Document
advertisement

CSCI3230
Entropy, Information &Decision Tree
Liu Pengfei
Week 12, Fall 2015
1
Which feature to choose?
2
Information Gain
Suppose we have a dataset of people
Which split is more informative?
Split over whether
Account exceeds 50K
Less or equal 50K
3
Over 50K
Split over whether
applicant is employed
Unemployed
Employed
Information Gain
Uncertainty/Entropy (informal)
4
Measures the level of uncertainty in a group of
examples
Uncertainty
Very uncertain group
5
Less uncertain
Minimum
uncertainty
Entropy: a common way to measure uncertainty
• Entropy = −𝑝𝑖 log(𝑝𝑖 )
pi is the probability of class i, or that the proportion of class i in
the set.
• Entropy comes from information theory. The
higher the entropy, the less the information
content
• --some say higher entropy,
•
more information
6
Information Gain
We want to determine which attribute in a given set
of training feature vectors is most useful for
discriminating between the classes to be learned.
Information gain tells us how important a given
attribute of the feature vectors is.
We will use it to decide the ordering of attributes in
the nodes of a decision tree.
7
Example of Entropy
Whether students like the movie Gladiator
Gender
Major
Like
Male
Female
Male
Female
Math
History
CS
Math
Yes
No
Yes
No
Female
Male
Male
Math
CS
History
No
Yes
No
Female
Math
Yes
4
8
𝐸 𝐿𝑖𝑘𝑒 = − log
4
8
− − log
4
8
=1
4
8
Example of Entropy
Gender
Male
Major
Math
Like
Yes
Female
Male
Female
Female
History
CS
Math
Math
No
Yes
No
No
Male
Male
Female
CS
History
Math
Yes
No
Yes
P(Major=Math & Like =Yes) = 0.25
P(Major=History & Like =Yes) = 0
P(Major=CS & Like =Yes) = 1
𝐸 𝐿𝑖𝑘𝑒|𝑀𝑎𝑗𝑜𝑟 = 𝑀𝑎𝑡ℎ
2
2
2
2
= − 4 log 4 − − 4 log 4 =1
2
𝐸 𝐿𝑖𝑘𝑒|𝑀𝑎𝑗𝑜𝑟 = 𝐶𝑆 = − 2 log
0
− − 2 log
0
2
=0
𝐸 𝐿𝑖𝑘𝑒|𝑀𝑎𝑗𝑜𝑟 = ℎ𝑖𝑠𝑡𝑜𝑟
2
2
0
0
= − 2 log 2 − − 2 log 2 =0
2
2
Example of Entropy
Gender
Male
Major
Math
Like
Yes
Female
Male
Female
Female
History
CS
Math
Math
No
Yes
No
No
Male
Male
Female
CS
History
Math
Yes
No
Yes
P(Gender=male & Like =Yes) =
0.75
P(Gender =female & Like =Yes) =
0.25
𝐸 𝐿𝑖𝑘𝑒|𝐺𝑒𝑛𝑑𝑒𝑟 = 𝑚𝑎𝑙𝑒
1
1
3
3
= − log
− − log
4
4
4
4
𝐸 𝐿𝑖𝑘𝑒|𝐺𝑒𝑛𝑑𝑒𝑟 = 𝑓𝑒𝑚𝑎𝑙𝑒
3
3
1
1
= − log
− − log
4
4
4
4
CSCI3230
Introduction to Neural Network I
Liu Pengfei
Week 12, Fall 2015
The Angelina Effect
12
Angelia is a carrier of the mutation
in the BRCA1 gene.
Angelina Jolie's risk of having
breast cancer was amplified by
more than 80 percent and ovarian
cancer by 50 percent.
Her aunt died from breast cancer
and her mother from ovarian
cancer.
She decided to go for surgery and
announced her decision to have
both breasts removed.
Can we use a drug for the
treatment?
Neural Network Project
Topic: Protein-Ligand Binding Affinity Prediction
Goal: Given the structural properties of a drug, you are helping a chemist
to develop a classifier which can predict how strong a drug (ligand) will
bind to a target (protein).
Due date will be announced later
Do it alone / Form a group of max. 2 students
(i.e. >= 3 students per group is not allowed.)
You can use any one of the following language: C, C++, Java, Swi-Prolog,
CLisp, Python, Ruby or Perl.
However, you cannot use data mining or machine learning packages
Start the project as early as possible !
13
How to register your group ?
14
How to register your group ?
15
What to include in your zip file ?
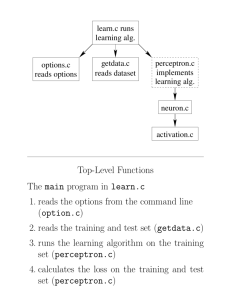
Your zip file should contain the followings:
preprocess.c – your source code (if you use C)
preprocessor.sh – a script file to compile your source
code
trainer.c – your source code (if you use C)
trainer.sh – a script file to compile your source code
best.nn – your Neural Network
Case Sensitive !
16
Grading
Please note that the neuron network interfaces/formats
are different from the previous years.
We adopts a policy of zero tolerance on plagiarism.
Plagiarism will be SERIOUSLY punished.
To make the project estimation easier, we will evaluate
your work based on the F-measure
17
Model Evaluation
Cost-sensitive measures
Predicted Class
Actual
Class
Class = Yes
Class = No
Class = Yes
a (TP)
b (FN)
Class = No
c (FP)
d (TN)
TP
a
Precision (p)
TP FP a c
TP
a
Recall (r)
TP FN a b
2rp
2a
F - measure (F)
r p 2a b c
18
Introduction to Neural Network
20
Biological Neuron
21
A neuron is an electrically
excitable cell that
processes and transmits
information through
electrical and chemical
signals.
A chemical signal occurs
via a synapse, a specialized
connection with other
cells.
Artificial Neuron
An artificial neuron is a logic
computing unit.
In this simple case, we use a
step function as the activation
function: only 0 and 1 are
possible outputs
Artificial Neuron
Activation Function g(u)
Mechanism:
Input:
𝑖𝑛 = 𝑥1 𝑤1 + 𝑥2 𝑤2 + ⋯ + 𝑥5 𝑤5
Output:
𝜃
y = g(in)
Step function
22
Example
5
3.2
0.1
If w1 = 0.5, w2 = -0.75, w3 = 0.8, and step function
g (with threshold 0.2) is used as activation
function, what is the output?
w1
w2
w3
Activation Function g(u)
Summed input = 5(0.5) + 3.2(-0.75) + 0.1(0.8)
= 0.18
Output = g(Summed input)
𝜃
Step function
23
Since 0.18 < 0.2, so Output = 0
Artificial Neuron
An artificial neuron is a logic
computing unit.
In this case, we use sigmoid
function as activation function:
real values from 0 and 1 are
possible outputs
Artificial Neuron
Activation Function g(z)
Mechanism:
Input:
Output:
24
𝑖𝑛 = 𝑥1 𝑤1 + 𝑥2 𝑤2 + ⋯ + 𝑥5 𝑤5
y = g(in)
Sigmoid function
𝑔 𝑧 =
1
1 + 𝑒 −𝑧
Example
5
3.2
0.1
If w1 = 0.5, w2 = -0.75, w3 = 0.8, and sigmoid
function g is used as activation function, what is
the output?
w1
w2
w3
Activation Function g(z)
Summed input = 5(0.5) + 3.2(-0.75) + 0.1(0.8)
= 0.18
1
Output = g(Summed input) = 1+𝑒 −0.18 = 0.54488
Sigmoid function
25
1
𝑔 𝑧 =
1 + 𝑒 −𝑧
Logic Gate Simulation
[0,1]
Function:
Sum(input)>t ?
[0,1]
[0,1]
[0,1]
[0,1]
I1
I2
Total Input
t
Input > t?
AND
0
0
0
1.5
0
AND
0
1
1
1.5
0
AND
1
0
1
1.5
0
AND
1
1
2
1.5
1
26
Logic Gate Simulation
[0,1]
[0,1]
[0,1]
[0,1]
[0,1]
Function:
Sum(input)>t ?
I1
I2
Total Input
t
Input > t?
OR
0
0
0
0.5
0
OR
0
1
1
0.5
1
OR
1
0
1
0.5
1
OR
1
1
2
0.5
1
27
Logic Gate Simulation
[0,1]
[0,1]
[0,1]
[0,1]
[0,1]
Function:
Sum(input)>t ?
I1
I2
Total Input
t
Input > t?
NOT
0
N/A
0
-0.5
1
NOT
1
N/A
-1
-0.5
0
28
Logic Gate Simulation
For the previous cases, it can be viewed as a classification problem:
separate the class 0 and class 1.
The neuron simply finds a line to separate the two classes
And: I1+I2 – 1.5 = 0
Or: I1+I2 – 0.5 = 0
Xor: ?
29
I1 I2 Output
0
0
0
0
1
1
1
0
1
1
1
0
Linear Separability
Two classes ('+' and '-') below are
linearly separable in two
dimensions.
Two classes ('+' and '-') below are
linearly inseparable in two
dimensions.
i.e we can find a set of w1, w2
such that:
Every point x belongs to class ‘+’
satisfy 𝑛𝑖=1 𝑤𝑖 𝑥𝑖 ≥ 𝑡
&
Every point x belongs to class ‘-’
satisfy 𝑛𝑖=1 𝑤𝑖 𝑥𝑖 < 𝑡
30
The above example would need
two straight lines and thus is not
linearly separable.
http://en.wikipedia.org/wiki/Linear_separability
Artificial Neural Networks
Important concepts:
What is a perceptron?
What is a single-layer perceptron?
What is a multi-layer perceptron?
What is the feed forward property?
What is the general learning principle ?
31
Technical Terms
Perceptron = Neuron
Single-layer perceptron =
Single-layer neural network
Multi-layer perceptron =
Multi-layer neural network
The presence of one or
more hidden layer is the
difference between singlelayer perceptron and multilayer perceptron.
32
The simplest kind of neural
network is a single-layer perceptron
network, which consists of a single
layer of output nodes; the inputs
are fed directly to the outputs via a
series of weights.
Multi-layer Perceptron
Multi-layer
Input layer
Hidden layer(s)
Output layer
Feed-forward
Links go in one
direction only
http://en.wikipedia.org/wiki/Multilayer_perceptron
33
A MLP consists of
multiple layers of nodes
in a directed graph.
Except for the input
nodes, each node is a
neuron.
The multilayer
perceptron consists of
three or more layers
(an input and an output
layer with one or more
hidden layers).
Feed Forward Property
Given inputs to input layer (L0)
Outputs of neurons in L1 can be
calculated.
Outputs of neurons in L2 can be
calculated and so on.
Finally, outputs of neurons in the
output layer can be calculated
34
General Learning Principle
1.
For supervised learning,
we provide the model a
set of inputs and targets.
2.
The model returns the
outputs
3.
Reduce the difference
between the outputs and
targets by updating the
weights
4.
Repeat step 1-3 until
some stopping criteria is
encountered
35
Input
Target
Input
Input
Input
w1
w2
w3
Output
Summary
1.
We have learnt the similarity between the biological neurons and
artificial neurons
2.
We have learnt the underlying mechanism of artificial neurons
3.
We have learnt how artificial neurons compute logic (AND, OR, NOT)
4.
We have learnt the meaning of perceptron, single-layer perceptron and
multi-layer perceptron.
5.
We have learnt how information is propagated between neurons in
multi-layer perceptron (Feedforward property).
6.
We have learnt the general learning principle of artificial neuron
network.
36
Announcements
Written assignment 3 will be released this week.
Neural network project specification will be released this
week.
Since there will be no tutorial on next Thursday due to
congregation ceremony, please attend one of the other
two tutorial sessions on Wednesday.
37