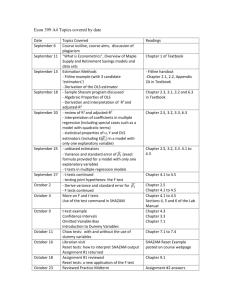
Lecture 9 Heteroskedasticity
advertisement

Lecture 9
Heteroskedasticity
In this chapter, we aim to answer the following questions:
1. What is the nature of heteroskedasticity?
2. What are its consequences?
3. how does one detect it?
4. What are the remedial measures?
9.1
The Nature of Heteroskedasticity
• Homoskedasticity (homoskedasticity): the classical regression model
assumes that residuals εi were identically distributed with mean zero
and equal variance σ 2 (i.e., E(εi |Xi ) = 0, and Var(εi |Xi ) = σ 2 , where
Xi means {Xi2 , · · · , Xik }, for i = 1, 2, · · · , n)
• Because the variance is a measure of dispersion of the observed value
of the dependent variable (y around the regression line β1 + β2 X2 +
· · · + βk Xk ), homoskedasticity means that the dispersion is the same
across all observations. However, in many situations, this assumption
might be false.
Example 1. Take the sample of household consumption expenditure
and income. Since household with low income do not have much flexibility in spending, consumption patterns among such low-income households may not vary very much. On the other hand, rich families have
1
2
LECTURE 9 HETEROSKEDASTICITY
a great deal of flexibility in spending. Some might be large consumers;
others might be large savers and investors in financial markets. This
implies that actual consumption might be quite different from average
consumption. Therefore, it is very likely that higher income households
have a large dispersion around mean consumption than lower income
households. Such situation is called heteroskedasticity.
Example 2. The annual salary and the number of years since earning
the Ph.D. for 222 professors from seven universities.
(Example 8.1, Ramanathan (2002))
Look at the scatter diagram of log salary and years since Ph.D. [Figure
8.2]
The spread around an average straight-line relation is not uniform. ⇒
It violates the usual assumption of homoskedasticity of the error terms.
• Heteroskedasticity arises also when one uses grouped data rather than
individual data.
• Heteroskedasticity can occur in time series data also.
• Let’s relax the assumption that the residual variance is constant across
observations and assume heteroskedasticity instead
• Assume εi is a random variable with E(εi |Xi ) = 0 and Var(εi |Xt ) =
E(ε2i |Xi ) = σi2 , for i = 1, · · · , n. It implies each observation has a
different error variance.
ASSUMPTION A4’ εi is a random variable with E(εi |Xi ) = 0 and Var(εi |Xi ) =
E(ε2i |Xi ) = σi2 , for i = 1, · · · , n. Thus,
E[εε0 ] = σ 2 Ω =
σ12 0 0 · · · 0
0 σ22 0 · · · 0
..
.. . .
.
..
. ..
.
.
.
0 0 0 · · · σn2
It will sometimes be useful to write
σi2 = σ 2 ωi
For convenience, we shall use the normalization
tr(Ω) =
n
X
ωi = n
i=1
c
Yin-Feng
Gau 2002
ECONOMETRICS
3
9.2
LECTURE 9 HETEROSKEDASTICITY
Consequences of Ignoring Heteroskedasticity
yi = β1 + β2 Xi2 + · · · + βk Xik + εi
where Var(εi |Xi ) = σi2 for i = 1, · · · , n. That is, the error variances are
different for different values of i and are unknown.
In the presence of heteroskedasticity, the OLS estimator b is still unbiased, consistentm and asymptotically normally distributed.
9.2.1
Effects on the properties of the OLS estimators
If one ignores heteroskedasticity and uses OLS estimators to estimate β’s,
the properties of unbiasedness and consistency still are not violated. But
OLS estimate is no more efficient. It is possible to find an alternative
unbiased linear estimate that has a lower variance than OLS estimate.
Inefficiency of OLS estimators:
yi = βxi + εi
Var[εi ] = σ ωi
2
Assume that yi and xi are measured as deviations from means, so E[yi ] =
E[xi ] = 0. Let x denote the column of vector of n observations on xi , and Ω
be defined as
2
σ1 0 0 · · · 0
2
0 σ2 0 · · · 0
Ω = ..
.. . .
.
..
. ..
.
.
.
0
0
· · · σn2
0
The variance of the OLS and GLS estimators of β are
σ 2 n x2 ωi
Var[b] = σ (x x) x Ωx(x x) = Pni=1 2i 2
( i=1 xi )
2
σ
Var[β̂] = σ 2 [x0 Ω−1 x]−1 = Pn
2
i=1 (xi /ωi )
2
c
Yin-Feng
Gau 2002
0
−1 0
0
−1
P
ECONOMETRICS
4
LECTURE 9 HETEROSKEDASTICITY
We can have that
Var[b]
Var[β̂]
=
(1/n)
Pn
2
i=1 zi
z2
=
z 2 + (1/n)
Pn
i=1 (zi
2
z
− z)2
=1+
Var[x2i ]
>1
(E[x2i ])2
where ωi = x2i = zi . It shows that the gain in efficiency from GLS over OLS
can be substantial.
9.2.2
Effects on the tests of hypotheses
The estimated variances and covariances of the OLS estimates of the β’s
are biased and inconsistent when heteroskedasticity is present but ignored
[see Kmenta (1986), pp.276-279]. Therefore, the tests of hypotheses are no
longer valid.
9.2.3
Effects on forecasting
Forecasts based on OLS estimated will also be unbiased. But forecasts are
inefficient (because the estimates are inefficient).
PROPERTIES of OLS with Heteroskedastic Errors:
1. The estimates and forecasts based on OLS will still be unbiased and
consistent.
2. The OLS estimates are no longer BLUE and will be inefficient. Forecasts will also be inefficient.
3. The estimated variances and covariances of the regression coefficients
will be biased and inconsistent, and hence tests of hypotheses are invalid.
9.2.4
The Estimated Covariance Matrix of b
The conventionally estimated covariance matrix for the OLS estimator σ 2 (X0 X)−1
is inappropriate; the appropriate matrix is σ 2 (X0 X)−1 (X0 ΩX)(X0 X)−1 .
The error resulted from the conventional estimator is shown below. We
know
ε0 Mε
e0 e
=
s2 =
n−K
n−K
c
Yin-Feng
Gau 2002
ECONOMETRICS
5
LECTURE 9 HETEROSKEDASTICITY
where
M = I − X(X 0 X)−1 X 0
Thus, we can obtain
s2 =
e0 e
ε0 X(X0 X)−1 X0 ε
−
n−K
n−K
Taking the expectation for the two parts separately,
e0 e
tr[E[ε0 ε]]
nσ 2
E
=
=
n−K
n−K
n−K
"
#
and
ε0 X(X0 X)−1 X0 ε
tr[E[(X0 X)−1 X0 ε0 εX]]
E
=
n−K
n−K
"
#
tr σ 2
=
X0 X
n
−1 X0 ΩX
n
n− K
!−1
0
nσ
X
X
tr
Qn ∗
=
n−K
n
2
As n → ∞,
e0 e
E
→ σ2
n−K
"
and
#
ε0 X(X0 X)−1 X0 ε
E
→0
n−K
"
#
if b is consistent
Therefore,
If b is consistent, then lim E[s2 ] = σ 2
n→∞
This implies that:
If plimb = β, then plims2 = σ 2
The difference between the conventional estimator and the appropriate covariance matrix for b is
Est.Var[b] − Var[b] = s2 (X 0 X)−1 − σ 2 (X0 X)−1 (X0 ΩX)(X0 X)−1
c
Yin-Feng
Gau 2002
ECONOMETRICS
6
LECTURE 9 HETEROSKEDASTICITY
9.2.5
Estimating The Appropriate Covariance Matrix
for OLS
Σ=
n
1 2 0
1X
σ X ΩX =
σi2 xi x0i
n
n i=1
White (1980) Shows that under very general conditions, the matrix
S0 =
n
1X
e2 xi x0i
n i=1 i
where ei denotes the ith least squares residual, is a consistent estimator of
Σ. Therefore, the White estimator,
Est.Var[b] = n(X0 X)−1 S0 (X0 X)−1
can be used as an estimate of the true variance of the least squares estimator.
9.3
Testing for Heteroskedasticity
• Scatter diagram of squared residuals — before actually carrying out
any formal tests of heteroskedasticity, it is useful to examine the model’s
residuals visually. ⇒ plot the squares of the residuals obtained by
applying OLS to the model (i.e., e2i , i = 1, · · · , n)
• Graph the squared estimated residuals against a variable that is suspected to the cause of heteroskedasticity.
• If the model has several explanatory variables, we can graph e2i against
each of these variables, or graph it against Ŷi , the fitted value of the
dependent variable.
• This graphing technique is only suggestive of heteroskedasticity and is
not a substitute for formal testing.
• Gujarati (2003) Figure 10.7
c
Yin-Feng
Gau 2002
ECONOMETRICS
7
LECTURE 9 HETEROSKEDASTICITY
9.3.1
Goldfeld-Quandt Test
• Goldfeld and Quandt (1965): based on the ratio of variances.
• Idea: If the error variances are equal across observations (i.e., homoskedastic), then the variance for one part of the sample will be the
same as the variance for another part of the sample.
⇒ one can test for the equality of error variances using a F -test on the
ratio of two variances.
• Divide the sample of observations into three parts, then discard the
middle observations.
⇒ Estimate the model for each of the two other sets of observations
and compute the corresponding residual variances.
⇒ Use an F -test to test for the equality of these two variances.
e01 e1 /(n1 − K)
F [n1 − K, n2 − K] = 0
e2 e2 /(n2 − K)
Formal steps for Goldfeld-Quandt test:
Step 1: Identify a variable (Z) to which the error variance σi2 is related.
Suppose that σi2 is suspected of being positively related to Zi . Arrange
the data set according to increasing values of Zi (Zi could be one of
the Xs in the regression. For example, σi2 = σ 2 x2i for some variable x)
Step 2: Divide the sample of n observations into the first n1 and the last
n2 , thus omitting the middle observations n1 + 1 through n − n2 . The
number of observations to be omitted is arbitrary and is usually between one-sixth and one-third. Note that n1 and n2 must be greater
than the number of coefficients to be estimated.
Step 3: Estimate separate regressions for observations 1 through n1 and
n − n2 + 1 through n.
Step 4: Obtain th error sum of squares as follows:
SSR1 =
n1
X
i=1
c
Yin-Feng
Gau 2002
e2i
and SSR2 =
n
X
e2i
i=n−n2 +1
ECONOMETRICS
8
LECTURE 9 HETEROSKEDASTICITY
Under H0 : homoskedasticity, we have that SSR/σ 2 has the χ2 distribution. Also we know that the ratio of two independent χ2 -distributed
random variables is F -distributed. Therefore, the GQ statistic is computed as follows:
Step 5: Compute
σ̂22
SSR2 /(n2 − k)
=
2
σ̂1
SSR1 /(n1 − k)
where k is the number of regression coefficients including the constant
term. Under the null hypothesis of homoskedasticity, GQ ∼ Fn2 −k,n1 −k .
If the disturbances are normally distributed, the the GQ statistic is
exactly F -distributed under the null hypothesis.
GQ =
∗
⇒ if GQ > Fα%
then reject the null of homoskedasticity and conclude that
heteroskedasticity is present, where α% is the significance level.
9.3.2
Testing Homoskedasticity by the Lagrange Multiplier (LM) Tests
yi = β1 + β2 Xi2 + · · · + βk Xik + εi
We are interested to test if assumptions A4 is true, therefore we are to test
the null hypothesis
H0 : Var(εi |Xi ) = σ 2
Because u is assumed to have a zero conditional mean, E(εi |Xi ) = 0,
Var(εi |Xi ) = E(ε2i |Xi )
and so the null hypothesis of homoskedasticity is equivalent to
H0 : E(ε2i |Xi ) = σ 2
A simple approach is to assume a linear function for σi2 :
σi2 = α1 + α2 Zi2 + · · · + αp Zip
where the error variance σi2 is related to a number of variables Z2 , · · · , Zp .
Then the null hypothesis can be written as
H0 : α2 = · · · = αp = 0
F -statistic for testing α2 = · · · = αp = 0
c
Yin-Feng
Gau 2002
ECONOMETRICS
9
LECTURE 9 HETEROSKEDASTICITY
Step 1: Regress y against a constant term, x2 , · · · , xk , and obtain the estimated residuals ei for i = 1, · · · , n.
Step 2: Regress ei against a constant term, Z2 , · · · , Zp , and obtain OLS
estimators α̂1 , α̂2 , · · · , α̂p ). Denote the corresponding R-squared as Re22 .
F =
Re22 /(p − 1)
1 − Re22 /(n − k)
Under H0 , this F statistic has an Fp−1,n−k distribution.
LM-test for testing α2 = · · · = αp = 0:
LM = n · Re22
Under H0 , this LM statistic has an χ2p−1 distribution.
The LM statistic of the test is actually called the Breusch-Pagan test for
heteroskedasticity (BP test)
A Simple Example of Breusch-Pagan Test
• Breusch and Pagan (1980): based on the Lagrange multiplier test principle.
• If the error variance σi2 is not constant but is related to a number
of variables Z2 , · · · , Zp (some or all of which might be the Xs in the
model). The simplest example is assuming that Z’s are X’s. Hence,
the model becomes
yi = β1 + β2 Xi2 + · · · + βk Xik + εi
σi2 = α1 + α2 Xi2 + · · · + αk Xik
• Under H0 : α2 = · · · = αk = 0, the variance is a constant, indicating
homoskedasticity.
• Breusch-Pagan test is aversion of LM statistic for the hypothesis α2 =
· · · = αk = 0. The LM test consists of an auxiliary regression and using
it to construct a test statistic.
c
Yin-Feng
Gau 2002
ECONOMETRICS
10
LECTURE 9 HETEROSKEDASTICITY
Step 1: Estimate yi = β1 +β2 xi2 +· · ·+βk xik +εi by OLS and compute
ei = yi − β̂1 − β̂2 Xi2 − · · · − β̂k Xik
2
and σ̂ =
e2i
n
P
Step 2: e2i is an estimate of the error variance σi2 . If σi2 = α1 +α2 Xi2 +
· · ·+αk Xik were valid, one would expect e2i to be related to the xs.
Run the regression of e2i against a constant term, Xi2 , · · · , Xik , and
compute the LM statistic: n · Re22 . This LM statistic is distributed
χ2k under H0 .
• Breusch-Pagan has been shown to be sensitive to any violation of the
normality assumption.
• Breusch-Pagan test also requires a prior knowledge of what might be
causing the heteroskedasticity.
Auxiliary equations for error variance, E(ε2i |Xi ):
σi2 = α1 + α2 Zi2 + · · · + αp Zip
σi = α1 + α2 Zi2 + · · · + αp Zip
ln(σi2 ) = α1 + α2 Zi2 + · · · + αp Zip
(9.1)
(9.2)
(9.3)
which is equivalent to
σi2 = exp(α1 + α2 Zi2 + · · · + αp Zip )
where exp means the exponential function, p is the number of unknown
coefficients, and the Zs are variables with known values. (some or all of the
Zs might be the Xs in the model)
1. Breusch-Pagan test (Breusch and Pagan, 1979): use the formulation
(9.1)
2. Glesjet test (Glesjer, 1969): use the formulation (9.2)
3. Harvey-Godfrey test (Harvey, 1976, and Godfrey, 1978): use the formulation (9.3)
Because we do not know σi , we use estimates obtained by applying OLS to
yi = β1 + β2 Xi2 + · · · + βk Xik + εi
to obtain the estimated residuals ei . Then, use e2i for σi2 , |ei | for σi , and
ln(e2i ) for ln(σi2 ).
c
Yin-Feng
Gau 2002
ECONOMETRICS
11
LECTURE 9 HETEROSKEDASTICITY
White’s Test
• The Goldfeld-Quandt test is not as useful as the LM tests because it
can not accommodate situations where several variables jointly cause
heteroskedasticity, as in Equations (9.1), (9.2), and (9.3).
• By discarding the middle observations, we will throw away valuable
information.
• The Breusch-Pagan test has be shown to be sensitive to any violation
of the normality assumption.
• All the previous tests require a prior knowledge of what might be causing the heteroskedasticity.
• White (1980): a direct test for the heteroskedasticity that is very closely
related to the Breusch-Pagan test but does not assume any prior knowledge of the heteroskedasticity
• White’s test is a large sample LM test with a particular choice for the
Z’s, but it does not depend on the normality assumption.
yi = β1 + β2 Xi2 + β3 Xi3 + εi
2
2
σi2 = α1 + α2 Xi2 + α3 Xi3 + α4 Xi2
+ α5 Xi3
+ α6 Xi2 Xi3
Step 1: Regress y against a constant term, X2 , and X3 , and obtain
estimated residuals ei = yi − β̂1 − β̂2 Xi2 − β̂3 Xi3 .
2
2
Step 2: Regress e2i against a constant term, Xi2 , Xi3 , Xi2
, Xi3
and
2
Xi2 Xi3 . Compute n · Re2 , where n is the size of the sample and
Re22 is the unadjusted R-squared from the auxiliary regression of
e2 .
Step 3: Reject H0 : α2 = α3 = α4 = α5 = α6 = 0 if nRe22 > χ25 (0.05),
the upper 5 percent point on the χ2 distribution with 5 d.f.
• Although White’s test is a large sample test, it has been found useful
in samples of 30 or more.
• If the null is not rejected, it implies that the residuals are homoskedastic.
c
Yin-Feng
Gau 2002
ECONOMETRICS
12
LECTURE 9 HETEROSKEDASTICITY
• If some of the explanatory variables are dummy variables, say Xi2 is
2
a dummy variable, then Xi2
= Xi2 and hence should not be included
separately, as otherwise there will be exact multicollinearity and the
auxiliary regression cannot be run.
• With k explanatory variables (including the constant term), the auxiliary regression will have k(k + 1)/2 terms, excluding the constant
term. The number of observations must be larger than that, and hence
n > k(k + 1)/2 is a necessary condition.
9.4
Estimation Procedures
If the assumption of homoskedasticity is rejected, we have to find alternative
estimation procedures that are superior to OLS. The following are several
approaches to estimations.
9.4.1
Heteroskedasticity Consistent Covariance Matrix
(HCCM) Estimation
• Heteroskedasticity-Robust Inference: White (1980) proposes a method
of obtaining consistent estimators of the variance and covariances of
OLS estimators, called as the HCCM estimator,
9.4.2
Generalized (or Weighted) Least Squares When
Ω is Known
Before development of heteroskedasticity-robust statistics from White (1980),
the usual solution to problem of heteroskedasticity is to model and estimate
the specific form of heteroskedasticity. This leads to a more efficient estimator
than OLS, and it produces t and F statistics that have y and F distributions. However, such approach suffers the problem of unknown nature of the
heteroskedasticity.
β̂ = (X 0 Ω−1 X 0 )−1 X 0 Ω−1 y
Example 1:
Consider the most general case,
Var[εi ] = σi2 = σ 2 ωi
c
Yin-Feng
Gau 2002
ECONOMETRICS
13
LECTURE 9 HETEROSKEDASTICITY
Then
Ω=
ω1 0 0 · · · 0
0 ω2 0 · · · 0
..
.. . .
.
..
. ..
.
.
.
0 0 0 · · · ωn
The GLS estimator is obtained by regressing Py on PX,
√
√
y1 / ω1
x1 / ω1
√
√
y2 / ω2
x2 / ω2
Py =
PX =
..
..
.
.
√
√
yn / ωn
xn / ωn
where
Applying the OLS to the transformed model, we obtain the weighted least
squares (WLS) estimator
"
β̂ =
n
X
#−1 "
wi xi x0i
i=1
n
X
#
wi xi yi
i=1
where wi = 1/ωi .
Example 2:
Consider
σi2 = σ 2 x2ik
Then the transformed model for GLS is
x1
x2
ε
y
= βk + β1
+ β2
+ ··· +
xk
xk
xk
xk
where βk = β0 /xk .
Example 3:
If the variance is proportional to xk instead of x2k , σi2 = σ 2 xik . Then the
transformed model for GLS is
y
x1
= βk + β1 √
xk
xk
!
+ β2
x2
√
xk
!
ε
+ ··· + √
xk
√
where βk = β0 / xk .
c
Yin-Feng
Gau 2002
ECONOMETRICS
14
LECTURE 9 HETEROSKEDASTICITY
Weighted Least Squares (WLS)
The Heteroskedasticity if Known up to a Multiplicative Constant:
Let’s specify the form of heteroskedasticity as
Var(εi |Xi2 , · · · , Xik ) = σi2 = σ 2 Zi2
or equivalently σi = σZi
where the values of Zi are known for all i. Zi could be h(Xi2 , · · · , Xik ), some
function of the explanatory variables that determines the heteroskedasticity.
Write Var(εi |Xi ) = σi2 = σ 2 Zi2 , where Xi denotes all independent variables for observation i, and Zi changes across observations. Suppose the
original equation is
yi = β1 + β2 Xi2 + · · · + βk Xik + εi
and assumptions A1-A3 are satisfied. Since Var(εi |Xi ) = E(ε2i |Xi ) = σ 2 Zi2 ,
E
εi
Zi
2 !
Xi = E(ε2i |Xi )/Zi2 = (σ 2 Zi2 )/Zi2 = σ 2
We divide the above equation by Zi to get
yi
β1
Xi2
Xik
εi
=
+ β2
+ · · · + βk
+
Zi
Zi
Zi
Zi
Zi
or
∗
∗
∗
yi∗ = β1 Xi1
+ β2 Xi2
+ · · · + βk Xik
+ ε∗i
∗
where Xi1
= 1/Zi and Xij∗ = Xij /Zi for j = 2, · · · , k. Hence, OLS esti∗
∗
∗
mators obtained by regressing yi∗ against Xi1
, Xi2
, · · · , Xik
will be BLUE.
∗
∗
∗
These estimators, β1 , β2 , · · · , βk , will be different from the OLS estimators
in the original equation. The βj∗ are examples of generalized least squares
(GLS) estimators.
Summary on Weighted Least Squares (WLS):
Define wi = 1/σi , rewrite the original equation as
wi yi = β1 wi + β2 (wi Xi2 ) + · · · + βk (wi Xik ) + (wi εi )
Minimize the weighted sum of squares of residuals:
X
(wi εi )2 =
X
(wi yi − β1 wi − β2 wi Xi2 − · · · − βk wi Xik )2
Remarks:
c
Yin-Feng
Gau 2002
ECONOMETRICS
15
LECTURE 9 HETEROSKEDASTICITY
• Observation for which σi2 is large are given less weights in WLS.
• Resulting estimators are identical to those obtained by applying OLS
to equation of y ∗ and X ∗ ’s.
Multiplicative Heteroskedasticity with Known Proportional Factor:
• Assume the heteroskedasticity is such that the residual standard deviation σi is proportional to some known variable zi
Var(εi |Xi ) = σi2 = σ 2 Zi2
or equivalently σi = σzi
divide every term in the original equation by Zi
1
Xi2
Xik
εi
yi
= β1 + β2
+ · · · + βk
+
Zi
Zi
Zi
Zi
Zi
or
∗
∗
∗
yi∗ = β1 Xi1
+ β2 Xi2
+ · · · + βk Xik
+ ε∗i
(9.4)
We have
Var(ε∗i |Xi )
εi Var(εi |Xi )
= Var
Xi =
= σ2
Zi
Zi2
∗
∗
∗
• Estimates obtained by regressing yi∗ against Xi1
, Xi2
, · · · , Xik
will be
2
2 2
BLUE (when σi = Zi σ ).
• This is the same as WLS with wi = 1/Zi .
• Because the GLS estimates are BLUE, OLS estimates of the original
equation will be inefficient.
9.4.3
Estimated Generalized Least Squares (EGLS) or
Feasible GLS (FGLS)
• As the structure of the heteroskedasticity is generally unknown (that
is, Zi or σi is unknown), one must first obtain estimates of σi by some
means and then use the weighted least squares procedure. This method
is called estimated generalized least squares (EGLS).
• There are many ways to model heteroskedasticity, but we study one
particular flexible approach.
c
Yin-Feng
Gau 2002
ECONOMETRICS
16
LECTURE 9 HETEROSKEDASTICITY
Assume that
Var(u|X) = σ 2 exp(δ1 + δ2 X2 + · · · + δk Xk )
Once the parameters δj were known, we may just apply WLS to obtain
efficient estimators of βj . The best way is to use the data to estimate deltaj ,
and then to use these estimates δ̂j to construct weights.
Following the setup of Var(u|X), we can write
u2 = σ 2 exp(δ1 + δ1 X1 + · · · + δk Xk )v
where E(v|X) = 1. If we assume that v is actually independent of X, we can
write
log(u2 ) = δ1 + δ2 X2 + · · · + δk Xk + e
where E(e) = 0 and e is independent of X; the intercept in this equation
is different from δ0 . Since this equation satisfies the Gauss-Markov assumptions, we can get unbiased estimators of the deltaj by using OLS.
Now, replace the unobserved u with the OLS residuals. Next, run the
regression of log(e2i ) on a constant, X2 , · · · , Xk . Call the fitted values as ĝi .
So the estimates of σi2 are simply
σ̂i2 = exp(ĝi )
So we may use WLS with weights 1/σ̂i .
SUMMARY of the FGLS Procedure to Correct for Heteroskedasticity:
1. Run the regression of y on a constant, X2 , · · · , Xk and obtain the residuals, ei , i = 1, · · · , n.
2. Create log(ei ) by first squaring the OLS residuals and then taking the
natural log.
3. Run the regression of log(e2i ) on a constant, X2 , · · · , Xk , and obtain the
fitted value, gˆi .
4. Exponential the fitted values, gˆi , to obtain σ̂i2 = gˆi
5. Estimate the equation
y = β1 + β2 X2 + · · · + βk Xk + u
by WLS, using weights 1/σ̂i
c
Yin-Feng
Gau 2002
ECONOMETRICS
17
LECTURE 9 HETEROSKEDASTICITY
9.5
Linear Probability Model (LPM)
9.5.1
Nature of LPM
y = β1 + β2 X2 + · · · + βk Xk + u
E(y|X) ≡ E(y|X2 , · · · , Xk ) = β1 + β2 X2 + · · · + βk Xk
where y is a binary variable. It results
P(y = 1|X2 , · · · , Xk ) = β1 + β2 X2 + · · · + βk Xk
More important, the linear probability model does violate the assumption of
homoskedasticity. When y is a binary variable, we have
Var(y|X) = p(X)[1 − p(X)]
where p(X) denotes the probability success: p(X) = β1 + β2 X2 + · · · + βk Xk .
This indicates there exists heteroskedasticity in LPM model. It implies the
OLS estimators are inefficient in the LPM. Hence we have to correct for
heteroskedasticity for estimating the LPM if we want to have a more efficient
estimator that OLS in LPM.
Procedures of Estimating the LPM:
1. Obtain the OLS estimators of the LPM at first.
2. Determine whether all of the OLS fitted values, ŷi , satisfy 0 < ŷi < 1.
If so, proceed to step (3). If not, some adjustment is needed to bring
all fitted values into the unit interval.
3. Construct the estimator of σi2 :
σ̂i2 = ŷi (1 − ŷi )
4. Apply WLS to estimate the equation
y = β1 + β2 X2 + · · · + βk Xk + u
using weights wi = 1/σ̂i .
c
Yin-Feng
Gau 2002
ECONOMETRICS
18
9.5.2
LECTURE 9 HETEROSKEDASTICITY
Maximum Likelihood Estimation (MLE)
Use MLE method to estimate β, the collection of β0 , β1 , · · · , βk , σ 2 , and Ω(θ),
the variance matrix of parameters, at the same time. Let Γ estimate Ω−1 .
Then, the log likelihood can be written as:
log L = −
n
1
1
log(2π) + log σ 2 − 2 ε0 Γε + log |Γ|
2
2σ
2
First Order Condition (FOC):
1
∂ log L
= 2 X 0 Γ(Y − Xβ)
∂β
σ
∂ log L
n
1
= − 2 + 4 (Y − Xβ)0 Γ(Y − Xβ)
2
∂σ
2σ
2σ
1 −1
1
1
=
Γ − ( 2 )εε0 = 2 (σ 2 Ω − εε0 )
2
σ
2σ
9.6
Heteroskedasticity-Robust Inference After OLS Estimation
Since hypotheses tests and confidence interval with OLS are invalid in the
presence of heteroskedasticity, we must make decide if we entirely abandon
OLS or reformulate the adequate corresponding test statistics or confidence
intervals. For the later options, we have to adjust standard errors, t, F , and
LM statistics so that they are valid in the presence of heteroskedasticity of
unknown form. Such procedure is called heteroskedasticity-robust inference
and it is valid in large samples.
9.6.1
How to estimate the variance, Var(β̂j ), in the
presence of heteroskedasticity
Consider the simple regression model,
yi = β0 + β1 xi + εi
Assume assumptions A1-A3 are satisfied. If the errors are heteroskedastic,
then
Var(εi |xi ) = σi2
c
Yin-Feng
Gau 2002
ECONOMETRICS
19
LECTURE 9 HETEROSKEDASTICITY
The OLS estimator can be written as
Pn
(xi − x)εi
2
i=1 (xi − x)
β̂1 = β1 + Pi=1
n
and we have
Pn
Var(β̂1 ) =
− x)2 σi2
SST2x
i=1 (xi
where SSTx = ni=1 (xi − x)2 is the total sum of squares of the xi . Note:
When σi2 = σ 2 for all i, Var(β̂1 ) reduces to the usual form, σ 2 /SSTx .
Regarding the way to estimate Var(β̂1 ) in the presence of heteroskedasticity, White (1980) proposed a procedure which is valid in large samples.
Let ei denote the OLS residuals from the initial regression of y on x. White
(1980) suggested a valid estimator of Var(β̂1 ) for heteroskedasticity of any
form (including homoskedasticity), is
P
Pn
− x)2 e2i
SST2x
i=1 (xi
Brief proof: (for complete proof, please refer to White (1980))
Pn
− x)2 e2i p
→ E[(xi − µx )2 ε2i ]/(σx2 )2
SST2x
Pn
Pn
2 2
2 2
i=1 (xi − x) σi p
i=1 (xi − x) ei
→
n · Var(β̂1 ) = n ·
SST2x
SST2x
n·
i=1 (xi
Therefore, by the law of large number
limit theorem, we
Pn and the2 central
2
x)
e
(x
−
i=1 i
i
d β̂ ) =
to construct confidence
can use this estimator, Var(
1
SST2x
intervals and t test.
For the multiple regression model,
yi = β0 + β1 xi1 + · · · + βk xik + εi
under assumptions A1-A3, the valid estimator of Var(β̂j ) is
Pn
d β̂ ) =
Var(
j
2 2
i=1 rij ei
SST2j
where rij denotes the ith residuals from regressing xj on all other indepenP
dent variables (including an intercept), and SSTj = ni=1 (xij − xj )2 .
c
Yin-Feng
Gau 2002
ECONOMETRICS
20
LECTURE 9 HETEROSKEDASTICITY
REMARKS:
σ2
,
SSTj (1 − Rj2 )
P
for j = 1, . . . , k, where SSTj = ni=1 (xij − xj )2 , and Rj2 is the R2 from
the regressing xj on all other independent variables (and including an
intercept).
• The variance of the usual OLS estimator β̂j is Var(β̂j ) =
d β̂ ) is called heteroskedasticity-robust stan• The square root of Var(
j
dard error for β̂j . Once the heteroskedasticity-robust standard errors
are obtained, we can then construct a heteroskedasticity-robust t
statistic.
estimate − hypothesized value
t=
standard error
References
Greene, W. H., 2003, Econometric Analysis, 5th ed., Prentice Hall. Chapter
11.
Gujarati, D. N., 2003, Basic Econometrics, 4th ed., McGraw-Hill. Chapter
10.
Ramanathan, R., 2002, Introductory Econometrics with Applications, 5th
ed., Harcourt College Publishers. Chapter 8.
Ruud, P. A., 2000, An Introduction to Classical Econometric Theory, 1st ed.,
Oxford University Press. Chapter 18.
c
Yin-Feng
Gau 2002
ECONOMETRICS