict our theory. In fact, a matrix with small δ and
large ρ will tend to have a higher condition number than a matrix with small ρ and large δ. To see why
this is so, consider that a matrix S with a large δ has more variable lowest and highest eigenvalues, while
a matrix with a large ρ will have less variable lowest and highest eigenvalues. If ρ is large then the matrix
with less variable lowest and highest eigenvalues will tend to have a condition number which is much closer
to κmax (S). Note this follows from the fact that if ρ is large, then δ is small, so E is small in some sense
and the spectrum of S will be approximately equal to the spectrum of Σ. If ρ is large and δ is small then
the lowest and highest eigenvalues of Σ will be close to those predicted by κmax (S) for all matrices S.
Postulate 1. Let ρ1 , δ1 be the parameters used to generate matrix S1 = Σ1 + E1 . In particular, let
ρ1 , δ1 be chosen so that δ1 , ρ1 ∼ U (0, 1) subject to the constraint that ρ1 + δ1 < 1. Further, let S2 = Σ2 + E2
with ρ2 large relative to δ2 so that ρ2 > E [ρ1 ] and δ2 ≤ E [δ1 ] on average, then E [κ(S1 )] < E [κ(S2 )] .
In light of Postulate 1 we re-examine the results we reported in Figure 7. Now, we clearly see that
the average κ(S1 ) realized in this data is indeed less than the average κ(S2 ), which is perfectly consistent
with our postulate and earlier theory.
20
3. SIMULATIONS CONDUCTED TO EVALUATE THE ALGORITHM
2. How different are S and Σ?
As we discussed in the previous section, our algorithm can produce matrices with widely varying condition
numbers, however we have not yet answered the question of whether or not our algorithm is useful. In order
to be useful, our algorithm would need to be able to generate a random matrix S which is discernibly different
the determined matrix Σ. We looked at a number of measures to evaluate the performance of our algorithm
in generating discernibly different matrices. In particular, we performed hypothesis tests on our simulated
correlation matrices S using Box’s M test of equality for covariance matrices [5]. Box’s M test is of the
hypotheses:
H0 : S = Σ0
H1 : S 6= Σ0
where Σ0 = Σ + δIp with Σ, δ as previously and Ip the p × p identity matrix. Σ0 is a transformation of Σ
into a correlation matrix because it now has a main diagonal of 1s.
1
ρ
Σ0 = .
..
ρ
ρ ... ρ
1 . . . ρ
.. . .
.
. ..
.
ρ ... 1
The test statistic for Box’s M is:
(2p2 + 3p − 1)
2
[(n − 1) log |Σ0 | − log |S| + tr(SΣ0−1 ) − p
X0 = (1 − C)W = 1 −
6(n − 1)(p + 1)
where
(2p2 + 3p − 1)
C=
6(n − 1)(p + 1)
W = (n − 1) log |Σ0 | − log |S| + tr(SΣ0−1 ) − p
and n is the number of observations which our estimated correlation matrix S is based on. This test statistic
does not follow any conventional distribution, however it can be modified so that the p-value of the test can
be estimated by:
αp
=
P (−2ρ log λ ≥ X02 )
=
P (Xf2 ≥ X02 ) + ω[P (Xf2+4 ≥ X02 ) − P (Xf2 ≥ X02 )]/(1 − C)2 + O((n − 1)−3 )
with
p(2p4 + 6p3 + p2 − 12p − 13)
p(p + 1)
and f =
2
288((n − 1) )(p + 1))
2
Box’s M test is a statistical test for correlation matrices. It is designed for testing parameter estimates
gathered from multivariate normal data. However, our correlation matrices are not estimates, they are
exactly equal to the idealized population parameters and the number of observations used in αp could be
said to infinity. Thus, it may seem slightly odd to utilize the test because it would be possible for us to
simply look at the two matrices, Σ0 and S and see if they are different. However, using Box’s M test allows
us to determine whether or not the simulated matrix S and defined Σ0 are different enough from one another
that it would be possible to tell them apart if S had been estimated from real data and Σ0 was the matrix
of true but unknown population correlations. The value for the number of observations n can be thought of
as indicative of the size of the data set from which we would need to estimate S in order to be sure it was
in fact different from Σ0 given the degree of difference between the entries of Σ0 and S.
ω=
2. HOW DIFFERENT ARE S AND Σ?
21
While Box’s M is a reasonable metric to use in evaluating whether or not our algorithm produces
meaningfully different matrices, there are a number of other measures we could use. In particular, given the
method we used to generate S a natural question might be how different S and Σ are under various different
matrix norms. The two norms which it is most natural to ask this question about are the Frobenius norm,
which is a generalization of Euclidean distance and is easily understood intuitively, and kSkop , which we
implicitly used in order to construct S.
Definition 7 (Frobenius Norm). For a matrix T , the Frobenius norm, denoted kT k2 is
v
uX
n
um X
kT k2 = t
|aij |2
i=1 j=1
Definition 8. Let A be a p × p positive matrix, then λ1 (A) is a matrix norm. In particular, it is the
operator norm for A. Denote it kSkop .
The value of kS − Σ0 k2 and kS − Σ0 kop was graphed versus δ from δ = 0 to δ = .19 for ρ = .8 with step
size .001 and n = 10. Based on these graphs it appears that the p-value of Box’s M is related, though not
linearly, to both the Frobenius and operator norms. The p-value of Box’s M seems to undergo a radical
jump for some critical value of the matrix norm for both the Frobenius and operator norms.
Further, it appears that varying δ linearly increases both the Frobenius and operator norm’s calculation
of the distance between S, Σ0 .
Figure 8. The Frobenius norm distance between S, Σ0 (Frobenius.Norm.Distance), the
values of δ used to generate S (Delta.S) and the P-value of Box’s M test for the hypotheses
that S and Σ0 are different (Box.M.Test.pvalue)
22
3. SIMULATIONS CONDUCTED TO EVALUATE THE ALGORITHM
Figure 9. The Modulus norm distance between S, Σ0 (Frobenius.Norm.Distance), the values of δ used to generate S (Delta.S) and the P-value of Box’s M test for the hypotheses
that S and Σ0 are different (Box.M.Test.pvalue)
CHAPTER 4
Extensions of our algorithm
We explored a number of natural modifications and extensions of the algorithm explored in depth in the
previous 3 chapters which allow us to (1) add gram matrices constructed with different δ for each row of E
to Σ, (2) construct block diagonal correlation matrices and (3) construct matrices with positive and negative
starting values of ρij .
1. Multiple δi
The simplest modification to the algorithm we have already explored is the method we used to generate
a different δi for each of p rows of E. Choose some max(δ), denoted δmax , subject to the constraint that
ρ + δmax < 1. Now choose, or randomly generate, up to p different δi subject
√ to the additional constraint
that δi ≤ δmax . Now create a Gram matrix composed of ei , where kei k ≤ δi . Denote the Gram matrix
which results from this method of choosing δ Ed .
δ1
he1 , e2 i . . . he1 , ep i
he2 , e1 i
δ2
. . . he2 , ep i
Ed =
..
..
..
..
.
.
.
.
hep , e1 i hep , e2 i . . .
We now argue that Ed will have bounded off diagonal entries.
δp
Remark 6. The off diagonal entries of Ed are bounded. In particular, each off diagonal entry has
absolute value less than or equal to δmax .
Proof. Consider an arbitrary entry of Ed . This entry will be hei , ej i. Applying Theorem 2 we find
that
p p
|hei , ej i| ≤ δi δj ≤ δmax .
It is also necessary to slightly modify the matrix Σ for use with multiple δi , label the new matrix Σd .
Σd =
1 − δ1
ρ
..
.
ρ
1 − δ2
..
.
...
...
..
.
ρ
ρ
..
.
ρ
ρ
. . . 1 − δp
By an identical argument to that we used in Chapter 1, it is apparent that Sd = Σd + Ed is a correlation
matrix because it satisfies the criteria of Remark 2. Further, the upper bound for the condition number
κmax (S) we described and derived earlier in Remark 3 still holds, so
κ(Sd ) ≤
pρ + pδmax + 1
1 − ρ − δmax
23
24
4. EXTENSIONS OF OUR ALGORITHM
except now the inequality will be sharp if and only if
δi = δmax
∀ i.
In other words, the inequality will be sharp if the different δi are all equal to one another, so we return
to the case which we have discussed at length in Chapter 1. The proof is trivial, so we do not present a
formal argument, however consider that if δi < δmax , for at least 1 δi , then λp (Σd ) = 1 − ρ − δi > 1 − ρ − δ
and the lowest possible eigenvalue of Ed remains zero. Thus, κ(Sd ) < κmax (Sd ). We now move onto the
block diagonal case.
2. Block Diagonal Correlation Matrices
The theory which motivates the construction of block diagonal matrices is extremely similar to that
which drives the construction of matrices with different δi for each row. Suppose we want a correlation
matrix T with dimension a × a. We would like this matrix to have larger entries in diagonal blocks than the
off diagonal blocks. In order to do this, we will first create a block diagonal matrix A and perturb it with a
Gram matrix G. First, consider the construction of A.
Let A be a block diagonal a × a matrix with N total blocks, where each block is correlation matrix.
Each of N diagonal blocks of A will be a Σ matrix identical to those we have constructed in earlier chapters.
We introduce the following notation.
Definition 9. Let A be a block diagonal matrix with dimension a × a. Denote each diagonal block as
Σt for 1 ≤ t ≤ N . Further, let each Σt ∈ Mbt ×bt . We define Σt to have off diagonal entries ρt and main
diagonal entries with value 1 − δt . Also, define δmaxN = max (δt ) and ρmaxN = max (ρt ). We further
1≤t≤N
1≤t≤N
require that
δmaxN + ρmaxN < 1.
Thus, each Σt is a matrix with the following structure
Σt =
1 − δt
ρt
..
.
ρt
1 − δt
..
.
...
...
..
.
ρt
ρt
..
.
ρt
ρt
...
1 − δt
and A has the structure
A=
Σ1
0
..
.
0
Σ2
..
.
...
...
..
.
0
0
..
.
0
0 . . . ΣN
Now, we create an a × a Gram matrix G which mirrors the block structure of M . In order to construct
N
X
G we will consider choosing the requisite a vectors in t sets with cardinality bt , where
bt = a. In order to
t=1
emphasize the similarity of the process which produces G to the process which produces the E in the single
block case, denote each of these sets as Et . Thus, we have
Et = {et,1 , et,2 , . . . , et,b }.
2. BLOCK DIAGONAL CORRELATION MATRICES
We require that for each et,i ∈ Et that ket,i k =
25
√
δt . Note that et,i is a vector in an a dimensional vector
N
[
space. After choosing t of these sets of vectors, we form a Gram matrix from
Et . Denote this matrix G.
t=1
G=
he1,1 , e1,2 i
δ1
..
.
δ1
he1,2 , e1,1 i
..
.
...
...
..
.
he1,1 eN,b i
he1,2 , eN,b i
..
.
he1,1 eN,b i he1,2 , eN,b i . . .
δN
Now define T = A + G. T is a correlation matrix because it satisfies the criteria of Remark 2 and it will
be computationally invertible because it will still be subject to the argument in Remark 3.
1
ρ1 + he1,1 , e1,2 i . . . he1,1 eN,b i
ρ1 + he1,2 , e1,1 i
1
. . . he1,2 , eN,b i
T =
..
..
..
..
.
.
.
.
he1,1 eN,b i
he1,2 , eN,b i
...
1
To illustrate using our algorithm to generate a block diagonal matrix, we provide an example.
Example 3. We will generate a correlation matrix T with dimension a × a = 4 × 4. Further, we want
to have two main diagonal blocks the first of which will have dimension b1 × b1 = 2 × 2 and the second of
which will have b2 × b2 = 2 × 2. Thus, we choose ρ1 and ρ2 with δ1 and δ2 subject to the constraints that:
(1)
δ 1 + ρ1 < 1
(2)
δ 1 + ρ2 < 1
(3)
δ 2 + ρ1 < 1
(4)
δ 2 + ρ2 < 1
Or equivalently,
max δt + max ρt = δmaxN + ρmaxN < 1.
t=1,2
t=1,2
Thus we have
A=
Σ1
02×2
02×2
Σ2
δ1
ρ1
=
0
0
ρ1
δ1
0
0
0
0
δ2
ρ2
0
0
ρ2
δ2
Now choose 4 vectors
, e1,2 } and E2 = {e2,1 , e2,2 } subject
to the the constraint that
√ in two sets, E1 = {e1,1√
S
ke1,1 k = ke1,2 k = δ1 and ke2,1 k = ke2,2 k = δ2 . The Gram Matrix of E1 E2 . is:
δ1
he1,1 , e1,2 i he1,1 , e2,1 i he1,1 , e2,2 i
he1,2 , e1,1 i
δ1
he1,2 , e1,2 i he1,2 , e2,2 i
G=
he2,1 , e1,1 i he2,1 , e1,2 i
δ2
he2,1 , e2,2 i
he2,2 , e1,1 i he2,2 , e1,2 i he2,2 , e1,2 i
δ2
Thus, we have T = A + G where T is:
1
ρ1 + he1,1 , e1,2 i
he1,1 , e2,1 i
he1,1 , e2,2 i
ρ1 + he1,2 , e1,1 i
1
he1,2 , e1,2 i
he1,2 , e2,2 i
T =
he2,1 , e1,1 i
he2,1 , e1,2 i
1
ρ2 + he2,1 , e2,2 i
he2,2 , e1,1 i
he2,2 , e1,2 i
ρ2 + he2,2 , e1,2 i
1
26
4. EXTENSIONS OF OUR ALGORITHM
3. Make some ρij for Σ negative
A final extension of our algorithm allows us to incorporate positive and negative initial ρ. Let U be a
p × p diagonal matrix with +/ − 1 on the main diagonal. Note that U ∗ = U −1 so
U ΣU
has the same block diagonal structure as Σ, but now Σ has +/− signs intermixed with the off diagonal
entries. Further, U ΣU is unitarily equivalent to Σ so the eigenvalues of U ΣU are the same as those of Σ.
Now let S = U ΣU + G and observe that S will be a correlation matrix with some entries which are positive
and some that are negative.
4. Some concluding remarks
We have described an algorithm to generate random correlation matrices S which have bounded condition numbers. This allows us to determine how computationally stable the matrix S will be. The algorithm
we have presented here has a number of natural applications. One such application is to sensitivity test calculations which rely on correlation structure. In particular, our algorithm adds small random perturbations
to the hypothesized correlation matrix and recalculate any correlation related quantity.
Further, the algorithm has potential applications in fields where it is desirable to generate data with a
variety of correlation structures. If one is interested in finding a way to randomly create multivariate normal
data with a random collection of correlation matrices, our algorithm could easily allow one to generate any
number of different correlation structures. Further refinements of the methods we have presented here could
randomly perturb any starting positive definite matrix with known eigenvalues while bounding the condition
number of the perturbed matrix.
Bibliography
[1] Rajendra Bhatia. Matrix Analysis. Springer, 1997.
[2] Nicholas J. Higham. Computing the nearest correlation matrix-a problem from finance. IMA Journal of Numerical Analysis,
22(3), 2002.
[3] Roger A. Horn and Charles R. Johnson. Matrix Analysis. Cambridge University Press, 1985.
[4] Garry J. Tee. A simple example of an ill-conditioned matrix. ACM SIGNUM Newsletter, 7(3), 1972.
[5] Neil H. Timm. Applied Multivariate Analysis. Springer, 2002.
[6] Wikipedia. Covariance matrix, 2010.
27