Performance Tradeoffs for Static Allocation of Zero
advertisement

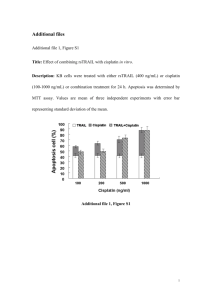
Performance Tradeoffs for Static Allocation of Zero-Copy Buffers Pål Halvorsen, Espen Jorde, Karl-André Skevik, Vera Goebel, and Thomas Plagemann Institute for Informatics, University of Oslo, Norway Multimedia and Telecommunications Track (MTT ’02) – 28th EUROMICRO Conference, Dortmund, Germany, September 2002 Overview Application scenario The INSTANCE project Zero-copy data paths static buffer allocation performance evaluation Summary and conclusions MTT’02, Dortmund, Germany, September 2002 © 2002 Pål Halvorsen Application Scenario Media-on-Demand server: Applicable in applications like News- or Video-on-Demand provided by city-wide cable or pay-per-view companies Multimedia Storage Server Network Retrieval is the bottleneck: Some important factors: • Memory management • Communication protocol processing • Error management MTT’02, Dortmund, Germany, September 2002 Network Project goals: Optimize performance within a single server: • Reduce resource requirements • Maximize number of clients © 2002 Pål Halvorsen The INSTANCE Project We try to make optimal use of a given set of resources: network level framing integrated error management memory architecture Project goals: periodic broadcast service dynamic zero-copy static zero-copy buffers MTT’02, Dortmund, Germany, September 2002 Optimize performance within a single server: buffers • Reduce resource requirements • Maximize number of clients © 2002 Pål Halvorsen General Operating System Structure and Data Path application user space kernel space file system MTT’02, Dortmund, Germany, September 2002 communication system © 2002 Pål Halvorsen Example: Intel Hub Architecture (850 Chipset) – II Pentium 4 Processor registers cache(s) system bus Thus, copy operations is expensive: Note: application these transfers only show data movement between sub-systems. bandwidth Additionally, is limited data touchingcommunication operations file system within a sub-system will require that data issystem moved frommemory consumes andCPU to the cycles CPU, e.g.: disk network card - checksum calculation - encryption - data affects encoding the cache - forward error correction (64-bit, 400/533 MHz) memory controller hub RAM interface (two 64-bit, 200 MHz) RDRAM file system RDRAM communication system RDRAM application RDRAM hub interface (four 8-bit, 66 MHz) I/O controller hub PCI slots PCI bus (32-bit, 33 MHz) MTT’02, Dortmund, Germany, September 2002 network card PCI slots PCI slots disk © 2002 Pål Halvorsen Zero-Copy: Basic Idea application user space kernel space file system buf b_data communication system mbuf m_data bus(es) MTT’02, Dortmund, Germany, September 2002 © 2002 Pål Halvorsen Zero-Copy: Dynamic Allocation user space memory application mbuf memory pools buf memory pools buf buf cluster file system MTT’02, Dortmund, Germany, September 2002 communication system mbuf mbuf cluster © 2002 Pål Halvorsen Zero-Copy: Static Allocation Allocate all needed memory during stream initialization If possible, set all buf and mbuf data pointers Use alternating buffers MTT’02, Dortmund, Germany, September 2002 header data pointer mbuf pointer buf pointer bufs mbufs data area © 2002 Pål Halvorsen Zero-Copy: Operations Stream initialization currently used buffer header send offset currently used buffer header send offset bufs bufs mbufs mbufs data area data area Read operation Send operation Stream close MTT’02, Dortmund, Germany, September 2002 © 2002 Pål Halvorsen Performance: Test Setup Implemented in NetBSD Dell Precision Workstation 620 PIII 1 GHz CPU 100 Mbps network card Single disk storage Software probe to measure allocation times RDTSC instruction CPUID instruction probe overhead 206 cycles MTT’02, Dortmund, Germany, September 2002 © 2002 Pål Halvorsen Evaluation: Zero-Copy Transfer Rate Zero-copy transfer rate limited by network card and storage system A later dynamic version: saturated a 1 Gbps NIC reduced processing time by approximately 50 % Throughput increase of ~2.7 times per stream (can at least double the number of clients) approx. 12 Mbps approx. 6 Mbps huge improvement in number of concurrent streams MTT’02, Dortmund, Germany, September 2002 © 2002 Pål Halvorsen Evaluation: Static Allocation Saves time to get and free memory regions malloc – 5.80 µs, free – 6.48 µs get_poolitem – 0.15 µs, put_poolitem – 0.15 µs e.g., 1 GB file, 64 KB disk blocks, 1 KB packets retrieving 1 GB 16 K disk I/Os (1 buf, 1 region each) sending 1 GB 1 M packets (2 mbufs each, sharing data region) totally 2 M + 32 K get and free operations 0.63 s sending the whole file assuming a pool (takes totally about 10 s, or 7s kernel time, to send having fast devices) Might save time to set data pointers and length fields Inflexible (variable bit rate streams) Strict waiting on static buffers Saves CPU cycles at the cost of statically allocating memory MTT’02, Dortmund, Germany, September 2002 © 2002 Pål Halvorsen Conclusions and Future Work Zero-copy reduces data movement overhead in the OS (reduces processing time by approximately 50 %) Static versus dynamic allocation of zero-copy buffers tradeoff between flexibility and CPU resources static saves CPU, but inflexible dynamic is flexible, but adds allocation costs we will use our dynamic implementation in our future work Ongoing and future work: Tune dynamic implementation (ongoing) Zero-copy network–disk path (ongoing) Add memory caching MTT’02, Dortmund, Germany, September 2002 © 2002 Pål Halvorsen Questions?? MTT’02, Dortmund, Germany, September 2002 © 2002 Pål Halvorsen