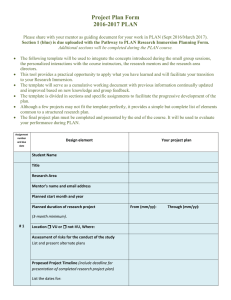
Case-control studies - UCLA School of Public Health
advertisement

Case-Control Studies EPI 200A October 29 and November 3, 2009 Case-Control study; the history A disease looking for a cause Vincent Memorial Hospital: 8 women of 15-22 years of age with vaginal cancer between 1966-1969 A very rare disease, especially in young women No common exposure to tampons or drugs; none used oral contraceptives (OCs) 1 case to 4 controls without the disease matched on age, born in the same hospital Similar data on X-rays, maternal smoking, pregnancy complications, childhood diseases, etc. 2 Case-Control study; the history A disease looking for a cause 7 of 8 case mothers had used diethyl-stilbesterol (DES); none of the 32 mothers for controls had used DES. Herbst et al. N Engl J Med 1971; 284: 878-81. 3 Exp Cases Non-cases + a b c d a/c > b/d if a cause a/c and b/d are exposure odds 4 The idea of a case-control study dates back to Hippocrates ….. 5 Hippocrates in first epidemics ”By paying attention to what was common to every case, and particular to each case, to the patient; the prescriber and the prescription, to the epidemic constitution generally, and its local mood, to the habits of life and occupation of each patient, to his speech, conduct, silences, thought, sleep, wakefulness, and dreams – their content and incidence, to his pickings and scratchings, tears, stools, urine, spit and vomit, to earlier and later forms of illness during the same prevalence, to critical or fatal determinations, to sweat, chill, rigor, hiccup, sneezing, breathing, belching, to passage of wind, silently or with noise; to bleedings, and to piles.” 6 The philosophy of the case-control study was taken from JSM as stated in MacMahon, Pugh and Ipsen: Epidemiologic Methods. London: Churchill, 1960. John Stuart Mill’s logic of causation 1. Method of difference 2. Method of agreement Only qualitative estimates 7 Broders 1920: JAMA; 74: 656-64. Cancer of the lip; 537 cases and 500 controls; similar smoking habits (80%), 78% of cases smoked the pipe; 38% among controls. Schreck and Lenowitz 1947: Cancer Research; 7: 180187. Cancer of the penis; circumcision as a protective factor. 1950s smoking and lung cancer 8 Doll and Hill on Smoking & Carcinoma of the Lung. BMJ September, 1950 / UK, Mortality Rates Year 1901 - 20 1936 - 9 Rates 100,000 Males 1.1 10.6 Females 0.7 2.5 This increase was also seen in USA, Canada, Australia, Denmark, Switzerland. 9 Doll and Hill on Smoking & Carcinoma of the Lung. BMJ September, 1950 Better diagnostic tools? Hypotheses: Air pollution (cars, industries) or tobacco smoking Reports from Germany 1939, 3 out of 86 lung cancer patients were non-smokers. Similar reports from the U.S. in 1950 (Schrek, Wynder, Graham) 10 Methods 20 London Hospitals were asked to notify all patients with cancer of the lung, stomach, colon, and rectum. Interviewers were also asked to select non-cancer patients of the same sex, age and from the same hospital. Hospital diagnosis on discharge accepted 2370 cancer cases identified > 75 years (150) Wrong diagnosis (80) No interview (too late (189)) (too ill (116)) (dead (67)) (too def, etc. (37)) 11 Methods, cont. No patients refused Study population Carcinoma of lung: Carcinoma of stomach: Carcinoma of colon/rectum: Other malignant diseases Controls (other patients) Other cases Excluded All 709 206 431 81 709 335 4 2475 Other cases – interviewed as cancer cases but the diagnosis was not confirmed or redundant non-cancer controls – without a match 12 Assessment of smoking Smoking habit change as a function of e.g. price (duty raised in 1947) and disease Were asked: A smoker = at least 1 cigarette per day at least 1 year 1. smoked any period of their life 2. age at which they started or stopped 3. current intensity 4. changes in smoking habits 5. type of tobacco smoking 6. inhaled or not 13 Assessment of smoking, cont. Two interviews done 6 months apart First Interviewer Second Interviewer Cigarette Cigarette 0 1 5 15 25 0 1 5 15 25 50+ 8 All 8 1 4 1 6 1 13 4 18 50+ 3 9 1 1 1 3 0 0 13 5 0 All 9 5 17 14 4 1 50 14 Assessment of smoking, cont. Sex Disease Non Smokers Males Lung cancer Controls Lung cancer Controls Females P 2(0.3%) 27(4.2%) 647 622 <0.001 19(31.7%) 32(53.3%) 41 28 <0.02 Then they showed Smokers Lung cancer patients smoked more, had smoked for a longer time period, smoking a pipe carried less risk Inhaling: Assessing 688 living cancer patients, 61.6% said they inhaled. 650 other patients, 67.2% said they inhaled. 15 Assessment of smoking, cont. Interpretation Selection bias = = Information bias more lung cancer patients from rural areas restriction to greater London – same results control patients – did they have a disease that prevented them from smoking or was prevented by smoking? - different patient control groups – same results interviewed before they were diagnosed blinding of interviewers – did not work compared smoking data for patients suspected for lung cancer but who did not have the disease 16 Assessment of smoking, cont. It is not reasonable, in our view, to attribute the results to any special selection of cases or to bias in recording… there is a real association between carcinoma of the lung and smoking. This is not necessarily to say that smoking causes lung cancer. The association would occur if carcinoma of the lung caused people to smoke or if both attributes were end-effects of a common cause. Only carcinogenic substance found in tobacco smoke is arsenic. Because carcinogenic testing at this time was based upon a skin-rat-test. 17 Disease ORs and exposure ORs are similar Closed Cohort Exp D D N + - a c b d N+ N- ND ND a/N+ b/N+ c/Nd/N- = a/b c/d a/ND Exposure odds = c/ND ratio b/ND d/ND = a/c b/d Disease odds = ratio a/b = axd = a/c c/d cxb b/d 18 So the exposure odds ratio OR ; = a/c b/d a/b is equal to the disease odds ratio c/d and RR is closed to the disease OR when the disease is rare RR = CI+ CI- ~ CI+ / (1- CI+ ) CI- / (1- CI -) 1-CI close to 1, if the disease is rare. 19 Advantages of the Case-Control Method Well suited to the study of rare diseases or diseases with long latency periods Allows study of multiple potential causes of a disease Relatively quick to mount and conduct Relatively inexpensive Requires comparatively few subjects Existing records can occasionally be used Often no risk to subjects 20 Disadvantages of the Case-Control Method Relies often on recall or records for information on past exposures Validation of information is difficult or sometimes impossible Control of extraneous variables may be incomplete Selection of an appropriate control group may be difficult Vulnerable to selection bias Rates of disease in exposed and unexposed individuals cannot be determined (not always true) 21 Advantages of the cohort method In principle, provides a complete description of experience subsequent to exposure, including rates of progression, staging of disease, and natural history Allows study of multiple potential effects of a given exposure, thereby obtaining information on potential benefits as well as risks Allows for the calculation of rates of disease in exposed and unexposed individuals Permits flexibility in choosing variables to be systematically recorded Allows for thorough quality control in measurement of study variables (not time in historical cohorts) 22 Disadvantages of the cohort method Large numbers of subjects are required to study rare diseases Potentially long duration for follow-up Current practice, usage, or exposure to study factors may change, making findings irrelevant Relatively expensive to conduct Maintaining follow-up is difficult Control of extraneous variables may be incomplete 23 A disease “looking” for a cause Case-control study A cause “looking” for a disease Follow-up study 24 Modern case-control methods The terminology is still confusing. You will find terms such as retrospective studies, TROHOC studies, casereferent studies, case-base studies, case-cohort studies, case-non-case studies and case-control studies. If we forget John Stuart Mill and start with a cohort and the estimates of effect measures this study provides, we have: 25 A cohort study of CS2 exposure and AMI E + - D+ 400 200 D9,600 9,800 N 10,000 10,000 T 9,800 9,900 RR = 400/10,000) / (200/10,000) = 2.0 IRR = (400/9,800) / (200/9,900) = 2.02 OR = (400/9,600) / (200/9,800) = 2.04 26 If we for some reason would reconstruct OR by using a more economic sampling approach, we would do a case-non-case study: E + N D+ 400 200 600 Controls (D-) 9,600/19,400 x 600 = 296.9 9,800/19,400 x 600 = 303.1 600 400/200 OR = = 2.04 296.9/303.1 27 A cohort study of CS2 exposure and AMI E + - D+ 400 200 D9,600 9,800 N 10,000 10,000 T 9,800 9,900 RR = 400/10,000) / (200/10,000) = 2.0 IRR = (400/9,800) / (200/9,900) = 2.02 OR = (400/9,600) / (200/9,800) = 2.04 28 If we wanted to estimate RR, we would select a different sampling strategy: The case-cohort study E + N D+ 400 200 600 Controls (D-) 10,000/20,000 x 600 = 300 10,000/20,000 x 600 = 300 600 OR = (400/200) / 300/300) = 2.0 This is a study for a fixed cohort with no loss to follow up. 29 A cohort study of CS2 exposure and AMI E + - D+ 400 200 D9,600 9,800 N 10,000 10,000 T 9,800 9,900 RR = 400/10,000) / (200/10,000) = 2.0 IRR = (400/9,800) / (200/9,900) = 2.02 OR = (400/9,600) / (200/9,800) = 2.04 30 In a cohort with loss to follow-up or in a dynamic population, one would aim at estimating the IRR. As it is seen in the cohort example, we need to sample controls to estimate the distribution of exposed and unexposed observation time. E + N D+ 400 200 600 Controls (D-) 9,800/19,700 x 600 = 298.5 9,900/19,700 x 600 = 301.5 600 OR = 2.02 31 To obtain this estimate, we sample from the population at risk at the time of the onset of the disease (incidence density sampling). In a small population like this: 1 2 3 4 5 6 7 8 D D D time t 3 is our case at time t, and the population at risk is number 1, 4, 5, 6 and 7. All selected controls that get the disease during recruitment should also become cases and controls may be selected more than once. 32 Summary: Assume an underlying follow-up study like Exp D+ + a c Db d N N+ N- T t+ t- RR = (a/N+) / (c/N-) or (a/c) / (N+/N-) IRR = (a/t+) / (c/t-) or (a/c) / (t+/t-) OR = (a/b) / (c/d) or (a/c) / (b/d) The right-hand figures are what we want controls to estimate. 33 Food poisoning: diarrhea and fever within 48 hours following a picnic Food/drinks N Disease All 480 24 Shrimp salad 122 8 Olives 326 20 Fried chicken 430 10 Barbecued chicken 183 18 Beans 256 12 Potato salad 375 17 Bread 178 7 Beer 466 23 How would you get data? How would you analyze data? How would you do a case-control study? 34 Cohort RRB-chicken = 18/183 6/297 = 4.869 Case cohort approach Exp + - Cases Controls 18 6 9.15 14.85 24 24 Sampling fraction, r, 48/480 = 0.10 4.869 = 4.869 = 4.869 = 18/(480x0.10-0.10N-) 6/0/10N18x0.10N6x(48-0.10N-) 1.8N288-0.6N- 1402.27 – 2.921N- = 1.8NN- = 297 35 Summary: Assume an underlying follow-up study like Exp D+ + a c Db d N N+ N- T t+ t- RR = (a/N+) / (c/N-) or (a/c) / (N+/N-) IRR = (a/t+) / (c/t-) or (a/c) / (t+/t-) OR = (a/b) / (c/d) or (a/c) / (b/d) The right-hand figures are what we want controls to estimate. 36 In a case control study we get estimates of relative effect measure. We usually cannot estimate absolute measures of association, why not? In some situations we can 37 We sample a fraction r then r+N+/r-N- = N+/N- if r+ = rr+t+/r-t- = t+/t- if r+ = r- r+b/r-d = b/d if r+ = r- Since we in a study with a known source population, N, get data on RR and have data on a and c, we get: a/(rN-rN-) RR = c/rN- That equation can be solved for N- given r is known and absolute risks can be estimated 38 Or in the book (ME3) terminology: Follow-up Exp + - D A+ A- A+ I+ = T+ D B+ B- T T+ T- AI- = T- We sample a rate r of controls per unit time B+/T+ = B-/T- = r or B+/r = T+ and B-/r = T- 39 In the case-control study, we have the following pseudo rate: A+/B+ and A-/BTo get incidence rates I+ = A+/T+ We: I+ = A+/B+ x r or I+ = A+/B+ x B+/T+ = A+/T+ If r is not known we still get: Pseudo rate+ = Pseudo rate- A+ /((B+ /T+)T+) A+ /B+ = A-/((B-/T-)T-) A-/B- A+ /(r xT+) = A-/(r xT-) = A+/T+ A-/T- = requires incidence density sampling IRR 40 Case-control studies are not conceptually retrospective. They do not compare cases with non-cases, but exposed with not exposed. They apply a specific sampling strategy to provide the relative effect measures in the underlying cohort. They provide estimates with far less observations than in the cohort study. Given the necessary exposure data and sampling data are available, they are equivalent in quality to the cohort approach. In fact they represent just a different approach to obtain the cohort result. Case-control studies are the studies of choice if you can reconstruct exposure data back in time (for the exposure of interest as well as for confounders). They represent often the design of choice in genetic studies 41 If you want to study if bacterial vaginoses causes preterm birth, how would you sample cases and controls? 42 If you want to study if antibiotics prevent preterm births, what is the source population (study base)? If you want to study if use of bicycle helmets prevents head injuries, what is the source population (study base)? 43 The described type of case-control study is a study with a primarily defined study base. Cases come from a well-defined cohort and we may sample controls from this cohort. Or Cases come from a well-defined population. We have complete ascertainment and we may sample controls from this population at given points in time. Be careful if these conditions are not met. Sometimes cases are prevalent cases. 44 Since prevalence is a function of incidence and duration (D) P/I-P= I x D Determinants of prevalence reflect aetiologic as well as prognostic factors. 45 Example: Exercise and AMI Exp + - Exp + N D+ S+ S- 30 30 10 1,000 20 1,000 20 10 DS+ 20 10 30 N Cohort 15 15 30 RR = (30/1,000) / (30/1,000) = 1.0 OR = (20/10) / (15/15) = 2.0 46 The same rules as for risks will apply for estimating effect measures based on prevalence data. A case-non-case study will estimate P /(1 P ) OR P /(1 P ) Control sampling from the entire population (including prevalent cases) will estimate: P OR P 47 Controls are ideally randomly sampled from the same population that gave rise to the cases. Controls will then estimate the exposure distribution in the source population but this estimate will be subject to random sampling variation. 48 It will often be difficult to make random sampling and: If the selected sampling strategy produces exposure estimates that are interchangeable with the exposure distribution in the study base, results will be unbiased. If not, effect estimates will be biased. 49 If all cases cannot be ascertained (no registry, not all come to the health care system), a case-control study should be designed to take this lack of ascertainment into consideration. This type of case-control study is usually ”weak”. Our source population definition will be: All potential cases define the source population. The conditions that actually led to case identification should lead to identification of all member of the source population. (those who would enter the case group if they have the conditions that were seen for cases – may depend upon disease characteristics, insurance conditions, financial means etc) 50 How to design a case-control study on male risk factors of infertility. Only half of those with an infertility problem seek medical help? 51 Selection of population controls The method of choice is to use a register that includes the entire population that gave rise to the cases, without such register it is more difficult to make sure all have same chance of being selected RDD - random digit dialling who has a telephone who is home how many are home who has more numbers + + how many do not respond to unsolicited calls + + Neighbourhood controls make sure they were residents at case diagnosis risk of overmatching Friend controls 52 Population controls - sampling from a list of list of residents Complicated if time must be taken into consideration. Best would be “density sampling” or could be sampled at one point in time. One option: 1. Select a date at random from the case ascertainment period 2. Select a person at random from the list 3. If resident at the selected date (1) - then OK as a control 4. Repeat 1-3 until the desired number of controls is reached 5. Exp. Data is collected according to date at onset of the disease or the random date (1) 53 Sampling of time - not persons Sampling within an existing cohort e.g. diet and cancer a. make list of time units (e.g. 1 month) for all participants b. sample from these units 54 Use of patient controls rather than population controls. This idea stems from Mill’s “method of scientific inference”, not from sampling from the underlying cohort. 55 If case ascertainment depends on a factor (e.g. access to medical care) sampling of controls must have similar dependency (e.g. hosp. Controls) Advantages of hospital controls easy to sample better response rate symmetry in data collection 56 The “control disease” must neither be caused nor prevented by the exposure If cases are referred to the case ascertainment hospital hospital controls must have the same referral pattern Use a single disease if an ideal ‘control’ disease exist, but it may also be acceptable to: Exclude all diseases with a known or suspected association with exposure - and make use of the remaining diseases as controls One control group, or more than one 57 Two stage sampling Exposure Levels Cases Controls 0 1 2 c a1 a2 d b1 b2 First stage case-control sampling could be based upon inexpensive (perhaps already existing) data. A second stage sample could take analytical costs into consideration. Could be: 1. All cases and a random sample of controls 2. Oversampling of more informative cases and/or cohorts. For example, those with the highest exposure levels. Such a sampling strategy must be taken into consideration when doing the analysis. 58 Matching Definition: Cases and controls are selected to be similar with respect to certain variables - usually controls are selected to be similar to cases. Maching could be 1:1, 1:2, …, 1:5. 59 1 2 3 4 5 6 7 8 D D t Time At time t, 1, 3, 4 and 6 are candidates. Which ones fit the matching criteria? 60 If matching is done for four age groups, two sex groups and four socioeconomic groups, there are 4 x 2 x 4 = 32 classifications - it may be difficult to find a match. 61 Matching is usually done on confounders, but matching in a case-control study does not in itself eliminate confounding why? E D 2 1 C Confounding requires: 1. The confounder is a cause (1) 2. The confounder (c) is associated with E (2). 62 Matching on (1) does not eliminate a causal association causation is a fact of life independently of our manipulations. We compare exposed and not exposed. We should not try to compare cases with non-cases. We try to identify notexposed according to our counterfactual ideal. We have no similar guidelines for cases and controls. We may use restrictions –but then they should be used for cases as well as controls. It is a mistake to think controls should be as healthy as possible. Matching may produce a well-balanced data set for analyses. Matching usually requires matched analysis. The matched sets are kept in the analyses and should be identifiable. 63 Matching may even lead to confounding (create an association between E and C) in situations where this was not present in the study base. All of this is very different from using matching in follow-up studies. The effect of the matching variables on the outcome cannot be studied. Matching is not always done on confounders; could be done on time (incidence density sampling) or on a sampling criteria (like data or birth). Is birth weight correlated with cancer of the testis? Select controls among boys born in the same hospital before and after the birth of the cases. What is wrong with that? 64 E D Example: C Evaluation of a screening programme for cervical cancer matching on the ”GP factor”. Setting: A doctors screen 80% B doctors 20% 65 A 10,000 8,000 sc+ 40 D(0.5%) 2,000 sc- 20 D(1.0%) B 10,000 2,000 sc+ 10 D(0.5%) 8,000 sc- 80 D(1.0%) RR = 0.5 66 Case-cohort study E D Cohort + - 50 100 66 84 OR = RR = 0.64 67 Stratified analysis or analysis of matched sets will solve the problems GP E D Cohort OR A + - 40 20 48 12 0.50 B + - 10 80 18 72 0.50 68 In order to have true confounding, GPs must be a risk factor of cervical cancer E D C 69 Setting: A 10,000 8,000 sc+ 2,000 sc- 40 D(0.5%) 20 D(1.0%) B 10,000 2,000 sc+ 20 D(1.0%) 8,000 sc- 160 D(2.0%) RR = 0.5, but now confounding in the study base 70 The cohort: Matched case-cohort study: E D All RR + - 60 180 10,000 10,000 0.33 E D Cohort OR + - 60 180 84 156 0.62 71 Again, stratification will solve the problems GP E D Cohort OR A + - 40 20 48 12 0.50 B + - 20 160 36 144 0.50 72 Cross-sectional study – a survey An observational study in which all variables are measured at a single point in time 73 Are used to estimate prevalences of diseases and frequencies of exposures. Diseases of short duration will not be well presented since prevalence is a function of incidence and duration 74 A study of peripheral vascular disease (PVD) in Scotland and smoking PVD No PVD All Smoking Ever Never 23 8 1704 1291 1727 1299 All 31 2995 3026 Measures of association? Interpretation? 75 Because exposure and disease are assessed at the same time, cross-sectional studies may not be able to establish that exposure preceded onset of the disease process. 76 77 78 79 80 81 Case-crossover design Cases and controls should come from the same studybase. Fulfilled if cases are also the controls. For most exposures, we move from being exposed to unexposed. If we have no carry-over effect and the cause-effect relationship is short, we may compare IR in the two time segments. IRexp / IRnon-exp 82 As always a case-control study samples the underlying population experience. Each case represents the follow-up of one person. If cases are their own controls, we adjust for subject characteristics, sometimes for confounding by indication. 83 If the time period before onset of the case status equals the reference time period, 4 outcomes are possible CaseType period 1 exp 2 exp 3 not-exp 4 not-exp Reference period exp not-exp exp not-exp Type 1 and 4 provide no indication of causal relevance. Type 2 indicates causal association. Type 3 indicates the opposite. type2 OR type3 84 The design rules out time-stable personal habits as confounders but not time-dependent factors. Selection bias if type 2 and type 3 cases decide on participation based upon their case status. Information bias is a potential problem if exposure status is based upon recall. 85 The case-crossover design is biased if the exposure varies over the time period under study. The case-time study tries to incorporate adjustment for this change over time by including data on exposure used over time for controls. This will not automatically adjust for confounding by indication. Data on disease severity are needed. 86 Case-crossover study N Engl J Med 1997;336:453-58 Aim: Use of cellular telephones - a risk factor for motor vehicle accidents? Methods: Case-crossover = case ascertainment North York Collision Reporting Centre, Toronto. July 1, 1994 - August 31, 1995, 10-18 hours, Monday-Friday. Note! Centre does not include accidents with injuries, only substantial property damage. Criteria: Excl. drivers who had no cellular phone or no billing records. 87 Case-crossover study N Engl J Med 1997;336:453-58 Timing of the accident Subject statement Police records Call to emergency Two out of 3 = exact Timing of exposure: 10 minutes prior to accident Reference exposure time: Workday before the accident Same weekday The week before the accident Adjustment for driving 88 Case-crossover study N Engl J Med 1997;336:453-58 5890 drivers - 1064 had a phone - 742 participated 699 had a billing record Time of accident: exact inexact 231 468 170 had used the phone 10 minutes prior to the accident 37 the weekday before crude OR 6.5 (4.5, 9.9) adj OR 4.3 (3.0, 6.5) 89 Table 2. Relative risk of a motor vehicle collision in 10minute periods, according to selected characteristics Characteristics All subjects Age (yr) < 25 25-39 40-54 ≥ 55 No. with telephone use in 10 min before collision Relative Risk (95% CI) 170 4.3 (3.0-6.5) 21 95 44 10 6.5 (2.2 - ) 4.4 (2.8 - 8.8) 3.6 (2.1 - 8.7) 3.3 (1.5 - ) Sex Male Female 123 47 4.1 (2.8 - 6.4) 4.8 (2.6 - 14.0) High-school graduation Yes No 153 17 4.0 (2.9 - 6.2) 9.8 (3.0 - ) Type of job Prof Other 34 136 3.6 (2.0 - 10.0) 4.5 (3.1 - 7.4) 90 Characteristics No. with telephone use in 10 min before collision Relative Risk (95% CI) 0-9 Driving 10-19 experience 20-29 (yr) ≥ 30 40 67 36 27 6.2 (2.8 - 25.0) 4.3 (2.6 - 10.0) 3.0 (1.7 - 7.0) 4.4 (2.1 - 17.0) Cellular telephone experience (yr) 0 or 1 2 or 3 4 or 5 ≥ 6 51 39 36 44 7.8 (3.8 - 32.0) 4.0 (2.2 - 12.0) 2.8 (1.7 - 6.7) 4.1 (2.3 - 12.0) Type of cell phone Hand-held Hands free 129 41 3.9 (2.7 - 6.1) 5.9 (2.9 - 24.0) 91 Fig. 1. Relative Risk of a collision for different control periods Relative risk of a collision 10 8 6 4 2 0 Day before Workday Weekday Max-use Matching day day Comparison Day 92 Fig. 2 Time of cellular-telephone call in relation to the relative risk of a collision 10 8 6 • 4 2 0 • • • 93 Fig. 3 Consistency of relative risks obtained from different collision times 100.0 10.0 • • • • • • • • • • 1.0 0.1 Time of Day Day of Week 94