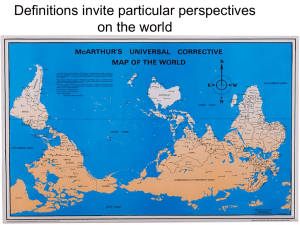
- Sacramento
advertisement

DIFFERENTIAL ITEM FUNCTIONING AND ADVERSE IMPACT: A COMPARISON OF MANTEL-HAENZSEL AND LOGISTIC REGRESSION Heather JoAn Whiteman B.A., University of California, Davis 2006 THESIS Submitted in partial satisfaction of the requirements for the degree of MASTER OF ARTS in PSYCHOLOGY (Industrial/Organizational Psychology) at CALIFORNIA STATE UNIVERSITY, SACRAMENTO SPRING 2011 DIFFERENTIAL ITEM FUNCTIONING AND ADVERSE IMPACT: A COMPARISON OF MANTEL-HAENZSEL AND LOGISTIC REGRESSION A THESIS by Heather JoAn Whiteman Approved by: ____________________________, Committee Chair Lawrence S. Meyers, PhD. ____________________________, Second Reader Lee Berrigan, PhD. ____________________________, Third Reader James E. Kuthy, PhD. Date: _______________________ ii Student: Heather JoAn Whiteman I certify that this student has met the requirements for format contained in the University format manual, and that this thesis is suitable for shelving in the Library and credit is to be awarded for the thesis. ___________________________________________ Jianjian Qin, PhD., Graduate Coordinator Department of Psychology iii ________________ Date Abstract of DIFFERENTIAL ITEM FUNCTIONING AND ADVERSE IMPACT: A COMPARISON OF MANTEL-HAENZSEL AND LOGISTIC REGRESSION by Heather JoAn Whiteman This study serves as a comparative analysis of two measures for detecting differential item functioning (DIF) in item responses of 29,171 applicants on a 49 item selection test. The methods compared in this study were two of the more commonly used DIF detection procedures in the testing arena: the Mantel-Haenszel chi-square and the logistic regression procedure. The study focused on the overall effect each method had on adverse impact when used for the removal of items from a test. The study found that the presence of adverse impact findings were decreased by the removal of items displaying DIF, and that the effect on adverse impact differed by method of DIF detection. The study does not however, provide enough evidence to support the use of one DIF detection method over the other in applied settings where considerations such as cost and test reliability are of concern. ____________________________, Committee Chair Lawrence S. Meyers, PhD. iv ACKNOWLEDGMENTS I would first like to thank Biddle Consulting Group, Inc. the equal employment opportunity, affirmative action, and employee selection firm in the western United States that allowed me to use their data. I would like to thank all of the professors in the Industrial/Organizational Psychology program who have influenced me. I would particularly like to thank Dr. Meyers, Dr. Kuthy, and Dr. Berrigan who served on my committee and who assisted in guiding me through the thesis process. I would like to especially appreciate and thank Dr. Meyers for the time he took in giving me advice on the thesis and the enthusiasm and exceptional teaching he offered in his courses. I attribute the bulk of my learning in Industrial/Organizational Psychology to Dr. Meyers and the courses that he taught. I would like to thank Dr. Kuthy for serving as a professional role model and instilling in me a knowledge and respect for the applied Industrial/Organizational field. I would like to thank Dr. Berrigan for his dedication to the students and his willingness to contribute to my thesis. I would also like to thank my parents, Randy and Carrie, who have always been supportive of my goals. I would also like to thank my friends and colleagues who have provided support, input and camaraderie. v TABLE OF CONTENTS Page Acknowledgments ……………………………………………………………………….. v List of Tables ………………………………………………………………………….... ix List of Figures …………………………………………………………………………... xi Chapter 1. INTRODUCTION .…………………………………………………………...………. 1 Early History of Selection Testing ………………………………………...…….. 1 Setting Legal Precedent for Fairness in Selection Testing …………………...…. 4 Setting the Standards for Fairness in Selection Procedures …………………...… 7 Adverse Impact ………………………………………………………...………... 9 Validity in Selection Procedures ………………………………...……………... 13 Evidence based on test content ……………………………………….... 14 Evidence based on relation of a test to other variables ……………….... 16 Evidence based on response processes ……………………………….... 19 Evidence based on internal structure of a test ………………………….. 20 Evidence based on consequences of testing ……………………………. 22 Validity and Reliability ……………………………………...…………………. 22 Differential Item Functioning ………………………………………...………... 26 Differential Item Functioning and Item Bias ……..……………………. 26 Measuring Differential Item Functioning ……………………………… 29 Ability Measures in DIF Analyses …………………………………....... 30 vi Factors Affecting DIF Detection …………………………………….… 33 Uniform/Non-Uniform DIF ……………………………………………. 34 DIF Detection Methods ………………………………………………………… 36 Mantel-Haenszel ……………………………………………………….. 36 Logistic Regression …………………………………………………….. 41 DIF Detection Method Comparisons ……………………….………...... 44 Purpose of the Study …………………………………………………..…………. 46 2. METHOD .…………………………………………………………………...…….... 48 Sample Description ………………………………...………………………...… 48 Instrument ……………………………………………………...………………. 48 Procedure ………………………………………………………………...…….. 50 DIF Analysis for Item Removal ……………………………………...… 50 Adverse Impact Analyses …………………………………………….... 54 3. RESULTS ……………………………………………………………………...……. 56 DIF and Item Removal …………………………………………………...…….. 56 Mantel-Haenszel Analyses ……………...……………………………… 56 Logistic Regression Analyses ……………..…………………………… 61 Comparison of the MH and LR Methods for DIF Detection and Item Removal ……………………………………………………….….. 64 Adverse Impact Analyses ……………………………………………...…….… 70 Original Test 80% Rule Adverse Impact Analyses ……………………. 72 MH Test 80% Rule Adverse Impact Analyses ………………………… 74 vii LR Test 80% Rule Adverse Impact Analyses ………………………..… 77 Comparison of 80% Rule Adverse Impact Analyses …………………... 78 4. DISCUSSION ………………………………………………………………...…...… 86 Findings & Conclusions ……….……………………………………………..… 86 Limitations …………………………………………………………………...… 89 Implications for Future Studies ………………………………………………… 91 Appendices …………………………………………………………………................... 93 Appendix A. Item Means and Standard Deviations ……………………………..…...... 94 Appendix B. MH DIF Values and Classification Level by Item ……………..…..……. 96 Appendix C. Nagelkerke R2 Values and DIF Classification Category by Item …....… 106 Appendix D. Number of Applicants Passing at Cut-off Score Level by Test and Comparison Group …………………………………….…………...… 120 Appendix E. Fisher’s Exact Statistical Significance Results of Adverse Impact by Test & Comparison Group ...…………………………………………... 125 References ……………………………………………………………………..……… 130 viii LIST OF TABLES Page 1. Table 1 Demographic Characteristics of Examinees ………..……………….… 49 2. Table 2 Descriptive Statistics of Examinee Test Scores .………………………. 50 3. Table 3 MH Method DIF Classifications by Reference Group ……………...… 57 4. Table 4 MH Method DIF Classification by Item Number ………..………….… 59 5. Table 5 Item Numbers Displaying Small or No DIF with the MH Method …… 60 6. Table 6 Descriptive Statistics of the MH Test Scores ….……………………… 60 7. Table 7 LR Method DIF Classification by Reference Group ………..………… 62 8. Table 8 LR Method DIF Classification by Item Number ………..…………..… 62 9. Table 9 Item Numbers Displaying Small or No DIF with the LR Method ….… 63 10. Table 10 Descriptive Statistics of LR Test Scores ……………..……….……… 64 11. Table 11 MH & LR DIF Classifications by Item Number ………..…………… 69 12. Table 12 Descriptive Statistics of the Original, MH and LR Test Scores …...… 70 13. Table 13 Number of 80% Rule Violations and Practically Significant 80% Rule Violations in the Original Test by Comparison Groups ………………..… 73 14. Table 14 Number of 80% Rule Violations and Practically Significant 80% Rule Violations in the Original Test by Cut-off Score Levels ...……………..… 75 15. Table 15 Number of 80% Rule Violations and Practically Significant 80% Rule Violations in the MH Test by Comparison Groups …………………….… 76 16. Table 16 Number of 80% Rule Violations and Practically Significant 80% Rule Violations in the MH Test by Cut-off Score Levels ..………………….… 77 ix 17. Table 17 Number of 80% Rule Violations and Practically Significant 80% Rule Violations in the LR Test by Comparison Groups ..…………………...… 79 18. Table 18 Number of 80% Rule Violations and Practically Significant 80% Rule Violations in the LR Test by Cut-off Score Levels ..…………………….. 80 x LIST OF FIGURES Page 1. Figure 1 Uniform DIF ………………………………………………………….. 35 2. Figure 2 Non-uniform DIF ……………………………………………………... 36 3. Figure 3 MH Contingency Table Example …………………………………….. 37 4. Figure 4 DIF Assessment Classifications …………………………………….... 67 5. Figure 5 80% Rule Violations by Test ………………………………………… 81 6. Figure 6 80% Rule Violations by Comparison Group ………………………… 82 7. Figure 7 Practically Significant 80% Rule Violations by Comparison Group … 83 8. Figure 8 80% Rule Violations by Percent Cut-off Score Level ……………..…. 84 9. Figure 9 Practically Significant 80% Rule Violations by Percent Cut-off Score Level ..…………………………………………………………………… 85 xi 1 Chapter 1 INTRODUCTION Early History of Selection Testing The origins of testing for filling occupational roles began in 210 BC with the Chinese Civil Service System (Goodwin, 1997). When a new dynasty began in China, it was often a result of a militaristic takeover. A new emperor would come into power and require a large body of new civil service workers to run the empire. For this reason, a system was developed to appoint individuals into civil service positions based on merit rather than family or personal connections. The Civil Service Examination became one way to select a set of men to fill necessary bureaucratic positions and was first instituted around the sixth century. While these exams were intensely trained for and taken by many, very few individuals actually passed; in fact, there is evidence to suggest that the failure of these examinations created many hardships for the individual and sometimes even resulted in suicide. Those that did pass the exams rose in both the financial and social ranks, as did all the members of their family. So, while these tests may have been a good first attempt at a meritocracy, they too had shortfalls in their almost unattainable status (a passing rate supposedly around 2%) and in the way whole families and clans would be elevated by the achievement of one relative (“Confucianism,” n.d., para. 5). Early America also required reform in its appointment systems. A change of President typically resulted in a spoils system, which rewarded individuals who supported the new political party by appointing them to public offices. Unfortunately, due to the 1 2 nature of the spoils appointment system many people who were in political offices did not have the competence to fulfill their job duties. As the government grew even larger there was a clear need for reform in the political system (Heineman, et al., 1995). When Ulysses S. Grant was president (1869-1877), there was such a need for a civil service system that in 1871 Congress allowed for the setting of regulations for admission to public service and for the appointment of a Civil Service Commission. Soon after its creation, the Civil Service Commission ceased to be funded by Congress and was dismantled in 1875. Despite the Civil Service Commission’s short existence, it proved itself to be a functional tool for appointing individuals to public offices based on merit. Republican Rutherford B. Hayes was a major proponent of reform in this area and when he became president (1877-1881) he used competitive examinations for all public office appointments. Hayes worked with Democrat George H. Pendleton to recreate the Civil Service Commission in hopes that a value-based process would become part of both political parties. While the Civil Service Commission did not get far during Hayes’ presidency, there was an outcry for civil service reform after President James A. Garfield was assassinated in the first year of his term, 1881. His life was taken by a disgruntled officeseeker who was denied a political office but felt he was entitled to it based on the spoils system (Manley, 1986). The death of President Garfield, along with the need for more specialized skills and knowledge in government jobs, helped spur the passage of the Pendleton Act (Milkovich & Wigdor, 1991). Introduced by George H. Pendleton, the act rendered it unlawful to use the spoils system. Helped by President Chester Arthur (18812 3 1885), the bill became the Civil Service Act of 1883 and re-established the Civil Service Commission. Under the act, the government is required to appoint people into positions based on their merit as judged by official Civil Service Examinations. The Act ensured that certain aspects of proper testing should be enforced, such as validity and fairness in accessibility. It also stipulated that Civil Service Examinations need to be practical and related to matters that fairly test the capacity and fitness of a person for a position and that the exams must be given in a location that would be “reasonably convenient and inexpensive for applicants to attend” (Civil Service Act, 1883). It specified that no person in a current office could be promoted to another without first having passed the Civil Service Examination. It even addressed issues of substance abuse by stating that “no person habitually using intoxicating beverages to excess shall be appointed to, or retained in, any office…” (Section 8). The Pendleton Act further hindered any form of patronage by stating that no more than two family members could be appointed to positions covered under its constitution. It eliminated the potential for Congress members to influence the appointment of individuals to federal offices by negating their recommendation through examination. The Act also prohibited the soliciting of campaign donations on Federal government property (Civil Service Act, 1883). While the Pendleton Act may have been the placemark for the end of the spoils system in America, the law only applied to federal jobs and it was not mandated to be used for appointment into state and local offices. One result of the Civil Service Act of 1883 was that public offices were being held by individuals with more expertise and less political clout. The Pendleton Act served to push America toward a meritocracy in its 3 4 selection of employees (Milkovich, 1991); however, it fell short of creating a true nondiscriminatory standard for selection processes in the workforce. For example, women were not allowed to sit for these early examinations and, as a result, were not able to gain a public office. The tests were still only plausible for those individuals who had the privileges of an education and the means to afford the trip or days away from work to take such a test. Setting Legal Precedent for Fairness in Selection Testing The issues of validity and test fairness for the selection of employees went unaddressed until the Civil Rights Act of 1964 and its emphasis on equal employment opportunity in Title VII. The Civil Rights Act of 1964 was written under the Presidency of John F. Kennedy (1961-1963) in 1963 but was not passed until shortly after his assassination. President Kennedy had been a leader in the civil rights movement and his successor, President Lyndon B. Johnson (1963-1969), continued with the legacy. In his first address to the nation he said, “the ideas and the ideals which [Kennedy] so nobly represented must and will be translated into effective action.” On July 2, 1964 President Johnson signed the Civil Rights Act into law among political guests including Martin Luther King, Jr. While the Civil Rights Act of 1964 is most popularly known for the racial desegregation of schools and public places, it also specifically applied to fair employment practices. Title VII of the Civil Rights Act of 1964 prohibits the discrimination of an individual from employment or other personnel transactions based on race, color, religion, sex, or national origin (Civil Rights Act of 1964, Sec. 703). When the Civil Rights Act was in its early draft stage, the category of sex was not included. 4 5 However, a powerful democrat, Howard W. Smith, who was against the Civil Rights Act, added it in an attempt to lessen the desirability and ultimately the passing of the bill. Despite this, the Civil Rights Act passed in congress and Title VII became applicable on the basis of sex discrimination as well (Freeman, 1991). Title VII also prohibits the discrimination of individuals who associate with persons of a particular race, color, religion, sex, or national origin, and ensures that no employee can be fired for making a claim of discrimination (Civil Rights Act of 1964, Sec. 703). Title VII coined the term protected class, which is used to define groups of people who are protected from discrimination in employment situations based on personal characteristics. The protected classes labeled within the 1964 act included only the personal characteristics of race, color, religion, sex, and national origin. Age was added as a protected class in the Age Discrimination in Employment Act (ADEA) of 1967 to stipulate that employment discrimination of individuals based on age is unlawful (Age Discrimination in Employment Act of 1967, Sec. 623). The categories of age are divided at forty years of age; individuals at or above the age of forty represent one class, while those below the age of forty represent another. The Equal Employment Opportunity Commission (EEOC) was created to implement the laws set forth by Title VII of the Civil Rights Act of 1964. The United States Government Manual, published and updated annually by the Federal Government since 1935, defines the EEOC’s role as one that enforces laws prohibiting discrimination based on race, color, religion, sex, national origin, disability, or age in hiring, promoting, firing, setting wages, testing, training, apprenticeship and all other terms and conditions 5 6 of employment (U.S. Government Manual, 2005-2006). In 1966 this agency published the EEOC Guidelines which provided a basic description of what constituted a valid selection procedure. Validity, as it will be discussed here and more thoroughly described below, is concerned with the evaluation of a test or measurement. In fact, where testing is concerned, validity is the most fundamental consideration when developing and evaluating a test. Without it you cannot support the interpretation of test scores nor use the test fairly for legitimate decision making purposes. Despite Title VII of the Civil Rights Act and the creation of the EEOC, there was not much attention placed on the assessment of selection procedure fairness until the court case of Griggs v. Duke Power Co., 401 U.S. 424 (1971). In this case there was a unanimous agreement of eight Supreme Court justices that the selection procedures employed by the Duke Power Company were invalid because they did not directly comply with a key aspect listed in the EEOC Guidelines of 1966: the selection procedures did not demonstrate job relatedness. The court determined that the practice of requiring a high school diploma for supervisory positions in the Duke Power Company was a deliberate attempt on the part of the Duke management to prevent the promotion of African American employees. Since the knowledge, skills, and abilities (KSAs) required for the completion of high school did not directly relate to those required to perform supervisory duties at Duke, the power company was forced to change its selection practices and pay restitution to employees who had suffered as a results of these practices (Guion, 1998). The Griggs v. Duke Power Co. case was a strong impetus for explicating what constitutes a violation of Title VII of the Civil Rights Act and for defining the 6 7 various aspects of the field revolving around selection tests and potential discrimination as a result of their use. Setting the Standards for Fairness in Selection Procedures About a decade following the Griggs v. Duke Power Co. case, a joint effort was attempted by the EEOC, the Civil Service Commission (CSC), the Department of Labor (DOL), and the Department of Justice (DOJ) to publish a single set of principles to address issues pertaining to the use of tests, selection procedures and other employment decisions. This set of principles was published in 1978 as the Uniform Guidelines on Employee Selection Procedures (Guidelines). The Guidelines were designed to assist employers, licensing and certification boards, labor organizations, and employment agencies in complying with the requirements of the federal law which prohibits employment practices that discriminate on grounds of race, color, religion, sex, and national origin (Guidelines, 1978). Federal agencies have adopted the Guidelines to provide a uniform set of principles governing use of employee selection procedures which are consistent with applicable legal standards and validation standards that are generally accepted by the psychological profession and which the Government will apply in the discharge of its responsibilities (Guidelines, 1978). The Guidelines continue to serve as a respected source of guidance for employers in regard to compliance with Title VII in employment processes; however, there have been more recent publications developed to serve as more exhaustive sources of reference for establishing selection procedure fairness. One of these publications is the Standards for Educational and Psychological Testing (Standards). The Standards were developed 7 8 by the American Educational Research Association, American Psychological Association and the National Council on Measurement Education in 1985 to explicate the standards which should be followed in the development, fairness and use of all tests. The Standards were revised in 1999 to provide more information for employers’ use in adhering to the laws and regulations set forth in Title VII of the Civil Rights Act of 1964 (Standards, 1999). A third set of guidelines currently in use are the Principles for the Validation and Use of Personnel Selection Procedures (2003) (Principles). These principles were originally published by Division 14 of the American Psychological Association (the Society for Industrial and Organizational Psychology, or SIOP) in 1975 and most recently updated in 2003. The Principles are not an alternative set of guidelines to the Standards, but instead are intended to be complementary to them with more precise application to employment practices. “The Principles are not meant to be at variance with the Standards for Educational and Psychological Tests (APA, 1974). However, the Standards were written for measurement problems in general while the Principles are addressed to the specific problems of decision making in the areas of employee selection, placement, promotions, etc.” (Principles, 2003, p. 2). The major distinction among these three sets of guidelines is their purpose of application. The Guidelines were developed primarily for evaluating testing practices in light of Title VII [of the Civil Rights Act of 1964] (Biddle & Noreen, 2006). The Principles even go so far as to directly state that their guidance is not necessarily 8 9 intended to parallel legal standards: “Federal, state, and local statutes, regulations, and case law regarding employment decisions exist. The Principles is not intended to interpret these statutes, regulations, and case law, but can inform decision making related to them” (Principles, p. 1). The Standards and the Principles serve as a much needed set of resources that are more explicit in the practices governing fair and valid selection procedures. Adverse Impact Neither the Standards nor the Principles discuss the technical determination of disparate impact because it is a legal term (Biddle & Noreen, 2006). The Guidelines, however, are intended to provide guidance around employee selection processes in light of the Title VII legal requirements; as a result they are predominately focused on addressing the issue of adverse impact and disparate treatment in employment settings. The Guidelines define adverse impact as a “substantially different rate of selection in hiring, promotion, or other employment decision which works to the disadvantage of members of a race, sex, or ethnic group” (Guidelines, Sec. 16B). In order to determine whether there is a substantially different rate of selection, the Guidelines provide the 80% rule (Guidelines, Sec. 4D), a heuristic for determining whether adverse impact may exist. In order to assess whether a violation of this rule has occurred, the passing rate of the focal group is divided by the passing rate of the reference group. If the passing rate of the focal group is not at least 80% of the passing rate of the reference group, then the 80% rule has been violated and there is evidence of adverse impact (Guion, 1998). The group of interest, the focal group, is the group with the lower passing rate and is generally 9 10 compromised of individuals of a minority or protected class (e.g., females or minority ethnicities). The reference group is the group with the higher passing rate and is generally comprised of the non-minority or unprotected class (e.g., males or Caucasians). An example of the 80% rule is generally helpful in understanding its use in selection procedures. Example: A selection procedure has 200 applicants who must pass a test in order to be considered for employment, 100 of the applicants are focal group members and 100 are reference group members. If 55 focal group individuals pass the test (a passing rate of 55%) and 80 reference group individuals pass the test (a passing rate of 80%) the ratio of passing rates would be 55:80. This ratio is equivalent to a percentage difference of .69; thus indicating that the passing rate of the focal group is 69% of the passing rate of the reference group. This value indicates a violation of the 80% rule and is evidence of adverse impact against the focal group. A problem with the 80% rule is that it is easily affected by small numbers; when the group sizes are small, the ratio can change drastically just by the passing/failing of one individual. For example, if there were two groups, each with only 4 individuals, and the passing rate of the reference group was 100% there would be evidence of adverse impact against the focal group if even just one person did not pass. This would create an erroneous message of adverse impact if the 80% rule was used as the sole determiner of adverse impact. There are also times when the 80% rule is not violated but there is still a presence of adverse impact in the test. The Guidelines explicitly address just such an occurrence and also name alternative methods for assessing adverse impact: 10 11 …smaller differences in selection rates may nevertheless constitute adverse impact, where they are significant in both statistical and practical terms or where a user’s actions have discouraged applicants disproportionately on grounds of race, sex, or ethnic group (Guidelines, 1978, Sec. 4D). The processes mentioned for detecting adverse impact, a statistical test of differences between the groups and an assessment of practical significance can be used in lieu of, or in addition to, the use of the 80% rule. The process of assessing statistical significance between two groups is generally done with a statistical software program and utilizes a “Fisher Exact” procedure to determine when the difference is as large as or larger than one that could be likely due to chance (Guion, 1998). The measure of whether or not a difference is due to chance is computed as a p value and can also be called a probability. A p value below .05 has less than a 5% probability of having occurred by chance (Meyers & Hunley, 2008). A value below 05 is generally accepted by the courts, Guidelines, and professional standards as the threshold for indicating adverse impact (Biddle & Noreen, 2006). While .05 has become the standard level for determining statistical significance, the value comes from a somewhat arbitrary determination when Irving Fisher published tables (Fisher, 1926, 1955) that labeled values below .05 as statistically significant. A comment in a textbook by Keppel & Wickens (2004) beg the questions: Why do researchers evaluate… an unvarying significance level of 5 percent? Certainly some results are interesting and important that miss this arbitrary criterion. Should not a researcher 11 12 reserve judgment on a result for which p = .06, rather than turning his or her back on it? (Keppel & Wickens, 2004, p. 45). The courts have also contended that significance criteria "must not be interpreted or applied so rigidly as to cease functioning as a guide and become an absolute mandate or proscription" (Albemarle Paper Company v. Moody, 1975). According to Biddle (2006), values below .05 are “statistically significant,” and values between .05 and .10 can be considered “close” to significance. The second process that was addressed by the Guidelines for the assessment of adverse impact, practical significance, is an assessment that can be used in conjunction with the 80% rule and the statistical significance tests. Practical significance is evaluated by hypothetically changing the passing status of a couple individuals in the adversely affected group to a passing status from failing status. Practical significance is useful for counteracting the potential problems associated with tests that are easily affected by sample sizes, such as the 80% rule and statistical tests of significance. If a finding of adverse impact is no longer statistically significant or there is no longer a violation of the 80% rule after hypothetically changing the passing status, then the results of the statistical significance and/or 80% rule tests are likely instable and should not be seen as concrete evidence of adverse impact. According to Biddle & Noreen (2006), some courts assessing legal cases of adverse impact give consideration to whether the adverse impact seen in a test is also practically significant before determining the presence of adverse impact. Practical significance is only a necessary assessment when there is a finding of adverse impact. A test can possess statistically and practically 12 13 significant adverse impact, statistically significant but not practically significant adverse impact, or neither statistically or practically significant adverse impact. Validity in Selection Procedures When adverse impact is found, test developers and users should evaluate if the test is unsuitable for selection purposes; however, the Guidelines state that adverse impact does not render a test unsuitable when there is sufficient validity evidence to support the test or procedure and there are no other reasonable alternative measures of selection available. This is because the overall validity of the test should be the most important aspect when considering whether it is appropriate for use in a selection process. Adverse impact should be avoided if at all possible, however, where a test is a valid predictor for successful performance in a job, it should be used in order to ensure that the candidate with the best abilities in the tasks, knowledge or skills needed for the position is selected. There are not clear legal expectations around the interaction of adverse impact and test validity, in fact, the Guidelines do not require a test user to conduct validity studies of selection procedures where no adverse impact occurs. However, all test users are encouraged to use selection procedures which are valid, especially users operating under merit principles (Guion, 1998). Guion (1998) defines validity as the effectiveness of test use in predicting a criterion measuring something else and valued in its own right, meaning that a valid test is one that can effectively predict the desired performance, skill or attribute of interest. Perfect assessment of an individual is not possible, therefore, we use tests as an approximation for a persons’ true ability in one area and then infer something about the 13 14 individual from their score. The Standards state that validity references the degree to which evidence and theory support the interpretations of test scores entailed by the proposed uses of a test. Validity therefore is a measure which indicates the accuracy of a test. A test that is valid would be capable of fully assessing all of the traits it was designed to measure without also capturing extraneous traits that were not intended for inclusion in the assessment. A test is only considered valid for its specific purpose and context. Because validity refers to an inference which is drawn from a test score, the Standards intimate that tests capable of drawing successful inferences are to be considered valid. Conversely, a test with low validity would not be able to successfully draw inferences based on test results. The Standards outline five sources of validity evidence used in evaluating the proposed interpretations of test scores for specific purposes. These sources of validity evidence include: 1) evidence based on test content, 2) evidence based on the relation of a test to other variables, 3) evidence based on response processes, 4) evidence based on internal structure, and 5) evidence based on the consequences of testing. While not all of these five sources are necessary to validate a test, the most important types of evidence to determine validity will depend on the individual test and the legal context that may or may not be present when adverse impact is concerned. Evidence Based on Test Content The first source listed by the Standards, evidence based on test content, assesses the relationship between the content of the test and the domain that it is intended to measure. In a test designed to measure an applicant’s knowledge in the field for which 14 15 they are applying, one would expect some basic things: 1) that the content of the test is related to the topic area of the position, 2) that the test covers a broad range of topics relevant to the position, neither focusing too heavily on, or omitting any topic areas, and 3) that the test includes only items directly related to the position. Validity evidence based on content is unique because it can be determined through pure logical determination (Standards, 1999); there is no required statistical procedure or mathematical computation undertaken to determine content validity (though metrics are often used to quantify and simplify the process). A job analysis is a commonly performed method to determine validity evidence based on content. A job analysis serves to identify the tasks that are performed on a job and to link them to the skills, abilities and knowledge that are required for successful performance of the job. This analysis is done with the use of subject matter experts who are familiar with the job and can determine the relevance of the skills, abilities, or knowledge to the actual tasks performed on the job. In order to show content validity evidence, items on a test must be clearly linked to those tasks identified in the job analysis as critical or important to the successful performance of an individual on the job. Content validity evidence should also address the design of the test. A question that is unnecessarily difficult, intended to “trick” people, or poorly worded would not be valid for inclusion on a selection test even if it is was appropriately related to the job content. In the case of selection tests, the difficulty of the test should be related to the difficulty of the job. For example, if a test is designed for an entry level position but requires the use of expert skill levels, the test would not be a valid measure for assessing 15 16 a job of entry level skills. If the domain being assessed is comprised of many traits, a valid test would seek to measure all of those traits and none which do not exist in the given domain. Evidence Based on Relation of a Test to Other Variables The second source for validity evidence according to the Standards can be obtained by assessing the relationship of test scores to external variables. This form of validity evidence encompasses two traditionally held views of validity, criterion and construct validity. Criterion validity for a selection test concerns the ability of the test to predict a test taker’s performance in the job based off of the test results. Criterion validity is established through a mathematical study in which statistically significant results ‘prove’ that the test predicts job performance. There are two forms of criterion validity, predictive and concurrent. In concurrent studies, data on the criterion variable are collected at about the same time as the predictors, whereas predictive studies consist of criterion data collected some time after the predictor variables have been measured (Standards, 1999). Predictive criterion validity can be assessed by administering a test to individuals and then comparing their performance on the test to later obtained measures of performance. For example, colleges and universities in the U.S. demonstrate the validity evidence of their use of standardized aptitude test scores in admissions processes because the tests have been shown to predict the first year of an undergraduate’s success in terms of grade point average. Concurrent criterion validity can be determined by comparing the outcome of an individual’s score to a current measure of ability. For 16 17 example, a company may administer a test they believe will assess an individual’s ability to perform well in a particular position to current employees in those positions. If individuals who perform well in the position currently also perform well on the test (and individuals who are poor performers on the job are also poor performers on the test), then this would demonstrate validity evidence based on the relation of the test to a concurrent measure of job performance. Construct validity differs from criterion related validity by its relation to theoretical constructs which are thought to underlie behaviors such as performance, knowledge, or ability. Obtaining an adequate amount of empirical evidence underlying a particular construct is usually a difficult task to undertake, especially if the test is specific to a unique construct. In some cases there are already measures in place to assess the job related aspects of interest for a test. For example, a test assessing an individual’s degree of depression should significantly correlate to a scale such as the Beck Depression Inventory. When using external variables as a source for construct validity evidence one can look at both convergent and divergent evidence. Convergent evidence refers to the relationship between test scores and other measures assessing related constructs, such as described in the previous example. Divergent evidence refers to a lack of relationship between test scores and measures of constructs which should be unrelated to the test construct. For example, a test assessing an individual’s degree of social desirability should not significantly correlate to the Ray Directiveness Scale since research provides evidence for little or no relationship between these two constructs (Ray, 1979). These 17 18 convergent and divergent relationships between the test and other variables can be established by use of correlations or other statistical procedures (Standards, 1999). The uses of criterion and construct validity are only two of the ways that evidence for validity of a test can be found based on its relationship to other variables. Another process through which the Standards advocate gaining validity evidence based on relation of a test to other variables is validity generalization. Validity generalization concerns the use of a test in contexts other than the one for which it was first designed. A tests’ applicability in a new context can be ascertained through different procedures; however, the most commonly used process for obtaining this form of validity evidence is through a meta-analytic study. A meta-analytic study is performed by studying literature and research results concerning the tests’ use in other contexts. A good example is the literature available concerning the wide applicability of the SAT to many different academic contexts. There is a large amount of data available concerning the ability of the SAT, a standardized test of reading, writing, and math skills, to predict a college freshman’s GPA in their first year. A meta-analysis of these studies would indicate that this prediction of GPA by SAT scores is stable across many different universities. As such, a university wanting to use the SAT for admissions would have demonstrable evidence of validity generalization for the use of this test for admissions purposes. Synthetic validity is another way in which a test can have validity evidence based on a relationship to other variables. A test that is comprised of parts of other tests is said to be a synthesized test. If an employer wanted to hire recruiters for their company, they may wish to assess a prospective recruiter in many different ways. Suppose the company 18 19 already had a valid test for predicting performance in this position but they have come to realize that extroversion is also a good predictor for success in this position. Rather than design a whole new test, the company could synthesize together their previous test and part of a psychological inventory that assesses extraversion for a more accurate predictor of a successful employee in the recruiter job position. Under the concept of synthetic validity, if they use an already established and validated procedure to measure extroversion, the new selection process would not need to be assessed again in terms of validity. The caveats related to the use of validity evidence obtained from a tests relation to other variables should be taken into consideration, such as the large degree of error variance that external criterion variables often contain. For example, if using performance appraisal scores of employees as a measure of concurrent criterion validity evidence, there may be errors in the rating system used, or the results may be skewed since the population of test takers were already proven to perform at least adequately in the position given their current employment in the position. It is important that the other variables being used to gather validity evidence are valid and appropriate measure or constructs. Evidence Based on Response Processes Validity evidence based on response processes focuses on the removal of confounding variables in a test. If a test is given to measure extraversion, such as in the previous example for a recruiter job position, care should be taken so that the test takers’ responses are not based on their knowledge that the employer is looking for an 19 20 extraverted person. Typically this form of evidence comes from the analysis of test takers responses to questions concerning about the process they used while taking the test (Standards, 1999). It is important to note that evidence based on response processes may lead to confounded responses of test takers during the data collection procedure if it is undertaken by the evaluator or administrator of the test. Thus, evidence of the rater’s ability to appropriately collect and evaluate responses to an item on a test in accordance with the intended construct of the test should be ensured (Standards, 1999). Evidence Based on Internal Structure of a Test The fourth type of validity evidence, evidence based on internal structure of a test, assesses the relationships among test items and the criterion they are attempting to measure. The Standards identify two sources of evidence based on internal structure; factor structure and internal consistency. The factor structure of a test is generally determined by running a factor analysis procedure in a statistical program. This procedure identifies patterns of correlation between individual items and the constructs represented in a test. It serves as a method for finding the underlying themes or patterns within items of a test. Factor analysis provides the degree of relationship that exists between test items and test constructs. This allows for the creation of test subscales based on item relationships. For a simplistic example, a factor analysis of an elementary school proficiency exam might show that addition and subtraction items are highly correlated with each other and that grammar and spelling questions are highly correlated with each other. This would indicate the presence of two subscales, a math subscale and a verbal subscale, which could be scored 20 21 and analyzed. By evaluating results based on subscales, a greater inference of an individuals’ true ability can be made. Consider two elementary students who have an average overall score on this example proficiency exam. One student performed at an average level on both the math items and the verbal items. The other student performed exceptionally well on the math items but very poorly on the verbal items. To consider these two example students as equal in terms of proficiency with both math and verbal would be an invalid use of the test results, but by assessing the factor structure it can be identified and corrected. The purpose of the test should be considered when determining whether subscales are necessary or an averaged total test result may be adequate. The second type of validity evidence based on internal structure of a test, internal consistency can be found by assessing aspects of the individual items on a test. Inter-item correlations are one way to determine internal structure based on internal consistency; if two items have a high inter-item correlation they are essentially measuring the same construct, not different a unique aspect of the domain being assessed. Another measure useful to assess internal consistency is item-total correlation. This describes how related an item is to the total test score. If an item-total correlation is high it indicates that individuals who tend to get the item correct also tend to score higher on the test, and visaversa. If an item-total correlation is negative, however, it would indicate that individuals who score high on the test tend to score poorly on that particular item. A negative itemtotal correlation is usually an indicator of a poor item or possibly an improperly keyed item. 21 22 Evidence Based on Consequences of Testing The final type of validity evidence stated in the Standards concerns evidence based on consequences of testing and is inherent in many of the other forms of validity evidence. Zumbo (1999) considers the consequences of test use to be an essential part of validation. This form of evidence is somewhat controversial due to its link with adverse impact. The Standards state that one may have to accept group differences on relevant attributes as real if a test measures those attributes consistently with the proposed interpretation of the test. One of the benefits of validity evidence based on the consequences of testing is that it allows one to be sure in ruling out confounds in a test which might be correlated with group membership (Meyers, 2007). In addition, a distinction must be made between evidence that is directly related to the validity of a test and evidence that may inform decisions about social policy, but falls outside the realm of validity (Standards, 1999). Validity and Reliability Validity is often confused with the concept of reliability. Reliability indicates the precision of a test; it is the extent to which a set of measurements is free from randomerror variance (Guion, 1998). A test on which a person consistently scores similarly would indicate a test that has very little random error and would be considered to have high reliability. A test in which a person first scores very highly and then very poorly would be said to have low reliability because the scores that a person receives seem random. Reliability is important because of its ability to determine whether a valid inference can be made based on a test score. Any test that is being assessed for validity 22 23 should first be found to be reliable. According to Guion (1998), “if a test is not reliable, it cannot have any other merit.” A valid test must be reliable but a reliable test is not always valid. Consistent scoring of individuals on a test does not mean that the test is measuring what it is intended to measure. For example, a bathroom scale may report that a person is 10 pounds lighter than they actually are every time someone stands it. That scale would be reliable; however it is reliably inaccurate as to a persons’ true weight. Reliability has its basis in consistency. The scale is only said to be reliable because it had been used repeatedly and produced similar results. The same is true for any test, a test would have to be administered many times and produce similar scores each of those times. Within classical test theory, reliability is thought of in terms of how close a test can approximate an individual’s “true score.” A true score is the score that an individual would have obtained if measurement was perfect, that is, being able to measure without error. Theoretically, every individual has a true score on any test, but one’s observed score, the score actually received on the test, is usually different from this true score as a result of any number of issues. A person’s true score is affected by problems inherent in the test itself, the test takers’ mood, the test taking environment and any number of social or personal influences. Classical test theory states that the relationship between an individual’s true score and their observed score can be expressed mathematically: X=T+E Where X is the observed score of the individual, T is the true score, and E represents the error in a test (Guion, 1998). Classical test theory also expresses the deviation from a true 23 24 score in reference to the variance inherent in the scores themselves and the error variance. This is expressed mathematically as follows: VO = VT + VE Where VO is the variance of the obtained score, VT is the variance of the true scores, and VE is the error variance. If a test were perfectly reliable, VE = 0, the variance of the observed score would be identical to that of the variance of the true score. A different mathematical representation of the notion of reliability is expressed by the function: Reliability = VT VO This equation presents a ratio of reliability in terms of the variance of the true score that can be found in an observed score from a test. This shows how much of the true score variance is shared with the observed score variance. It also shows how much unique variance the observed score has apart from the true score that would indicate error. The importance of reliability in assessing the validity of a test comes from the effect it has on the relation of the observed score to an individual’s true score. The less reliable a test is the less appropriate assumptions are if based on the test results. A separate notion of reliability concerns the concept of internal consistency. This addresses the likelihood that an individual will respond similarly to all items on a test. It is typically assessed by internal consistency coefficients of items taken from a specific content domain. Analyses are performed on these test items that determine how well they perform as a part of the test. The analysis of items tells how difficult an item is and whether or not the item is capable of discriminating between test takers that have 24 25 different ability levels. This can be determined using item difficulty measures such as Cohen’s d, corrected item-total correlations (the correlation of performance on one item to the performance on the test as a whole) and with item characteristic curves (indicators of the area on which an item has the most power in differentiating between individuals of varying ability). Also, if a test happens to be a multiple choice test, these methods can be used to assess item distractors and determine their role in the test. Internal consistency can be assessed through procedures like split half reliability and the Kuder-Richardson equation. Split half reliability consists of dividing a test into two sets of items, scoring each set of items separately and then looking at the correlation between the two sets of items. If a high correlation was found, then people tended to score similarly across the test and there is likely “functional unity” across the test as a whole (Guion, 1998). It is important when doing split half reliability that certain things are understood. For example, it would be improper to split the test into halves in which the first half of questions were compared to the last half, due to the fact that test takers may be experiencing fatigue and therefore may perform more poorly on test items occurring later in a test. The Kuder-Richardson procedures are internal consistency measures that were developed off of two mathematical equation, the 20th and 21st equation. First developed by Kuder and Richardson in 1937, the equations are useful in determining the reliability of a test which has dichotomously scored items (e.g., true/false, correct/incorrect). The Kuder-Richardson formulas may be considered averages of all the split-half coefficients that would be obtained using all possible ways of dividing the test (Guion, 1998). The problem with both the split half reliability and the 25 26 Kuder-Richardson is that they are only useful for assessing the reliability of a dichotomously scored test. This dilemma was attended to by Cronbach, who developed the more commonly used coefficient alpha in 1951.The coefficient alpha uses a general application of the Kuder-Richardson 20th equation (Guion, 1998) and can be used on any quantitative scoring system whether dichotomous or not. Another classical test theory aspect of reliability concerns the precision of the test itself. Precision can be thought of as the absence of error in a test, and is measured by the standard error of measurement. The standard error of measurement (SEM) is the amount of deviation in the test scores that would be found if an individual took the same test numerous times in the same conditions (and if their memory could be wiped clean so that they would not be affected by previous exposure to the test). Once an SEM is obtained, a confidence interval can be made around the score. A confidence interval is a score range within which we can say with a certain degree of confidence that an individual’s score would fall if they took the test repeatedly. A 95% confidence interval means that if an individual were to take the test 100 times they would score within the range specified 95 out of those 100 times (Meyers, 2007). The range of the interval is also an indicator of precision in a test. For example, on a test with 100 points possible a range between 80 and 85 points is more precise than a range between 75 and 90 points. Differential Item Functioning Differential Item Functioning and Item Bias While there are many different forms of validity evidence of concern when evaluating a test, the focus of this work is to address validity as it concerns the 26 27 consequences of testing through bias at the individual item level. Individual items in a test can be assessed in many ways. One way is to assess the ratio of each group answering the item correctly; this is similar to the way adverse impact is assessed on the test as a whole. If items are scored dichotomously, an average of the number of individuals who answered the item correctly could be compared between groups. This simple comparison of means may seem adequate; however, it does little more than indicate which group tended to answer the item correctly more often. Simple differences between groups can often lead to an assumption of bias; but, there are often very real reasons why two groups may score differently. For example, a test item on art history would likely have more correct responses given by a group of art students than a group of psychology students. This would not be an indicator of bias; it would merely represent a greater ability of the art students to answer questions related to art history. To assume that this item was biased against psychology students and to remove it from the test would be inappropriate since the item was designed to assess an individuals’ knowledge of art history, not to avoid any possible group differences. An item is considered biased when equally able (or proficient) individuals from different groups do not have equal probabilities of answering an item correctly. The key point in distinguishing biased items from simple differences in item response is the inclusion of ability as a consideration. Differential Item Functioning (DIF) is a statistical technique designed to help detect and measure item bias. DIF assesses individual items on a test and indicates if one group of individuals has a different probability of answering correctly, but only after differences in ability between groups have been controlled for. 27 28 DIF is a statistical property of an item while item bias is more general and lies in the interpretation (Wiberg, 2007). DIF is necessary, but not sufficient, for an item to be considered biased; that is, if we do not find DIF then we do not have item bias, but if we do find DIF then it may be item bias or it may be item impact. Item impact refers to the occurrence of test takers from different groups having different probabilities of responding correctly to an item due to true differences in ability measured by the item (Dorans & Holland, 1993). Item impact can be measured through the proportion of test takers passing an item regardless of their total score (Wiberg, 2007). A difference in item responses would be expected when the examinee groups differed in knowledge, experience or interest in the items content. It may not always be clear whether differences in groups that are a result of history or preference should be considered bias or whether they can be legitimately useful in selecting the most appropriate individuals based on test results. In fact it might be impossible to remove all DIF because groups do not have the same life experience (Wiberg, 2007). An item displaying DIF may not necessarily indicate bias; in fact, an item may be fair for one purpose and unfair for a different purpose (Zieky, 2003). The distinction between item bias and simple differences between groups is that item bias is a kind of invalidity that harms one group more than another (Holland & Wainer, 1993). If an item displays DIF, it would only be considered biased if the results of the test put individuals at a disadvantage. For example, an item with DIF on a test used to assess group differences would not be biased, but an item with DIF on a test used for employment 28 29 selection would be biased because it harms the employment opportunities of one group of individuals. Measuring Differential Item Functioning DIF analyses extend beyond a simple comparison of average scores between groups by matching individuals first on ability before comparing rates of correct responses. Because of this, some courts have specifically approved using DIF for the review and refinement of personnel tests (Biddle, 2006). The Standards (1999) also support the use of DIF analyses for assessing the fairness of a test and encourage further assessment of items displaying DIF: When credible research reports that differential item functioning exists across age, gender, racial/ethnic, cultural, disability, and/or linguistic groups in the population of test takers in the content domain measured by the test, test developers should conduct appropriate studies when feasible. Such research should seek to detect and eliminate aspects of test design, content, and format that might bias test scores for particular groups (Standards, 1999, Sec. 7.3). Grouping Individuals in DIF Analyses In the excerpt from the Standards (1999) above there is a listing of some groupings of individuals, i.e., age, gender, racial/ethnic, etc., highlighting the different possible groupings that can be compared and assessed with DIF analyses. In assessing DIF, groups of individuals can be created based on any group characteristic of concern. Typically, DIF studies concern one “focal” group of individuals that the study is 29 30 concerned with and a separate group meant to serve as the “reference” group. In many employment selection environments the groupings tend to center around protected groupings of individuals such as those stated in the Standards excerpt above. Ability Measures in DIF Analyses In order to assess desired groupings of individuals on an item a measure of ability is necessary. Because true ability is unobservable (Scheuneman & Slaughter, 1991) a proxy for ability must be established. Many of the methods used for DIF detection utilize the total test score as a measure of ability in order to assess an individual item. While it may seem circular to base an ability measure on a test that may contain DIF items, it is one of the most appropriate criterion measures available. This is because there is not usually another indicator of ability available to use for differentiating between individuals in two groups. Also, the test itself will inevitably be the most relevant to the item because each item of the test was designed to specifically assess the dimension of interest. While many methods for detecting DIF utilize total test score as a proxy for ability level, it should be noted that there is also another measure of ability that is used for detecting DIF, called a theta value. Theta is an estimated true score based on item response theory (IRT) methods. The theta value used in IRT methods is quite different from the use of ability measures that reflect only the number of items answered correctly on a test since it is based on a systematic relationship, which can be assumed through mathematical functions, between levels of the trait being assessed and the likelihood that the individual will respond in a particular way (Guion, 1998). Despite the differences in 30 31 methodology, IRT true scores are still estimated from performance on the test and hence are not independent estimates of “true” ability” (Scheuneman, 1991). The use of total test score as an appropriate matching criterion is made more stable by the validation process of the test itself. The more validity evidence indicating that a test can provide appropriate inferences based on test scores, the greater its strength as a matching variable. It should be noted that the reliability of a test is also an important factor in regard to the appropriateness of the total test score as a matching variable. This is because, within each group, a reliable and valid test would properly discriminate between those of high ability and those of low ability and do a reasonably satisfactory job of rank ordering individuals on that ability dimension (Scheuneman, 1991). Test length also affects the accuracy of total score as a measure of ability level; the longer the test, the more reliable the total scores (Clauser & Mazor, 1998; Rogers & Swaminathan, 1993). In some instances a further step is taken to ensure that the total test score used for matching is free of questions that may be unfair by removing items with elevated values of DIF before matching individuals (Camilli & Shephard, 1994; Wiberg, 2007; Zieky, 2003). When this sort of approach is used it is important to always include the item being assessed for DIF in the overall test score used for matching (Donoghue, et al., 1993; Dorans & Holland, 1993; Holland & Thayer, 1988; Lewis, 1993; Zwick, 1990). One reason for excluding items with elevated DIF levels before matching individuals is that the percentage of DIF items in a test can reduce the validity of the total test score as the matching variable. According to Jodoin & Gierl (2001), the greater the percentage of 31 32 items with elevated DIF the more likely there will be errors made when identifying items that display DIF. Still, Mazor et. al. (1995) state that a high percentage of DIF items in a test may be indicative of the dimensional complexity of the test rather than bias per se. This is due to the fact that apparent DIF may sometimes be the result of multidimensionality in a test that measures complex, multidimensional skill areas. According to Mazor et. al. (1995) several studies have found high percentages of items exhibiting DIF in well constructed tests. Multidimensionality of a test can trigger the detection of DIF items because when a test assesses many dimensions, the total score, used as a matching variable, is actually a composite score comprised of the abilities of individuals in the many different dimensions. The total score will be affected by the number of items representing each dimension in the test. Consider a verbal aptitude test for example; if there are many items focusing on sentence completion and only a few assessing other dimensions of verbal ability, the total score would reflect an individuals’ ability more appropriately matched on sentence completion since the majority of the total score was based on those items. Consequently, an item assessing comprehension of written text may display DIF because individuals were not well matched on this form of verbal ability. Mazor et al., (1995) found that use of multiple ability measures can be used to correct for the identification of non-DIF items. For example, comprehension items originally identified as DIF may not be identified if individuals are matched on both their sentence completion ability and comprehension ability. When DIF analyses utilize only one ability measure (i.e, total test 32 33 score) the test should be relatively uni-dimensional in order to best assess and detect DIF in individual items. Factors Affecting DIF Detection Just as some items can erroneously display DIF when they are not in fact bias it is also possible for a test with biased items to avoid DIF detection. If the test is measuring an extraneous trait across the test as a whole it will be incidentally measuring an additional domain, knowledge, or skill beyond that which it was intended to measure, but because it assesses it equally on all items no detection of that extraneous trait could be made (Donoghue & Allen, 1993). Another characteristic that affects the detection of DIF in items concerns the sample size. Items are more reliably flagged as displaying DIF when based on large sample sizes (e.g., more than 500 individuals) than on small sample sizes (e.g., less than 100 or so); (Biddle, 2006). The presence or absence of biased items in a test does not constitute evidence of bias or lack of bias in test scores (Scheuneman & Slaughter, 1991). In fact, even when there is a finding of bias it might be contradictory to the Guidelines to remove it if it shows strong validity evidence, unless that validity evidence is stronger in the majority group than in the protected group(s) and/or equal ability individuals from the different groups have different success rates on the item. This is because an item which displays strong validity is likely a good measure of the skill, knowledge, or ability of interest. Removing the item would decrease the overall validity and usefulness of the selection tool. As with valid tests which display adverse impact, there is no clear determining point 33 34 as to when items should be removed from a test based on bias and retained based on validity. An item displaying DIF needs to be evaluated to determine whether it is truly biased based on group membership. While some items can clearly be identified as valid or not, the majority call for judgments to be made on the basis of vague or unspecified criteria (Scheuneman & Slaughter, 1991). To date, a body of research has yet to emerge that all observers can agree demonstrates that the scores of minority examinees are or are not biased. This lack of certainty leaves people free to accept or reject the various findings according to which of these agree with their individual “biases” concerning what they believe to be true. Given that the true ability or skill we are trying to measure is unobservable and that the stakes of testing are so high, this situation is likely to remain unchanged for some time to come (Scheuneman & Slaughter, 1991, p. 13). Uniform/Non-uniform DIF There are two types of DIF, uniform and non-uniform differential item functioning. Uniform differential item functioning occurs when an item on a test affects one group of individuals differently than another evenly across ability levels, e.g., one group of individuals always scores higher on an item than another group. Figure 1 presents an illustration of this concept. 34 35 Performance on an Item Uniform DIF 1.8 1.6 1.4 1.2 1 0.8 0.6 0.4 0.2 0 High Low Group A Group B Ability Level Figure 1. In uniform DIF individuals of different groups score at an equally different level across the range of ability. Non-uniform differential item functioning measures the presence of an interaction between ability level and group membership. For example, test takers low in ability may score higher if they are in group A and lower in group B, while those with moderate ability score comparably on the item and those with a high level of ability may have a greater score on an item if they are a member of group B. In this instance we could say that while group A does not always score better than group B or vice versa, the item functions differently for the two groups. Figure 2 presents a simplified illustration of this concept. 35 36 Non-Uniform DIF (Interaction) Performance on an Item 0.9 0.8 0.7 0.6 0.5 Group A 0.4 Group B 0.3 0.2 0.1 0 Low High Ability Level Figure 2. In non-uniform DIF individuals of different groups do not score at an equally different level across the range of ability. DIF Detection Methods There are many different methodologies for detecting differential item functioning in a test item. This study focuses on two of the more popularly used methods for detecting DIF in test items, the Mantel-Haenszel (MH) method and the logistic regression (LR) method. These methodologies were selected for this study because of their relative ease in use and accessibility in an applied setting. For a detailed review of other methodologies used for assessing DIF, such as the IRT method referenced earlier, consult Holland & Wainer (1993). Mantel-Haenszel The Mantel-Haenszel procedure is widely considered to be one of the most popular and commonly used procedures for detecting DIF (Clauser & Mazor, 1998; 36 37 Dorans & Holland, 1993; Hidalgo & López-Pina, 2004; Mazor, et al., 1995; Wiberg, 2007; Zwick, 1990). Rogers & Swaminathan (1993) indicate that its popularity is likely due to “computational simplicity, ease of implementation, and associated test of statistical significance.” The procedure was first developed by Mantel & Haenszel (1959) in order to control extraneous variables when studying illnesses in populations. It was later proposed as a method for detecting DIF by Holland & Thayer in 1988. The MH procedure is a variation of the chi-square test that assesses the associations between two variables, both of which are dichotomous, for example, correct/incorrect or focal group/reference group. MH is an easy method for detecting possible bias in an item on a test and takes into account ability level by matching groups first on this basis before analyzing them for differences in correct/incorrect item response probabilities. For this reason it falls into the classification of a contingency table method. When detecting DIF with the MH method, multiple 2x2 contingency tables are created, one for each level of ability. Within the tables, the probabilities of individuals from one group correctly/incorrectly responding to an item are compared to the probabilities of individuals from the other group (see Figure 3). Correct Incorrect Probability that members of Group Probability that members of Group A correctly responded to the item A incorrectly responded to the item Probability that members of Group Probability that members of Group B correctly responded to the item B incorrectly responded to the item Group A Group B Figure 3. Example structure of an MH contingency table at one ability level. 37 38 A comparison of probabilities is performed by obtaining the ratio of focal group probabilities to reference group probabilities. These ratios are then averaged across all of the ability levels, with greater weight given to those ratios gathered from larger sample sizes; this is in response to the larger error found in smaller sample sizes. MH is a DIF detection method that typically matches ability by total test score. As such, there can be as many 2x2 tables as there are items in the test. This is called thin matching and it allows for the assessment of every ability level possible based on total test scores. Thin matching is the strategy typically used for MH DIF studies and yields the best results for long tests (40+ items) with adequate sample sizes (1600+ individuals) (Donoghue & Allen, 1993). If, however, one of the table cells lacks individuals from each group (e.g., there are no focal group individuals who scored at one of the ability levels) then it is not analyzed, leading to a loss of data. As a result, thin matching can yield poor results for short tests (5 or 10 items) and/or those with smaller sample sizes (Donoghue & Allen, 1993). To avoid this, grouped ability levels can be created by placing individuals into groups comprised of more than one observed test score, this method is called thick matching. Thick matching has the greatest advantage when the test has a small sample size or when there is little variation in the scores of individuals. This is because less of the data is discarded as a result of an empty cell in one of the ability contingency tables. Thin and thick matching techniques are generally the most commonly used forms of ability matching in MH, however, there are many other methods for matching; see Donoghue & Allen (1993) for a description of other strategies used to match individuals on total test score. 38 39 MH is useful in detecting DIF in dichotomous items and can be extended to polytomously scored items. The MH method can both detect and measure the size of DIF in an item. It cannot, however, be used to identify non-uniform DIF (Wiberg, 2007). It has been suggested that MH can be modified for use in detecting non-uniform DIF (Mazor, et al., 1994), but the appropriateness of such an extension is still questioned (Wiberg, 2007). Because MH is capable of both detecting and measuring the amount of DIF, items can be identified as possessing DIF and can also be classified into levels of DIF based on the amount displayed. The MH produces a statistic based on the odds ratio of the reference and focal groups summed across the many ability levels. The odds ratio is created by summing the numbers of reference group individuals who answered the item correct along with the number of focal group individuals who answered the item incorrectly, this summation is then divided by the total number of individuals at the given score level. This value is then divided by the summation of the number of reference group members who answered the item incorrectly and the number of focal group members who answered the item correctly divided by the total number of individuals at the given score level. This value is then generally used to determine an effect size estimate of the MH procedure; created by performing a linear transformation to create a “delta” metric for use in categorization. The calculation is performed by taking the natural log of the odds ratio multiplied by -2.35. This delta metric, MH D-DIF (Curley & Schmitt, 1993; Wiberg, 2007; Zwick, 1990), is used to indicate item difficulty in the test development process. 39 40 The MH D-DIF measure can range from negative infinity to infinity. A negative MH D-DIF value would indicate that the item displays DIF against the focal group, while a positive value would indicate DIF against the reference group. A MH D-DIF value of zero would indicate lack of DIF in the item. The MH D-DIF metric and a measure of statistical significance can then be used to classify DIF into various levels. The most commonly used categorization method for DIF while using the MH method is one currently in use by the Education Testing Service (ETS). This commonly used classification system labels DIF items as having either Type A, B, or C DIF. Type A DIF is classified as items whose MH D-DIF absolute values are less than 1, this level of DIF is often considered to show negligible differences between the two groups. Type B DIF is classified as those items which have an absolute value between 1 and 1.5 and that are also statistically significant, this level of DIF is considered to show an intermediate or moderate difference between the two groups. Type C DIF is classified as items having an absolute MH D-DIF value above 1.5 and that are also statistically significant, this level of DIF is considered to show a large difference between the two groups (Hidalgo & López-Pina, 2004). Logistic Regression The second method addressed for the detection of DIF in this study is the logistic regression (LR) method. It is a regression model that was first proposed for the detection of DIF by Swaminathan & Rogers (1990). Regression models predict a dependent variable in terms of independent variables; logistic regression is designed to predict a dependent variable that is dichotomous (i.e., correct/incorrect item responses). It can also 40 41 be extended to work with factors that have more than two categories. The LR method differs from MH in many ways; it is a parametric test of DIF and is designed to assess both uniform and non-uniform DIF. The LR method also allows for the use of continuous ability measures, thus it allows for all ability levels (scores on the total test) to be evaluated regardless of whether there are members from both the focal and reference group with that same total test score. With the MH procedure there may be a necessity to group individuals into ability levels, as in thick matching, to prevent data loss when there are no individuals in one of the groups at a particular core level. For this reason some consider the LR method to be more efficient than the matching process undertaken for MH DIF detection (Mazor, et al., 1995). LR assesses DIF in an item by entering the independent variables of the model (total test score and group membership) in a particular order to predict the likelihood of an individual answering an item correctly. The ability level (total test score) is entered first into the regression model. This allows the model to assess how much of the predicted likelihood of answering the item correctly is due to an individuals’ ability on the test as a whole. The second variable (group membership) is then entered into the model in order to assess how much of the individuals’ likelihood of answering an item correctly is related to their group membership above and beyond what would be expected by their ability level. If an individuals’ likelihood of answering the item correctly is significantly affected by their group membership after accounting for differences in ability, then the item is exhibiting DIF. LR is capable of also assessing non-uniform DIF simultaneously with the assessment of uniform DIF. This is done by lastly including into 41 42 the model the interaction of ability and group membership as an independent variable. If there is a significant interaction effect, indicating that groups perform differently at different levels of ability, then that item is displaying non-uniform DIF. The LR method is used for the study of DIF in preference to other regression methods because test items are typically scored on a binary scale (correct/incorrect). Logistic regression is generally thought to be superior to other forms of regression for the detection of DIF in dichotomously scored items. For example, unlike linear regression, logistic regression will not give you results of less than zero or greater than one, a common problem in linear regression despite the possible score item outcomes of only 0 (incorrect) or 1 (correct). Other forms of regression can be applied when dealing with items scored on a scale other than binary; ordinal logistic regression can be used for rating scale or Likert-type items and ordinary least-squares regression can be used for continuous or Likert-type items that have many scale points (e.g., more than 6 scale points) (Slocum, et al., 2003). At each of the steps in the LR process an effect size measure is created which can be used to assess the level of DIF in an item; this is computed by most statistical software programs as a Nagelkerke R-squared value. The Nagelkerke R-square is an approximation of the R-square used in other regression models however, some caution that it should not be treated as if it were a measure of the proportion of variance accounted for, such as in the use of R-squared values in other regression models (Cohen, et al., 2003). While it may not be appropriate to interpret and use these values in the same way as R-squared values obtained in other analyses, this study will refer to these values 42 43 as simply R-squared for the purposes of this study. The R-squared value from each of the steps of the LR method can be used to determine the magnitude of DIF by subtracting the R-squared value of the step prior (Zumbo, 1999). For example, to determine the magnitude of uniform DIF the R-squared value of the first step (ability level only) is subtracted from the R-squared value of the second step (group membership added after ability level). This allows for a measurable difference of the effect that group membership has on the likelihood of answering an item correctly after accounting for ability level. This same process can be used when assessing the magnitude of nonuniform DIF, in this case the R-squared value of the first step would be subtracted from the R-squared value of the third step (the interaction of ability and group membership is added after the two individual variables have been added) (Slocum, et al., 2003). Uniform DIF is only considered present when steps 1 and 2 differ significantly and there is no significant difference between steps 1 and 3 (Swaminathan & Rogers, 1990). Once the differences in R-squared values have been determined they can be evaluated to assess and categorize levels of DIF. One of the more commonly used criteria for categorizing DIF levels into categories of A, B and C, like those used in the MH procedure is the effect size criteria of Jodoin & Gierl (2001). If the difference between Rsquared values is below 0.035 then there is said to be negligible DIF (Category A), differences in R-squared values between 0.035 and 0.070 are considered moderate DIF (Category B), and differences in R-squared values above 0.070 are considered large DIF (Category C). It should also be noted that there is a second commonly used categorization system by Hidalgo & Lopez-Pina (2004), however the categorization system by Jodoin & 43 44 Gierl (2001) was proposed as being more sensitive to detecting DIF (Wiberg, 2007) and was therefore used in preference to the Hidalgo & Lopez-Pina (2004) system for this study. The R-squared differences are used to determine the effect size of DIF in an item; however, they do not identify which group is performing at a lower rate on the item after controlling for ability. The odds ratio is used to determine if one group has higher odds of responding correctly to an item than another group after ability has been accounted for (Slocum, et al., 2003) and this will tell you the direction of the DIF. DIF Detection Method Comparisons Previous studies have found differences in performance by the MH and LR methods that would sometimes suggest the appropriateness of using one method over the other; those differences, which are applicable to this study, will be highlighted here. It is important to note that some of the studies which identify differences between the two methods have yet to be replicated and that emerging research continues to accumulate on differences between these two methods for DIF detection. The LR method differs from the MH method greatly in its reliance on certain assumptions. For example, unlike the MH method, LR assumes that there is a linear relationship between the probability of individuals answering an item correct and their total test score (Wiberg, 2007). There is also an assumption in LR that the scores of individuals are distributed evenly; this is because of the process by which the LR method attempts to fit the scores to the regression curve. When there are not enough observed scores at either the extremely low or high end of the possible score range, the LR may not 44 45 be able to as accurately predict an individuals’ likelihood of responding to an item correctly. Data that are not evenly spread across all of the possible score ranges are not quite as problematic for the MH procedure, since contingency tables without information in one of the cells are skipped in the process of detecting DIF (Rogers & Swaminathan, 1993). Studies have also found that the LR method for detecting DIF is affected by the percentage of items in the test containing DIF while the MH method is not (Rogers & Swaminathan, 1993). According to Rogers and Swaminathan (1993) there are pros and cons to the use of each method in terms of uniform/non-uniform DIF; because the LR procedure contains parameters representing both uniform and non-uniform DIF, it may be less powerful than the MH procedure in detecting strictly uniform DIF. Conversely, the MH procedure has been found to have slightly higher detection rates for uniform DIF (Rogers & Swaminathan, 1993) but since it is designed for the detection of DIF that is constant across the range of ability levels, it is generally not able to detect non-uniform DIF and when it is modified to do so, it may not be effective in detecting non-uniform DIF. An advantage that the LR method has over the MH method is the ability to be extended for use with multiple ability measures. Mazor et al. (1995) found a greater ease of use with the LR method than with MH given the difficult nature of building contingency tables off of multiple ability estimates in the MH method. While the current study is only concerned with DIF detection methods that utilize one ability measure (total test score), it should be noted that some tests may require the use of multiple ability measures to be assessed appropriately and that the differences between the two methods 45 46 could differ based on the degree of multidimensionality in the ability measure used. According to Clauser, et al., (1991) the choice of using either total test score or subtest scores has a substantial influence on the classification of items showing DIF. Studies in which the LR and MH methods have been compared have found MH to be superior in regards to Type I errors; a greater rate of false positives has been found when using the LR method for DIF detection (Mazor et al., 1995). Additionally, a study by Ibrahim (1992) suggests that the level of false positives detected by both methods may increase with larger sample sizes. In addition to affecting false positive rates, the sample size, or number of test takers involved in an analysis of DIF, can affect the ability of detection models to accurately identify and classify DIF in an item. The MH method may be more appropriate when sample sizes are low (Schumacker, 2005) since the LR method requires a larger sample to function appropriately, though there is still likely to be loss of accuracy in the MH method given the necessity of thick matching with small sample sizes. Rogers and Swaminathan (1993) indicate that the sample size has a strong effect on both the MH and LR method and Mazor et al., (1994) found that the percentage of DIF items correctly identified decreased with smaller sample sizes. Purpose of the Study Mazor et al. (1995), Scheuneman & Slaughter (1991) and others have claimed that regardless of which criterion the comparison is based on, the MH and LR procedures result in similar numbers of items (and similar items) being identified. It is precisely this statement that the current study seeks to either support or provide evidence against. Also important to the purpose of this study is the practical usefulness of one method over the 46 47 other. For example, if for long tests the MH is a simpler and less expensive method than others, as Clauser and Hambleton (1994) suggest, then a negligible difference between the two methods in terms of number of items or degree of DIF identified could support a preference for the use of the MH method over the LR method in applied settings where time and cost are of concern. Conversely, if LR is found to outperform the MH method to such a degree that the overall adverse impact seen in a test would be altered then there would be justification for the practical use of the LR method regardless of the impacts on time or cost. The purpose of this study is to serve as a comparative analysis of two measures for detecting differential item functioning (DIF) in data concerning individual test items. The methods compared in this study are two of the more commonly used procedures in the testing arena; the Mantel-Haenszel chi-square and the logistic regression procedure. The study focuses on the overall effect each method has on adverse impact when used for the removal of items from a test. It is this author’s hypotheses that 1) adverse impact will be decreased by the removal of items that display DIF, and 2a) that the overall adverse impact of the test will be different depending on the method used for detecting differential item functioning, but 2b) that there will be no practical significance in the differences found. 47 48 Chapter 2 METHOD Sample Description The data used in this study were provided by Biddle Consulting Group, Inc. and included test item responses of 29,799 job applicants for entry level security officer positions in over 180 locations throughout the United States and Guam during 2007. For the sake of test security and client confidentiality, the specific names of the test and administering company have been excluded. The sample used for this study included only the applicant data for which self identified demographic data were available (N = 29,171). As shown in Table 1, self identified gender of the applicants was 69% male and 31% female. Self identified ethnicities of the applicants was 50.7% Caucasian and 49.3% minority; the minority status is comprised of American Indian/Alaskan Native (0.8%), Asian (1.9%), Hispanic (8.8%), African American (35.0%), Native Hawaiian/Pacific Islander (0.6%), and those self identified as belonging to two or more races (2.3%). Instrument All applicants for an entry-level security officer position with the company for which this test was developed were required to take a multiple-choice test for consideration in the hiring process. The test was designed to measure the basic knowledge, skills, abilities, and personal characteristics that were found through a content validated job analysis to be linked to critical duties of the position and that are necessary on the first day of the job. The test included 49 multiple choice items. These items were 48 49 scored 1 for correct responses and 0 for incorrect responses, for a total possible score of 49. The mean test score of all 29,171 applicants was 40.20 with a standard deviation of 5.30 and an internal consistency reliability coefficient (Cronbach’s alpha) of .774. The individual item means and standard deviations can be found in Appendix A. The mean test scores and standard deviations by demographic group are presented in Table 2. Table 1 Demographic Characteristics of Examinees (N = 29,171). ___________________________________________________________________________ Characteristics N % ___________________________________________________________________________ Gender Male 20,136 69.0 Female 9,035 31.0 Caucasian 14,780 50.7 Total Minority 14,391 49.3 American Indian/Alaskan Native 244 0.8 Asian 563 1.9 Hispanic 2,554 8.8 African American 10,197 35.0 Native Hawaiian/Pacific Islander 162 0.6 Two or More Races 671 2.3 Ethnicity ___________________________________________________________________________ 49 50 Table 2 Descriptive Statistics of Examinee Test Scores (N = 29,171). ___________________________________________________________________________ Characteristics M SD ___________________________________________________________________________ Gender Male 40.43 5.32 Female 39.66 5.17 Caucasian 41.96 4.26 Total Minority 38.28 5.64 American Indian/Alaskan Native 40.64 4.58 Asian 37.80 6.00 Hispanic 38.98 5.72 African American 38.08 5.59 Native Hawaiian/Pacific Islander 38.61 5.08 Two or More Races 40.26 4.72 Ethnicity ___________________________________________________________________________ Procedure DIF Analysis for Item Removal Two DIF analyses were performed on each item of the selection test. One analysis was performed using the MH method and another was performed using the LR method. Though some researchers find that it may seem inconsistent to focus on only one type of DIF because it can be detected with little effort or expense (Rogers & Swaminathan, 1993), it is the purpose of this study to analyze the most typical way that DIF detection 50 51 methods are used. Therefore, in this study the MH procedure was used only to identify uniform DIF (even though it is possible to extend it for use in detecting non-uniform DIF) and the LR method was used to analyze both uniform and non-uniform DIF simultaneously. Given the large sample size and number of items, DIF detection analyses with the MH method were performed using thin matching; every item was analyzed across all possible test score values (0-49). The absolute MH D-DIF value, a measure of the effect size of DIF, is calculated by analyzing the odds ratios of the groups assessed across the many ability levels and transforming them into a “delta” metric by taking the natural log of the odds ratio across the score levels and multiplying it by -2.35. The MH D-DIF value, which can range from negative infinity to positive infinity, was then used to categorize the items by the classification rules developed by ETS as laid out in a study by Hidalgo & López-Pina (2004). Items were classified as displaying large DIF (ETS classification category C) when the absolute MH D-DIF values were greater than 1.5 and statistically significant. Items were classified as displaying intermediate DIF (ETS classification category B) when the absolute MH D-DIF values were between 1.0 and 1.5 and statistically significant. All items with an absolute MH D-DIF value that were not significant or that were below 1.0 were classified as displaying small or no DIF (ETS classification category A). In order to detect DIF with the LR method, analyses were performed using a 3 stage logistic regression procedure which assessed the dependent variable of applicant score responses (0 incorrect, 1 correct) for each item. At stage 1 total test score was 51 52 included in the model; total test score was included to serve as a proxy for ability and was entered first in the process so that further stages of the analyses could examine other attributes while the ability level of applicants was controlled for. At stage 2 the variable for group membership was included in the model; this stage of the process was performed to assess response differences as a result of group membership when applicant ability was controlled for. This comparison of group membership with applicant ability controlled for assesses the presence of uniform DIF. At stage 3 the interaction of total test score and group membership was included in the model; this stage of the process was performed to assess response differences as a result of the interaction of ability and group membership when applicant ability was controlled for. This comparison of an ability and group membership interaction with applicant ability controlled for assesses the presence of nonuniform DIF. The logistic regression procedure computes the amount of variance in the applicants score responses that can be accounted for by the variables entered into the model at that stage and the previous stages. In the first stage the variance accounted for by the total test score is computed. The second stage of the model computes the amount of variance accounted for by both total test score and group membership. The third stage of the model computes the amount of variance accounted for by both the variable in stage 2 and the interaction of total test score and group membership. The amount of variance accounted for at each stage is represented by a Nagelkerke R2 value. The Nagelkerke R2 value can then be compared across the different stages to detect DIF. To determine nonuniform DIF, the Nagelkerke R2 values at stage 3 and stage 1 are compared. If the 52 53 difference between these two values was not significant, a second comparison was made to determine the presence of uniform DIF by comparing the Nagelkerke R2 values at stage 2 and stage 1. The classification of small, intermediate and large levels of DIF was modeled after the classification criteria suggested by Jodoin and Gierl (2001). The classification of large DIF (equivalent to an ETS classification category C) was applied if a statistically significant change in Nagelkerke R2 values was greater than .070. If there was a change between Nagelkerke R2 values between .035 and .070 and this change was statistically significant, the classification of intermediate DIF (equivalent to an ETS classification category B) was applied. A categorization of small or no DIF (equivalent to an ETS classification category A) was applied to items that did not have a statistically significant difference in Nagelkerke R2 values or a difference of less than .035. The categorization of DIF levels was applied to items displaying large or intermediate DIF regardless of whether or not the negatively impacted group is a legally protected group or reference group. The categorizations were then used to create two alternate test scores for each applicant, one in which all items categorized as displaying large or intermediate DIF using the MH method were removed, and one in which all items categorized as displaying large or intermediate DIF using the LR method were removed. This created 3 total test scores available for adverse impact analyses; the original 49 item total test score (Original Test), the test score based only on items which did not have large or intermediate DIF detected by the MH method (MH Test) and the test score based only on items which did not have large or intermediate DIF detected by the LR method (LR Test). 53 54 Adverse Impact Analyses The demographic groups available in the data set were used to create comparison groups for adverse impact analyses. One comparison was made with respect to gender, Male v. Female. Seven comparisons were made with respect to ethnicity (1) Caucasian v. all other ethnic groups, labeled Total Minority, (2) Caucasian v. American Indian/Alaskan Native, (3) Caucasian v. Asian, (4) Caucasian v. Hispanic, (5) Caucasian v. African American, (6) Caucasian v. Native Hawaiian/Pacific Islander, and (7) Caucasian v. two or more races. Since it was not the purpose of this study to determine appropriate cut-off scores for selection tests, the three test scores were analyzed with respect to adverse impact at all possible cut-off scores. The Original Test, MH Test and LR Test scores were analyzed at all possible cut-off scores for adverse impact using the 80% rule and the Fisher Exact procedure. A test of practical significance was also assessed for each result that indicated adverse impact in the test. If the passing rate of one group within a comparison was not at least 80% of the passing rate of the other group at a particular cut-off score, it was marked as a violation of the 80% rule. If the p value of the Fisher Exact test at a particular cut-off score was below .05, it was marked as displaying statistically significant adverse impact. If the p value of a Fisher Exact test at a particular cut-off score was between .05 and .10, it was marked as approaching statistically significant adverse impact. Practical significance was assessed for all violations of the 80% rule and all statistically significant findings of adverse impact. Because the intent of this study was to 54 55 utilize the most commonly used methods for DIF detection and adverse impact analyses, the 80% rule and Fisher’s Exact test were re-run after changing the status of two individuals in the lower passing rate group to a pass instead of a fail. This method of assessing practical significance was considered to be the most commonly used method because it was used in two court cases in which the courts found that if two or fewer persons from the group with the lowest pass rate were hypothetically changed from “failing” to “passing” status, and this resulted in eliminating the statistical significance finding, the results were not to be considered practically significant (Biddle, 2006). The court cases which changed the status of two individuals were U.S. v. Commonwealth of Virginia (569 F2d 1300, CA-4 1978, 454 F. Supp. 1077) and Waisome v. Port Authority (948 F.2d 1370, 1376, 2d Cir.,1991). A third court case Contreras v. City of Los Angeles (656 F.2d 1267, 9th Cir., 1981) involved the hypothetical status change of three individuals. These analyses were run for each of the eight demographic group pairs on all three tests so that each possible cut-off score of the three tests had an assessment of the 80% rule, statistical significance and test(s) of practical significance if applicable. The number of occurrences of 80% rule violations, statistical significance findings of adverse impact and the occurrence of practically significant findings of adverse impact were noted and compared to assess the overall effect each method had on the adverse impact of this test when used for the removal of items. 55 56 Chapter 3 RESULTS The main research issues that this study sought to address were: 1. The potential for decreasing overall adverse impact of a test by the removal of items displaying DIF. 2. The differences in overall adverse impact of a test when different methods are used for detecting and removing items which display DIF. 3. The practical significance in the differences found between the use of the two methods for item removal as it relates to adverse impact findings. To address these issues as they apply to the test and procedures used in this study, analyses of differential item functioning were performed using two methods, the MH method and the LR method. New test scores were created based on the removal of items displaying moderate or large levels of DIF, and the results of adverse impact analyses performed on these new tests, as well as the original test, were evaluated. DIF and Item Removal Mantel-Haenszel Analyses Each of the 49 items available in the test was assessed for DIF using the MantelHaenszel procedure among the eight comparison groups; this resulted in 392 assessments of DIF using the MH method. Of the 392 assessments, 3.6% (14) were classified as displaying a large amount of DIF, 9.4% (37) of the assessments were classified as 56 57 displaying intermediate DIF and 87% (341) of the assessments were classified as displaying small or no DIF. Table 3 displays the DIF classifications by comparison groups. The MH DIF values and DIF classification level of each item is presented in Appendix B. Table 3 MH Method DIF Classifications by Reference Group. _____________________________________________________________________________ Comparison Group ETS Classification Category A B C Male/Female 45 2 2 Total Minority/Caucasian 40 7 2 American Indian/Caucasian 46 3 0 Asian/Caucasian/Caucasian 41 6 2 Hispanic/Caucasian 45 3 1 African American/Caucasian 40 7 2 Hawaiian/Caucasian 37 9 3 Two or More/Caucasian 47 0 2 Grand Total 341 37 14 Note. The ETS classification category of A corresponds to small or no DIF, the category of B corresponds to moderate or intermediate levels of DIF, and the category of C corresponds to large levels of DIF. Twenty items on the test were found to display either moderate or large levels of DIF on one or more group comparisons when assessed with the MH method. Only 1 item, item #10, displayed a moderate or large level of DIF on all eight comparison groups. The 20 test item numbers and a count of the group comparisons displaying either 57 58 moderate DIF (ETS Classification Category B), or large DIF (ETS Classification Category C) are shown in Table 4. The remaining 29 items which displayed small or no DIF on all 8 group comparisons were retained to create the new test score based only on items which did not have large or intermediate DIF detected by the MH method. The term MH Test will be used to describe further results of this study as they pertain to the combined set of these 29 original test items; the complete list of item numbers on the MH Test can be found in Table 5. The mean test score of all 29,171 applicants on the 29 item MH Test was 23.32 with a standard deviation of 3.44 and a reliability coefficient (Cronbach’s alpha) of .660. The individual item means and standard deviations can be found in Appendix A. The mean test scores and standard deviations by demographic group are presented in Table 6. 58 59 Table 4 MH Method DIF Classifications by Item Number. ETS Classification ETS Classification Category B Category C 3 1 1 4 1 0 7 2 0 10 4 4 11 1 0 13 1 0 16 3 2 18 1 0 19 3 0 20 2 1 26 2 0 31 1 0 34 3 1 35 3 0 36 4 0 38 1 0 43 0 1 45 1 0 46 1 0 47 2 4 Grand Total 37 14 Item # Note. The ETS classification category of A corresponds to small or no DIF, the category of B corresponds to moderate or intermediate levels of DIF, and the category of C corresponds to large levels of DIF. 59 60 Table 5 Item Numbers Displaying Small or No DIF with the MH Method. Original Test Item Numbers of the MH Test 1, 2, 5, 6, 8, 9, 12, 14, 15, 17, 21, 22, 23, 24, 25, 27, 28, 29, 30, 32, 33, 37, 39, 40, 41, 42, 44, 48, 49. Table 6 Descriptive Statistics of MH Test Scores (N = 29,171). ___________________________________________________________________________ Characteristics M SD ___________________________________________________________________________ Gender Male 23.43 3.46 Female 23.06 3.38 Caucasian 24.34 2.88 Total Minority 22.27 3.65 American Indian/Alaskan Native 23.59 2.93 Asian 21.76 3.90 Hispanic 22.62 3.69 African American 22.11 3.65 Native Hawaiian/Pacific Islander 22.30 3.25 Two or More Races 23.27 3.13 Ethnicity ___________________________________________________________________________ 60 61 Logistic Regression Analyses Each of the 49 items available in the test was assessed for DIF using the logistic regression procedure among the eight comparison groups; this resulted in 392 assessments of both uniform and non-uniform DIF using the LR method. No DIF assessments were found to display non-uniform DIF. Therefore, all remaining discussion of DIF results are applicable only to uniform DIF findings. No DIF assessments were classified as displaying a large amount of DIF, 1.3% of assessments (5) were classified as displaying intermediate DIF and 98.7% of assessments (387) were classified as displaying small or no DIF. Table 7 displays the DIF classifications by comparison groups. The Nagelkerke R2 values and DIF classification level of each item is presented in Appendix C. Three items on the test were found to display either moderate or large levels of DIF on one or more group comparisons when assessed with the LR method. No items displayed a moderate or large level of DIF on all eight comparison groups. The 3 test item numbers and a count of the group comparisons displaying either moderate DIF (ETS Classification Category B), or large DIF (ETS Classification Category C) are shown in Table 8. 61 62 Table 7 LR Method DIF Classifications by Reference Group. _____________________________________________________________________________ Comparison Group ETS Classification Category Male/Female A 49 B 0 C 0 Total Minority/Caucasian 47 2 0 American Indian/Caucasian 49 0 0 Asian/Caucasian 48 1 0 Hispanic/Caucasian 49 0 0 African American/Caucasian 47 2 0 Hawaiian/Caucasian 49 0 0 Two or More/Caucasian 49 0 0 Grand Total 387 5 0 Note. The ETS classification category of A corresponds to small or no DIF, the category of B corresponds to moderate or intermediate levels of DIF, and the category of C corresponds to large levels of DIF. Table 8 LR Method DIF Classifications by Item Number. ETS Classification ETS Classification Category B Category C 10 2 0 16 1 0 47 2 0 Grand Total 5 0 Item # Note. The ETS classification category of A corresponds to small or no DIF, the category of B corresponds to moderate or intermediate levels of DIF, and the category of C corresponds to large levels of DIF. 62 63 The remaining 46 items which displayed small or no DIF on all 8 group comparisons were retained to create the new test score based only on items which did not have large or intermediate DIF detected by the LR method. The term LR Test will be used to describe the results of this study as they pertain to the combined set of these 46 original test items. The list of items on the LR Test can be found in Table 9. Table 9 Item Numbers Displaying Small or No DIF with the LR Method. Original Test Item Numbers of the LR Test 1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 12, 13, 14, 15, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 48, 49. The mean test score of all 29,171 applicants on the 46 item LR Test was 40.19 with a standard deviation of 5.28 and a reliability coefficient (Cronbach’s alpha) of .746. The individual item means and standard deviations can be found in Appendix A. The mean test scores and standard deviations by demographic group are presented in Table 10. 63 64 Table 10 Descriptive Statistics of LR Test Scores (N = 29,171). ___________________________________________________________________________ Characteristics M SD ___________________________________________________________________________ Gender Male 40.43 5.32 Female 39.66 5.17 Caucasian 41.96 4.26 Total Minority 38.38 5.61 American Indian/Alaskan Native 40.64 4.58 Asian 37.80 6.00 Hispanic 38.97 5.73 African American 38.08 5.59 Native Hawaiian/Pacific Islander 38.61 5.08 Two or More Races 40.26 4.72 Ethnicity ___________________________________________________________________________ Comparison of the MH and LR Methods for DIF Detection and Item Removal In order to compare DIF results between two differing detection methods, a single set of classification categories was applied to all of the DIF analysis results. All DIF assessments on items in this study were classified as displaying either large, intermediate, or small/no DIF. In the MH analyses, DIF classifications were determined using the absolute MH D-DIF value, a measure of the effect size of DIF, which is calculated by analyzing the 64 65 odds ratios of the groups assessed across the many ability levels and transforming them into a “delta” metric by taking the natural log of the odds ratio across the score levels and multiplying it by -2.35. The MH D-DIF value, which can range from negative infinity to positive infinity, was then used to categorize the items by the classification rules developed by ETS as laid out in a study by Hidalgo & López-Pina (2004). These classification rules indicated large DIF (ETS classification category C) when the absolute MH D-DIF values were greater than 1.5 and statistically significant, intermediate DIF (ETS classification category B) when the absolute MH D-DIF values were between 1.0 and 1.5 and statistically significant, and small or non-existent DIF (ETS classification category A) when the absolute MH D-DIF values were not significant or below 1.0. Although there is a process for creating a measure similar to the MH D-DIF value, LR D-DIF, where the odds ratios are assessed and transformed to a delta metric by multiplying the result by -2.35 (Monohan, et. al, 2007), the purpose of this study was to assess the two methods in their most commonly used manner. So, the more widely referenced classification criteria suggested by Jodoin and Gierl (2001) was used to assess large or intermediate DIF in the LR analyses. The classification of large DIF (equivalent to an ETS classification category C) was applied if a statistically significant change in Nagelkerke R2 values was greater than .070. If there was a change between Nagelkerke R2 values of between .035 and .070 and this change was statistically significant, the classification of intermediate DIF (equivalent to an ETS classification category B) was applied. A categorization of small or no DIF (equivalent to an ETS classification category 65 66 A) was applied to items that did not have a statistically significant difference in Nagelkerke R2 values or a difference of less than .035. Each of the 49 items on the original selection test was analyzed for DIF among the eight comparison groups. Thus, each item resulted in 8 DIF assessments performed by each detection method. The outcomes of these assessments were classified into one of the ETS classification categories. As a result, there were a total of 392 DIF assessments performed using each DIF detection method (784 DIF assessments overall). The term “assessments” will be used to refer to these 8 comparison group DIF assessments and the subsequent classifications performed with each method on all of the 49 items in the original test. The MH DIF detection method identified more assessments displaying DIF than did the LR method on the selection test used in this study. Of the 392 assessments of DIF performed using each method, the MH method classified 3.6% (14) as displaying a large amount of DIF, while the LR method classified no item as displaying a large amount of DIF. The MH method classified 9.4% (37) of the assessments as displaying intermediate DIF, while the LR method classified only 1.3% (5) assessments as displaying intermediate DIF (see Figure 4). 66 67 40 # of DIF Classifications 35 30 25 20 MH LR 15 10 5 0 Large DIF Intermediate DIF Figure 4. Display of DIF Assessments Classifications by DIF Detection Method. Of the 49 items assessed for DIF, the MH method identified 20 items as displaying either moderate or large levels of DIF on one or more assessments. The LR method identified only 3 items displaying moderate DIF on one or more assessments. Although the number of items identified by each method differed, there appeared to be a similar pattern in regard to the number of assessments identified as displaying DIF on particular items. The 3 items identified by the LR method, item numbers 10, 47 and 16, coincide with the test items identified by the MH method as displaying the largest number of moderate or large DIF assessments. Item 10 was identified as displaying the largest number of DIF assessments by the MH method (8) and 2 assessments by the LR method. Item 47 was identified as displaying the second largest number of DIF assessments by the MH method (6) and also 2 assessments by the LR method. Item 16 was identified as displaying the third largest number of DIF assessments by the MH method (5) and one assessment displaying DIF by the LR method. This may indicate that, 67 68 although the MH method of classification used in this study identifies more assessments as displaying DIF, the items identified would be in alignment with those also identified by the LR method if a more lenient classification system were used (see Table 11). When items were removed based on the two DIF detection methods, two new versions of the test were created, the MH Test and LR Test. Only items which displayed small or no DIF on all 8 group comparison assessments were retained to create the new test scores. This resulted in an MH Test comprised of 29 of the original 49 items and an LR Test comprised of 46 of the original 49 items. The test statistics of these two new tests were assessed and compared to the original test to determine if any significant changes occurred on the overall performance of the tests and applicant test scores as a result of the item removal. To ensure that the act of item removal when creating the MH and LR test did not greatly affect the average test score of applicants, the percent of mean test scores was calculated by dividing the mean test score of applicants by the total number of items on each test. This allowed for an assessment of applicant performance (total number of items correct divided by total number of items on the test) across the three tests. The percent of mean test scores on the MH Test (80.4%) and LR Test (82.2%) did not differ greatly from the average percentage score of the Original Test (82%). The reliability of the tests, however, did slightly decrease as the number of items on the test decreased (see Table 12). 68 69 Table 11 MH & LR DIF Classifications by Item Number. MH Assessments Displaying Large LR Assessments Displaying or Moderate DIF Large or Moderate DIF 10 8 2 47 6 2 16 5 1 34 4 36 4 35 3 19 3 20 3 3 2 7 2 26 2 11 1 13 1 4 1 18 1 31 1 38 1 43 1 45 1 46 1 Item # Grand Total 37 5 69 70 Table 12 Descriptive Statistics of the Original, MH and LR Test Scores (N = 29,171). ___________________________________________________________________________ Test # Test Items M SD r ___________________________________________________________________________ Original Test 49 40.19 5.28 .774 MH Test 29 23.31 3.45 .662 LR Test 46 37.81 4.84 .748 Note. Reliability (r) is reported by the Cronbach’s alpha measure. Adverse Impact Analyses Because this study was concerned with the effect of item removal based on DIF results on the incidence of adverse impact in a test, but did not seek to address the creation of cut-off points for selection tests, adverse impact analyses were performed for all possible cut-off points on all 3 tests. The counts of individuals who passed/failed in each comparison group at each possible cut-off score were used to perform adverse impact assessments; the number of passing individuals at each cut-off score level by test and comparison group can be found in Appendix D. The eight comparison groups assessed for adverse impact were the same comparison groups used for DIF detection analyses. These groups included one comparison made with respect to gender, Male v. Female, and seven comparisons made with respect to ethnicity: (1) Caucasian v. all other ethnic groups, labeled Total Minority, (2) Caucasian v. American Indian/Alaskan Native, (3) Caucasian v. Asian, (4) Caucasian v. Hispanic, (5) Caucasian v. African American, (6) Caucasian v. Native Hawaiian/Pacific Islander, and (7) Caucasian v. two or more races. Adverse impact 70 71 analyses included an assessment of whether or not there was an 80% rule violation on any of the eight comparison groups, whether or not there was a statistically significant difference on any of the eight comparison groups, and whether or not there was practical significance of any 80% rule violation or statistical significance adverse impact finding. Given the large number of applicants used in the study data (29,171), the results of the statistical significance tests were believed to contain too much alpha inflation for the results to be conclusive. Meyers & Hunley (2008) consider the situation of alpha inflation to be analogous to throwing darts at a dartboard: “We may be completely unskilled in this endeavor, but given enough darts and enough time we will eventually hit the center of the board. But based on that particular throw, we would be sadly mistaken to claim that the outcome was anything but sheer luck. In performing statistical analyses, the more related tests we perform the more likely it is that we will find “something significant,” but that particular outcome might not represent a reliably occurring effect." (Meyers & Hunley, 2008, p. 15). Of the 824 statistical significance tests performed on the three tests at all possible cut-off scores for the eight comparison groups, 523 (63.5%) were found to display statistically significant adverse impact. These findings were likely to be the result of alpha inflation, not true indicators of adverse impact. Appendix E displays the alpha level of each Fisher’s Exact Test performed on the three tests at all possible cut-off scores for the eight comparison groups. A comparison between the MH Test and LR Test in terms of statistically significant adverse impact assessments, whether practically significant or 71 72 not, was deemed inappropriate for the purposes of this study. Thus, only the results of the 80% rule assessments of adverse impact will be discussed in detail and utilized for comparison purposes. The term assessments will be used to explain adverse impact results performed at all possible cut off scores of a test for each group comparison. Original Test 80% Rule Adverse Impact Analyses In order to determine if the removal of items displaying DIF changed the amount of adverse impact displayed by a test, the applicant scores on the original 49 item test (Original Test) were analyzed to determine the level of adverse impact present in the unaltered test. The observed scores on the Original Test ranged from 10-49; thus adverse impact was assessed on the eight comparison groups at all 39 possible cut-off scores (312 assessments). To assess if violations to the 80% rule had occurred, thus indicating adverse impact, the passing rates of each group in a comparison were assessed to determine if the passing rate of one group was at least 80% the passing rate of the other group. If the passing rate of one group was not at least 80% the passing rate of the other group, a violation of the 80% rule was said to have occurred and was considered to be evidence of adverse impact. Among the 312 assessments, 91 were identified as having violated the 80% rule. The practical significance of any 80% rule violation was then assessed by the method of hypothetically changing the failing/passing status of two individuals, which was found to be the more commonly performed method for assessing practical significance of adverse impact in a legal setting. To perform the test of practical significance, the status of two individuals in the lower passing rate group was changed 72 73 from a failing status to a passing status and the 80% rule assessment was re-assessed. If there was still an 80% rule violation after the manipulation of two individuals occurred, then the 80% rule violation was considered to be practically significant. Eighty-nine of the 91 80% rule violations were found to be practically significant. Table 13 displays the number of 80% rule violations and practically significant 80% rule violations by comparison groups. Table 13 Number of 80% Rule Violations and Practically Significant 80% Rule Violations in the Original Test by Comparison Groups. _____________________________________________________________________________ Comparison Groups # of 80% Rule Violations # of Practically Significant 80% Rule Violations Male/Female 7 7 Total Minority/Caucasian 13 13 American Indian/Caucasian 8 7 Asian/Caucasian 15 15 Hispanic/Caucasian 12 12 African American/Caucasian 14 14 Hawaiian/Caucasian 13 12 Two or More/Caucasian 9 9 Grand Total 91 89 73 74 There were no findings of 80% rule violations in the lowest 24 cut-off score levels; cut-off scores between 11 and 34. There was at least one 80% rule violation and one practically significant 80% rule violation at every cut-off score at or above 35, a passing score of 71% or better on the 49 items. The number of group comparisons showing 80% rule violations at each cut-off score level increased as the cut-off score increased, such that the 7 highest cut-off scores on the test 43-48, which are equivalent to a passing score of 87.8% or higher, were shown to have 80% rule violations on all assessments performed (see Table 14). MH Test 80% Rule Adverse Impact Analyses The observed scores on the MH Test, which was comprised of the 29 items from the Original test which displayed small or no DIF on all 8 group comparisons when using the MH DIF detection method, ranged from 3-29; thus adverse impact was assessed on the 8 comparisons groups at all 26 possible cut-off scores. The passing rates of each group in a comparison were assessed to determine if any violations to the 80% rule had occurred. A violation was said to have occurred when the passing rate of one group was not at least 80% the passing rate of the other group. Among the 208 assessments (26 possible cut-off scores assessed on 8 comparison groupings), there were a total of 58 80% rule violations. To asses practical significance of an 80% rule violation the number of passing individuals in the lower passing rate group was increased by two individuals and the 80% rule assessment was re-assessed. If there was still an 80% rule violation after that manipulation of two individuals occurred, then the 80% rule violation was considered to be practically significant. Fifty-six of the 58 80% rule violations were also 74 75 found to be practically significant. Table 15 displays the number of 80% rule violations and practically significant 80% rule violations by comparison groups. Table 14 Number of 80% Rule violations and Practically Significant 80% Rule Violations in the Original Test by Cut-off Score Levels. Original Test # of Practically Significant Cut-off Score # of 80% Rule Violations 80% Rule Violations 35 1 1 36 2 2 37 4 4 38 5 5 39 5 5 40 5 5 41 6 6 42 7 7 43 8 8 44 8 8 45 8 8 46 8 8 47 8 8 48 8 8 49 8 6 91 89 Grand Total 75 76 Table 15 Number of 80% Rule violations and Statistically Significant 80% Rule Violations in the MH Test by Comparison Groups. _____________________________________________________________________________ Comparison Groups # of 80% Rule Violations # of Practically Significant 80% Rule Violations Male/Female 3 3 Total Minority/Caucasian 8 8 American Indian/Caucasian 5 3 Asian/Caucasian 10 10 Hispanic/Caucasian 8 8 African American/Caucasian 9 9 Hawaiian/Caucasian 9 9 Two or More/Caucasian 6 6 Grand Total 58 56 There were no findings of 80% rule violations in the lowest 16 cut-off score levels; cut-off scores between 4 and 19. There was at least one 80% rule violation and one practically significant 80% rule violation at every cut-off score at or above 20, a passing score of 69% or better on the 29 items. The number of group comparisons showing 80% rule violations at each cut-off score level increased as the cut-off score increased, such that the 3 highest cut-off scores on the test 27-29, which are equivalent to a passing score of 93.1% or higher, were shown to have 80% rule violations on all assessments performed (see Table 16). 76 77 Table 16 Number of 80% Rule violations and Statistically Significant 80% Rule Violations in the MH Test by Cut-off Score Levels. MH Test # of Practically Significant Cut-off Score # of 80% Rule Violations 80% Rule Violations 20 1 1 21 3 3 22 5 5 23 5 5 24 6 6 25 7 7 26 7 7 27 8 8 28 8 7 29 8 7 58 56 Grand Total LR Test 80% Rule Adverse Impact Analyses The observed scores on the LR Test, which was comprised of the 46 items from the Original test which displayed small or no DIF on all 8 group comparisons when using the LR DIF detection method, ranged from 8-46; thus adverse impact was assessed on the 8 comparisons groups at all 38 possible cut-off scores. The passing rates of each group in a comparison were assessed to determine if any violations to the 80% rule had occurred. A violation was said to have occurred when the passing rate of one group was not at least 77 78 80% the passing rate of the other group. Among the 304 assessments (38 possible cut-off scores assessed on 8 comparison groupings), there were a total of 81 80% rule violations. To assess practical significance of an 80% rule violation the number of passing individuals in the lower passing rate group was increased by two individuals and the 80% rule assessment was re-assessed. If there was still an 80% rule violation after that manipulation of two individuals occurred, then the 80% rule violation was considered to be practically significant. Seventy-eight of the 81 80% rule violations were also found to be practically significant. Table 17 displays the number of 80% rule violations and practically significant 80% rule violations by comparison groups. There were no findings of 80% rule violations in the lowest 25 cut-off score levels, cut-off scores between 10 and 33. There was at least one 80% rule violation and one practically significant 80% rule violation at every cut-off score at or above 34, a passing score of 73.9% or better on the 46 items. The number of group comparisons showing 80% rule violations at each cut-off score level increased as the cut-off score increased, such that the 5 highest cut-off scores on the test 42-46, which are equivalent to a passing score of 91.3% or higher, were shown to have 80% rule violations on all assessments performed (see Table 18). Comparison of 80% Rule Adverse Impact Analyses Because each of the three tests differed in the number of items on the test and therefore the number of cut-off scores at which adverse impact analyses could be performed, a simple comparison of the overall number of 80% rule violations and practically significant 80% rule violations was not appropriate. A longer test would 78 79 contain a larger number of cut-off scores and would therefore have a greater number of assessments performed that could potentially contain adverse impact than would a shorter test. To account for this, the total number of 80% rule violations and practically significant 80% rule violations were divided by the number of adverse impact analyses performed on each test; this created a percentage that could be used for making comparisons between all three tests. The following comparisons made in regards to 80% rule violations reference a percentage which is calculated by dividing the number of violations and practically significant violations by the total number of assessments performed on the test being described. Table 17 Number of 80% Rule violations and Statistically Significant 80% Rule Violations in the LR Test by Comparison Groups. _____________________________________________________________________________ Comparison Groups # of 80% Rule Violations # of Practically Significant 80% Rule Violations Male/Female 5 5 Total Minority/Caucasian 13 12 American Indian/Caucasian 8 6 Asian/Caucasian 14 13 Hispanic/Caucasian 12 11 African American/Caucasian 12 12 Hawaiian/Caucasian 13 11 Two or More/Caucasian 10 8 Grand Total 81 78 79 80 Table 18 Number of 80% Rule violations and Statistically Significant 80% Rule Violations in the LR Test by Cut-off Score Levels. LR Test Cut- # of Practically Significant off Score # of 80% Rule Violations 80% Rule Violations 34 1 1 35 4 4 36 5 5 37 5 5 38 6 5 39 6 6 40 7 7 41 7 7 42 8 8 43 8 8 44 8 8 45 8 8 46 8 6 81 78 Grand Total The Original Test contained the highest percentage of assessments with 80% rule violations (29.2%) and practically significant 80% rule violations (28.5%). The MH Test contained the next highest percentage of assessments with 80% rule violations (27.9%) and practically significant 80% rule violations (26.9%). The LR Test contained the lowest 80 81 percentage of assessments with 80% rule violations (26.6%) and practically significant 80% rule violations (25.7%). The percent of assessments found to violate the 80% rule and the percent of assessments found to be practically significant violations of the 80% rule are displayed graphically in Figure 5. Percent of Assessments 30 29 28 80% Rule Violations 27 26 Pract. Sig. 80% Rule Violations 25 24 23 Original Test MH Test LR Test Figure 5. Percentage of Adverse Impact Analyses Displaying 80% Rule Violations and Practically Significant 80% Rule Violations. The percentage of assessments with 80% rule violations were also analyzed by comparison groups to determine if the three versions of the test differed in the amount of adverse impact seen by comparison groups. However, all tests showed a similar pattern in terms of the percentage of assessments that were identified as 80% rule violations by comparison groups (see Figure 6). The lowest percentage of 80% rule violations by group occurred in the comparison between male and female applicants for all tests (1.4%2.2%). The highest percentage of 80% rule violations by group occurred in the 81 82 comparison between applicants self-identified as Asian or Pacific Islander and Caucasian 6 5 4 3 2 1 0 Original Test MH Test Two or More/Caucasian Hawaiian/Caucasian African American/Caucasian Hispanic/Caucasian Asian/Caucasian American Indian/Caucasian Total Minority/Caucasian LR Test Male/Female Percent of Assessments for all tests (4.3%-4.8%). Figure 6. Percentage of Adverse Impact Analyses Displaying 80% Rule Violations by Comparison Group and Test. All tests also showed a similar pattern in terms of the percentage of analyses that were identified as practically significant 80% rule violations by comparison groups (see Figure 7). The lowest percentage of practically significant 80% rule violations by group occurred in the comparison between male and female applicants for all tests (1.4%2.2%). The highest percentage of practically significant 80% rule violations by group occurred in the comparison between applicants self-identified as Asian or Pacific Islander and Caucasian for all tests (4.3%-4.9%). 82 6 5 4 Original Test 3 2 MH Test 1 LR Test Two or More/Caucasian Hawaiian/Caucasian African American/Caucasian Hispanic/Caucasian Asian/Caucasian American Indian/Caucasian Total Minority/Caucasian 0 Male/Female Percent of Assessments 83 Figure 7. Percentage of Adverse Impact Analyses Displaying Practically Significant 80% Rule Violations by Comparison Group and Test. For the sake of comparing cut-off score levels between the three tests which differ in the number of total items, each cut-off score level was divided by the total number of items on the test to create a percentage score of cut-off levels. By comparing percentage scores of cut-off levels the three tests can be assessed for the appearance of adverse impact at different difficulty levels. The term difficulty level in this instance refers only to the number of items an applicant must answer correctly to pass at that particular cutoff score divided by the total number of items on the test. The lowest percentage score cut-off level at which an 80% rule violation occurred was in the MH Test, which had a practically significant 80% rule violation at the percentage score cut-off level of 69%. The next lowest percentage score cut-off level at which an 80% rule violation occurred was in the Original Test, which had a practically significant 80% rule violation at the percentage score cut-off level of 71.4%. The first 83 84 occurrence of an 80% rule violation in the LR Test was at the percentage score cut-off level of 73.9%. The lowest percentage score cut-off level at which an 80% rule violation occurred on all group comparisons was in the Original Test, which had 8 practically significant 80% rule violations at the percentage score cut-off level of 87.8%. The next lowest percentage score cut-off level at which all group comparisons showed an 80% rule violation occurred in the LR Test, which had 8 practically significant 80% rule violations at the percentage score cut-off level of 91.3%. The lowest percentage cut of score level at which the MH Test violated the 80% rule on all group comparisons was at the percentage score cut-off level of 93.1%. All tests showed a similar pattern in terms of an increased number of 80% rule violations as percentage score cut-off levels increased (see Figure 8). 7 6 5 Original Test 4 MH Test 3 LR Test 2 1 100% 98-99% 96-97% 94-95% 92-93% 90-91% 88-89% 86-87% 84-85% 82-83% 80-81% 78-79% 76-77% 74-75% 72-73% 70-71% 0 68-69% # of 80% Rule Violations 8 % Score of Cut Off Level Figure 8. Number of 80% Rule Violations by % Cut-Off Score Level and Test. 84 85 All tests also showed a similar pattern in terms of an increased number of 8 7 6 5 Original Test 4 3 2 MH Test LR Test 100% 98-99% 96-97% 94-95% 92-93% 90-91% 88-89% 86-87% 84-85% 82-83% 80-81% 78-79% 76-77% 74-75% 72-73% 70-71% 1 0 68-69% # of Practially Significant 80% Rule Violations practically significant 80% rule violations as cut-off score levels increased (see Figure 9). % Score of Cut Off Level Figure 9. Number of Practically Significant 80% Rule Violations by % Cut-Off Score Level and Test. 85 86 Chapter 4 DISCUSSION Findings & Conclusions The results of this study indicate that the Mantel-Haenszel procedure of DIF detection identifies more instances of moderate or large DIF when using the classification rules developed by ETS as laid out in a study by Hidalgo & López-Pina (2004) than the logistic regression procedure of DIF detection when the classification of small, intermediate, and large levels of DIF was modeled after classification criteria suggested by Jodoin and Gierl (2001). This finding is consistent with Rogers and Swaminathan (1993) who also found the MH method to have higher detection rates for uniform DIF. Because the MH method detected more items displaying DIF, the use of this method for item removal resulted in fewer items that could be retained for a test comprised solely of items displaying only small or no DIF. The MH test created from the items displaying small or no DIF with the MH DIF detection method contained only 29 of the original 49 items, while the LR method included most (46) of the original 49 items. As would be expected, the reliability of the test was affected when the number of items on the test decreased with the removal of items. The reliability of the original test using the Cronbach’s alpha measure of reliability was .774; the reliability of the 46 items displaying small or no DIF by the LR method was .748 and the reliability of the 29 items displaying small or no DIF by the MH method was .662. This indicates that the use of the MH method for item removal may also lead to a decrease in test reliability. This may 86 87 indicate a potential weakness of the MH method, as it is used in this study, when the reliability of a test is of concern. Although the LR method is capable of assessing both uniform and non-uniform DIF simultaneously, there were no findings of non-uniform DIF detected by the LR method in this study. This suggests that in applied test assessment settings there may not always be a benefit to using the LR method for the sake of its ability to detect nonuniform DIF. The adverse impact results of this study show that a larger percentage of potential cut-off scores containing instances of 80% rule violations indicative of adverse impact were found in the original test (29.2%) and that this number is decreased with the removal of items displaying DIF through either the MH method (27.9%) or the LR method (26.6%). The results of the adverse impact analyses show a similar pattern in adverse impact findings by comparison groups; this suggests that the MH and LR method do not differ in their effect on particular comparison groups and that both methods reduce adverse impact findings in a similar manner across the eight comparison groups used in this study. The results also indicate that the occurrence of 80% rule violations indicative of adverse impact are more common as the difficulties of the cut-off score level increases. Difficulty in this instance refers to the number of items an applicant must answer correctly to pass at the particular cut-off. The difficulty of the cut-off score levels are determined by dividing the number of items an applicant must answer correctly to pass at the cut-off score by the total number of items on that test; higher percentage cut-off score 87 88 levels are considered to be more difficult. When the LR test was assessed, the appearance of adverse impact findings did not occur at any percentage cut-off score below 74%; this is much higher than the percentage cut-off score at which the original test (71%) or the MH test (69%) first displayed adverse impact. This may suggest that the use of the LR method for item removal would allow for more difficult cut-off score levels to be used without adverse impact than would the Original test. The MH method does not appear to allow for any more difficult cut-off score levels to be used without adverse impact than the Original test. To summarize, the results of this study indicate that the MH method, as it is applied in this study, identifies more items displaying potential DIF, but that the LR method, when used for item removal, will serve to better reduce possible adverse impact at slightly higher cut-off score levels and retain a higher test reliability level than will the MH method. Though these findings seem to indicate that the LR method should be used over the MH method, when performing DIF analyses in an applied setting there may be other factors involved. For example, in an applied setting the availability of resources may influence the decision to use one method over another. According to Rogers & Swaminathan (1993) the LR procedure appears to be three to four times more expensive than the MH procedure. This study also found that to be true when time is considered the “expense” of the procedure; the amount of time taken to apply the LR method in this study was approximately three times the amount of taken to apply the MH method for DIF detection analyses. Also, while many people may be at least conceptually comfortable with chi square statistics and the basic premises underlying the MH method, 88 89 the analytical skills required to understand the assumptions and interpret the output of the LR method may be a resource not readily available in many applied settings. Given that the reduction of adverse impact when the LR method is used only occurs in a couple out of many possible cut-off score levels, this study does not conclusively support the necessity of using the LR method for DIF detection and item removal over the use of the MH method in an applied setting. Limitations The MH method has been found to both over and under-estimate DIF according to several factors such as the matching variable (Holland & Thayer, 1988), guessing (Camilli & Penfield, 1997), and a lack of sufficient statistics for matching (Zwick, 1990). However, the selection test used in this study required a certain degree of confidentiality to ensure test security and anonymity. As such, the necessary information to address any of these factors was unavailable in the current study. Because the items could not be assessed for multi-dimensionality an assumption was made that the total test score was being appropriately used and assessed as a uni-dimensional measure for ability. The nature of this study did not allow for decisions to be made about the appropriate cut-off score for this particular selection test as it was intended for use with the employment organization. As a result the findings of this study do not revolve around a single cut-off score that can be assessed to determine simply whether or not adverse impact ceased to exist with the removal of items displaying DIF. While this provides for the assessment of many possible cut off scores, it is a potential limitation given that the assessment of adverse impact in a test is generally undertaken after considerable thought 89 90 has been given to selecting a single cut-off score that is appropriate for the purposes that the test has been designed to meet. Biddle (2006) warns that there is no firm set of rules for removing items based on DIF analyses, and that the practice should be approached with caution. A limitation of this study is that the method for removing items was based solely on the removal of all items which displayed even moderate DIF. There may be any number of reasons why an item displaying DIF may be essential to the purposes of a test and therefore necessary to retain. In an applied setting item removal should only occur after a thorough consideration of all item aspects as they relate to the purposes of the test has occurred. “If an item in a test displays DIF, one should try to find the source of the DIF, because it is not necessarily a bad item. An item might display DIF if it has a different item format than the rest of the items in the test (Longford et al., 1993). Another possibility is that the item measures an ability different from the one measured in the test or reflects that two groups have learned something with different pedagogical methods, hence making an item easier for one of the groups (Camilli, 2006). If it really is an item that favors one group, conditional on the ability, there are some strategies that one can apply. The most common ones are a) rewrite the item b) remove the item c) control for the underlying differences using an IRT model for scoring respondents. If however the item is kept in the test the test constructor should have a reason for that decision.” (Wiberg, 2007, p. 32). 90 91 Implications for Future Studies Rogers & Swaminathan (1993) found that detection rates for DIF differed depending on whether the item had a low, moderate, or high level of difficulty. Item difficulty was not addressed in this study; future studies comparing DIF detection methods may benefit by item difficulty analyses to determine if any differences found between the MH and LR methods may be a result of item difficulty levels within the test. Recently some discussion has begun concerning the use of practical significance assessments of adverse impact findings. Biddle (2010) suggests that employers should “tread carefully” in regards to practical significance of adverse impact findings, and that “hard-and-fast” practical significance rules should not be applied when analyzing adverse impact. Future research may be needed on the appropriateness of practical significance tests of adverse impact before making strong assumptions about the ability of particular DIF detection methods for item removal to reduce practically significant adverse impact findings. While the MH method used in this study did identify more assessments displaying DIF than the LR method, the items identified by both methods appeared to be in alignment (e.g., all items identified as displaying DIF with the LR method were also identified by the MH method). This indicates that the application of either a more lenient classification system with the LR method or a more stringent classification system with the MH method may have resulted in similar DIF identification results. Future research should be undertaken to compare various classification systems of DIF with these methods; there may be reason to believe that the results of this study which indicate that 91 92 the MH method identifies more assessments displaying DIF may be attributed to the classification system used rather than the methodology of the processes themselves. 92 93 APPENDICES 93 94 APPENDIX A Item Means and Standard Deviations Table A1 ____________________________________________________ Item # Mean SD N ____________________________________________________ Item 1 Item 2 Item 3 Item 4 Item 5 Item 6 Item 7 Item 8 Item 9 Item 10 Item 11 Item 12 Item 13 Item 14 Item 15 Item 16 Item 17 Item 18 Item 19 Item 20 Item 21 Item 22 Item 23 Item 24 Item 25 Item 26 Item 27 Item 28 Item 29 Item 30 Item 31 Item 32 Item 33 Item 34 0.8853 0.8272 0.9317 0.8605 0.7383 0.8545 0.9384 0.6981 0.5928 0.7942 0.6042 0.7183 0.8638 0.9802 0.6232 0.9530 0.7453 0.8570 0.7669 0.7629 0.7611 0.8804 0.8255 0.8307 0.7282 0.7687 0.9351 0.8899 0.9037 0.8611 0.7866 0.8625 0.6370 0.8581 0.3186 0.3781 0.2522 0.3464 0.4395 0.3526 0.2405 0.4591 0.4913 0.4043 0.4890 0.4498 0.3430 0.1394 0.4846 0.2116 0.4357 0.3500 0.4228 0.4253 0.4264 0.3245 0.3796 0.3750 0.4449 0.4217 0.2464 0.3130 0.2950 0.3459 0.4097 0.3444 0.4809 0.3490 29171 29169 29171 29170 29171 29170 29170 29170 29171 29169 29171 29170 29171 29170 29171 29170 29170 29169 29168 29154 29167 29167 29167 29167 29166 29167 29166 29167 29167 29165 29167 29166 29164 29164 94 95 ____________________________________________________ Item # Mean SD N ____________________________________________________ Item 35 Item 36 Item 37 Item 38 Item 39 Item 40 Item 41 Item 42 Item 43 Item 44 Item 45 Item 46 Item 47 Item 48 Item 49 0.8648 0.9184 0.8345 0.9101 0.8821 0.9260 0.6981 0.7538 0.9335 0.7665 0.9183 0.9503 0.6396 0.9298 0.7498 0.3420 0.2738 0.3716 0.2861 0.3225 0.2618 0.4591 0.4308 0.2491 0.4231 0.2739 0.2174 0.4801 0.2555 0.4331 29166 29167 29166 29163 29166 29147 29158 29158 29159 29158 29171 29157 29159 29159 29158 _____________________________________________________ 95 96 APPENDIX B MH DIF Values and Classification Level by Item Table A2 Item # 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 4 4 4 4 4 4 4 4 5 5 5 5 5 5 5 Comparison Group Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female MH CHI 7.6329 0.5673 2.8002 0.1426 6.5140 1.2694 4.4911 5.7022 0.6360 1.4704 1.9063 0.0000 17.4479 0.0564 6.5363 0.0312 19.7283 2.0049 9.3948 1.3957 0.3799 0.0014 190.3507 7.6473 2.5397 1.0546 0.0002 1.4825 0.9996 4.0262 70.8068 0.8472 10.8096 2.1012 87.2016 0.8305 1.5649 0.0009 0.6779 MH LOR LOR SE LOR Z 0.3348 0.1201 2.7877 -0.1161 0.1414 -0.8211 0.0728 0.0431 1.6891 -0.1177 0.2387 -0.4931 -0.1953 0.0760 -2.5697 0.2760 0.2237 1.2338 -0.0898 0.0421 -2.1330 0.1103 0.0460 2.3978 0.0940 0.1094 0.8592 0.1332 0.1045 1.2746 -0.0484 0.0345 -1.4029 -0.0167 0.1783 -0.0937 -0.2658 0.0630 -4.2190 0.0674 0.1992 0.3384 -0.0886 0.0345 -2.5681 -0.0073 0.0375 -0.1947 0.6076 0.1365 4.4513 0.2326 0.1559 1.4920 0.1631 0.0531 3.0716 -0.4603 0.3486 -1.3204 0.0589 0.0892 0.6603 -0.0378 0.3187 -0.1186 -0.8136 0.0601 -13.5374 0.1583 0.0570 2.7772 0.1900 0.1148 1.6551 0.1207 0.1112 1.0854 -0.0011 0.0366 -0.0301 0.2259 0.1744 1.2953 0.0638 0.0621 1.0274 -0.5756 0.2725 -2.1123 -0.3232 0.0385 -8.3948 -0.0380 0.0405 -0.9383 0.3417 0.1021 3.3467 0.1468 0.0987 1.4873 0.2933 0.0314 9.3408 0.1603 0.1625 0.9865 0.0712 0.0555 1.2829 -0.0237 0.1897 -0.1249 0.0265 0.0315 0.8413 96 BD 1.653 0.008 5.269 0.000 0.621 0.002 3.046 6.108 1.067 0.850 4.916 0.060 3.545 0.084 4.160 3.096 1.033 0.074 2.516 0.013 0.056 0.293 3.719 3.349 0.856 0.193 0.003 0.343 0.732 0.345 0.087 0.000 0.382 0.519 3.331 0.069 1.451 0.143 4.840 ETS CDR Classification Flag A OK A Flag A OK A Flag A OK A OK A Flag A OK A OK A OK A OK A Flag A OK A Flag A OK A Flag B OK A Flag A OK A OK A OK A Flag C Flag A OK A OK A OK A OK A OK A OK B Flag A OK A Flag A OK A Flag A OK A OK A OK A OK A 97 Item # 5 6 6 6 6 6 6 6 6 7 7 7 7 7 7 7 7 8 8 8 8 8 8 8 8 9 9 9 9 9 9 9 9 10 10 10 10 10 10 10 10 11 11 11 11 Comparison Group African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian MH CHI 110.3216 1.2442 0.1187 0.0538 2.2497 2.7840 0.0128 9.8320 0.8664 1.2969 1.2174 73.2346 0.5304 18.6170 2.1867 33.4078 72.5511 3.8260 3.3330 80.3454 6.0626 2.0086 0.2106 13.0895 94.0084 13.1920 0.9109 3.4921 0.5859 6.1157 0.8164 24.2685 12.7124 20.3974 43.1554 520.3883 8.6821 97.8521 10.3165 402.6554 550.1581 33.6978 0.8928 39.5689 0.8207 MH LOR LOR SE LOR Z 0.3541 0.0338 10.4763 0.1366 0.1163 1.1745 -0.0494 0.1222 -0.4043 -0.0097 0.0386 -0.2513 -0.3631 0.2273 -1.5974 0.1068 0.0631 1.6926 0.0496 0.2191 0.2264 -0.1204 0.0383 -3.1436 -0.0398 0.0419 -0.9499 -0.1905 0.1583 -1.2034 -0.2015 0.1702 -1.1839 -0.4744 0.0557 -8.5171 -0.2480 0.2878 -0.8617 -0.4151 0.0956 -4.3421 -0.5456 0.3402 -1.6038 -0.3324 0.0572 -5.8112 -0.5188 0.0611 -8.4910 -0.1940 0.0965 -2.0104 -0.1701 0.0907 -1.8754 -0.2567 0.0286 -8.9755 -0.3947 0.1564 -2.5237 -0.0710 0.0491 -1.4460 0.0917 0.1690 0.5426 0.1036 0.0285 3.6351 -0.3068 0.0317 -9.6782 0.3279 0.0891 3.6801 -0.0818 0.0825 -0.9915 0.0490 0.0260 1.8846 0.1106 0.1329 0.8322 -0.1159 0.0463 -2.5032 -0.1658 0.1670 -0.9928 0.1295 0.0262 4.9427 0.1033 0.0288 3.5868 0.5226 0.1136 4.6004 0.6822 0.1059 6.4419 0.8192 0.0365 22.4438 0.5623 0.1844 3.0493 0.5755 0.0593 9.7049 0.6468 0.1982 3.2634 0.6711 0.0339 19.7965 0.8905 0.0386 23.0699 -0.5444 0.0944 -5.7669 -0.0805 0.0820 -0.9817 -0.1641 0.0261 -6.2874 -0.1312 0.1350 -0.9719 97 BD 9.624 0.083 0.003 0.030 0.022 0.946 0.204 0.231 0.201 0.088 0.168 7.774 0.066 3.228 0.010 6.063 7.896 1.906 0.263 3.586 0.003 3.031 0.003 10.736 3.319 1.476 0.051 27.419 0.149 6.336 0.882 4.251 26.972 1.277 2.550 8.776 0.150 25.338 0.010 27.728 9.240 0.460 0.235 0.746 0.004 ETS CDR Classification Flag A OK A OK A OK A OK A OK A OK A Flag A OK A OK A OK A Flag B OK A Flag A OK A Flag A Flag B OK A OK A Flag A Flag A OK A OK A Flag A Flag A Flag A OK A Flag A OK A Flag A OK A Flag A Flag A Flag B Flag C Flag C Flag B Flag B Flag B Flag C Flag C Flag B OK A Flag A OK A 98 Item # 11 11 11 11 12 12 12 12 12 12 12 12 13 13 13 13 13 13 13 13 14 14 14 14 14 14 14 14 15 15 15 15 15 15 15 15 16 16 16 16 16 16 16 16 17 Comparison Group Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian MH CHI 1.7030 4.8206 2.4494 40.1383 13.2069 0.5121 20.9173 2.9070 5.6643 2.3182 70.2999 15.0035 6.7945 5.5269 82.1253 0.2960 5.6447 5.7626 41.2868 90.5703 0.8288 0.0156 4.6217 0.2686 0.2232 0.2630 11.4512 10.6201 0.0356 0.0001 16.5709 4.4212 23.7308 0.1685 26.6199 6.2316 75.6019 0.2711 49.7746 0.0164 24.9067 15.1942 5.9341 32.6918 1.8446 MH LOR LOR SE LOR Z -0.0602 0.0454 -1.3260 -0.3855 0.1693 -2.2770 -0.0416 0.0264 -1.5758 -0.1837 0.0290 -6.3345 -0.3741 0.1020 -3.6676 0.0696 0.0907 0.7674 -0.1340 0.0292 -4.5890 -0.2794 0.1577 -1.7717 -0.1218 0.0507 -2.4024 -0.2980 0.1847 -1.6134 -0.2511 0.0299 -8.3980 -0.1246 0.0321 -3.8816 -0.3315 0.1256 -2.6393 -0.3100 0.1280 -2.4219 -0.3549 0.0391 -9.0767 -0.1290 0.2002 -0.6444 -0.1550 0.0647 -2.3957 -0.6328 0.2574 -2.4584 -0.2530 0.0394 -6.4213 -0.4141 0.0434 -9.5415 0.2460 0.2346 1.0486 0.0829 0.2986 0.2776 -0.2238 0.1025 -2.1834 -0.5561 0.7137 -0.7792 0.0817 0.1487 0.5494 0.3332 0.4389 0.7592 -0.3457 0.1011 -3.4194 -0.3631 0.1116 -3.2536 -0.0221 0.0944 -0.2341 0.0032 0.0875 0.0366 0.1127 0.0276 4.0833 0.3018 0.1402 2.1526 0.2304 0.0474 4.8608 0.0856 0.1722 0.4971 -0.1465 0.0283 -5.1767 0.0767 0.0305 2.5148 1.2681 0.1595 7.9505 0.1588 0.2456 0.6466 0.5602 0.0797 7.0289 -0.1859 0.5060 -0.3674 0.5695 0.1150 4.9522 1.1208 0.2985 3.7548 -0.1663 0.0673 -2.4710 0.4797 0.0837 5.7312 -0.1400 0.1005 -1.3930 98 BD 0.234 0.246 0.090 0.009 0.002 0.652 2.973 0.004 0.121 0.090 2.383 6.036 0.010 0.347 2.046 0.020 0.285 0.004 1.993 3.766 0.223 0.056 0.635 0.025 0.780 0.000 0.033 0.551 1.139 0.468 1.789 0.144 13.767 0.006 1.228 0.012 26.031 0.154 0.064 0.147 0.365 1.226 0.020 0.002 2.283 ETS CDR Classification OK A OK A OK A Flag A Flag A OK A Flag A OK A Flag A OK A Flag A Flag A Flag A Flag A Flag A OK A Flag A Flag B Flag A Flag A OK A OK A OK A OK A OK A OK A Flag A Flag A OK A OK A Flag A OK A Flag A OK A Flag A Flag A Flag C OK A Flag B OK A Flag B Flag C Flag A Flag B OK A 99 Item # 17 17 17 17 17 17 17 18 18 18 18 18 18 18 18 19 19 19 19 19 19 19 19 20 20 20 20 20 20 20 20 21 21 21 21 21 21 21 21 22 22 22 22 22 22 Comparison Group Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian MH CHI 0.3673 0.3728 1.3236 4.2266 0.1160 5.9819 0.0022 0.6763 2.4090 1.1207 0.0577 0.9921 4.5873 4.5800 1.8145 0.2904 13.2235 203.0315 0.0058 26.1497 7.4117 107.9905 240.7583 11.0258 51.0234 317.0217 1.2289 42.2156 0.1043 34.2901 315.3005 8.7910 5.7641 35.1764 1.6152 0.0522 0.0003 33.6385 54.3611 5.0090 1.9655 21.5248 1.6389 1.1242 0.9495 MH LOR LOR SE LOR Z 0.0610 0.0935 0.6524 -0.0187 0.0300 -0.6233 -0.2002 0.1633 -1.2260 -0.1093 0.0527 -2.0740 0.0778 0.1796 0.4332 -0.0745 0.0303 -2.4587 -0.0021 0.0327 -0.0642 0.1012 0.1156 0.8754 0.1847 0.1141 1.6188 -0.0414 0.0384 -1.0781 0.0655 0.1931 0.3392 -0.0673 0.0655 -1.0275 -0.5613 0.2569 -2.1849 0.0809 0.0374 2.1631 -0.0573 0.0418 -1.3708 0.0639 0.1072 0.5961 0.3522 0.0958 3.6764 0.4470 0.0314 14.2357 0.0273 0.1694 0.1612 0.2768 0.0538 5.1450 0.5021 0.1788 2.8082 0.3181 0.0306 10.3954 0.5238 0.0338 15.4970 -0.3447 0.1026 -3.3596 -0.7623 0.1087 -7.0129 -0.5439 0.0307 -17.7166 -0.1800 0.1529 -1.1772 -0.3438 0.0528 -6.5114 -0.0746 0.1795 -0.4156 -0.1810 0.0308 -5.8766 -0.6080 0.0344 -17.6744 -0.3355 0.1124 -2.9849 0.2248 0.0919 2.4461 0.1781 0.0300 5.9367 0.2040 0.1510 1.3510 -0.0135 0.0533 -0.2533 -0.0149 0.1899 -0.0785 0.1730 0.0298 5.8054 0.2419 0.0327 7.3976 -0.3111 0.1351 -2.3027 -0.1884 0.1305 -1.4437 -0.1900 0.0410 -4.6341 -0.3096 0.2282 -1.3567 -0.0737 0.0679 -1.0854 -0.2596 0.2424 -1.0710 99 BD 0.182 11.608 0.000 2.295 0.017 0.191 14.437 1.351 0.228 0.000 0.046 0.260 0.062 0.466 0.062 0.821 0.038 1.563 0.107 0.246 0.070 2.313 0.721 0.282 0.107 1.036 0.059 0.319 0.227 18.626 1.493 0.220 0.124 1.357 0.001 8.291 0.002 0.129 0.275 0.025 1.036 1.452 0.137 2.137 0.138 ETS CDR Classification OK A Flag A OK A OK A OK A Flag A Flag A OK A OK A OK A OK A OK A OK B OK A OK A OK A Flag A Flag B OK A Flag A Flag B Flag A Flag B Flag A Flag C Flag B OK A Flag A OK A Flag A Flag B Flag A Flag A Flag A OK A Flag A OK A Flag A Flag A OK A OK A Flag A OK A OK A OK A 100 Item # 22 22 23 23 23 23 23 23 23 23 24 24 24 24 24 24 24 24 25 25 25 25 25 25 25 25 26 26 26 26 26 26 26 26 27 27 27 27 27 27 27 27 28 28 28 Comparison Group Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian MH CHI 5.2473 26.9158 4.0924 8.8836 59.4804 0.1056 0.0368 0.3809 4.0119 83.5781 2.5749 2.8039 36.9827 0.1845 0.0299 0.3525 1.3996 49.4233 11.2522 0.4047 1.6605 1.7818 0.5255 3.5609 27.5269 0.0883 1.7256 0.5134 131.8035 3.1769 6.4987 7.6384 176.5991 172.9213 2.4068 0.0290 29.6966 1.5732 4.1932 0.0083 1.0636 31.0061 9.3194 0.0722 43.6632 MH LOR LOR SE LOR Z -0.0946 0.0410 -2.3073 -0.2331 0.0450 -5.1800 0.2297 0.1109 2.0712 0.3196 0.1049 3.0467 0.2696 0.0348 7.7471 0.0780 0.1852 0.4212 0.0138 0.0618 0.2233 0.1523 0.2077 0.7333 -0.0700 0.0346 -2.0231 0.3428 0.0375 9.1413 -0.1945 0.1159 -1.6782 -0.1969 0.1137 -1.7318 -0.2154 0.0354 -6.0847 -0.0949 0.1832 -0.5180 -0.0119 0.0586 -0.2031 0.1308 0.1914 0.6834 -0.0423 0.0351 -1.2051 -0.2745 0.0390 -7.0385 0.3163 0.0932 3.3938 0.0607 0.0895 0.6782 0.0377 0.0288 1.3090 0.2015 0.1430 1.4091 0.0374 0.0499 0.7495 0.3284 0.1676 1.9594 -0.1545 0.0294 -5.2551 0.0101 0.0320 0.3156 0.1497 0.1084 1.3810 0.0831 0.1072 0.7752 0.3792 0.0331 11.4562 0.3338 0.1735 1.9239 0.1482 0.0575 2.5774 0.5081 0.1823 2.7872 0.4252 0.0322 13.2050 0.4610 0.0353 13.0595 0.2595 0.1598 1.6239 0.0486 0.1842 0.2638 0.3119 0.0574 5.4338 0.3847 0.2728 1.4102 0.1945 0.0934 2.0824 -0.0229 0.3222 -0.0711 -0.0569 0.0539 -1.0557 0.3386 0.0609 5.5599 0.3790 0.1257 3.0151 0.0487 0.1438 0.3387 0.3011 0.0454 6.6322 100 BD 0.279 0.137 0.787 1.124 0.071 0.054 0.011 0.348 2.130 0.637 0.718 0.071 2.553 0.003 1.022 0.418 6.145 2.816 0.027 1.030 2.983 0.003 0.621 0.039 3.998 5.220 0.912 0.392 3.381 1.982 0.081 0.530 9.821 14.259 0.985 0.199 1.436 0.007 0.346 0.322 1.796 1.145 13.444 0.347 0.645 ETS CDR Classification Flag A Flag A OK A Flag A Flag A OK A OK A OK A OK A Flag A OK A OK A Flag A OK A OK A OK A Flag A Flag A Flag A OK A OK A OK A OK A OK A Flag A Flag A OK A OK A Flag A OK A Flag A Flag B Flag A Flag B OK A OK A Flag A OK A OK A OK A OK A Flag A Flag A OK A Flag A 101 Item # 28 28 28 28 28 29 29 29 29 29 29 29 29 30 30 30 30 30 30 30 30 31 31 31 31 31 31 31 31 32 32 32 32 32 32 32 32 33 33 33 33 33 33 33 33 Comparison Group American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian MH CHI 2.2645 17.0406 0.1172 4.8695 38.6236 0.0032 0.1313 0.3482 0.0379 0.3263 0.2454 1.0554 0.2839 0.5293 1.2819 12.9435 0.0033 0.0912 0.0318 42.8949 15.1075 6.5747 9.0356 7.5341 0.2862 9.2041 4.4873 85.4549 33.9164 2.3701 0.2031 28.0935 0.0026 3.0174 0.0106 6.3864 34.1811 10.8524 2.6715 65.9624 0.1460 1.7003 0.0072 0.4773 82.6203 MH LOR LOR SE LOR Z 0.3518 0.2186 1.6093 0.3047 0.0734 4.1512 0.1164 0.2495 0.4665 0.0954 0.0428 2.2290 0.3037 0.0487 6.2361 0.0173 0.1376 0.1257 -0.0644 0.1471 -0.4378 -0.0280 0.0458 -0.6114 -0.0770 0.2449 -0.3144 -0.0466 0.0769 -0.6060 -0.1705 0.2720 -0.6268 -0.0472 0.0449 -1.0512 -0.0275 0.0495 -0.5556 -0.0972 0.1235 -0.7870 -0.1519 0.1266 -1.1998 -0.1422 0.0393 -3.6183 -0.0324 0.2035 -0.1592 -0.0221 0.0657 -0.3364 -0.0644 0.2239 -0.2876 0.2478 0.0378 6.5556 -0.1675 0.0429 -3.9044 -0.3019 0.1159 -2.6048 -0.3524 0.1163 -3.0301 0.0932 0.0337 2.7656 0.1108 0.1753 0.6321 -0.1858 0.0606 -3.0660 -0.4522 0.2116 -2.1371 0.3031 0.0327 9.2691 0.2106 0.0360 5.8500 0.1930 0.1205 1.6017 0.0621 0.1211 0.5128 0.2021 0.0379 5.3325 0.0102 0.2022 0.0504 0.1155 0.0652 1.7715 0.0034 0.2315 0.0147 -0.0963 0.0378 -2.5476 0.2415 0.0410 5.8902 -0.3133 0.0940 -3.3330 -0.1445 0.0858 -1.6841 -0.2202 0.0271 -8.1255 0.0602 0.1353 0.4449 -0.0620 0.0467 -1.3276 -0.0282 0.1674 -0.1685 0.0191 0.0271 0.7048 -0.2739 0.0301 -9.0997 101 BD 0.029 0.772 0.389 1.085 0.152 0.075 0.530 0.003 0.022 1.465 0.000 2.234 0.180 0.030 0.236 0.896 0.019 1.461 0.038 0.315 0.800 1.187 0.040 1.808 0.170 0.835 0.020 1.752 0.647 0.022 0.122 1.260 0.010 0.005 0.433 0.708 1.240 0.241 0.088 0.603 0.583 0.142 0.039 0.069 2.387 ETS CDR Classification OK A Flag A OK A OK A Flag A OK A OK A OK A OK A OK A OK A OK A OK A OK A OK A Flag A OK A OK A OK A Flag A Flag A Flag A Flag A Flag A OK A Flag A OK B Flag A Flag A OK A OK A Flag A OK A OK A OK A Flag A Flag A Flag A OK A Flag A OK A OK A OK A OK A Flag A 102 Item # 34 34 34 34 34 34 34 34 35 35 35 35 35 35 35 35 36 36 36 36 36 36 36 36 37 37 37 37 37 37 37 37 38 38 38 38 38 38 38 38 39 39 39 39 39 Comparison Group Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian MH CHI 10.9106 0.8379 151.5159 6.7812 14.3402 12.9722 3.5027 171.4637 2.4891 8.9142 180.2551 1.8022 21.4304 0.0531 120.0345 204.9177 2.3624 2.6072 68.1963 4.9203 45.6909 3.9345 6.0288 50.3235 0.8955 0.0184 62.8395 1.7043 12.9854 0.2553 15.7077 68.1385 6.9443 0.1396 13.8043 0.8858 7.4637 1.5254 8.2626 12.1489 0.8666 2.2702 1.0193 3.5026 0.0290 MH LOR LOR SE LOR Z -0.4115 0.1245 -3.3052 -0.1089 0.1126 -0.9671 -0.4607 0.0377 -12.2202 -0.5744 0.2185 -2.6288 -0.2430 0.0636 -3.8208 -0.9980 0.2834 -3.5215 -0.0707 0.0375 -1.8853 -0.5471 0.0421 -12.9952 -0.1964 0.1202 -1.6339 -0.3827 0.1269 -3.0158 -0.5232 0.0393 -13.3130 -0.2985 0.2075 -1.4386 -0.3059 0.0659 -4.6419 -0.0720 0.2134 -0.3374 -0.4482 0.0410 -10.9317 -0.6245 0.0440 -14.1932 0.2408 0.1505 1.6000 0.2689 0.1605 1.6754 0.4346 0.0531 8.1846 0.5574 0.2430 2.2938 0.5312 0.0805 6.5988 0.5554 0.2594 2.1411 0.1185 0.0480 2.4688 0.3953 0.0564 7.0089 -0.1131 0.1124 -1.0062 -0.0201 0.1068 -0.1882 -0.2811 0.0354 -7.9407 -0.2619 0.1896 -1.3813 -0.2230 0.0612 -3.6438 -0.1222 0.2036 -0.6002 -0.1412 0.0355 -3.9775 -0.3221 0.0390 -8.2590 -0.4354 0.1629 -2.6728 -0.0625 0.1409 -0.4436 -0.1669 0.0449 -3.7171 0.2224 0.2101 1.0585 -0.2182 0.0794 -2.7481 -0.4125 0.3063 -1.3467 -0.1335 0.0460 -2.9022 -0.1727 0.0494 -3.4960 0.1240 0.1240 1.0000 0.1918 0.1232 1.5568 -0.0435 0.0424 -1.0259 -0.5150 0.2600 -1.9808 0.0145 0.0704 0.2060 102 BD 1.105 0.106 0.073 0.050 0.460 0.021 0.000 0.865 0.577 0.008 2.204 0.012 0.263 0.476 1.094 3.119 1.069 0.594 31.930 0.227 25.894 0.064 13.908 36.408 0.310 0.120 0.472 0.007 0.438 0.036 0.205 0.669 0.448 0.016 1.657 0.156 1.931 0.380 0.105 0.465 0.678 0.558 0.195 0.001 2.019 ETS CDR Classification Flag A OK A Flag B Flag B Flag A Flag C OK A Flag B OK A Flag A Flag B OK A Flag A OK A Flag B Flag B OK A OK A Flag B OK B Flag B OK B Flag A Flag A OK A OK A Flag A OK A Flag A OK A Flag A Flag A Flag B OK A Flag A OK A Flag A OK A Flag A Flag A OK A OK A OK A OK A OK A 103 Item # 39 39 39 40 40 40 40 40 40 40 40 41 41 41 41 41 41 41 41 42 42 42 42 42 42 42 42 43 43 43 43 43 43 43 43 44 44 44 44 44 44 44 44 45 45 Comparison Group Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian MH CHI 1.2014 2.5388 2.5582 3.6565 4.9895 47.5060 0.0153 5.2155 0.3737 11.0548 48.5086 7.8076 0.2801 45.3010 0.0248 0.9660 0.0306 35.0741 62.1709 0.1099 2.1091 109.5007 1.9700 10.6218 0.1329 5.0608 143.5730 4.0190 0.1200 15.1501 3.2843 19.4826 17.0158 0.0000 6.3793 1.2638 2.3017 0.7990 0.0048 2.5731 1.0851 14.5052 0.4279 11.1270 0.0081 MH LOR LOR SE LOR Z 0.2545 0.2138 1.1904 -0.0667 0.0414 -1.6111 -0.0738 0.0457 -1.6149 -0.3135 0.1586 -1.9767 -0.3968 0.1734 -2.2884 -0.3550 0.0516 -6.8798 -0.0004 0.2545 -0.0016 -0.1996 0.0853 -2.3400 -0.2218 0.2922 -0.7591 -0.1719 0.0514 -3.3444 -0.3916 0.0564 -6.9433 -0.2802 0.0983 -2.8505 0.0516 0.0895 0.5765 -0.1941 0.0289 -6.7163 0.0351 0.1494 0.2349 -0.0496 0.0494 -1.0040 -0.0435 0.1701 -0.2557 -0.1739 0.0293 -5.9352 -0.2514 0.0320 -7.8562 0.0373 0.0979 0.3810 0.1369 0.0919 1.4897 -0.3271 0.0313 -10.4505 -0.2424 0.1636 -1.4817 -0.1765 0.0534 -3.3052 -0.0844 0.1838 -0.4592 0.0693 0.0307 2.2573 -0.4168 0.0348 -11.9770 0.3123 0.1522 2.0519 0.0760 0.1761 0.4316 0.2198 0.0563 3.9041 0.4958 0.2562 1.9352 0.3842 0.0867 4.4314 0.9480 0.2335 4.0600 0.0017 0.0531 0.0320 0.1537 0.0605 2.5405 -0.1272 0.1070 -1.1888 -0.1677 0.1054 -1.5911 -0.0291 0.0319 -0.9122 0.0023 0.1662 0.0138 -0.0916 0.0558 -1.6416 -0.2278 0.1990 -1.1447 0.1207 0.0315 3.8317 0.0232 0.0345 0.6725 -0.5937 0.1755 -3.3829 0.0253 0.1517 0.1668 103 BD 0.284 0.666 0.129 0.009 0.037 1.446 0.147 3.702 0.089 0.246 0.687 0.005 0.003 1.219 0.206 0.440 0.221 3.358 4.385 0.640 0.222 22.404 0.002 6.178 0.060 3.623 28.597 1.336 0.073 4.388 0.007 0.539 0.188 0.060 6.336 2.543 1.510 5.089 0.068 4.114 0.198 1.305 1.143 0.425 0.306 ETS CDR Classification OK A OK A OK A OK A OK A Flag A OK A Flag A OK A Flag A Flag A Flag A OK A Flag A OK A OK A OK A Flag A Flag A OK A OK A Flag A OK A Flag A OK A Flag A Flag A OK A OK A Flag A OK A Flag A Flag C OK A Flag A OK A OK A Flag A OK A OK A OK A Flag A OK A Flag B OK A 104 Item # 45 45 45 45 45 45 46 46 46 46 46 46 46 46 47 47 47 47 47 47 47 47 48 48 48 48 48 48 48 48 49 49 49 49 49 49 49 49 Comparison Group Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian MH CHI 10.2223 0.6418 2.1424 0.0464 7.3001 8.6026 7.7537 0.2268 10.0576 0.8335 2.6467 0.3565 2.8326 9.4407 52.5346 17.4978 1,182.3783 1.1434 283.6459 21.0493 275.4469 1,219.1791 0.2834 0.0131 14.1285 0.0108 0.4386 0.1463 49.6821 16.5381 8.8995 1.4765 46.8025 0.0214 0.0001 2.1503 24.2932 86.6831 MH LOR LOR SE LOR Z -0.1618 0.0502 -3.2231 0.2231 0.2383 0.9362 -0.1283 0.0846 -1.5165 -0.0980 0.2782 -0.3523 -0.1349 0.0495 -2.7253 -0.1605 0.0541 -2.9667 -0.5994 0.2140 -2.8009 0.1052 0.1828 0.5755 -0.1998 0.0626 -3.1917 0.3170 0.2887 1.0980 -0.1749 0.1044 -1.6753 -0.2834 0.3683 -0.7695 -0.1059 0.0617 -1.7164 -0.2089 0.0676 -3.0902 0.6824 0.0981 6.9562 0.3835 0.0929 4.1281 0.9929 0.0293 33.8874 0.1929 0.1643 1.1741 0.8319 0.0506 16.4407 0.7691 0.1752 4.3898 0.4852 0.0294 16.5034 1.0835 0.0317 34.1798 0.0992 0.1607 0.6173 0.0346 0.1734 0.1995 0.2077 0.0554 3.7491 0.0736 0.2913 0.2527 0.0652 0.0922 0.7072 0.1522 0.2871 0.5301 0.3538 0.0506 6.9921 0.2358 0.0585 4.0308 0.2881 0.0958 3.0073 -0.1211 0.0964 -1.2562 -0.2107 0.0308 -6.8409 0.0331 0.1512 0.2189 0.0009 0.0519 0.0173 -0.2950 0.1900 -1.5526 -0.1538 0.0311 -4.9453 -0.3212 0.0345 -9.3101 BD 3.395 0.084 3.493 0.047 0.297 2.718 0.022 0.301 0.001 0.315 0.054 0.018 1.347 0.007 41.559 8.415 56.713 0.624 32.145 6.208 6.551 116.070 0.001 0.647 13.809 0.000 0.466 0.030 31.868 22.164 1.440 0.205 0.043 1.477 0.016 0.000 0.007 0.973 ETS CDR Classification Flag A OK A OK A OK A Flag A Flag A Flag B OK A Flag A OK A OK A OK A OK A Flag A Flag C Flag A Flag C OK A Flag C Flag B Flag B Flag C OK A OK A Flag A OK A OK A OK A Flag A Flag A Flag A OK A Flag A OK A OK A OK A Flag A Flag A Table A2 Heading Descriptions Mantel-Haenszel Chi-Square (MH CHI) – The Mantel-Haenszel chi-square statistic (Holland & Thayer, 1988; Mantel & Haenszel, 1959) is distributed as chi-square with one degree of freedom. Critical values of this statistic are 3.84 for a Type I error rate of 0.05 and 6.63 for a Type I error rate of 0.01. 104 105 Mantel-Haenszel Common Log-Odds Ratio (MH LOR) – The Mantel-Haenszel common log-odds ratio (Camilli & Shepard, 1994; Mantel & Haenszel, 1959) is asymptotically normally distributed. Positive values indicate DIF in favor of the reference group, and negative values indicate DIF in favor of the focal groups. Standard Error of the Mantel-Haenszel Common Log-Odds Ratio (LOR SE) – The standard error of the Mantel-Haenszel common log-odds ratio. The standard error computed here is the non-symmetric estimator presented by Robins, Breslow and Greenland (1986). Standardized Mantel-Haenszel Log-Odds Ratio (LOR Z) – This is the MantelHaenszel log-odds ratio divided by the estimated standard error. A value greater than 2.0 or less than –2.0 may be considered evidence of the presence of DIF. Breslow-Day Chi-Square (BD) – The Breslow-Day chi-square test of trend in odds ratio heterogeneity (Breslow & Day, 1980; Penfield, 2003) is distributed as chisquare with one degree of freedom. Critical values of this statistic are 3.84 for a Type I error rate of 0.05 and 6.63 for a Type I error rate of 0.01. This statistic has been shown to be effective at detecting non-uniform DIF. Combined Decision Rule (CDR) – The combined decision rule (CDR) flags any item for which either the Mantel-Haenszel chi-square or the Breslow-Day chi-square statistic is significant at a Type I error rate of 0.025 (Penfield, 2003). The message OK is printed if neither statistic is significant, and the message FLAG is printed if either statistic is significant. The ETS Categorization Scheme (ETS Classification) – The ETS categorization scheme (Hidalgo & López-Pina, 2004; Zieky, 1993) categorizes items as having small (A), moderate (B), and large (C) levels of DIF. 105 106 APPENDIX C Nagelkerke R2 Values and DIF Classification Category by Item and Group Comparison Table A2 Item # 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 Comparison Group Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female Block 1 Nagelkerke R² 0.1780 0.1700 0.1870 0.1670 0.1720 0.1710 0.1870 0.1870 0.0790 0.0770 0.0910 0.0740 0.0780 0.0740 0.0910 0.0900 0.1070 0.0980 0.1170 0.0990 0.1100 0.1000 0.1170 Block 2 Nagelkerke R² 0.1800 0.1700 0.1880 0.1670 0.1720 0.1720 0.1870 0.1890 0.0790 0.0780 0.0910 0.0740 0.0790 0.0740 0.0910 0.0910 0.1100 0.0990 0.1190 0.0990 0.1100 0.1000 0.1330 Block 3 Nagelkerke R² 0.1810 0.1700 0.1910 0.1670 0.1740 0.1720 0.1870 0.1920 0.0790 0.0780 0.0920 0.0740 0.0800 0.0740 0.0920 0.0910 0.1110 0.0990 0.1200 0.0990 0.1110 0.1000 0.1330 106 Block 2 Significance Level 0.002** 0.753 0.000*** 0.719 0.043* 0.093 0.302 0.000*** 0.631 0.139 0.733 0.875 0.000*** 0.823 0.103 0.109 0.000*** 0.069 0.000*** 0.300 0.307 0.987 0.000*** Block 3 Significance Level 0.011* 0.973 0.000*** 0.513 0.000*** 0.889 0.034* 0.000*** 0.330 0.415 0.000*** 0.589 0.159 0.093 0.003** 0.000*** 0.044* 0.563 0.000*** 0.319 0.101 0.206 0.275 ETS Classification A A A A A A A A A A A A A A A A A A A A A A A 107 Item # 3 4 4 4 4 4 4 4 4 5 5 5 5 5 5 5 5 6 6 6 6 6 6 6 6 7 7 7 7 7 Comparison Group African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Block 1 Nagelkerke R² 0.1140 0.0370 0.0350 0.0310 0.0340 0.0340 0.0350 0.0320 0.0320 0.1960 0.1840 0.2330 0.1830 0.2090 0.1830 0.2310 0.2260 0.1560 0.1470 0.1820 0.1470 0.1580 0.1500 0.1820 0.1820 0.1250 0.1260 0.1480 0.1250 0.1340 Block 2 Nagelkerke R² 0.1160 0.0370 0.0360 0.0310 0.0340 0.0340 0.0350 0.0360 0.0320 0.1970 0.1850 0.2380 0.1830 0.2090 0.1830 0.2310 0.2340 0.1560 0.1470 0.1820 0.1480 0.1580 0.1500 0.1820 0.1820 0.1250 0.1260 0.1530 0.1250 0.1370 Block 3 Nagelkerke R² 0.1170 0.0370 0.0360 0.0330 0.0340 0.0350 0.0350 0.0360 0.0330 0.1970 0.1850 0.2400 0.1830 0.2090 0.1830 0.2310 0.2370 0.1560 0.1480 0.1840 0.1480 0.1600 0.1500 0.1820 0.1830 0.1260 0.1260 0.1530 0.1250 0.1370 107 Block 2 Significance Level 0.000*** 0.254 0.235 0.327 0.151 0.360 0.026* 0.000*** 0.849 0.001 0.076 0.000*** 0.233 0.116 0.982 0.058 0.000*** 0.294 0.885 0.028* 0.166 0.033* 0.553 0.033* 0.219 0.248 0.428 0.000*** 0.606 0.000*** Block 3 Significance Level 0.000*** 0.275 0.853 0.000*** 0.185 0.001 0.148 0.235 0.000*** 0.374 0.269 0.000*** 0.731 0.297 0.154 0.035* 0.000*** 0.144 0.497 0.000*** 0.458 0.000*** 0.338 0.242 0.000*** 0.035* 0.621 0.248 0.468 0.643 ETS Classification A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A 108 Item # 7 7 7 8 8 8 8 8 8 8 8 9 9 9 9 9 9 9 9 10 10 10 10 10 10 10 10 11 11 11 Comparison Group Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian Block 1 Nagelkerke R² 0.1240 0.1480 0.1440 0.1000 0.1010 0.0870 0.1000 0.1010 0.1010 0.0870 0.0850 0.0280 0.0240 0.0480 0.0240 0.0290 0.0250 0.0480 0.0480 0.2230 0.2060 0.2700 0.2050 0.2250 0.2070 0.2750 0.2800 0.0310 0.0350 0.0290 Block 2 Nagelkerke R² 0.1240 0.1500 0.1490 0.1010 0.1010 0.0880 0.1010 0.1010 0.1010 0.0880 0.0870 0.0290 0.0240 0.0490 0.0240 0.0290 0.0250 0.0490 0.0480 0.2250 0.2110 0.3060 0.2070 0.2350 0.2080 0.2950 0.3160 0.0350 0.0350 0.0310 Block 3 Nagelkerke R² 0.1240 0.1510 0.1490 0.1020 0.1010 0.0920 0.1010 0.1030 0.1010 0.0890 0.0920 0.0290 0.0240 0.0490 0.0240 0.0300 0.0250 0.0490 0.0490 0.2250 0.2110 0.3070 0.2070 0.2380 0.2080 0.2950 0.3180 0.0360 0.0350 0.0320 108 Block 2 Significance Level 0.165 0.000*** 0.000*** 0.003** 0.092 0.000*** 0.012* 0.130 0.799 0.000*** 0.000*** 0.000*** 0.278 0.015* 0.455 0.009** 0.225 0.000*** 0.000*** 0.000*** 0.000*** 0.000*** 0.001 0.000*** 0.001 0.000*** 0.000*** 0.000*** 0.335 0.000*** Block 3 Significance Level 0.930 0.051 0.365 0.006** 0.567 0.000*** 0.393 0.000*** 0.094 0.006** 0.000*** 0.567 0.338 0.010 0.195 0.146 0.060 0.013* 0.015* 0.683 0.223 0.000*** 0.225 0.000*** 0.853 0.075 0.000*** 0.001 0.130 0.000*** ETS Classification A A A A A A A A A A A A A A A A A A A A A B A A A A B A A A 109 Item # 11 11 11 11 11 12 12 12 12 12 12 12 12 13 13 13 13 13 13 13 13 14 14 14 14 14 14 14 14 15 Comparison Group American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Block 1 Nagelkerke R² 0.0360 0.0350 0.0360 0.0290 0.0300 0.0980 0.1050 0.1030 0.1030 0.1000 0.1030 0.1030 0.1070 0.1210 0.1220 0.1390 0.1210 0.1250 0.1190 0.1390 0.1390 0.2500 0.2280 0.2620 0.2300 0.2620 0.2320 0.2600 0.2480 0.1570 Block 2 Nagelkerke R² 0.0360 0.0350 0.0360 0.0290 0.0320 0.1000 0.1050 0.1030 0.1030 0.1010 0.1030 0.1050 0.1070 0.1220 0.1230 0.1430 0.1210 0.1250 0.1200 0.1410 0.1440 0.2530 0.2280 0.2620 0.2300 0.2630 0.2330 0.2620 0.2490 0.1570 Block 3 Nagelkerke R² 0.0360 0.0360 0.0360 0.0290 0.0330 0.1010 0.1050 0.1060 0.1030 0.1030 0.1030 0.1050 0.1100 0.1220 0.1230 0.1430 0.1210 0.1260 0.1200 0.1420 0.1440 0.2530 0.2280 0.2620 0.2300 0.2630 0.2330 0.2620 0.2490 0.1580 109 Block 2 Significance Level 0.380 0.116 0.009** 0.204 0.000*** 0.000*** 0.288 0.093 0.107 0.018* 0.058 0.000*** 0.18 0.003** 0.020* 0.000*** 0.552 0.016* 0.008** 0.000*** 0.000*** 0.030* 0.430 0.411 0.673 0.106 0.110 0.001 0.044* 0.451 Block 3 Significance Level 0.923 0.001 0.747 0.472 0.000*** 0.000*** 0.946 0.000*** 0.562 0.000*** 0.594 0.971 0.000*** 0.053 0.399 0.002** 0.986 0.001 0.526 0.021* 0.044* 0.574 0.974 0.442 0.692 0.763 0.313 0.590 0.340 0.000*** ETS Classification A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A 110 Item # 15 15 15 15 15 15 15 16 16 16 16 16 16 16 16 17 17 17 17 17 17 17 17 18 18 18 18 18 18 18 Comparison Group Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female Block 1 Nagelkerke R² 0.1550 0.1750 0.1550 0.1600 0.1560 0.1740 0.1810 0.3040 0.2980 0.3400 0.2950 0.3330 0.2940 0.3400 0.3380 0.1070 0.1090 0.1040 0.1080 0.1080 0.1100 0.1040 0.1040 0.1240 0.1230 0.1480 0.1200 0.1280 0.1170 0.1470 Block 2 Nagelkerke R² 0.1550 0.1760 0.1560 0.1610 0.1560 0.1740 0.1810 0.3390 0.2990 0.3510 0.2950 0.3430 0.3030 0.3400 0.3480 0.1080 0.1090 0.1040 0.1090 0.1090 0.1100 0.1040 0.1050 0.1250 0.1230 0.1480 0.1200 0.1280 0.1180 0.1470 Block 3 Nagelkerke R² 0.1550 0.1790 0.1560 0.1650 0.1570 0.1740 0.1840 0.3400 0.3000 0.3510 0.2960 0.3430 0.3030 0.3400 0.3480 0.1090 0.1090 0.1080 0.1090 0.1100 0.1100 0.1040 0.1090 0.1250 0.1230 0.1490 0.1200 0.1290 0.1180 0.1470 110 Block 2 Significance Level 0.942 0.000*** 0.028* 0.000*** 0.702 0.000*** 0.000*** 0.000*** 0.145 0.000*** 0.855 0.000*** 0.000*** 0.090 0.000*** 0.071 0.495 0.428 0.221 0.028* 0.757 0.129 0.235 0.373 0.065 0.619 0.597 0.394 0.016* 0.004** Block 3 Significance Level 0.035* 0.000*** 0.227 0.000*** 0.376 0.990 0.000*** 0.073 0.176 0.128 0.26 0.575 0.989 0.833 0.136 0.000*** 0.184 0.000*** 0.804 0.000*** 0.642 0.643 0.000*** 0.018* 0.741 0.000*** 0.672 0.005** 0.097 0.574 ETS Classification A A A A A A A B A A A A A A A A A A A A A A A A A A A A A A 111 Item # 18 19 19 19 19 19 19 19 19 20 20 20 20 20 20 20 20 21 21 21 21 21 21 21 21 22 22 22 22 22 Comparison Group African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Block 1 Nagelkerke R² 0.1470 0.0860 0.0830 0.1230 0.0800 0.0950 0.0830 0.1220 0.1260 0.0590 0.0580 0.0440 0.0610 0.0570 0.0620 0.0440 0.0420 0.0320 0.0340 0.0410 0.0340 0.0310 0.0340 0.0410 0.0460 0.1340 0.1290 0.1450 0.1310 0.1380 Block 2 Nagelkerke R² 0.1470 0.0860 0.0850 0.1350 0.0800 0.0970 0.0840 0.1280 0.1420 0.0610 0.0630 0.0580 0.0610 0.0610 0.0620 0.0450 0.0590 0.0340 0.0340 0.0430 0.0340 0.0310 0.0340 0.0420 0.0490 0.1350 0.1290 0.1460 0.1310 0.1380 Block 3 Nagelkerke R² 0.1480 0.0860 0.0850 0.1360 0.0800 0.0980 0.0840 0.1280 0.1430 0.0610 0.0630 0.0590 0.0610 0.0620 0.0620 0.0460 0.0610 0.0340 0.0350 0.0440 0.0340 0.0330 0.0340 0.0420 0.0500 0.1350 0.1300 0.1470 0.1310 0.1390 111 Block 2 Significance Level 0.869 0.884 0.000*** 0.000*** 0.917 0.000*** 0.007** 0.000*** 0.000*** 0.000*** 0.000*** 0.000*** 0.294 0.000*** 0.403 0.000*** 0.000*** 0.000*** 0.037* 0.000*** 0.277 0.343 0.624 0.000*** 0.000*** 0.006** 0.215 0.000*** 0.195 0.341 Block 3 Significance Level 0.001 0.362 0.752 0.000*** 0.162 0.014* 0.981 0.095 0.000*** 0.015* 0.175 0.000*** 0.392 0.002** 0.926 0.002** 0.000*** 0.153 0.118 0.000*** 0.403 0.000*** 0.501 0.558 0.000*** 0.142 0.026* 0.000*** 0.205 0.000*** ETS Classification A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A 112 Item # 22 22 22 23 23 23 23 23 23 23 23 24 24 24 24 24 24 24 24 25 25 25 25 25 25 25 25 26 26 26 Comparison Group Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian Block 1 Nagelkerke R² 0.1310 0.1430 0.1440 0.0830 0.0820 0.1060 0.0790 0.0870 0.0800 0.1070 0.1070 0.1130 0.1110 0.1230 0.1110 0.1210 0.1100 0.1230 0.1180 0.0330 0.0280 0.0450 0.0290 0.0320 0.0300 0.0440 0.0460 0.2070 0.2000 0.2450 Block 2 Nagelkerke R² 0.1310 0.1430 0.1460 0.0840 0.0830 0.1110 0.0790 0.0870 0.0800 0.1070 0.1130 0.1140 0.1110 0.1240 0.1110 0.1210 0.1110 0.1230 0.1200 0.0340 0.0280 0.0450 0.0290 0.0320 0.0300 0.0450 0.0460 0.2070 0.2000 0.2540 Block 3 Nagelkerke R² 0.1310 0.1430 0.1470 0.0840 0.0830 0.1120 0.0790 0.0870 0.0800 0.1070 0.1150 0.1140 0.1110 0.1250 0.1110 0.1220 0.1110 0.1230 0.1210 0.0340 0.0290 0.0450 0.0290 0.0320 0.0300 0.0450 0.0460 0.2070 0.2000 0.2560 112 Block 2 Significance Level 0.214 0.074 0.000*** 0.099 0.004** 0.000*** 0.784 0.976 0.629 0.219 0.000*** 0.048* 0.161 0.000*** 0.783 0.915 0.393 0.972 0.000*** 0.002** 0.573 0.218 0.179 0.633 0.065 0.000*** 0.732 0.389 0.329 0.000*** Block 3 Significance Level 0.072 0.944 0.000*** 0.082 0.502 0.000*** 0.975 0.063 0.613 0.429 0.000*** 0.122 0.942 0.000*** 0.788 0.009** 0.048* 0.057 0.000*** 0.452 0.038* 0.655 0.616 0.076 0.543 0.117 0.741 0.148 0.877 0.000*** ETS Classification A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A 113 Item # 26 26 26 26 26 27 27 27 27 27 27 27 27 28 28 28 28 28 28 28 28 29 29 29 29 29 29 29 29 30 Comparison Group American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Block 1 Nagelkerke R² 0.2000 0.2180 0.1980 0.2450 0.2420 0.1480 0.1370 0.1810 0.1400 0.1620 0.1380 0.1790 0.1800 0.1710 0.1630 0.2180 0.1640 0.1890 0.1630 0.2150 0.2190 0.1260 0.1230 0.1550 0.1200 0.1280 0.1200 0.1550 0.1560 0.1470 Block 2 Nagelkerke R² 0.2010 0.2190 0.1990 0.2450 0.2540 0.1480 0.1370 0.1850 0.1400 0.1630 0.1380 0.1790 0.1840 0.1720 0.1630 0.2220 0.1640 0.1910 0.1630 0.2160 0.2230 0.1260 0.1230 0.1550 0.1200 0.1280 0.1200 0.1550 0.1560 0.1470 Block 3 Nagelkerke R² 0.2010 0.2200 0.1990 0.2540 0.2570 0.1490 0.1380 0.1860 0.1400 0.1630 0.1380 0.1790 0.1850 0.1730 0.1630 0.2230 0.1640 0.1920 0.1630 0.2160 0.2240 0.1260 0.1240 0.1550 0.1200 0.1290 0.1200 0.1550 0.1560 0.1470 113 Block 2 Significance Level 0.040* 0.010 0.006** 0.000*** 0.000*** 0.095 0.689 0.000*** 0.166 0.024* 0.921 0.553 0.000*** 0.006** 0.662 0.000*** 0.105 0.000*** 0.677 0.003** 0.000*** 0.985 0.774 0.518 0.810 0.620 0.579 0.591 0.588 0.174 Block 3 Significance Level 0.007** 0.004** 0.170 0.180 0.000*** 0.144 0.312 0.007** 0.875 0.196 0.136 0.102 0.007** 0.001 0.225 0.001 0.742 0.035* 0.115 0.319 0.004** 0.170 0.261 0.009** 0.870 0.005** 0.861 0.265 0.041* 0.128 ETS Classification A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A 114 Item # 30 30 30 30 30 30 30 31 31 31 31 31 31 31 31 32 32 32 32 32 32 32 32 33 33 33 33 33 33 33 Comparison Group Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female Block 1 Nagelkerke R² 0.1430 0.1760 0.1420 0.1600 0.1420 0.1760 0.1710 0.1650 0.1570 0.2160 0.1590 0.1740 0.1570 0.2140 0.2150 0.0480 0.0460 0.0670 0.0450 0.0520 0.0440 0.0660 0.0670 0.0760 0.0780 0.0740 0.0760 0.0760 0.0780 0.0740 Block 2 Nagelkerke R² 0.1430 0.1770 0.1420 0.1600 0.1420 0.1790 0.1710 0.1650 0.1580 0.2170 0.1590 0.1750 0.1570 0.2180 0.2180 0.0490 0.0460 0.0700 0.0450 0.0520 0.0440 0.0670 0.0700 0.0770 0.0780 0.0760 0.0760 0.0760 0.0780 0.0740 Block 3 Nagelkerke R² 0.1430 0.1770 0.1420 0.1610 0.1420 0.1790 0.1720 0.1650 0.1580 0.2170 0.1590 0.1750 0.1580 0.2180 0.2190 0.0490 0.0460 0.0700 0.0450 0.0520 0.0440 0.0670 0.0710 0.0780 0.0780 0.0780 0.0770 0.0780 0.0780 0.0740 114 Block 2 Significance Level 0.216 0.020* 0.913 0.590 0.563 0.000*** 0.005** 0.005** 0.002** 0.000*** 0.613 0.003** 0.041* 0.000*** 0.000*** 0.230 0.610 0.000*** 0.830 0.129 0.833 0.035* 0.000*** 0.000*** 0.126 0.000*** 0.522 0.166 0.902 0.125 Block 3 Significance Level 0.978 0.001 0.809 0.180 0.258 0.449 0.001 0.867 0.536 0.002** 0.895 0.180 0.109 0.104 0.001 0.496 0.644 0.038* 0.940 0.178 0.021* 0.815 0.036* 0.030* 0.745 0.000*** 0.033* 0.000*** 0.886 0.351 ETS Classification A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A 115 Item # 33 34 34 34 34 34 34 34 34 35 35 35 35 35 35 35 35 36 36 36 36 36 36 36 36 37 37 37 37 37 Comparison Group African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Block 1 Nagelkerke R² 0.0750 0.1020 0.1060 0.0990 0.1060 0.1100 0.1050 0.0980 0.0970 0.1340 0.1290 0.1360 0.1300 0.1340 0.1320 0.1360 0.1290 0.2210 0.2090 0.2170 0.2110 0.2290 0.2160 0.2160 0.2160 0.1100 0.1080 0.1060 0.1070 0.1090 Block 2 Nagelkerke R² 0.0780 0.1040 0.1060 0.1070 0.1060 0.1120 0.1070 0.0980 0.1070 0.1350 0.1300 0.1460 0.1300 0.1370 0.1320 0.1430 0.1430 0.2220 0.2090 0.2250 0.2120 0.2370 0.2170 0.2170 0.2240 0.1110 0.1080 0.1080 0.1070 0.1100 Block 3 Nagelkerke R² 0.0800 0.1050 0.1060 0.1090 0.1070 0.1120 0.1070 0.0980 0.1090 0.1350 0.1300 0.1470 0.1300 0.1370 0.1320 0.1430 0.1430 0.2230 0.2100 0.2300 0.2120 0.2390 0.2170 0.2180 0.2290 0.1110 0.1080 0.1100 0.1070 0.1110 115 Block 2 Significance Level 0.000*** 0.000*** 0.371 0.000*** 0.006** 0.000*** 0.000*** 0.235 0.000*** 0.026* 0.002** 0.000*** 0.136 0.000*** 0.582 0.000*** 0.000*** 0.122 0.088 0.000*** 0.016* 0.000*** 0.023* 0.001 0.000*** 0.135 0.870 0.000*** 0.189 0.000*** Block 3 Significance Level 0.000*** 0.000*** 0.114 0.000*** 0.217 0.007** 0.234 0.433 0.000*** 0.347 0.505 0.000*** 0.859 0.014* 0.455 0.838 0.002** 0.026* 0.076 0.000*** 0.396 0.000*** 0.784 0.000*** 0.000*** 0.051 0.217 0.000*** 0.343 0.000*** ETS Classification A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A 116 Item # 37 37 37 38 38 38 38 38 38 38 38 39 39 39 39 39 39 39 39 40 40 40 40 40 40 40 40 41 41 41 Comparison Group Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian Block 1 Nagelkerke R² 0.1080 0.1060 0.1040 0.0460 0.0470 0.0540 0.0480 0.0470 0.0450 0.0540 0.0550 0.1730 0.1630 0.1900 0.1630 0.1820 0.1650 0.1880 0.1840 0.1290 0.1240 0.1550 0.1270 0.1480 0.1270 0.1540 0.1440 0.1280 0.1330 0.1270 Block 2 Nagelkerke R² 0.1080 0.1060 0.1060 0.0470 0.0470 0.0560 0.0480 0.0480 0.0460 0.0540 0.0570 0.1730 0.1640 0.1900 0.1640 0.1820 0.1650 0.1880 0.1840 0.1300 0.1250 0.1580 0.1270 0.1490 0.1270 0.1550 0.1480 0.1290 0.1330 0.1280 Block 3 Nagelkerke R² 0.1080 0.1060 0.1090 0.0470 0.0470 0.0560 0.0480 0.0480 0.0460 0.0540 0.0570 0.1730 0.1640 0.1920 0.1640 0.1830 0.1650 0.1880 0.1860 0.1300 0.1250 0.1580 0.1280 0.1490 0.1280 0.1550 0.1480 0.1310 0.1330 0.1320 116 Block 2 Significance Level 0.522 0.005** 0.000*** 0.002** 0.527 0.000*** 0.395 0.002** 0.086 0.002** 0.000*** 0.396 0.043* 0.151 0.084 0.528 0.127 0.741 0.306 0.051 0.029* 0.000*** 0.905 0.041* 0.565 0.002** 0.000*** 0.000*** 0.391 0.000*** Block 3 Significance Level 0.201 0.660 0.000*** 0.423 0.937 0.150 0.494 0.107 0.027* 0.974 0.322 0.080 0.072 0.000*** 0.876 0.018* 0.109 0.150 0.000*** 0.347 0.434 0.160 0.305 0.522 0.399 0.390 0.071 0.000*** 0.215 0.000*** ETS Classification A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A 117 Item # 41 41 41 41 41 42 42 42 42 42 42 42 42 43 43 43 43 43 43 43 43 44 44 44 44 44 44 44 44 45 Comparison Group American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Block 1 Nagelkerke R² 0.1330 0.1330 0.1310 0.1270 0.1280 0.1390 0.1370 0.1430 0.1360 0.1410 0.1370 0.1430 0.1410 0.1680 0.1590 0.1830 0.1600 0.1840 0.1630 0.1820 0.1790 0.1370 0.1340 0.1720 0.1310 0.1480 0.1310 0.1730 0.1660 0.1440 Block 2 Nagelkerke R² 0.1330 0.1330 0.1310 0.1280 0.1300 0.1390 0.1370 0.1470 0.1360 0.1420 0.1370 0.1430 0.1460 0.1690 0.1600 0.1850 0.1610 0.1880 0.1670 0.1820 0.1800 0.1370 0.1340 0.1720 0.1310 0.1480 0.1310 0.1740 0.1660 0.1470 Block 3 Nagelkerke R² 0.1330 0.1350 0.1320 0.1280 0.1330 0.1400 0.1370 0.1480 0.1360 0.1430 0.1370 0.1430 0.1470 0.1700 0.1600 0.1870 0.1610 0.1890 0.1670 0.1820 0.1820 0.1370 0.1340 0.1720 0.1310 0.1480 0.1310 0.1740 0.1670 0.1470 117 Block 2 Significance Level 0.714 0.260 0.620 0.000*** 0.000*** 0.664 0.084 0.000*** 0.202 0.001 0.433 0.000*** 0.000*** 0.047* 0.542 0.000*** 0.051 0.000*** 0.000*** 0.448 0.000*** 0.105 0.114 0.269 0.953 0.120 0.133 0.000*** 0.038* 0.000*** Block 3 Significance Level 0.535 0.000*** 0.008** 0.706 0.000*** 0.001 0.050 0.000*** 0.452 0.000*** 0.375 0.024* 0.000*** 0.050 0.525 0.000*** 0.858 0.029* 0.623 0.947 0.000*** 0.894 0.070 0.002** 0.487 0.672 0.718 0.377 0.000*** 0.672 ETS Classification A A A A A A A A A A A A A A A A A A A A A A A A A A A A A A 118 Item # 45 45 45 45 45 45 45 46 46 46 46 46 46 46 46 47 47 47 47 47 47 47 47 48 48 48 48 48 48 48 Comparison Group Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female Block 1 Nagelkerke R² 0.1470 0.1890 0.1450 0.1670 0.1450 0.1900 0.1830 0.1410 0.1460 0.1710 0.1450 0.1570 0.1430 0.1710 0.1690 0.2420 0.2340 0.2790 0.2360 0.2650 0.2350 0.2770 0.2810 0.2040 0.1860 0.2110 0.1890 0.2120 0.1910 0.2090 Block 2 Nagelkerke R² 0.1470 0.1900 0.1450 0.1670 0.1450 0.1900 0.1830 0.1430 0.1460 0.1720 0.1450 0.1570 0.1440 0.1720 0.1690 0.2460 0.2350 0.3280 0.2360 0.2840 0.2370 0.2880 0.3360 0.2040 0.1860 0.2130 0.1890 0.2130 0.1910 0.2130 Block 3 Nagelkerke R² 0.1470 0.1900 0.1450 0.1670 0.1450 0.1900 0.1840 0.1430 0.1460 0.1720 0.1460 0.1580 0.1440 0.1720 0.1700 0.2490 0.2360 0.3330 0.2360 0.2850 0.2380 0.2880 0.3420 0.2040 0.1860 0.2150 0.1890 0.2130 0.1910 0.2150 118 Block 2 Significance Level 0.602 0.038* 0.245 0.200 0.949 0.027* 0.090 0.002** 0.454 0.011* 0.261 0.099 0.566 0.186 0.016* 0.000*** 0.000*** 0.000*** 0.220 0.000*** 0.000*** 0.000*** 0.000*** 0.351 0.790 0.000*** 0.771 0.292 0.407 0.000*** Block 3 Significance Level 0.280 0.268 0.248 0.867 0.499 0.760 0.196 0.212 0.469 0.062 0.216 0.270 0.640 0.295 0.094 0.000*** 0.005** 0.000*** 0.134 0.000*** 0.013* 0.517 0.000*** 0.790 0.070 0.000*** 0.886 0.086 0.830 0.000*** ETS Classification A A A A A A A A A A A A A A A A A B A A A A B A A A A A A A 119 Item # 48 49 49 49 49 49 49 49 49 Comparison Group African American/Caucasian Asian/Caucasian Two or More/Caucasian Total Minority/Caucasian American Indian/Caucasian Hispanic/Caucasian Hawaiian/Caucasian Male/Female African American/Caucasian Block 1 Nagelkerke R² 0.2030 0.1400 0.1320 0.1490 0.1310 0.1450 0.1330 0.1480 0.1440 Block 2 Nagelkerke R² 0.2060 0.1400 0.1320 0.1510 0.1310 0.1450 0.1330 0.1490 0.1480 Block 3 Nagelkerke R² 0.2090 0.1410 0.1320 0.1520 0.1310 0.1460 0.1330 0.1490 0.1490 Block 2 Significance Level 0.000*** 0.011* 0.175 0.000*** 0.855 0.845 0.069 0.000*** 0.000*** Block 3 Significance Level 0.000*** 0.007** 0.062 0.000*** 0.002** 0.009** 0.359 0.222 0.000*** ETS Classification A A A A A A A A A Table A3 Heading Descriptions Block 1 Nagelkerke R² – The amount of variance accounted for in the first stage of the logistic regression procedure. Displays the amount of variance accounted for by applicants’ total test score. Block 2 Nagelkerke R² – The amount of variance accounted for in the second stage of the logistic regression procedure. Displays the amount of variance accounted for by both total test score and group membership. Block 3 Nagelkerke R² – The amount of variance accounted for in the third stage of the logistic regression procedure. Displays the amount of variance accounted for by total test score, group membership and the interaction of total test score and group membership. Block 2 Significance Level – The significance level of the Block 2 Nagelkerke R² value. * denotes that the value is significant at the <.05 level. ** denotes that the value is significant at the <.001 level. amount of variance accounted for in the second stage of the logistic regression procedure. Displays the amount of variance accounted for by both total test score and group membership. Block 3 Significance Level – The significance level of the Block 3 Nagelkerke R² value. * denotes that the value is significant at the <.05 level. ** denotes that the value is significant at the <.001 level. amount of variance accounted for in the second stage of the logistic regression procedure. Displays the amount of variance accounted for by both total test score and group membership. The ETS Categorization Scheme (ETS Classification) – The ETS categorization scheme (Jodoin and Gierl, 2001) categorizes items as having small (A), moderate (B), and large (C) levels of DIF. 119 120 APPENDIX D Number of Applicants Passing at Cut-off Score Level by Test and Comparison Group Table A4-1. Original Test Applicants Passing at Cut-off Score Level by Comparison Group Original Test Cutoff Score 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 Male 20133 20128 20118 20107 20086 20074 20058 20042 20018 19986 19961 19929 19895 19865 19813 19754 19675 19586 19468 19314 19118 18876 18596 Female 9031 9028 9024 9021 9018 9012 9002 8997 8984 8976 8969 8962 8946 8930 8907 8883 8847 8803 8742 8665 8548 8410 8242 Caucasian 14776 14774 14769 14765 14757 14756 14753 14748 14740 14732 14724 14715 14705 14703 14688 14673 14647 14629 14596 14556 14499 14448 14368 Total Minority 14388 14382 14373 14363 14347 14330 14307 14291 14262 14230 14206 14176 14136 14092 14032 13964 13875 13760 13614 13423 13167 12838 12470 American Indian/ Alaskan Native 244 244 244 244 244 243 243 243 243 243 243 243 243 243 243 243 242 242 241 240 239 237 231 Asian 563 563 562 562 561 561 560 559 558 557 555 552 550 548 543 540 535 526 519 508 498 484 472 120 Hispanic 2553 2552 2551 2548 2541 2538 2536 2533 2526 2520 2516 2509 2505 2497 2492 2483 2471 2455 2427 2393 2351 2303 2256 African American 10195 10190 10183 10176 10168 10156 10136 10124 10103 10079 10061 10042 10009 9975 9927 9873 9804 9722 9614 9475 9283 9030 8744 Native Hawaiian/ Pacific Islander 162 162 162 162 162 162 162 162 162 162 162 162 162 162 160 160 160 158 157 153 151 145 139 Two or More Races 671 671 671 671 671 670 670 670 670 669 669 668 667 667 667 665 663 657 656 654 645 639 628 121 Original Test Cutoff Score 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 Male 18187 17731 17167 16412 15620 14565 13323 11880 10077 8244 6269 4330 2603 1263 426 67 Female 8025 7784 7473 7049 6535 5963 5305 4511 3694 2923 2080 1388 792 374 124 20 Caucasian 14232 14037 13802 13423 12988 12384 11601 10577 9213 7760 6014 4295 2657 1323 447 78 Total Minority 11980 11478 10838 10038 9167 8144 7027 5814 4558 3407 2335 1423 738 314 103 9 American Indian/ Alaskan Native 227 219 207 199 192 176 169 146 119 92 71 49 28 14 2 0 Asian 441 422 395 360 333 295 265 220 184 132 92 46 18 8 2 0 121 Hispanic 2182 2098 2009 1881 1740 1580 1395 1197 976 745 529 337 172 71 30 3 African American 8385 8013 7531 6944 6289 5532 4687 3816 2928 2154 1442 852 444 189 56 6 Native Hawaiian/ Pacific Islander 130 128 123 113 102 89 79 63 52 45 28 20 9 2 1 0 Two or More Races 615 598 573 541 511 472 432 372 299 239 173 119 67 30 12 0 122 Table A4-2. MH Test Applicants Passing at Cut-off Score Level by Comparison Group. MH Test Cut-off Score 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 Male 20136 20135 20133 20126 20111 20078 20050 20019 19970 19908 19819 19699 19521 19258 18892 18396 17677 16652 15328 13649 11497 8939 6121 3488 1457 303 Female 9034 9030 9030 9028 9022 9017 9008 8993 8969 8942 8909 8849 8762 8626 8439 8182 7788 7291 6604 5687 4634 3437 2209 1183 464 96 Caucasian 14780 14779 14778 14773 14767 14759 14751 14742 14729 14710 14680 14655 14607 14541 14430 14261 13937 13406 12683 11595 10054 8082 5734 3364 1441 318 Total Minority 14390 14386 14385 14381 14366 14336 14307 14270 14210 14140 14048 13893 13676 13343 12901 12317 11528 10537 9249 7741 6077 4294 2596 1307 480 81 American Indian/ Alaskan Native 244 244 244 244 244 244 243 243 243 243 243 243 242 241 236 231 222 207 196 170 136 101 66 32 19 4 Asian 563 563 563 563 563 561 559 558 553 549 542 536 525 506 480 452 412 373 324 276 223 165 85 41 14 1 122 Hispanic 2554 2553 2553 2552 2546 2539 2533 2530 2521 2512 2500 2473 2433 2388 2315 2236 2105 1941 1744 1485 1211 893 568 300 110 16 African American 10196 10193 10192 10189 10180 10159 10141 10108 10063 10006 9933 9819 9655 9399 9082 8645 8077 7343 6381 5293 4093 2826 1684 824 292 53 Native Hawaiian/ Pacific Islander 162 162 162 162 162 162 162 162 162 162 162 161 160 155 146 138 124 115 101 83 64 51 30 14 2 0 Two or More Races 671 671 671 671 671 671 669 669 668 668 668 661 661 654 642 615 588 558 503 434 350 258 163 96 43 7 123 Table A4-3. LR Test Applicants Passing at Cut-off Score Level by Comparison Group. LR Test Cut-off Score 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 Male 20136 20135 20130 20122 20109 20094 20075 20061 20042 20023 19999 19963 19940 19900 19857 19812 19745 19662 19560 19424 19240 18984 18691 18266 17778 17127 16325 Female 9033 9033 9031 9028 9024 9021 9013 9006 8999 8988 8978 8972 8965 8951 8938 8909 8879 8849 8795 8736 8633 8504 8338 8131 7852 7554 7108 Caucasian 14779 14778 14775 14774 14767 14759 14756 14754 14749 14740 14731 14725 14716 14707 14698 14683 14663 14644 14615 14582 14532 14463 14373 14221 14011 13717 13289 Total Minority 14390 14389 14385 14375 14365 14355 14331 14312 14291 14270 14245 14209 14188 14143 14096 14037 13960 13866 13739 13577 13340 13024 12655 12175 11618 10963 10143 American Indian/ Alaskan Native 244 244 244 244 244 244 244 243 243 243 243 243 243 243 243 243 243 242 241 241 240 237 234 227 219 211 201 Asian 563 563 563 562 561 561 561 559 559 559 558 556 553 549 547 544 539 534 527 520 509 492 479 457 435 401 368 123 Hispanic 2554 2554 2553 2551 2549 2546 2538 2538 2531 2525 2522 2517 2514 2506 2499 2491 2481 2472 2453 2415 2375 2329 2273 2202 2114 2018 1887 African American 10196 10196 10193 10186 10179 10172 10156 10141 10127 10112 10091 10064 10050 10017 9979 9932 9872 9797 9704 9591 9415 9176 8897 8539 8123 7641 7036 Native Hawaiian/ Pacific Islander 162 162 162 162 162 162 162 162 162 162 162 162 162 162 162 161 160 160 158 157 154 148 141 133 128 123 111 Two or More Races 671 671 671 671 671 671 671 670 670 670 670 668 667 667 667 667 666 662 657 654 648 643 632 618 600 570 541 124 LR Test Cut-off Score 36 37 38 39 40 41 42 43 44 45 46 Male 15321 14140 12674 10898 8903 6790 4724 2846 1383 469 71 Female 6542 5906 5118 4258 3378 2472 1640 943 433 153 23 Caucasian 12704 11979 10984 9691 8153 6367 4562 2835 1415 488 83 Total Minority 9158 8066 6807 5464 4127 2894 1801 953 400 133 10 American Indian/ Alaskan Native 188 175 156 130 98 76 54 28 16 2 0 Asian 326 290 248 207 157 112 64 24 12 3 0 124 Hispanic 1723 1546 1345 1117 876 632 406 217 87 34 3 African American 6313 5511 4586 3614 2680 1837 1114 594 249 79 8 Native Hawaiian/ Pacific Islander 103 89 76 60 50 38 26 11 2 1 0 Two or More Races 506 456 397 337 267 200 138 80 35 15 0 125 Appendix E Fisher’s Exact Statistical Significance Results of Adverse Impact by Test & Comparison Group Table A5-1. Original Test Fisher’s Exact Statistical Significance Results of Adverse Impact by Comparison Group Original Test Cutoff Score 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 Male/Female 0.214 0.261 0.425 0.869 0.357 0.482 0.837 0.638 0.868 0.410 0.235 0.079 0.120 0.217 0.238 0.219 0.265 0.433 0.750 0.974 0.241 0.035*† 0.001***† 0.000***† Total Minority/ Caucasian 1.000 0.449 0.195 0.046*† 0.010***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† American Indian/ Caucasian 1.000 1.000 1.000 1.000 1.000 0.336 0.368 1.000 1.000 0.817 0.938 0.944 0.831 0.811 0.993 0.846 0.895 0.755 0.983 0.875 0.867 0.666 0.029*† 0.013*† Asian/ Caucasian 1.000 1.000 0.362 1.000 1.000 0.247 0.096 0.042*† 0.024*† 0.011*† 0.001***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 125 Hispanic/ Caucasian 1.000 0.614 0.708 0.112 0.001***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† African American/ Caucasian 1.000 0.402 0.154 0.041*† 0.034*† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† Hawaiian/ Caucasian 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 0.977 0.890 0.806 0.726 0.712 0.631 0.768 0.976 0.156 0.083 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† Two or More/ Caucasian 1.000 1.000 1.000 0.650 0.624 1.000 1.000 1.000 0.726 0.905 0.990 0.978 0.969 0.792 0.932 0.784 0.568 0.015*† 0.040*† 0.055 0.001***† 0.000***† 0.000***† 0.000***† 126 Original Test Cutoff Score 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 Male/Female 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.134 Total Minority/ Caucasian 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† American Indian/ Caucasian 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.001***† 0.000***† 0.000***† 0.000***† 0.000***† 0.003**† 0.011*† 0.102 0.069 0.491 Asian/ Caucasian 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.154 Hispanic/ Caucasian 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.008**† African American/ Caucasian 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† Note. * significance level <.05. ** significance level <.01. *** significance level <.001. 126 Two or Hawaiian/ More/ Caucasian Caucasian 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.001***† 0.000***† 0.120 0.084 0.705 0.108 † Practical significance. 127 Table A5-2. MH Test Statistical Significance Results of Adverse Impact by Comparison Group MH Test Cut-off Score 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 Male/Female 0.310 0.013*† 0.066 0.431 0.726 0.175 0.126 0.229 0.433 0.467 0.255 0.569 0.883 0.537 0.176 0.028*† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.003**† Total Minority/ Caucasian 0.493 0.120 0.000***† 0.475 0.051 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† American Indian/ Caucasian 1.000 1.000 1.000 1.000 1.000 1.000 0.388 1.000 0.864 0.885 0.912 0.700 0.837 0.825 0.476 0.178 0.039*† 0.003**† 0.020*† 0.001***† 0.000***† 0.000***† 0.000***† 0.000***† 0.359 0.745 Asian/ Caucasian 1.000 1.000 1.000 1.000 1.000 0.206 0.032*† 0.020*† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.002**† Hispanic/ Caucasian 1.000 0.273 0.380 0.629 0.007**† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.004**† African American/ Caucasian 0.408 0.166 0.130 0.432 0.094 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† Note. * significance level <.05. ** significance level <.01. *** significance level <.001. 127 Two or Hawaiian/ More/ Caucasian Caucasian 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 0.668 1.000 0.624 1.000 0.644 1.000 1.000 0.943 0.918 0.765 0.922 0.571 0.637 0.752 0.123 0.940 0.571 0.017*† 0.096 0.000***† 0.002**† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.005**† 0.107 0.069 † Practical significance. 128 Table A5-3. LR Test Statistical Significance Results of Adverse Impact by Comparison Group LR Test Cut-off Score 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 Male/Female 0.096 0.228 0.734 1.000 0.862 0.387 0.408 0.526 0.448 0.670 0.642 0.158 0.110 0.068 0.033*† 0.182 0.225 0.125 0.337 0.333 1.000 0.606 0.055 0.055 0.000***† 0.002**† 0.000***† 0.000***† Total Minority/ Caucasian 1.000 1.000 0.772 0.033*† 0.036*† 0.046*† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† American Indian/ Caucasian 1.000 1.000 1.000 1.000 1.000 1.000 1.000 0.358 1.000 1.000 1.000 0.924 0.956 0.852 0.762 0.942 0.761 0.870 0.868 0.882 0.963 0.582 0.284 0.016*† 0.001***† 0.000***† 0.000***† 0.000***† Asian/ Caucasian 1.000 1.000 1.000 0.230 0.103 0.206 0.247 0.023*† 0.038*† 0.077 0.047*† 0.004**† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 128 Hispanic/ Caucasian 1.000 1.000 1.000 0.135 0.170 0.063 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† African American/ Caucasian 1.000 1.000 1.000 0.051 0.066 0.071 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† Hawaiian/ Caucasian 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 0.684 0.900 0.815 0.741 0.677 0.951 0.852 0.998 0.213 0.117 0.004**† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† Two or More/ Caucasian 1.000 1.000 1.000 1.000 0.668 0.624 0.428 1.000 1.000 0.726 0.526 0.756 0.744 0.930 0.888 0.850 0.894 0.367 0.035*† 0.016*† 0.001***† 0.001***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 129 LR Test Cut-off Score 37 38 39 40 41 42 43 44 45 46 Male/Female 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.001***† 0.210 Total Minority/ Caucasian 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† American Indian/ Caucasian 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.004**† 0.003**† 0.138 0.047*† 0.460 Asian/ Caucasian 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.136 Hispanic/ Caucasian 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.005**† African American/ Caucasian 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† Note. * significance level <.05. ** significance level <.01. *** significance level <.001. 129 Two or Hawaiian/ More/ Caucasian Caucasian 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.000***† 0.091 0.158 0.671 0.094 † Practical significance. REFERENCES Age Discrimination in Employment Act of 1967. (n.d.) In New World Encyclopedia. Retrieved May 2, 2009, from http://www.eeoc.gov/policy/adea.html. Albermarle Paper Company v. Moody, 422 US 405 (1975). American Educational Research Association, American Psychological Association, & National Council on Measurement in Education. (1999). Standards for educational and psychological testing.Washington, D. C.: American Educational Research Association. American Psychological Association, Division of Industrial-Organizational Psychology, (1980). Principles for the validation and use of personnel selection procedures (2nd ed.). Berkeley, CA: American Psychological Association. Biddle, D. A. (2006). Adverse Impact and Test Validation; A practitioner’s Guide to Valid and Defensible Employment Testing (2nd ed). Burlington, VT; Gower. Biddle, D. A., & Nooren, P. M. (2006). Validity generalization vs. Title VII: Can employers successfully defend tests without conducting local validation studies? Labor Law Journal, 57, 216-237. Camilli, G. (2006). Test fairness. In R. L. Brennan (Ed.), Educational Measurement (4th ed., Vol. 4, pp. 221-256). Westport: American Council on Education & Praeger Publishers. cxxxi Camilli, G., & Penfield, D. A. (1994). Variance estimation for differential test functioning based on Mantel-Haenszel Statistics. Journal of Educational Measurement, 34(2), 123-139. Camilli, G., & Shepard, L. A. (1994). Methods for identifying biased items. Thousand Oaks, CA: Sage Publications. Chinese Imperial Examination System, Confucianism and the Chinese Scholastic System. California State Poly, Pomona. Retrieved August 24, 2007, from http://www.csupomona.edu/~plin/ls201/confucian3.html. Civil Rights Act of 1964. (n.d.) In New World Encyclopedia. Retrieved May 2, 2009, from http:/www.newworldencyclopedia.org. Civil Service Act of 1883. (n.d.) In Biography of an Ideal. Retrieved May 2, 2009, from http://www.opm.gov/biographyofanideal/PU_CSact.htm. Clauser, B. E., & Hambleton, R. K. (1994). Differential Item Functioning by P. W. Holland & H. Wainer. [Review of the book Differential Item Functioning]. Journal of Educational Measurement, 37(1), 88-92. Clauser, B. E., & Mazor, K. M. (1998). Using statistical procedures to identify differential item functioning test items. Educational Measurement: Issues and Practice, 17, 31-44. Clauser, B. E., & Mazor, K. M., & Hambleton, R. K. (1998). Influence of the criterion variable on the identification of differential item functioning test item using the Mantel-Haenszel statistic. Applied Psychological Measurement, 15, 353-359. cxxxi cxxxii Cohen, J., Cohen, P., West, S. G., & Aiken, L. S. (2003). Applied multiple regression/correlation analysis for the behavioral sciences. Lawrence Erlbaum Associates: New Jersey. Contreras v. City of Los Angeles. 656 F.2d 1267, 9th Cir. (1981). Curley, W. E. & Schmitt, A. P. (1993). Revising SAT-Verbal items to eliminate differential item functioning. (ETS Research Report RR-93-61). Princeton, NJ: Educational Testing Service. Donoghue, J. R., & Allen, N. L. (1993). Thin versus thick matching in the MantelHaenszel procedure for detecting DIF. Journal of Educational Statistics, 18(2), 131-154. Donoghue, J. R., Holland, P. W., & Thayer, D. T. (1993). A Monte Carlo study of factors that affect the Mantel-Haenszel and standardization measures of DIF. In P. W. Holland & H. Wainer (Eds.), Differential item functioning: Theory and practice, 137-166. Hillsdale, NJ: Erlbaum Dorans, N. J., & Holland, P. W. (1993). DIF detection and description: Mantel-Haenszel and standardization. In P. W. Holland & H. Wainer (Eds.), Differential item functioning, 35-66. Hillsdale, NJ: Erlbaum. Equal Employment Opportunity Commission, Civil Service Commission, Department of Labor, & Department of Justice. (1978). Uniform guidelines on employee selection procedures. Federal Register, 43(166), 38290-38309. cxxxii cxxxiii Fisher, R. A. (1926). The arrangement of field experiments, Journal of the Ministry of Agriculture of Great Britain, 33, 503-513. Fisher, R. A. (1956). Statistical Methods and Scientific Inference. New York: Hafner. Freeman, J. (1991). How ‘sex’ got into Title VII: Persistent opportunities as a maker of public policy. Law and Inequality: A Journal of Theory and Practice, 9(2), 163184. Goodwin, A. L. (1997). Assessment for equity and inclusion: embracing all our children. New York: Routledge. Griggs v. Duke Power Co., 401 U.S. 424 (1971). Guion, R. M. (1998). Assessment, measurement, and prediction for personnel decisions. Mahwah, NJ; Lawrence Erlbaum Associates. Heineman, R. A., Peterson, S. A., & Rasmussen, T. H. (1995). American Government (2nd ed.). New York: McGraw-Hill. Hidalgo, M. D., & López-Pina, J. A., (2004). Differential item functioning detection and effect size: A comparison between logistic regression and Mantel-Haenszel procedures. Educational and Psychological Measurement, 64(6), 903-915. Holland, P. W., & Thayer, D. T. (1988). Differential item performance and the MantelHaenszel procedure. In H. Wainer & H. Braun (Eds.), Test Validity ( pp.129-145). Hillsdale, NJ: Erlbaum. Holland, P. W. & Wainer, H. (1993). Differential item functioning. Hillsdale, NJ: Lawrence Erlbaum Associates, Publishers. cxxxiii cxxxiv Ibrahim, A. K. (1992) Distribution and power of selected item bias indices: A Monte Carlo study. Unpublished Ph.D. thesis. University of Ottowa, Ottawa, Ontario. Jodoin, M. G., & Gierl, M. J. (2001). Evaluating type 1 error and power rates using an effect size measure with logistic regression procedures for DIF detections. Applied Measurement in Education, 14, 329-349. Keppel, G. & Wickens, T.D. (2004). Design and analysis: A researchers handbook (4th ed.). New Jersey: Prentice Hall. Lewis, C. (1993). A note on the value of including the studied item in the test score when analyzing test items for DIF. In P. W. Holland & H. Wainer (Eds.), Differential item functioning, 321-335. Hillsdale, NJ: Lawrence Erlbaum Associates. Longford, N. T., Holland, P. W., & Thayer, D. T. (1993). Stability of the MH D-DIF statistics across populations. In P. W. Holland & H. Wainer (Eds.), Differential item functioning (pp. 171-196). Hillsdale, NJ: Lawrence Erlbaum Associates. Manley, C. H. (1986). Federal Employee Job Rights: The Pendleton Act of 1881 to the Civil Service Reform Act of 1978. Howard Law Journal, 29(spring). Mantel, N., & Haenszel, W. (1959). Statistical aspects of the analysis of data from retrospective studies of disease. Journal of the National Cancer Institute, 22, 719748. cxxxiv cxxxv Mazor, K. M., Clauser, B. E., & Hambleton, R. K. (1994). Identification of nonuniform differential item functioning using a variation of the Mantel-Haenszel procedure. Educational and Psychological Measurement, 54, 284-291. Mazor, K. M., Kanjee, A., & Clauser, B. E. (1995). Using logistic regression and the mantel-haenszel with multiple ability estimates to detect differential item functioning. Journal of Educational Measurement, 32(2), 131-144. Meyers, L. S. (2007). Sources of validity evidence. Unpublished Manuscript. Meyers, L. S. (2007). Reliability, error, and attenuation. Unpublished Manuscript. Meyers, L. S. & Hunley, K. (2008). CSA differential Item Functioning. Unpublished Manuscript, California Department of Corrections and Rehabilitation. Milkovich, G. T., & Wigdor, A. K. (1991). Pay for performance: Evaluating appraisal and merit pay. National Research Council, USA:. Committee on Performance Appraisal. Monahan, P. O., McHorney, C. A., Stump, T. E., & Perkins, A. J. (2007). Odds ratio, delta, ETS Classification, and Standardization Measures of DIF Magnitude for Binary Logistic Regression. Journal of Educational and Behavioral Statistics, 32(1), 92-109. Ray, J.J. (1979). The authoritarian as measured by a personality scale: Solid citizen or misfit? Journal of Clinical Psychology, 35, 744-747. cxxxv cxxxvi Rogers, H. J., & Swaminathan, H. (1993). A comparison of logistic regression and Mantel-Haenszel Procedures for Detecting Differential Item Functioning. Applied Psychological Measurement, 17, 105-116. Scheuneman, J. D. & Slaughter, C. (1991). Issues of test bias, item bias, and group differences and what to do while waiting for the answers. Unpublished manuscript, Educational Testing Service. Schumacker, R. E. (2005). Test bias and differential item functioning. Unpublished manuscript, Applied Measurement Associates. Slocum, S. L., Gelin, M. N., & Zumbo, B. D. (in press). Statistical and graphical modeling to investigate differential item functioning for rating scale and Likert item formats. In B. D. Zumbo (Ed.), Developments in the theories and applications of measurement, evaluation, and research methodology across the disciplines: Vol. 1. Vancouver: Edgeworth Laboratory, University of British Columbia. Swaminathan, H., & Rogers, J. (1990). Detecting differential item functioning using logistic regression procedures. Journal of Educational Measurement, 27, 361-370. United States Government Manual (2005-2006). Washington: Government Printing Office, 2005. U.S. v. Commonwealth of Virginia. 569 F2d 1300, (CA-4 1978), 454 F. Supp. 1077. Waisome v. Port Authority. 948 F.2d 1370, 1376, 2d Cir. (1991). cxxxvi cxxxvii Wiberg, M. (2007). Measuring and detecting differential item functioning in criterionreferenced licensing test; a theoretic comparison of methods. Educational Measurement, 60. Umeå: Department of educational measurement, Umeå universitet. Zieky, M. (2003). A DIF Primer. Princeton, NJ: Educational Testing Service. Zumbo, B. D. (1999). A Handbook on the Theory and Methods of Differential Item Functioning (DIF): Logistic Regression Modeling as a Unitary Framework for Binary and Likert-type (Ordinal) Item Scores. Ottawa, ON: Directorate of Human Resources Research and Evaluation, Department of National Defense. Zwick, R. (1990). When do item response function and Mantel-Haenszel Definitions of Differential Item Functioning Coincide? Journal of Educational Statistics, 15(3), 185-197. cxxxvii