High Reliability Org Intro by Soule
advertisement

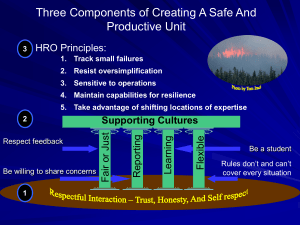
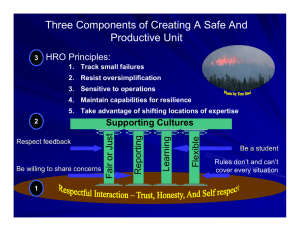
Introduction to High Reliability Organizations Ralph T. Soule What is Reliability? • “Reliability depends on the lack of unwanted, unanticipated, and unexplainable variance in performance” – Eric Hollnagel, 1993 Examples of High Reliability Organizations • • • • • • • • Nuclear power-generation plants Naval aircraft carriers Chemical production plants Offshore drilling rigs Air traffic control systems Incident command teams Wild land firefighting crews Hospital ER/Intensive care units Low Reliability Example of Low Reliability:Tenerife • Precursors – Small airport, overtaxed air controllers, speaking English, not accustomed to large planes, visibility obscured by fog – KLM Pilot in a hurry to complete mission before crew expended, spends most of his time running simulators as an instructor, not challenged by crew – Too much information passed too fast, speakers “stepping” on each other 1-The planes are parked at the end of runway 12 with the KLM in front of the Pan Am. 2-The KLM has made it to the end of runway 30 and is ready for takeoff. 3-The Pan Am has passed the first taxiway. 4-The Pan Am has passed the second taxiway. 5-The Pan Am has missed the third taxiway where it is supposed to exit. The KLM begins to takeoff. 6-The Pan Am tries to get off the runway but is hit by the KLM. 583 people die. “Swiss cheese” model of accident causation Reason, J. BMJ 2000;320:768-770 Copyright ©2000 BMJ Publishing Group Ltd. So Why Do Smart People Do Dangerous Things? • Excessive Workload – Physical and cognitive effort involved in task performance. • Lack of Situation Awareness – What’s going on? – What’s likely to happen next? – What will happen if I take a particular action? • Excessive Stress, Fatigue, Uncertainty, etc. – Impacts perceptual-motor performance, decisionmaking, etc. So Why Do Smart People Do Dangerous Things? • Diminished Attention – Too much to attend to at once (overload) – Too little to attend to for too long (underload) • Poor Teamwork and Communication – Often due to poor layout of work space and/or poor layout of command and communication structure Common reasons why defensive weaknesses not detected and repaired • People involved tend to forget to be afraid • Bad events rare in well-defended systems, few people have direct experience with them Common reasons why defensive weaknesses not detected and repaired • Production demands are immediate, attention grabbing whereas safe operations generate a constant – and hence relatively uninteresting – non-event outcome – Reliability is invisible - nothing much to pay attention to – If people see nothing happening, easy to presume nothing is happening • If nothing is happening and they continue to operate has they have, they get fooled into thinking nothing will continue to happen Dangerous Defenses • Defense in depth – Redundancy makes systems more complex • Since some types of errors are not immediately recognizable, operators/maintainers will not learn from them as readily • Accumulated errors can allow ‘holes’ in defensive systems to line up and permit the passage of an accident trajectory – Unforeseen common mode failures can make it possible for errors to affect more than one layer simultaneously – Changing procedures to prevent the “last” problem can make the procedures more complex and introduce unforeseen failure modes Common reasons why defensive weaknesses not detected and repaired • Conclusion – If eternal vigilance is the price of freedom, then chronic unease is the price of safety – HROs are hard to sustain when the thing about which one is uneasy either has not happened or happened a long time ago – Accidents do not occur because people gamble and lose, they occur because people do not believe that the accident that is about to occur is possible – High Reliability • Operators/Managers of High Reliability Orgs assume that each day could be a bad day and act accordingly. Regarding safety information, they – – – – – Actively seek it Messengers are trained and rewarded Responsibility is shared Failures lead to far-reaching reforms New ideas are welcomed 5 Habits of Highly Reliable Organizations • Don't be tricked by your success – Preoccupation with failure • Defer to experts on the front line – Sensitivity to operations • Let the unexpected circumstances provide your solution – Resilience means having a steady head • Embrace complexity – Reluctance to simplify • Anticipate -- but also anticipate your limits – You can prepare for unexpected events, within limits Characteristics of HROs • Safety oriented culture • Operations are a team effort • Communications are highly valued • Always prepared for the unexpected • Multidisciplinary review of near- misses and adverse outcomes Characteristics of HROs • Strong, well defined leadership • safety oriented culture • operations are a team effort • flattened hierarchy for safety • communications revered • emergencies and the unexpected are rehearsed • place value on the “near miss” • multidisciplinary review • top brass (senior management) endorses • substantial budget devoted to training Characteristics of HROs • Safety oriented culture • Operations are a team effort How Different Organizations Handle Safety Information • Pathologic Culture Don’t want to know, messengers are shot, responsibility is shirked, failure is punished or concealed, new ideas are actively discouraged • Bureaucratic Culture May not find out, messengers are listened to... if they arrive, responsibility is compartmentalized, failures lead to local repairs, new ideas often present problems • Generative Culture Actively seek it, messengers are trained and rewarded, responsibility is shared, failures lead to far-reaching reforms, new ideas are welcomed Tools • Commander's Intent – Intended to help people read the your mind if they run into uncertainty about how to carry out the orders under “field” conditions. – – – – – • Situation (Here is what I think we face). Task (Here is what I think we should do). Intent (Here is why) Concerns (Here is what we should keep our eye on) Calibration (Now, talk to me (about your questions and concerns)) Pre-mortems – Tool for anticipating the unexpected Summary • High reliability is a process, not a result • Safety is a dynamic non-event • Error management has two components: – Error reduction and – Error containment • Engineering a Safety Culture – – – – reporting culture -> providing the data for navigation just culture -> trust, deciding when there is fault flexible culture -> adjust learning culture -> plan, do, check, act • If eternal vigilance is the price of freedom, then chronic unease is the price of safety References • The Logic of Failure, Dietrich Dorner • Intuition at Work, Gary Klein • The Vulnerable System: An Analysis of the Tenerife Air Disaster, Karl E. Weick • The 1996 Mount Everest climbing disaster: The breakdown of learning in teams, D. Christopher Kayes, Into Thin Air, Jon Krakauer, Outside Online • Managing the Risks of Organizational Accidents, James Reason • Managing the Unexpected, Weick and Suttcliff • Inviting Disaster, James Chiles • http://www.highreliability.org/