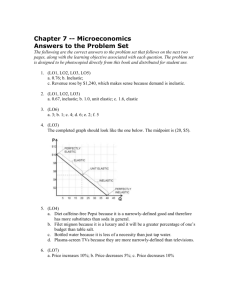
Chapter 17:
Nonparametric
Statistics
Learning Objectives
LO1
Use both the small-sample and large-sample runs tests to
determine whether the order of observations in a sample
is random.
LO2
Use both the small-sample and large-sample cases of the
Mann-Whitney U test to determine if there is a difference
in two independent populations.
LO3
Use both the small-sample and large-sample cases of the
Wilcoxon matched-pairs signed rank test to compare the
difference in two related samples.
continued...
Learning Objectives
LO4
Use the Kruskal-Wallis test to determine whether samples
come from the same or different populations.
LO5
Use the Friedman test to determine whether different
treatment levels come from the same population when a
blocking variable is available.
LO6
Use Spearman’s rank correlation to analyze the degree of
association of two variables.
LO1
Parametric vs. Nonparametric Statistics
• The appropriateness of the data analysis depends on the
level of measurement of the data gathered: nominal, ordinal,
interval, or ratio
• Parametric Statistics are statistical techniques based on
assumptions about the population from which the sample
data are collected.
– A fundamental assumption is that data being analyzed are randomly
selected from a normally distributed population.
– It requires quantitative measurement that yield interval or ratio level
data.
LO1
Parametric vs. Nonparametric Statistics
• Nonparametric Statistics are based on fewer assumptions
about the population and the parameters than are
parameter statistics.
– Because of this property nonparametric statistics are sometimes
called “distribution-free” statistics.
– A variety of nonparametric statistics are available for use with
nominal or ordinal data.
LO1
Advantages
of Nonparametric Techniques
• Sometimes there is no parametric alternative to the use of
nonparametric statistics.
• Certain nonparametric test can be used to analyze nominal
data.
• Certain nonparametric test can be used to analyze ordinal
data.
• The computations on nonparametric statistics are usually less
complicated than those for parametric statistics, particularly
for small samples.
• Probability statements obtained from most nonparametric
tests are exact probabilities.
LO1
Disadvantages
of Nonparametric Statistics
• Nonparametric tests can be wasteful of data if parametric
tests are available for use with the data.
• Nonparametric tests are usually not as widely available
and well know as parametric tests.
• For large samples, the calculations for many
nonparametric statistics can be tedious.
LO1
Branch of the Tree Diagram Taxonomy
Inferential Techniques
LO1
Runs Test
• The one-sample runs test is a nonparametric test of
randomness
• The runs test examines the number of runs of each of
two possible characteristics that sample items may have
• A run is the order or sequence of observations that have
a particular (the same) one of the characteristics. For
example, the continuous succession of heads in 15
tosses of a coin.
– Example with two runs:
H, H, H, H, H, H, H, H, T, T, T, T, T, T, T
– Example with fifteen runs:
H, T, H, T, H, T, H, T, H, T, H, T, H, T, H
LO1
Runs Test: Sample Size Consideration
• Sample size: n
• Number of sample members possessing the first
characteristic: n1
• Number of sample members possessing the second
characteristic: n2
• n = n1 + n2
• If both n1 and n2 are ≤ 20, the small sample runs test is
appropriate.
LO1
Setting up the Problem
• Hypothesize
– Step 1: The hypotheses
– Ho: The observations in the sample generated randomly
– Ha: The observations in the sample not generated randomly
• TEST
– Step 2: let n1 be the number of items with one characteristic and n2
be the number of items in the other.
– If the total number of items is less than or equal to 20, small sample
runs test appropriate
• Steps 3 and 4:
– Set α and critical regions of test
LO1
Setting Out the Problem Continued
– Step 5: Set out the sample data in actual format
– Step 6: Tally the number of runs in the sample
• Action
– Step 7: Decide whether there is sufficient evidence to accept or reject
the null hypothesis
– Step 8: Set out business implications
LO1
Canadian Tire Store Problem
small runs test
Step 1: The hypotheses
– Ho: The observations in the sample generated randomly
– Ha: The observations in the sample not generated randomly
Step 2: n1= 7, n2 = 8
Step 3: let α=0.05
Step 4: With n1 = 7 and n2 = 8, Table A.11 yields a critical value
of 4 and Table A.12 yields a critical value of 13.
* If there are 4 or fewer runs, or 13 or more runs, the decision
rule is, reject the null hypothesis.
* If the observed runs are between 4 and 13, then the decision
rule is, do not reject the null hypothesis.
LO1
Runs Test: Cola Example
LO1
Runs Test: Small Sample Example
Excel cannot analyze data by using the runs test; however, Minitab can. Figure 17.2 is the
Minitab output for the cola example runs test. Notice that the output includes the number
of runs, 12, and the significance level of the test. For this analysis, diet cola was coded as a
1 and regular cola as a 2. The Minitab runs test is a two-tailed test and the reported
significance of the test is equivalent to a p value. Because the significance is 0.9710, the
decision is to not reject the null hypothesis.
LO1
Large Sample Machine Problem
• A machine occasionally produces parts that are flawed.
• When the machine is working in adjustment, flaws still occur
but seem to happen randomly. A quality control person
selects 50 of the parts produced by the machine today and
examines them one at a time in the order that they were
made. The result is 40 parts with no flaws; and 10 parts with
flaws. The following sequence is observed, N= no flaws; F=
Flaws:
NNNFNNNNNNNFNNFFNNNNNNFNNN
NFNNNNNNFFFFNNNNNNNNNNNN
• The quality controller wishes to determine if the flaws are
LO1 occurring randomly
Points of Interest
• When samples are large, they start looking like samples that
come from normal distributions
• Sampling distribution of R for large samples is approximately
normally distributed with a mean and standard deviation of:
• The test statistic is a z statistic computed as:
LO1
Runs Test: Large Sample Example
LO1
Runs Test: Large Sample Example
LO1
Runs Test: Large Sample Example Minitab
Output
LO1
Runs Test: Large Sample Example Minitab
Output
LO1
Mann-Whitney U Test
• Mann-Whitney U tests is a nonparametric
counterpart of the t test used to compare the
means of two independent populations.
• It does not require normally distributed
populations
• The assumptions of the model:
– The samples are independent.
– The level of data is at least ordinal.
LO2
Mann-Whitney U Test:
Sample Size Consideration
•
Let size of sample one be n1
•
Let size of sample two be n2
•
Small sample case:
•
•
Large sample case:
•
LO2
If both n1 ≤ 10 and n2 ≤ 10, the small sample procedure is
appropriate.
If either n1 or n2 is greater than 10, the large sample procedure is
appropriate.
Calculations of the U-Test
• Arbitrarily designate the two samples as group 1 and group 2.
• The data from the two groups are combined into one group,
with each data value retaining a group identifier of its original
group.
• The pooled values are then ranked from 1 to n with the
smallest number being assigned a rank 1
• Calculate W1 = the sum of the ranks of values from group 1;
and W2 = the sum of the ranks of values from group 2.
LO2
Mann-Whitney U-Formulas:
Small Sample Case
• Calculating the U statistic for W1 and W2
U1 n1 n2
U 2 n1 n2
n1 (n1 1)
W1
2
n2 (n2 1)
W2
2
The test statistic is the smallest of these two U values
Bothe u values do not have to be calculated. One can be derived from
the other by the transformation:
U ' n1 n2 U
LO2
Mann-Whitney U Test: Difference between Health Service Workers and
Educational Service Workers
Small Sample Example - Problem 17.1
Step 1:
H0: The health service population is
identical to the educational service
population with respect to employee
compensation
Ha: The health service population is not
identical to the educational service
population with respect to employee
compensation
LO2
Mann-Whitney U Test: Small Sample Example
- Demonstration Problem 17.1
Step 2: Because we cannot be certain the populations are
normally distributed, we choose a nonparametric
alternative to the t test for independent populations:
the small-sample Mann-Whitney U test.
Step 3: = .05
Step 4: If the final p-value < .05, reject H0.
Step 5. The sample data are provided.
LO2
Mann-Whitney U Test: Small Sample Example
- Demonstration Problem 17.1
Step 6:
• W1 = 1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 =
31
• W2 = 5 + 9 + 10 + 11 + 12 + 13 + 14
+ 15 = 89
Because U2 is the smaller value of U,
we use Uo = 3 as the test statistic for
Table A.13. Because it is the smallest
size, let n1 = 7 and n2 = 8.
LO2
Mann-Whitney U Test: Small Sample Example
- Demonstration Problem 17.1
Step 7: Table A.13 yields a p value of 0.0011. Because
this test is two-tailed, we double the p value,
producing a final p value of 0.0022. Because the
p value is less than α = 0.05, the null hypothesis
is rejected. The statistical conclusion is that the
populations are not identical.
LO2
Mann-Whitney U Test: Small Sample Example Demonstration Problem 17.1 – Minitab Output
p value = .0011 from table A.13 and p value = .0046 from minitab.
The difference in p values is due to rounding error in the table.
LO2
Mann-Whitney U Test:
Formulas for Large Sample Case
For large sample sizes, the value of U is approximately normally
distributed. Using an average expected U value for groups of this
size and a standard deviation of U’s allows computation of a z
score for the U value.
LO2
Incomes of CBC
and Non-CBC Viewers
Step 1:
Ho: The incomes for CBC viewers and non-CBC
viewers are identical
Ha: The incomes for CBC viewers and non-CBC
viewers are not identical
Step 2: Use the Mann-Whitney U test for
large samples
Steps 3, 4, and 5:
LO2
CBC and Non-CBC Viewers: Calculation of U
Step 6:
LO2
Ranks of Income from Combined Groups of
CBC and Non-CBC Viewers
Step 6:
LO2
CBC and Non-CBC Viewers: Conclusion
Step 6:
Step 7:
Step 8:
LO2
The fact that CBC viewers have higher average income can affect the
type of programming on CBC in terms of both trying to please present
viewers and offering programs that might attract viewers of other
income levels. In addition, advertising can be sold to appeal to viewers
with higher incomes.
Wilcoxon Matched-Pairs Signed Rank Test
• Note that the Mann-Whitney U test cannot be applied to two
samples that are related
• Instead, the Wilcoxon Matched-Pairs is applicable to related
samples: it is a nonparametric alternative to the t test for
related samples
• Applicable to studies in which the data in one group is related
to the data in the other group, including before and after
studies
• Studies in which measures are taken on the same person or
object under different conditions
• Studies of twins or other relatives
LO3
Wilcoxon Matched-Pairs Signed Rank Test
•
•
•
•
•
•
LO3
Differences of the scores of the two matched samples
Differences are ranked, ignoring the sign
Ranks are given the sign of the difference
Positive ranks are summed
Negative ranks are summed
T is the smaller sum of ranks
Wilcoxon Matched-Pairs Signed Rank Test:
Sample Size Consideration
• n is the number of matched pairs
• If n > 15, T is approximately normally distributed, and a Z test
is used.
• If n is small, a special “small sample” procedure is followed:
– The paired data are randomly selected.
– The underlying distributions are symmetrical.
• In such a case a critical value against which to compare T is
found in Table A.14 of this text.
LO3
Wilcoxon Matched-Pairs Signed Rank Test:
Small Sample Example
Step 1:
H0: Md = 0
Ha: Md 0
Step 2: n = 6
Step 3: =0.05
Step 4:
If Tobserved 1, reject H0.
LO3
Step 5:
Wilcoxon Matched-Pairs Signed Rank Test:
Small Sample Example
Step 6:
Family
Pair
1
2
T
3
4
5
6
Toronto Montreal
1,950
1,760
1,840
1,870
2,015
1,810
1,580
1,660
1,790
1,340
1,925
1,765
d
190
-30
205
-80
450
160
Rank
+4
-1
+5
-2
+6
+3
T = minimum(T+, T-)
T+ = 4 + 5 + 6 + 3= 18
T- = 1 + 2 = 3
Step 7:
T=3
T = 3 > Tcrit = 1, do not reject H0.
LO3
Wilcoxon Matched-Pairs Signed Rank Test:
Small Sample Example
Step 6:
Family
Pair
1
2
T
3
4
5
6
Toronto Montreal
1,950
1,760
1,840
1,870
2,015
1,810
1,580
1,660
1,790
1,340
1,925
1,765
d
190
-30
205
-80
450
160
Rank
+4
-1
+5
-2
+6
+3
T = minimum(T+, T-)
T+ = 4 + 5 + 6 + 3= 18
T- = 1 + 2 = 3
Step 7:
T=3
T = 3 > Tcrit = 1, do not reject H0.
LO3
Wilcoxon Matched-Pairs Signed Rank Test:
Minitab Output
p value = 0.142 > α = 0.05, do not reject Ho
STEP 8. Not enough evidence is provided to declare that Toronto and Montreal
differ in annual household spending on movie rentals. This information may be
useful to movie rental services and stores in the two cities.
LO3
Wilcoxon Matched-Pairs Signed Rank Test:
The Large Sample Formulas
LO3
Comparing Airline Cost per Mile of Airfares for 17 Cities in
Canada for Both 1979 and 2009
LO3
Airline Cost Comparison: T Calculation
LO3
Airline Cost Comparison: Action
There is no significant difference in the cost of airline
tickets between 1979 and 2009.
LO3
Kruskal-Wallis Test
• A nonparametric alternative to one-way analysis of
variance (ANOVA)
• Like the one-way ANOVA it is used to determine whether
c ≥ 3 samples come from the same or different
populations
• May be used to analyze ordinal data
• It requires and makes no assumption about the
distribution or shape of the population
• It assumes that the c groups are independent
• It assumes random selection of individual items
LO4
The Formulation of the Hypotheses
• The hypotheses tested by the Kruskal-Wallis test follows
– Ho: The c populations are identical
– Ha: At least one of the c populations is different
• The process of computing a Kruskal-Wallis K statistic begins
with ranking the data in all groups together, as though they
were from one group. Beginning with 1 assigned to the
smallest value, and so on. Ties are each given the average of
the rank of the two values.
• Unlike one-way ANOVA, in which the raw data is analyzed, the
Kruskal-Wallis test analyzes the ranks of the data.
LO4
Kruskal-Wallis K Statistic
é c 2ù
12 ê T j ú
K=
- 3 n +1
S
ê
ú
n n +1 ê j=1 n j ú
ë
û
(
)
(
where
c = number of groups
n = total number of items
Tj = total of ranks in a group
nj = number of items in a group
K ≈ χ2, with df = c − 1
LO4
)
Number of Office Patients per Physician
in Three Organizational Categories
Ho: The c populations are identical.
Ha: At least one of the c populations is different.
LO4
Patients per Physician Data:
Kruskal-Wallis Preliminary Calculations
LO4
Patients per Day Data: Kruskal-Wallis Calculations
and Conclusion
LO4
Friedman Test
• A nonparametric alternative to the randomized block design
• Assumptions
– The blocks are independent.
– There is no interaction between blocks and treatments.
– Observations within each block can be ranked.
• Hypotheses
– Ho: The treatment populations are equal
– Ha: At least one treatment population yields larger values
than at least one other treatment population
LO5
Friedman Test
LO5
Step 1 of Friedman Test: Tensile Strength
of Plastic Housings
Ho: The supplier populations are equal
Ha: At least one supplier population yields larger values than at
least one other supplier population
LO5
Steps 2.3.and 4 of Friedman Test:
Tensile Strength of Plastic Housings
LO5
Step 5 of Friedman Test:
Tensile Strength of Plastic Housings
LO5
Steps 6 and 7 of Friedman Test:
Tensile Strength of Plastic Housings
LO5
Steps 7 and 8:
Action and Business Implications
• Step 7: Because the observed value of χr2 = 10.68 is greater
than the critical value (7.8147) of chi-square at α = 0.05 , df = 3,
the decision is to reject the null hypothesis
• Step 8: The business implication is that statistically, there is a
significant difference in the tensile strength of housings made
by different suppliers.
– Moreover the sample reveals that supplier 3 is producing housings with
a lower tensile strength than those made by other suppliers and that
supplier 4 is producing housings with higher tensile strength
– Further study by managers and a quality team may result in attempts
to bring supplier 3 up to standard on tensile strength or perhaps
cancellation of the contract.
LO5
Distribution for Tensile Strength
Example Figure 17.8
LO5
Friedman Test: Tensile Strength
of Plastic Housings – Minitab Output
LO5
Spearman’s Rank Correlation
• To measure the degree of association of two variables.
• When only ordinal-level data or ranked data are available,
Spearman’s rank correlation, rs, can be used to analyze the
degree of association of two variables. Charles E. Spearman
(1863-1945) developed this correlation coefficient.
LO6
Spearman’s Rank Correlation for
Heifer and Lamb Prices
LO6
Spearman’s Rank Correlation for Heifer and Lamb
Prices
From the previous slide, the lamb prices are ranked and the
heifer prices are ranked. The difference in ranks is computed for
each year. The differences are squared and summed, producing
Σd2 = 108. The number of pairs, n, is 10. The value of rs = 0.345
indicates that there is a very modest positive correlation
between lamb and heifer prices.
LO6
COPYRIGHT
Copyright © 2014 John Wiley & Sons Canada, Ltd. All
rights reserved. Reproduction or translation of this work
beyond that permitted by Access Copyright (The Canadian
Copyright Licensing Agency) is unlawful. Requests for
further information should be addressed to the
Permissions Department, John Wiley & Sons Canada, Ltd.
The purchaser may make back-up copies for his or her
own use only and not for distribution or resale. The
author and the publisher assume no responsibility for
errors, omissions, or damages caused by the use of these
programs or from the use of the information contained
herein.