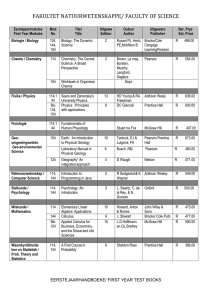
Chapter 13 - Inference About Comparing Two Populations
advertisement

Chapter 13 Inference About Comparing Two Populations Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.1 Comparing Two Populations… Previously we looked at techniques to estimate and test parameters for one population: Population Mean , Population Variance , and Population Proportion p We will still consider these parameters when we are looking at two populations, however our interest will now be: The difference between two means. The ratio of two variances. The difference between two proportions. Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.2 Difference of Two Means… In order to test and estimate the difference between two population means, we draw random samples from each of two populations. Initially, we will consider independent samples, that is, samples that are completely unrelated to one another. Population 1 Sample, size: n1 Parameters: (Likewise, we consider Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. Statistics: for Population 2) 13.3 Difference of Two Means… In order to test and estimate the difference between two population means, we draw random samples from each of two populations. Initially, we will consider independent samples, that is, samples that are completely unrelated to one another. Because we are compare two population means, we use the statistic: Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.4 Sampling Distribution of 1. is normally distributed if the original populations are normal –or– approximately normal if the populations are nonnormal and the sample sizes are large (n1, n2 > 30) 2. The expected value of 3. The variance of is is and the standard error is: Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.5 Making Inferences About Since is normally distributed if the original populations are normal –or– approximately normal if the populations are nonnormal and the sample sizes are large (n1, n2 > 30), then: is a standard normal (or approximately normal) random variable. We could use this to build test statistics or confidence interval estimators for … Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.6 Making Inferences About …except that, in practice, the z statistic is rarely used since the population variances are unknown. ?? Instead we use a t-statistic. We consider two cases for the unknown population variances: when we believe they are equal and conversely when they are not equal. Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.7 When are variances equal? How do we know when the population variances are equal? Since the population variances are unknown, we can’t know for certain whether they’re equal, but we can examine the sample variances and informally judge their relative values to determine whether we can assume that the population variances are equal or not. Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.8 Test Statistic for 1) Calculate (equal variances) – the pooled variance estimator as… 2) …and use it here: degrees of freedom Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.9 CI Estimator for (equal variances) The confidence interval estimator for when the population variances are equal is given by: pooled variance estimator Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. degrees of freedom 13.10 Test Statistic for (unequal variances) The test statistic for when the population variances are unequal is given by: degrees of freedom Likewise, the confidence interval estimator is: Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.11 Which case to use? Which case to use? Equal variance or unequal variance? Whenever there is insufficient evidence that the variances are unequal, it is preferable to perform the equal variances t-test. This is so, because for any two given samples: The number of degrees of freedom for the equal variances case ≥ Larger numbers of degrees of freedom have the same effect as having larger sample sizes Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. The number of degrees of freedom for the unequal variances case ≥ 13.12 Example 13.1… Do people who eat high-fiber cereal for breakfast consume, on average, fewer calories for lunch than people who do not eat high-fiber cereal for breakfast? What are we trying to show? What is our research hypothesis? The mean caloric intake of high fiber cereal eaters ( is less than that of non-consumers ( ), i.e. is Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. ) ? 13.13 Example 13.1… IDENTIFY The mean caloric intake of high fiber cereal eaters ( ) is less than that of non-consumers ( ), translates to: (i.e. ) Thus, H1: Phrase H0 & H1 as a “difference of means” Hence our null hypothesis becomes: H0: Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.14 Example 13.1… A sample of 150 people was randomly drawn. Each person was identified as a consumer or a non-consumer of highfiber cereal. For each person the number of calories consumed at lunch was recorded. The data: Independent Pop’ns; Either you eat high fiber cereal or you don’t n1+n2=150 Recall H1: There is reason to believe the population variances are unequal… Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.15 Example 13.1… COMPUTE Thus, our test statistic is: The number of degrees of freedom is: Hence the rejection region is… Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.16 Example 13.1… COMPUTE Our rejection region: Our test statistic: Compare Since our test statistic (-2.09) is less than our critical value of t (-1.658), we reject H0 in favor of H1 — that is, there is sufficient evidence to support the claim that high fiber cereal eaters consume less calories at lunch. Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.17 Example 13.1… COMPUTE Likewise, we can use Excel to do the calculations… Recall H0: Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.18 Example 13.1… INTERPRET …however, we still need to be able to interpret the Excel output: Compare… …or look at p-value Beware! Excel gives a right tail critical value! i.e. 1.6573 vs. –1.6573 !! Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.19 Confidence Interval… Suppose we wanted to compute a 95% confidence interval estimate of the difference between mean caloric intake for consumers and non-consumers of high-fiber cereals… That is, we estimate that non-consumers of high fiber cereal eat between 1.56 and 56.86 more calories than consumers. Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.20 Confidence Interval… Alternatively, you can use the Estimators workbook… values in bold face are calculated for you… Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.21 Example 13.2… IDENTIFY Two methods are being tested for assembling office chairs. Assembly times are recorded (25 times for each method). At a 5% significance level, do the assembly times for the two methods differ? That is, H1: Hence, our null hypothesis becomes: H0: Reminder: since our null hypothesis is a “not equals” type, it is a two-tailed test. Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.22 Example 13.2… COMPUTE The assembly times for each of the two methods are recorded and preliminary data is prepared… The sample variances are similar, hence we will assume that the population variances are equal… Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.23 Example 13.2… COMPUTE Recall, we are doing a two-tailed test, hence the rejection region will be: The number of degrees of freedom is: Hence our critical values of t (and our rejection region) becomes: Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.24 Example 13.2… COMPUTE In order to calculate our t-statistic, we need to first calculate the pooled variance estimator, followed by the t-statistic… Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.25 Example 13.2… INTERPRET Since our calculated t-statistic does not fall into the rejection region, we cannot reject H0 in favor of H1, that is, there is not sufficient evidence to infer that the mean assembly times differ. Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.26 Example 13.2… INTERPRET Excel, of course, also provides us with the information… Compare… …or look at p-value Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.27 Confidence Interval… We can compute a 95% confidence interval estimate for the difference in mean assembly times as: That is, we estimate the mean difference between the two assembly methods between –.36 and .96 minutes. Note: zero is included in this confidence interval… Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.28 Terminology… If all the observations in one sample appear in one column and all the observations of the second sample appear in another column, the data is unstacked. If all the data from both samples is in the same column, the data is said to be stacked. Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.29 Identifying Factors I… Factors that identify the equal-variances t-test and estimator of : Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.30 Identifying Factors II… Factors that identify the unequal-variances t-test and estimator of : Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.31 Matched Pairs Experiment… Previously when comparing two populations, we examined independent samples. If, however, an observation in one sample is matched with an observation in a second sample, this is called a matched pairs experiment. To help understand this concept, let’s consider example 13.4 Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.32 Example 13.4… Is there a difference between starting salaries offered to MBA grads going into Finance vs. Marketing careers? More precisely, are Finance majors offered higher salaries than Marketing majors? In this experiment, MBAs are grouped by their GPA into 25 groups. Students from the same group (but with different majors) were selected and their highest salary offer recorded. Here’s how the data looks… Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.33 Example 13.4… The numbers in black are the original starting salary data; the number in blue were calculated. although a student is either in Finance OR in Marketing (i.e. independent), that the data is grouped in this fashion makes it a matched pairs experiment (i.e. the two students in group #1 are ‘matched’ by their GPA range the difference of the means is equal to the mean of the differences, hence we will consider the “mean of the paired differences” as our parameter of interest: Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.34 Example 13.4… IDENTIFY Do Finance majors have higher salary offers than Marketing majors? Since: We want to research this hypothesis: H1: (and our null hypothesis becomes H0: Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. ) 13.35 Test Statistic for The test statistic for the mean of the population of differences ( ) is: which is Student t distributed with nD–1 degrees of freedom, provided that the differences are normally distributed. Thus our rejection region becomes: Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.36 Example 13.4… COMPUTE From the data, we calculate… …which in turn we use for our t-statistic… …which we compare to our critical value of t: Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.37 Example 13.4… INTERPRET Since our calculated value of t (3.81) is greater than our critical value of t (1.711), it falls in the rejection region, hence we reject H0 in favor of H1; that is, there is overwhelming evidence (since the p-value = .0004) that Finance majors do obtain higher starting salary offers than their peers in Marketing. Compare… Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.38 Confidence Interval Estimator for We can derive the confidence interval estimator for algebraically as: In the previous example, what is the 95% confidence interval estimate of the mean difference in salary offers between the two business majors? That is, the mean of the population differences is between LCL=2,321 and UCL=7,809 dollars. Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.39 Identifying Factors… Factors that identify the t-test and estimator of Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. : 13.40 Inference about the ratio of two variances So far we’ve looked at comparing measures of central location, namely the mean of two populations. When looking at two population variances, we consider the ratio of the variances, i.e. the parameter of interest to us is: The sampling statistic: is F distributed with degrees of freedom. Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.41 Inference about the ratio of two variances Our null hypothesis is always: H0: (i.e. the variances of the two populations will be equal, hence their ratio will be one) Therefore, our statistic simplifies to: Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.42 Example 13.6… IDENTIFY In example 13.1, we looked at the variances of the samples of people who consumed high fiber cereal and those who did not and assumed they were not equal. We can use the ideas just developed to test if this is in fact the case. We want to show: H1: (the variances are not equal to each other) Hence we have our null hypothesis: H0: Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.43 Example 13.6… CALCULATE Since our research hypothesis is: H1: We are doing a two-tailed test, and our rejection region is: F Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.44 Example 13.6… CALCULATE Our test statistic is: .58 1.61 F Hence there is sufficient evidence to reject the null hypothesis in favor of the alternative; that is, there is a difference in the variance between the two populations. Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.45 Example 13.6… INTERPRET We may need to work with the Excel output before drawing conclusions… Our research hypothesis H1: requires two-tail testing, but Excel only gives us values for one-tail testing… If we double the one-tail p-value Excel gives us, we have the p-value of the test we’re conducting (i.e. 2 x 0.0004 = 0.0008). Refer to the text and CD Appendices for more detail. Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.46 Example 13.6… CALCULATE If we wanted to determine the 95% confidence interval estimate of the ratio of the two population variances in Example 13.1, we would proceed as follows… The confidence interval estimator for Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. , is: 13.47 Example 13.6… CALCULATE The 95% confidence interval estimate of the ratio of the two population variances in Example 13.1 is: That is, we estimate that lies between .2388 and .6614 Note that one (1.00) is not within this interval… Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.48 Identifying Factors Factors that identify the F-test and estimator of Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. : 13.49 Difference Between Two Population Proportions We will now look at procedures for drawing inferences about the difference between populations whose data are nominal (i.e. categorical). As mentioned previously, with nominal data, calculate proportions of occurrences of each type of outcome. Thus, the parameter to be tested and estimated in this section is the difference between two population proportions: p1–p2. Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.50 Statistic and Sampling Distribution… To draw inferences about the the parameter p1–p2, we take samples of population, calculate the sample proportions and look at their difference. is an unbiased estimator for p1–p2. x1 successes in a sample of size n1 from population 1 Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.51 Sampling Distribution The statistic is approximately normally distributed if the sample sizes are large enough so that: Since its “approximately normal” we can describe the normal distribution in terms of mean and variance… …hence this z-variable will also be approximately standard normally distributed: Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.52 Testing and Estimating p1–p2… Because the population proportions (p1 & p2) are unknown, the standard error: is unknown. Thus, we have two different estimators for the standard error of , which depend upon the null hypothesis. We’ll look at these cases on the next slide… Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.53 Test Statistic for p1–p2… There are two cases to consider… Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.54 Example 13.8… IDENTIFY A consumer packaged goods (CPG) company is test marketing two new versions of soap packaging. Version one (bright colors) is distributed in one supermarket, while version two (simple colors) is in another. Since the first version is more expensive, it must outsell the other design, that is its market share, p1, must be greater than that of the other soap package design, i.e. p2. That is, we want to know, is p1 > p2? or, using the language of statistics: H1: (p1–p2) > 0 Hence our null hypothesis will be H0: (p1–p2) = 0 [case 1] Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.55 Example 13.8… IDENTIFY Here is the summary data… Our null hypothesis is H0: (p1–p2) = 0, i.e. is a “case 1” type problem, hence we need to calculate the pooled proportion: Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.56 Example 13.8… CALCULATE At a 5% significance level, our rejection region is: The value of our z-statistic is… Compare… Since 2.90 > 1.645, we reject H0 in favor of H1, that is, there is enough evidence to infer that the brightly colored design is more popular than the simple design. Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.57 Example 13.8… CALCULATE In Excel, we can use the Z-Test: 2 Proportions tool in the Data Analysis Plus package to “crunch the numbers”… Compare… p-value… Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.58 Example 13.9… IDENTIFY Suppose in our test marketing of soap packages scenario that instead of just a difference between the two package versions, the brightly colored design had to outsell the simple design by at least 3% Our research hypothesis now becomes: H1: (p1–p2) > .03 And so our null hypothesis is: H0: (p1–p2) = .03 Since the r.h.s. of the H0 equation is not zero, it’s a “case 2” type problem Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.59 Example 13.9… IDENTIFY Same summary data as before: Since this is a “case 2” type problem, we don’t need to calculate the pooled proportion, we can go straight to z: Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.60 Example 13.9… INTERPRET Since our calculated z-statistic (1.15) does not fall into our rejection region , there is not enough evidence to infer that the brightly colored design outsells the other design by 3% or more. Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.61 Confidence Intervals… The confidence interval estimator for p1–p2 is given by: and as you may suspect, its valid when… Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.62 Example 13.10… COMPUTE Create a 95% confidence interval for the difference between the two proportions of packaged soap sales from Ex. 13.8: Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.63 Identifying Factors… Factors that identify the z-test and estimator for p1–p2 Copyright © 2005 Brooks/Cole, a division of Thomson Learning, Inc. 13.64