Introductory Statistics for Laboratorians dealing with High
advertisement

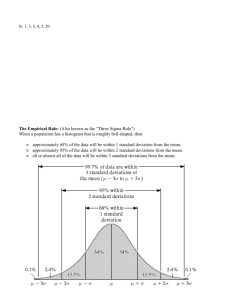
Introductory Statistics for Laboratorians dealing with High Throughput Data sets Centers for Disease Control Problem 7: Dispersion • Prepare 2 line graphs, one for males and one for females using the data presented below. • Put both line graphs on the same axes. Problem 7: Dispersion Attitudes on Race Relations Males Females X f X f 9 1 9 1 8 1 8 1 7 3 7 0 6 3 6 3 5 4 5 10 4 3 4 2 3 2 3 2 2 2 2 0 1 1 1 1 Problem 7: Dispersion 12 10 8 Males 6 Females 4 2 0 0 1 2 3 4 5 6 7 8 9 Problem 7: Dispersion 12 10 8 Males 6 Females 4 2 0 1 2 3 4 5 6 7 8 9 Problem 7: Dispersion • How can we quantify the difference between the men and the women in this problem. • Compute the mean (average) for the men. • Compute the mean (average) for the women. Problem 7: Dispersion • What are the highest and lowest scores for the men? • What are the highest and lowest scores for the women? • Count the number of scores from lowest to highest. This number is called the Range of the scores. • In this case the Range doesn’t help us describe the difference between the males and the females. We need better measures of dispersion. Problem 8: Dispersion • For the following data: • What is the highest and lowest score? • What is the Range? (count the number of scores from the lowest to the highest.) • What is the Mean (average)? • How far is each person from the Mean? (Fill in the column. Always subtract the mean from the score. ) Problem 8: Dispersion Data Table N= Subject Score X Fred 0 George 1 Harry 2 Jerry 4 Larry 5 Jennifer 6 Jan 7 Joan 8 Jessica 8 Juana 9 Total = Mean = Distance from Mean x = (Score – Mean) Total deviation = Squared Distance from Mean Sum Squares = Problem 8: Dispersion • Compute the “Sum of Squared Deviations from the Mean” (SS) for this data set (or sample or whatever you call it). • Compute the variance of the sample. • Compute the standard deviation of the sample. Dispersion Definitions • The range is the number of scores from the smallest to the largest. • Deviation Score = Score – Mean – Always subtract the mean from the score – Always preserve the sign (positive or negative) – The total of the deviation scores is always zero • Sum Squares = Total of the squared deviation scores. (SS) • Variance = SS/N • Standard Deviation = square root of variance Standard Deviation • Surely there is an easier way to measure dispersion than using all this squaring and square rooting. • Turns out, the standard deviation is the exact point on a normal curve where the second derivative is zero. • If you were skiing down the slope, it would get steeper and steeper then it would start to flatten out. That point is the standard deviation. • That’s why it is the preferred measure of dispersion. Standard Deviation Problem 9 • Given the following collection of scores: 2, 3, 5, 6, 6, 8 – Calculate the range of the scores – Calculate the sum of squares – Calculate the variance – Calculate the standard deviation Problem 9 Data Table Subject X Fran 2 Frank 3 Frangelica 5 Fonz 6 Frieda 6 Fabiano 8 N= Total = Mean = x2 Deviation score (x) SS = Normal distributions Normal—or Gaussian—distributions are a family of symmetrical, bell- shaped density curves defined by a mean m (mu) and a standard deviation s (sigma): N (m, s). 1 f ( x) e 2 s 1 xm 2 s 2 x e = 2.71828… The base of the natural logarithm π = pi = 3.14159… x A family of density curves Here the means are the same (m = 15) while the standard deviations are different (s = 2, 4, and 6). 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 Here the means are different (m = 10, 15, and 20) while the standard deviations are the same (s = 3). 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 All Normal curves N (m, s) share the same properties About 68% of all observations Inflection point are within 1 standard deviation (s) of the mean (m). About 95% of all observations are within 2 s of the mean m. Almost all (99.7%) observations are within 3 s of the mean. mean µ = 64.5 standard deviation s = 2.5 N(µ, s) = N(64.5, 2.5) Reminder: µ (mu) is the mean of the idealized curve, while x is the mean of a sample. σ (sigma) is the standard deviation of the idealized curve, while s is the s.d. of a sample. Definitions: Statistical Symbols • In an actual sample – Scores are represented by – – – – Mean = X x Deviation Score Standard Deviation = s Variance = s2 X XX • In a theoretical distribution (density curve) – Mean = μ – Standard Deviation = σ – Variance = σ2