Submission Document
advertisement

Kaggle - Dunnhumby's Shopper Challenge
2nd Place Finish Methodology
Neil Schneider
Neil.Schneider@Milliman.com
Introduction
The Dunnhumby's Shopper Challenge asked for models to predict the shopping habits of customers
followed by a grocery chains customer loyalty cards. The goal was predict the date of return and the
spend amount during that visit. The scoring metric was the percentage right for selecting the correct
day of return and being within $10 of the actual spend amount. The paper will outline the strategy used
to correctly predict 18.67% of the shopper's habits. A slight alternative to this method, which was not
selected for inclusion in the competition, will also be discussed. This method improved the score to
18.83%. All methodologies were developed using SAS, R, and JMP.
Data Preparations
The raw shopper data was processed to add additional variables before beginning any analyses. Both
the training and testing sets, went through a 4 step process. All code can be found in Appendix A. The
first step was to limit the time period to dates between April 1, 2010 and March 31, 2011. Step two
involved creating additional variables for the Day of the Week and the Day of the Month of each
purchase. The third step involved retaining the previous visits information to be used in the final step to
create a days between visits variable. Control processes were applied to the training set and retained
visit information was nullified for the first entry of each shopper. Unfortunately, in the testing set the
first visit for each customer included the last visits information from the previous customer. The impact
of this error should be negligible if there is any impact at all. The processed data were also used to
create a Last Visit set. This set included the last entry for each shopper and created a variable indicating
the number of days already passed since his or her last visit.
One more set was created from the raw data. This was the results for the customers in the training set.
There was one entry per shopper and it was the first return date after March 31, 2011. It only included
the customer name, visit_date and visit_spend.
Visit_Spend Methodology
All discussed methods used the same spend amounts. The amounts will differ based on the projected
day of the week for the shopper's return, but the methodology is the same. A member's next spend
amount was developed on historical data only. There was no training a model on data past March 31,
2011. Training data are used later to optimize method selection.
The chosen method optimizes the results based on the testing statistic for this competition. The metric for
determining if the projected visit spend amount is correct was being with $10 of the actual spend amount.
Maximizing the number of spends within the $20 window was accomplished by empirically calculating the
$20 range that a customer most often spends. I termed this window the Modal Range. Typically, it is
less than both the mean and the median of a customer's spending habits. Predictions were further
enhanced by determining a modal range for each day of the week. In the final submissions, these values
were also front weighted by triangle weighting the dates from April 1, 2010. (A spend on April 1, 2010
has a weight of one and a spend on March 31, 2011 has a weight of 365.)
The projected visit spend was based off the day of the week of the projected visit date. In cases where
the customer does not have enough experience on the return day of the week, their overall modal range
is assumed. The training data were used to develop credibility thresholds for selecting a customer's daily
modal range verse their overall modal range. The thresholds were hard cutoffs. If the customer did not
have enough experience on a particular day of the week, the overall modal range was projected. The
overall modal range was not front weighted like the daily ranges.
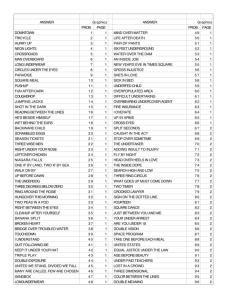
Optimized thresholds base on the training data are found in the following table.
Day of the Week
Sunday
Monday
Tuesday
Wednesday
Thursday
Friday
Saturday
Experience Threshold
15
17
22
19
16
26
21
*These thresholds should have been optimized based on the actual return visit date,
but may have been optimized for a previous date projection method.
Visit_Date Methodology
The key modeling technique used in predicting a customer's return date was a Generlized Boosting
Regression Model. In R, the "gbm" package provided the programming for this model. Individual
models were developed for each possible day of return from April 1, 2011 through April 9, 2011. April
9th was chosen as the last day because of time constraints and the empirical distribution of the training
data. Each day was considered to be a Bernoulli, for whether the customer first returned on that date.
The first step was to create a suite of explanatory variable to use in the GBM regression. Many of the
variables used were developed in previous methods. Ultimately, 106 variables were entered into the
GBM model. There are sets of variables that may have been perfectly correlated with other columns,
but that does not matter in GBM modeling. The table below will list the variables:
Variable
Wkday_prior_freq
Avg_days_prior
Med_days_prior
Mod_days_prior
stdev_days_prior
Wkday_weight
Wkday_freq
Wkday_prob
Wkday_prob_strength
Number of this
Type
7 - one per day of
the week
7 - one per day of
the week
7 - one per day of
the week
7 - one per day of
the week
7 - one per day of
the week
7 - one per day of
the week
7 - one per day of
the week
7 - one per day of
the week
7 - one per day of
the week
Wkday_total_weight
1
Wkday_total_freq
1
Days_since_freq
36 - one per
common days
between visits
Days_since_total_freq
1
Last_spend
1
Last_dayofmth
1
Last_day
1
Days_already_past
1
Description
Counts of visits based on the previous visit's
day of the week.
The average number of days since the
previous visit
The median number of days since the
previous visit
The mode number of days since the previous
visit
The standard deviation of days since the
previous visit
Sum of weighted visits for each day of the
week
Count of visits for each day of the week
The probability of a customer visiting on a
day of the week based on the weights.
The wkday_prob variable multiplied by the
wkday_freq variable.
Sum of wkday_weights for each customer
Sum of wkday_freq for each customer
Count of visits after common number of days
between visits.
Sum of Days_since_freq variable for each
customer
The spend amount of the last visit before
April 1, 2011
The day of the month of the last visit before
April 1, 2011
The day of the week of the last visit before
April 1, 2011
The number of days between the last visit
and April 1, 2011
The next step was to create the models. Each date had a model designed for it. Due to processing time
parameters such as the number of cross-validation folds, number of trees and the shrinkage were
changed between dates. These parameters can be extracted from the GBM class data provided with
this documentation. Cross-validation folds were either 5 or 10. The number of trees ranged from
30,000 to 50,000 and the shrinkage ranges from 0.0001 to 0.002. The interaction depth also ranged
from 2 to 3. The best iteration number was based on the Cross-validation method.
Finally, the test data was run through the GBM models. The set of nine scores from the models were
compared. In the final selected model, the maximum score for each customer was chosen. This
maximum represented the expected day of return. This method produced the second place finish
submission. In another submission, I ran a nominal logistic regression on a customer's date of return
and the scores from the GBM models. This model was then used to project the test customers' date of
return. This additional step added 0.16 to the final score, but was not submitted for consideration.
Control of Work Product
Attempts to recreate the winning submission were slowed due to poor version control as the
competition came to a close. The training sets used in the GBM model had two errors for each
customer. The Wkday_prior_freq variable had one visit shifted from one day to another. This also
created an issue with avg, med, and mod _days_prior variables. The average variable is the most
influenced by outliers and had the biggest impact. While, these errors were corrected in SAS, it was not
updated in R. In the test data used to create the final predictions, there was only an error in the count
of wkday_prior_freq. The error was the inclusion of one additional count that should not have been
included. Code to create the erroneous data is included in the SAS programs. All erroneous sets end in
the suffix "_bad". These errors should not have hurt the predictive power of the model and correcting
them should improve on or maintain the current results.
Code
Code to recreate this submission is included in its entirety in the appendix and in separately attached zip
file: Winning Submission.zipx.
APPENDIX
*******************************************************;
*
*;
*
Kaggle - Dunnhumby's Shoppers Challenge
*;
*
*;
*
Written by Neil Schneider
*;
*
*;
*
Program processes raw shopper data for use in
*;
*
subsequent programs.
*;
*
*;
*******************************************************;
libname Drive 'C:\Dunnhumby\Winning Submission\';
libname raw 'C:\Dunnhumby\SAS Data';
*Bring in and modify the raw data;
*Step 1: Limit data to explanatory period 4/1/2010-3/31/2011;
*Step 2: Create "Day of Week" and "Day of Month" variables;
*Step 3: Retain Date, Spend, Day of Week, and Day of Month variable from the
previous record.;
*NOTE: Additional code to reset the first entry for each member was not
applied to the testing data set;
*Step 4: Create the "Days Since Prior" variable. This is the time between
visits;
data drive.train_set_mod;
set raw.Train_set;
by customer_id visit_date;
where visit_date ge '01APR2010'd and visit_date lt '01APR2011'd;
dayofmth = day(visit_date);
day = weekday(visit_date);
format prior_date yymmdd10.;
prior_date = lag1(visit_date);
prior_spend = lag1(visit_spend);
prior_day = weekday(prior_date);
prior_dayofmth = day(prior_date);
if first.customer_id then do;
days_since_prior = .;
prior_date = .;
prior_spend = .;
prior_day = .;
prior_dayofmth = .;
end;
else days_since_prior = visit_date - prior_date;
run;
***THIS IS THE CONSEQUENCE OF BAD VERSION CONTROL***;
*This data is used in the GBM regressions.;
*I guess this proves the system is robust to still produce
acceptable answers;
*Drop first customer_id since there is not prior information to
fill in on this line;
data train_set_mod_bad;
set raw.Train_set;
by customer_id;
if ^first.customer_id then output;
run;
*Use the prior information to fill in information.
All customers after the first will have a erroneous entry derived
from the previous customer's last record;
data drive.train_set_mod_bad;
set train_set_mod_bad;
by customer_id visit_date;
where visit_date ge '01APR2010'd and visit_date lt
'01APR2011'd;
dayofmth = day(visit_date);
day = weekday(visit_date);
format prior_date yymmdd10.;
prior_date = lag1(visit_date);
prior_spend = lag1(visit_spend);
prior_day = weekday(prior_date);
prior_dayofmth = day(prior_date);
days_since_prior = visit_date - prior_date;
run;
*Do this correctly for the test group;
data drive.test_set_mod;
set raw.test_set;
by customer_id visit_date;
where visit_date ge '01APR2010'd and visit_date lt '01APR2011'd;
dayofmth = day(visit_date);
day = weekday(visit_date);
format prior_date yymmdd10.;
prior_date = lag1(visit_date);
prior_spend = lag1(visit_spend);
prior_day = weekday(prior_date);
prior_dayofmth = day(prior_date);
days_since_prior = visit_date - prior_date;
if first.customer_id then do;
days_since_prior = .;
prior_date = .;
prior_spend = .;
prior_day = .;
prior_dayofmth = .;
end;
else days_since_prior = visit_date - prior_date;
run;
***THIS IS THE CONSEQUENCE OF BAD VERSION CONTROL***;
*This data is used in the GBM regressions.;
*I guess this proves the system is robust to still produce
acceptable answers;
*Use the prior information to fill in information.
All customers after the first will have a erroneous entry derived
from the previous customer's last record;
data drive.test_set_mod_bad;
set raw.test_set;
by customer_id visit_date;
where visit_date ge '01APR2010'd and visit_date lt
'01APR2011'd;
dayofmth = day(visit_date);
day = weekday(visit_date);
format prior_date yymmdd10.;
prior_date = lag1(visit_date);
prior_spend = lag1(visit_spend);
prior_day = weekday(prior_date);
prior_dayofmth = day(prior_date);
If visit_date gt prior_date then days_since_prior =
visit_date - prior_date;
else days_since_prior = .;
run;
*Using the sets created above.;
*Retain the last entry for each shopper;
*Create a variable counting the days passed since the last visit.;
data drive.train_last_spend;
set drive.train_set_mod;
by customer_id;
days_already_past = '01APR2011'd - visit_date;
rename visit_date = last_date visit_spend=last_spend
dayofmth = last_dayofmth day=last_day
prior_date = sec_last_date prior_spend=sec_last_spend
prior_dayofmth=sec_last_dayofmth prior_day=sec_last_day
days_since_prior=last_days_since;
if last.customer_id;
run;
*Using the sets created above.;
*Retain the last entry for each shopper;
*Create a variable counting the days passed since the last visit.;
data drive.test_last_spend;
set drive.test_set_mod;
by customer_id;
days_already_past = '01APR2011'd - visit_date;
rename visit_date = last_date visit_spend=last_spend
dayofmth = last_dayofmth day=last_day
prior_date = sec_last_date prior_spend=sec_last_spend
prior_dayofmth=sec_last_dayofmth prior_day=sec_last_day
days_since_prior=last_days_since;
if last.customer_id;
run;
*Create training set results;
data drive.train_set_results_01APR2011;
set raw.train_set;
where visit_date ge '01APR2011'd;
by customer_id visit_date;
if first.customer_id;
run;
*Create Results dummy flags for R GBM regressions;
data drive.train_date_results_dummyflag;
set drive.train_set_results_01APR2011;
drop visit_spend;
*create date
apr_01
apr_02
apr_03
apr_04
apr_05
apr_06
apr_07
apr_08
apr_09
apr_10
apr_11
apr_12
apr_13
apr_14
apr_15
apr_16
apr_xx
flags;
= -1;
= -1;
= -1;
= -1;
= -1;
= -1;
= -1;
= -1;
= -1;
= -1;
= -1;
= -1;
= -1;
= -1;
= -1;
= -1;
= -1;
select (visit_date);
when ('01APR2011'd) apr_01
when ('02APR2011'd) apr_02
when ('03APR2011'd) apr_03
when ('04APR2011'd) apr_04
when ('05APR2011'd) apr_05
when ('06APR2011'd) apr_06
when ('07APR2011'd) apr_07
when ('08APR2011'd) apr_08
when ('09APR2011'd) apr_09
when ('10APR2011'd) apr_10
when ('11APR2011'd) apr_11
when ('12APR2011'd) apr_12
when ('13APR2011'd) apr_13
when ('14APR2011'd) apr_14
when ('15APR2011'd) apr_15
when ('16APR2011'd) apr_16
otherwise apr_xx = 1;
end;
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
1;
1;
1;
1;
1;
1;
1;
1;
1;
1;
1;
1;
1;
1;
1;
1;
run;
*Output CSV file for R;
proc export data = drive.train_date_results_dummyflag
outfile = 'C:\Dunnhumby\Winning
Submission\train_date_results.csv'
DBMS = csv replace;
run;
*************************************************************;
*
*;
*
Kaggle - Dunnhumby's Shoppers Challenge
*;
*
*;
*
Written by Neil Schneider
*;
*
*;
*
Program develops projections for shoppers' date of
*;
*
return to the store.
*;
*
*;
*************************************************************;
libname Drive 'C:\Dunnhumby\Winning Submission\';
********************************************************;
****************Training Data***************************;
********************************************************;
data train_set_date_mod;
merge drive.train_set_mod
drive.train_last_spend (keep= customer_id
days_already_past);
by customer_id;
run;
***THIS IS THE CONSEQUENCE OF BAD VERSION CONTROL***;
data train_set_date_mod_bad;
merge drive.train_set_mod_bad
drive.train_last_spend (keep= customer_id
days_already_past);
by customer_id;
run;
*Date prediction is based on Generalized Boosting Regression Model.;
*The following code creates variables to be considered by the GBM
function.;
**********************************************************************;
*************Days since last purchase frequencies*********************;
**********************************************************************;
*Determine frequency of the days between visits for a
customer;
*Only allows for days between visit that are greater than
the time already elasped;
proc summary missing data=train_set_date_mod;
where days_since_prior ge days_already_past;
class customer_id days_since_prior days_already_past;
output out=train_freq_days_since ;
run;
*Type 4 in the summary is the customer level frequency for
all eligible visits;
*Type 6 in the summary is the customer and days between
visits frequency;
*Only day frequencies over 5 are included;
data train_prob_days_since (drop= days_already_past _TYPE_
rename=mem_freq=days_since_total_freq
rename=_FREQ_=days_since_freq);
merge train_freq_days_since (where= (_TYPE_=4)
rename=(_FREQ_=mem_freq))
train_freq_days_since (where= (_TYPE_=6))
;
by customer_id;
days_since_prob = _FREQ_ / mem_freq;
if _FREQ_ gt 5;
run;
*x1 set is the number of visits for each days between visit
for each customer;
*null values are included when customers have a frequency
of 0-5;
proc transpose data=train_prob_days_since
out=train_prob_days_since_x1 (drop=_NAME_)
label=days_since_prior
prefix=days_since_freq;
by customer_id;
id days_since_prior;
var days_since_freq;
run;
*x2 set is the calculated probability of customers visiting
on that day;
*Again null values are created as above;
proc transpose data=train_prob_days_since
out=train_prob_days_since_x2 (drop=_NAME_)
label=days_since_prior
prefix=days_since_prob;
by customer_id;
id days_since_prior;
var days_since_prob;
run;
*Keep one entry per customer to include the total frequency
considered;
data train_prob_days_since_x3;
set train_prob_days_since;
by customer_id;
if first.customer_id;
keep customer_id days_since_total_freq;
run;
*Combined the three prior sets to create a days between
visit set to be included in the GBM regression;
data train_prob_days_since_x;
merge train_prob_days_since_x1
train_prob_days_since_x2
train_prob_days_since_x3;
by customer_id;
run;
*******************************************************************;
*************Day of week purchase frequencies**********************;
*******************************************************************;
*To calculate the probabilities of visits by a customer for
a given day of the week.
value of the weights by day are needed;
*The weights are the cube root of triangle front
weighting.;
proc sql;
create table train_freq_wkday as
select
customer_id
,day
,sum((visit_date - '01APR2010'd)**(1/3)) as
wkday_weight
,count(*) as wkday_freq
from train_set_date_mod
group by customer_id
,day
;
quit;
run;
*to calculate the probabilities of visits by a customer for
a given day of the week,
the total weight is needed;
*The weights are the cube root of triangle front
weighting.;
proc sql;
create table train_freq_wkday_total as
select
customer_id
,sum((visit_date - '01APR2010'd)**(1/3)) as
wkday_total_weight
,count(*) as wkday_total_freq
from train_set_date_mod
group by customer_id
;
quit;
run;
*The weighted frequencies and count of visits are combined;
*This step creates the probability of a visit for a day of
the week;
*Also a "strength" metric was created, this is the
probability weighted by the frequency;
data train_prob_day;
merge train_freq_wkday
train_freq_wkday_total
;
by customer_id;
wkday_prob = wkday_weight / wkday_total_weight;
wkday_prob_strength = wkday_prob * wkday_freq;
run;
*Transpose the weights for each day into a single row
for each customer;
proc transpose data=train_prob_day
out=train_prob_day_x1 (drop=_NAME_)
label=day
prefix=wkday_weight;
by customer_id;
id day;
var wkday_weight;
run;
*Transpose the frequency counts for each day into a single
row for each customer;
proc transpose data=train_prob_day
out=train_prob_day_x2 (drop=_NAME_)
label=day
prefix=wkday_freq;
by customer_id;
id day;
var wkday_freq;
run;
*Transpose the day of week probabilities for each day into
a single row for each customer;
proc transpose data=train_prob_day
out=train_prob_day_x3 (drop=_NAME_)
label=day
prefix=wkday_prob;
by customer_id;
id day;
var wkday_prob;
run;
*Transpose the strength of the day of week probabilities
for each day into a single row for each customer;
proc transpose data=train_prob_day
out=train_prob_day_x4 (drop=_NAME_)
label=day
prefix=wkday_prob_strength;
by customer_id;
id day;
var wkday_prob_strength;
run;
*Create a set for the total frequency and total weight for
a customer;
data train_prob_day_x5;
set train_prob_day;
by customer_id;
if first.customer_id;
keep customer_id wkday_total_freq wkday_total_weight;
run;
*Combine the prior group of datasets into a single set for
inclusion in the master set for the GBM regression;
data train_prob_day_x;
merge train_prob_day_x1
train_prob_day_x2
train_prob_day_x3
train_prob_day_x4
train_prob_day_x5
;
by customer_id;
run;
**********************************************************************;
********************Days Since Last Statistics************************;
**********************************************************************;
***THIS IS THE CONSEQUENCE OF BAD VERSION CONTROL***;
*Additional statistics about the days between visits to be
included in the GBM regression;
*Based on the day of the week of the previous visit;
proc summary nway missing data=train_set_date_mod_bad;
where prior_day ne .;
class customer_id prior_day;
var days_since_prior;
output out=train_prob_days_since_stats
(drop= _TYPE_ rename=_FREQ_=wkday_prior_freq)
mean=avg_days_prior
median=med_days_prior
mode=mod_days_prior
std=stdev_wkday_prior;
run;
*Group of transposes to change all all day of week
statistics into a single row for each customer;
proc transpose data=train_prob_days_since_stats
out=train_prob_days_since_stats_x1 (drop=_NAME_)
label=prior_day
prefix=wkday_prior_freq;
by customer_id;
id prior_day;
var wkday_prior_freq;
run;
proc transpose data=train_prob_days_since_stats
out=train_prob_days_since_stats_x2 (drop=_NAME_)
label=prior_day
prefix=avg_days_prior;
by customer_id;
id prior_day;
var avg_days_prior;
run;
proc transpose data=train_prob_days_since_stats
out=train_prob_days_since_stats_x3 (drop=_NAME_)
label=prior_day
prefix=med_days_prior;
by customer_id;
id prior_day;
var med_days_prior;
run;
proc transpose data=train_prob_days_since_stats
out=train_prob_days_since_stats_x4 (drop=_NAME_)
label=prior_day
prefix=mod_days_prior;
by customer_id;
id prior_day;
var mod_days_prior;
run;
proc transpose data=train_prob_days_since_stats
out=train_prob_days_since_stats_x5 (drop=_NAME_)
label=prior_day
prefix=stdev_wkday_prior;
by customer_id;
id prior_day;
var stdev_wkday_prior;
run;
*Group combination to include in the master set.;
data train_prob_days_since_stats_x;
merge train_prob_days_since_stats_x1
train_prob_days_since_stats_x2
train_prob_days_since_stats_x3
train_prob_days_since_stats_x4
train_prob_days_since_stats_x5
;
by customer_id;
run;
**********************************************************************;
*****************Create Train Master Set******************************;
**********************************************************************;
*This set includes all the information and statistics to be
include in the GBM regression;
*Also for the training set the first visit post March 31,
2011 is included;
*"If results" clause is used to drop the 48 customers who
do not return after March 31, 2010.;
data drive.train_master_set;
format customer_id last_date;
merge train_prob_days_since_stats_x
train_prob_day_x
train_prob_days_since_x
drive.train_last_spend
(drop= last_days_since sec:)
drive.train_set_results_01apr2011
(in=results)
;
by customer_id;
if results;
drop _NAME_;
run;
*Output CSV file for R;
proc export data = drive.train_master_set
outfile =
'C:\Dunnhumby\Winning Submission\train_master_set_R.csv'
DBMS = csv replace;
run;
********************************************************;
******************Test Data*****************************;
********************************************************;
data test_set_date_mod;
merge drive.test_set_mod
drive.test_last_spend (keep= customer_id
days_already_past);
by customer_id;
run;
***THIS IS THE CONSEQUENCE OF BAD VERSION CONTROL***;
data test_set_date_mod_bad;
merge drive.test_set_mod_bad
drive.test_last_spend (keep= customer_id
days_already_past);
by customer_id;
run;
*Date prediction is based on Generalized Boosting Regression Model.;
*The following code creates variables to be considered by the GBM
function.;
*All summaries below match the summaries for the training data above.
**********************************************************************;
***************Days since last purchase frequencies*******************;
**********************************************************************;
proc summary missing data=test_set_date_mod;
where days_since_prior ge days_already_past;
class customer_id days_since_prior days_already_past;
output out=test_freq_days_since ;
run;
data test_prob_days_since (drop= days_already_past _TYPE_
rename=mem_freq=days_since_total_freq
rename=_FREQ_=days_since_freq);
merge test_freq_days_since (where= (_TYPE_=4)
rename=(_FREQ_=mem_freq))
test_freq_days_since (where= (_TYPE_=6))
;
by customer_id;
days_since_prob = _FREQ_ / mem_freq;
if _FREQ_ gt 5;
run;
proc transpose data=test_prob_days_since
out=test_prob_days_since_x1 (drop=_NAME_)
label=days_since_prior
prefix=days_since_freq;
by customer_id;
id days_since_prior;
var days_since_freq;
run;
proc transpose data=test_prob_days_since
out=test_prob_days_since_x2 (drop=_NAME_)
label=days_since_prior
prefix=days_since_prob;
by customer_id;
id days_since_prior;
var days_since_prob;
run;
data test_prob_days_since_x3;
set test_prob_days_since;
by customer_id;
if first.customer_id;
keep customer_id days_since_total_freq;
run;
data test_prob_days_since_x;
merge test_prob_days_since_x1
test_prob_days_since_x2
test_prob_days_since_x3;
by customer_id;
run;
**********************************************************************;
***************Day of week purchase frequencies***********************;
**********************************************************************;
proc sql;
create table test_freq_wkday as
select
customer_id
,day
,sum((visit_date - '01APR2010'd)**(1/3)) as
wkday_weight
,count(*) as wkday_freq
from test_set_date_mod
group by customer_id
,day
;
quit;
run;
proc sql;
create table test_freq_wkday_total as
select
customer_id
,sum((visit_date - '01APR2010'd)**(1/3)) as
wkday_total_weight
,count(*) as wkday_total_freq
from test_set_date_mod
group by customer_id
;
quit;
run;
data test_prob_day;
merge test_freq_wkday
test_freq_wkday_total
;
by customer_id;
wkday_prob = wkday_weight / wkday_total_weight;
wkday_prob_strength = wkday_prob * wkday_freq;
run;
proc transpose data=test_prob_day
out=test_prob_day_x1 (drop=_NAME_)
label=day
prefix=wkday_weight;
by customer_id;
id day;
var wkday_weight;
run;
proc transpose data=test_prob_day
out=test_prob_day_x2 (drop=_NAME_)
label=day
prefix=wkday_freq;
by customer_id;
id day;
var wkday_freq;
run;
proc transpose data=test_prob_day
out=test_prob_day_x3 (drop=_NAME_)
label=day
prefix=wkday_prob;
by customer_id;
id day;
var wkday_prob;
run;
proc transpose data=test_prob_day
out=test_prob_day_x4 (drop=_NAME_)
label=day
prefix=wkday_prob_strength;
by customer_id;
id day;
var wkday_prob_strength;
run;
data test_prob_day_x5;
set test_prob_day;
by customer_id;
if first.customer_id;
keep customer_id wkday_total_freq wkday_total_weight;
run;
data test_prob_day_x;
merge test_prob_day_x1
test_prob_day_x2
test_prob_day_x3
test_prob_day_x4
test_prob_day_x5
;
by customer_id;
run;
*********************************************************************;
********************Days Since Last Statistics***********************;
*********************************************************************;
proc summary nway missing data=test_set_date_mod_bad;
where prior_day ne .;
class customer_id prior_day;
var days_since_prior;
output out=test_prob_days_since_stats
(drop= _TYPE_ rename=_FREQ_=wkday_prior_freq)
mean=avg_days_prior
median=med_days_prior
mode=mod_days_prior
std=stdev_wkday_prior;
run;
proc transpose data=test_prob_days_since_stats
out=test_prob_days_since_stats_x1 (drop=_NAME_)
label=prior_day
prefix=wkday_prior_freq;
by customer_id;
id prior_day;
var wkday_prior_freq;
run;
proc transpose data=test_prob_days_since_stats
out=test_prob_days_since_stats_x2 (drop=_NAME_)
label=prior_day
prefix=avg_days_prior;
by customer_id;
id prior_day;
var avg_days_prior;
run;
proc transpose data=test_prob_days_since_stats
out=test_prob_days_since_stats_x3 (drop=_NAME_)
label=prior_day
prefix=med_days_prior;
by customer_id;
id prior_day;
var med_days_prior;
run;
proc transpose data=test_prob_days_since_stats
out=test_prob_days_since_stats_x4 (drop=_NAME_)
label=prior_day
prefix=mod_days_prior;
by customer_id;
id prior_day;
var mod_days_prior;
run;
proc transpose data=test_prob_days_since_stats
out=test_prob_days_since_stats_x5 (drop=_NAME_)
label=prior_day
prefix=stdev_wkday_prior;
by customer_id;
id prior_day;
var stdev_wkday_prior;
run;
data test_prob_days_since_stats_x;
merge test_prob_days_since_stats_x1
test_prob_days_since_stats_x2
test_prob_days_since_stats_x3
test_prob_days_since_stats_x4
test_prob_days_since_stats_x5
;
by customer_id;
run;
**********************************************************************;
**********************Create Master Set*******************************;
**********************************************************************;
*This set includes all the information and statistics to
apply the GBM regression results
to make projections on a customers next visit date;
data drive.test_master_set;
format customer_id last_date;
merge test_prob_days_since_stats_x
test_prob_day_x
test_prob_days_since_x
drive.test_last_spend
(drop= last_days_since sec:)
;
by customer_id;
drop _NAME_;
run;
*This set includes the training set, but then only keeps
the test set data.
This will create copies of all the variables in the
training set onto the test set;
data drive.Test_Master_set_v2;
set drive.train_master_set
drive.test_master_set (in=test)
;
if test;
drop visit_date visit_spend;
run;
*Output CSV file for R;
proc export data = drive.Test_Master_set_v2
outfile =
'C:\Dunnhumby\Winning Submission\test_master_set_R.csv'
DBMS = csv replace;
run;
*******************************************************;
*
*;
*
Kaggle - Dunnhumby's Shoppers Challenge
*;
*
*;
*
Written by Neil Schneider
*;
*
*;
*
Program develops projections for shoppers' next *;
*
spend amount.
*;
*
*;
*******************************************************;
libname Drive 'C:\Dunnhumby\Winning Submission\';
********************************************************;
****************Training Data***************************;
********************************************************;
data train_set_mod;
set drive.train_set_mod;
run;
********************************************************;
****************Modal range spend***********************;
********************************************************;
*Modal Range Spend is defined as the empirical range with the maximum number
of spends;
*In case of a tie the first range is chosen. (This errs towards smaller
spends);
*Cross every customer spend amount with every other spend amount
for that customer;
*Use triangle weighting to give more recent spend dates more
weight;
proc sql;
create table prob_cnt as
select
main.customer_id
,main.visit_date
,main.visit_spend
,sum(case
when sec.visit_spend ge main.visit_spend and
sec.visit_spend - 20 le main.visit_spend
then (sec.visit_date - '01APR2010'd)
else 0
end) as prob_cnt
from train_set_mod as main
inner join train_set_mod as sec on
main.customer_id = sec.customer_id
group by main.customer_id
,main.visit_date
,main.visit_spend
;
quit;
run;
*Find the maximum count of spends by customer;
proc summary nway missing data=prob_cnt;
class customer_id;
var prob_cnt;
output out=max_prob (drop=_TYPE_) max=max_prob;
run;
*Output the modal range for each customer;
data drive.train_modal_range
(drop = visit_date visit_spend prob_cnt output_flag
rename=_FREQ_=total_visits);
merge prob_cnt
max_prob;
by customer_id;
retain output_flag;
*Reset Output Flag;
if first.customer_id then output_flag = 0;
*Output first spend amount to equal the maximum amount;
if prob_cnt = max_prob and output_flag = 0 then do;
output_flag = 1;
*The bottom value of the range was used in developing
the maximum range counts, so the middle of the range
is +10;
modal_range = visit_spend + 10;
output;
end;
run;
***********************************************************;
***********Modal range spend by Day of Week****************;
***********************************************************;
*Same idea as above, only this time each customer has a modal range of spend
amounts for Sunday through Saturday.;
*Cross every customer spend amount with every other spend amount
for that customer for a particular day of the week.;
*Use triangle weighting to give more recent spend dates more
weight;
proc sql;
create table prob_daily_cnt as
select
main.customer_id
,main.day
,main.visit_date
,main.visit_spend
,sum(case
when sec.visit_spend ge main.visit_spend and
sec.visit_spend - 20 le main.visit_spend
then (sec.visit_date - '01APR2010'd)
else 0
end) as prob_cnt
from train_set_mod as main
inner join train_set_mod as sec on
main.customer_id = sec.customer_id and
main.day = sec.day
group by main.customer_id
,main.day
,main.visit_date
,main.visit_spend
;
quit;
run;
*Find the maximum count of spends by customer and day of the
week;
proc summary nway missing data=prob_daily_cnt;
class customer_id day;
var prob_cnt;
output out=max_prob (drop=_TYPE_) max=max_prob;
run;
*Output the modal range for each customer;
data modal_range_wkday
(drop = visit_date visit_spend prob_cnt output_flag);
merge prob_daily_cnt
max_prob;
by customer_id day;
retain output_flag;
*Reset Output Flag;
if first.day then output_flag = 0;
*Output first spend amount to equal the maximum amount;
if prob_cnt = max_prob and output_flag = 0 then do;
output_flag = 1;
*The bottom value of the range was used in developing
the maximum range counts, so the middle of the range
is +10;
modal_range = visit_spend + 10;
output;
end;
run;
*Transpose the day of week variable into columns;
proc transpose data=modal_range_wkday
out=drive.train_modal_range_wkday
label=day
prefix=Modal_range_;
by customer_id;
id day;
var modal_range;
run;
********************************************************;
**********Number of Visits during entire year***********;
********************************************************;
proc summary nway missing data=train_set_mod;
class customer_id day;
output out=drive.train_entire_visits (drop=_TYPE_
rename=_FREQ_=visit_num_entire);
run;
proc transpose data=drive.train_entire_visits
out=drive.train_entire_visit_wkday
label=day
prefix= visit_num_entire_;
by customer_id;
id day;
var visit_num_entire;
run;
*Find the answers;
data drive.train_forecast_spend (drop=_NAME_);
merge drive.train_last_spend
drive.train_modal_range
drive.train_modal_range_wkday
drive.train_entire_visit_wkday
drive.train_set_results_01apr2011 (in=results);
by customer_id;
if results;
run;
********************************************************;
******************Test Data*****************************;
********************************************************;
data test_set_mod;
set drive.test_set_mod;
run;
********************************************************;
****************Modal range spend***********************;
********************************************************;
*Modal Range Spend is defined as the empirical range with the maximum number
of spends;
*In case of a tie the first range is chosen. (This errs towards smaller
spends);
*Cross every customer spend amount with every other spend amount
for that customer;
*Use triangle weighting to give more recent spend dates more
weight;
proc sql;
create table prob_cnt as
select
main.customer_id
,main.visit_date
,main.visit_spend
,sum(case
when sec.visit_spend ge main.visit_spend and
sec.visit_spend - 20 le main.visit_spend
then 1
else 0
end) as prob_cnt
from test_set_mod as main
inner join test_set_mod as sec on
main.customer_id = sec.customer_id
group by main.customer_id
,main.visit_date
,main.visit_spend
;
quit;
run;
*Find the maximum count of spends by customer;
proc summary nway missing data=prob_cnt;
class customer_id;
var prob_cnt;
output out=max_prob (drop=_TYPE_) max=max_prob;
run;
*Output the modal range for each customer;
data drive.test_modal_range
(drop = visit_date visit_spend prob_cnt output_flag
rename=_FREQ_=total_visits);
merge prob_cnt
max_prob;
by customer_id;
retain output_flag;
*Reset Output Flag;
if first.customer_id then output_flag = 0;
*Output first spend amount to equal the maximum amount;
if prob_cnt = max_prob and output_flag = 0 then do;
output_flag = 1;
*The bottom value of the range was used in developing
the maximum range counts, so the middle of the range
is +10;
modal_range = visit_spend + 10;
output;
end;
run;
***********************************************************;
***********Modal range spend by Day of Week****************;
***********************************************************;
*Same idea as above, only this time each customer has a modal range of spend
amounts for Sunday through Saturday.;
*Cross every customer spend amount with every other spend amount
for that customer for a particular day of the week.;
*Use triangle weighting to give more recent spend dates more
weight;
proc sql;
create table prob_daily_cnt as
select
main.customer_id
,main.day
,main.visit_date
,main.visit_spend
,sum(case
when sec.visit_spend ge main.visit_spend and
sec.visit_spend - 20 le main.visit_spend
then (sec.visit_date - '01APR2010'd)
else 0
end) as prob_cnt
from test_set_mod as main
inner join test_set_mod as sec on
main.customer_id = sec.customer_id and
main.day = sec.day
group by main.customer_id
,main.day
,main.visit_date
,main.visit_spend
;
quit;
run;
*Find the maximum count of spends by customer and day of the
week;
proc summary nway missing data=prob_daily_cnt;
class customer_id day;
var prob_cnt;
output out=max_prob (drop=_TYPE_) max=max_prob;
run;
*Output the modal range for each customer;
data modal_range_wkday
(drop = visit_date visit_spend prob_cnt output_flag);
merge prob_daily_cnt
max_prob;
by customer_id day;
retain output_flag;
*Reset Output Flag;
if first.day then output_flag = 0;
*Output first spend amount to equal the maximum amount;
if prob_cnt = max_prob and output_flag = 0 then do;
output_flag = 1;
*The bottom value of the range was used in developing
the maximum range counts, so the middle of the range
is +10;
modal_range = visit_spend + 10;
output;
end;
run;
*Transpose the day of week variable into columns;
proc transpose data=modal_range_wkday
out=drive.test_modal_range_wkday
label=day
prefix=Modal_range_;
by customer_id;
id day;
var modal_range;
run;
********************************************************;
**********Number of Visits during entire year***********;
********************************************************;
proc summary nway missing data=test_set_mod;
class customer_id day;
output out=drive.test_entire_visits (drop=_TYPE_
rename=_FREQ_=visit_num_entire);
run;
proc transpose data=drive.test_entire_visits
out=drive.test_entire_visit_wkday
label=day
prefix= visit_num_entire_;
by customer_id;
id day;
var visit_num_entire;
run;
*Find the answers;
data drive.test_forecast_spend (drop=_NAME_);
merge drive.test_last_spend
drive.test_modal_range
drive.test_modal_range_wkday
drive.test_entire_visit_wkday;
by customer_id;
run;
# *********************************************************;
#*
*;
#*
Kaggle - Dunnhumby's Shoppers Challenge
*;
#*
*;
#*
Written by Neil Schneider
*;
#*
*;
#*
Program uses loaded GBM results for each modeled
*;
#*
day to create scores used in JMP.
*;
#*
*;
# *********************************************************;
#Load R Workspace
load("C:/Dunnhumby/Winning Submission/GBM_results_R_workspace.RData")
#Load Libraries
#install.packages("gbm")
library("gbm")
#Load training and test date sets created in SAS
train_date_master <- as.matrix(read.csv("C:/Dunnhumby/Winning
Submission/train_master_set_R.csv"))
test_date_master <- as.matrix(read.csv("C:/Dunnhumby/Winning Submission/test_master_set_R.csv"))
train_date_results <- as.matrix(read.csv("C:/Dunnhumby/Winning Submission/train_date_results.csv"))
#Set Nulls and NA to 0
#Turn data into numerics. The Date field will become NAs but that is ok.
train_date_master[is.na(train_date_master)]<-0
train_date_master <- apply(train_date_master, 2, as.numeric)
test_date_master[is.na(test_date_master)]<-0
test_date_master <- apply(test_date_master, 2, as.numeric)
#Modify results and combine with master set
train_date_results[train_date_results==-1]<-0
train_date_results <- apply(train_date_results, 2, as.numeric)
train_date_master <- cbind(train_date_master[,1:110],train_date_results[,3:19])
colnames(train_date_master)[111:127] <- colnames(train_date_results[,3:19])
#Sample GBM code
#Models were run for each day up to Apr09. That cutoff was choosen based on time available to the
end of contest
#and the number of actual returns drops to low levels after the 9th.
#All GBM code can be recreated from loaded workspace with GBM class variables
# gbm1 <- gbm(apr_01~.,data=as.data.frame(train_date_master[1:99952,c(3:108,111)]),
#
#offset = NULL,
#
#misc = NULL,
#
distribution = "bernoulli",
#
#w = NULL,
#
#
#
#
#
#
#
#
#
#
#
#
#
#var.monotone = NULL,
n.trees = 50000,
interaction.depth = 3,
n.minobsinnode = 10,
shrinkage = 0.001,
bag.fraction = 0.5,
train.fraction = 1.0,
cv.folds = 5,
keep.data = FALSE,
verbose = TRUE,
#var.names = NULL,
#response.name = NULL
)
#cross-validation method is used to get the best iteration number
#predictions are made for both the training and test sets
best.iter.1 <- gbm.perf(gbm1,method="cv")
gbm.predict.1 <as.matrix(predict.gbm(gbm1,as.data.frame(train_date_master[1:99952,c(3:108,111)]),best.iter.1))
gbm.predict.test.1 <as.matrix(predict.gbm(gbm1,as.data.frame(test_date_master[1:10000,3:108]),best.iter.1))
best.iter.2 <- gbm.perf(gbm2,method="cv")
gbm.predict.2 <as.matrix(predict.gbm(gbm2,as.data.frame(train_date_master[1:99952,c(3:108,112)]),best.iter.2))
gbm.predict.test.2 <as.matrix(predict.gbm(gbm2,as.data.frame(test_date_master[1:10000,3:108]),best.iter.2))
best.iter.3 <- gbm.perf(gbm3,method="cv")
gbm.predict.3 <as.matrix(predict.gbm(gbm3,as.data.frame(train_date_master[1:99952,c(3:108,113)]),best.iter.3))
gbm.predict.test.3 <as.matrix(predict.gbm(gbm3,as.data.frame(test_date_master[1:10000,3:108]),best.iter.3))
best.iter.4 <- gbm.perf(gbm4,method="cv")
gbm.predict.4 <as.matrix(predict.gbm(gbm4,as.data.frame(train_date_master[1:99952,c(3:108,114)]),best.iter.4))
gbm.predict.test.4 <as.matrix(predict.gbm(gbm4,as.data.frame(test_date_master[1:10000,3:108]),best.iter.4))
best.iter.5 <- gbm.perf(gbm5,method="cv")
gbm.predict.5 <as.matrix(predict.gbm(gbm5,as.data.frame(train_date_master[1:99952,c(3:108,115)]),best.iter.5))
gbm.predict.test.5 <as.matrix(predict.gbm(gbm5,as.data.frame(test_date_master[1:10000,3:108]),best.iter.5))
best.iter.6 <- gbm.perf(gbm6,method="cv")
gbm.predict.6 <as.matrix(predict.gbm(gbm6,as.data.frame(train_date_master[1:99952,c(3:108,116)]),best.iter.6))
gbm.predict.test.6 <as.matrix(predict.gbm(gbm6,as.data.frame(test_date_master[1:10000,3:108]),best.iter.6))
best.iter.7 <- gbm.perf(gbm7,method="cv")
gbm.predict.7 <as.matrix(predict.gbm(gbm7,as.data.frame(train_date_master[1:99952,c(3:108,117)]),best.iter.7))
gbm.predict.test.7 <as.matrix(predict.gbm(gbm7,as.data.frame(test_date_master[1:10000,3:108]),best.iter.7))
best.iter.8 <- gbm.perf(gbm8,method="cv")
gbm.predict.8 <as.matrix(predict.gbm(gbm8,as.data.frame(train_date_master[1:99952,c(3:108,118)]),best.iter.8))
gbm.predict.test.8 <as.matrix(predict.gbm(gbm8,as.data.frame(test_date_master[1:10000,3:108]),best.iter.8))
best.iter.9 <- gbm.perf(gbm9,method="cv")
gbm.predict.9 <as.matrix(predict.gbm(gbm9,as.data.frame(train_date_master[1:99952,c(3:108,119)]),best.iter.9))
gbm.predict.test.9 <as.matrix(predict.gbm(gbm9,as.data.frame(test_date_master[1:10000,3:108]),best.iter.9))
#create individual vectors for each date
apr01 <- (train_date_master[1:99952,111])
apr02 <- (train_date_master[1:99952,112])
apr03 <- (train_date_master[1:99952,113])
apr04 <- (train_date_master[1:99952,114])
apr05 <- (train_date_master[1:99952,115])
apr06 <- (train_date_master[1:99952,116])
apr07 <- (train_date_master[1:99952,117])
apr08 <- (train_date_master[1:99952,118])
apr09 <- (train_date_master[1:99952,119])
#combine training and test predictions with actual date flags
gbm.predict.train <cbind(train_date_master[,1],gbm.predict.1,gbm.predict.2,gbm.predict.3,gbm.predict.4,gbm.predict.5,
gbm.predict.6,gbm.predict.7,gbm.predict.8,gbm.predict.9,
apr01,apr02,apr03,apr04,apr05,apr06,apr07,apr08,apr09)
#Apr data information from the first 10000 records in the training set are used as place holders for the
variables
gbm.predict.test <cbind(test_date_master[,1],gbm.predict.test.1,gbm.predict.test.2,gbm.predict.test.3,gbm.predict.test.4,
gbm.predict.test.5,
gbm.predict.test.6,gbm.predict.test.7,gbm.predict.test.8,gbm.predict.test.9,
apr01[1:10000],apr02[1:10000],apr03[1:10000],apr04[1:10000],apr05[1:10000],
apr06[1:10000],apr07[1:10000],apr08[1:10000],apr09[1:10000])
#The wrongly mapped on date flag are all set to 0
gbm.predict.test[,11:18] <- 0
#Stack the sets and output them into a csv for JMP.
gbm.predict.all <- rbind(gbm.predict.train,gbm.predict.test)
write.csv(gbm.predict.all,"C:/Dunnhumby/Winning Submission/Apr01_Apr09_JMP.csv")
*******************************************************;
*
*;
*
Kaggle - Dunnhumby's Shoppers Challenge
*;
*
*;
*
Written by Neil Schneider
*;
*
*;
*
Program combines date and spend projections to *;
*
create the final submission.
*;
*
*;
*******************************************************;
*Bring in results from R;
PROC IMPORT OUT= drive.Results_from_R
DATAFILE=
"C:\Dunnhumby\Winning Submission\Apr01_Apr09_JMP.csv"
DBMS=CSV REPLACE;
GETNAMES=YES;
DATAROW=2;
GUESSINGROWS=50;
RUN;
data max_score_date;
set drive.results_from_R (drop= VAR1 rename=(VAR2=customer_id));
max_score = max(var3,var4,var5,var6,var7,var8,var9,var10,var11);
format forecast_date yymmdd10.;
select (max_score);
when (var3) forecast_date = '01APR2011'd;
when (var4) forecast_date = '02APR2011'd;
when (var5) forecast_date = '03APR2011'd;
when (var6) forecast_date = '04APR2011'd;
when (var7) forecast_date = '05APR2011'd;
when (var8) forecast_date = '06APR2011'd;
when (var9) forecast_date = '07APR2011'd;
when (var10) forecast_date = '08APR2011'd;
when (var11) forecast_date = '09APR2011'd;
otherwise forecast_date = "Error";
end;
run;
*repeating spend GBM max score;
Data drive.final_sumbission (keep= customer_id visit_date visit_spend);
merge drive.test_forecast_spend
max_score_date
(keep=customer_id forecast_date firstobs=99953);
by customer_id;
format visit_date mmddyy10.;
visit_date = forecast_date;
select (weekday(visit_date));
when (1) do;
if modal_range_1 = . or
visit_num_entire_1 lt 15 then
visit_spend = modal_range;
else visit_spend = modal_range_1;
end;
when (2) do;
if modal_range_2 = . or
visit_num_entire_2 lt 17 then
visit_spend = modal_range;
else visit_spend = modal_range_2;
end;
when (3) do;
if modal_range_3 = . or
visit_num_entire_3 lt 22 then
visit_spend = modal_range;
else visit_spend = modal_range_3;
end;
when (4) do;
if modal_range_4 = . or
visit_num_entire_4 lt 19 then
visit_spend = modal_range;
else visit_spend = modal_range_4;
end;
when (5) do;
if modal_range_5 = . or
visit_num_entire_5 lt 16 then
visit_spend = modal_range;
else visit_spend = modal_range_5;
end;
when (6) do;
if modal_range_6 = . or
visit_num_entire_6 lt 26 then
visit_spend = modal_range;
else visit_spend = modal_range_6;
end;
when (7) do;
if modal_range_7 = . or
visit_num_entire_7 lt 21 then
visit_spend = modal_range;
else visit_spend = modal_range_7;
end;
Otherwise visit_spend = modal_range;
end;
run;
*Output CSV file for R;
proc export data = drive.final_sumbission
outfile =
'C:\Dunnhumby\Winning Submission\winning_submission.csv'
DBMS = csv replace;
run;