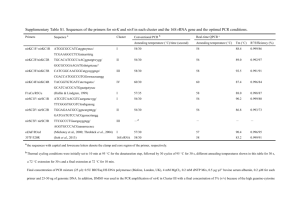
Genomic database searches: ITmD37E sequences were
advertisement

S1. Methods Genomic database searches: ITmD37E sequences were identified in the Aedes aegypti (Ae. aegypti) (NIAID, Broad Institute, project accession AAGE02000000 at NCBI) and Anopheles gambiae (An. gambiae) (HOLT 2002) whole-genome sequences by the use of RepeatScout, TBLASTN, and BLASTN (ALTSCHUL et al. 1997; PRICE et al. 2005). Culex pipiens quinquefasciatus (C. pipiens) genome trace files (>5X coverage, Sep. 2006) and ESTs (Oct. 2006) were searched by TBLASTN using ITmD37E sequences as queries. Searches were performed through the VectorBase website (www.vectorbase.org). The conceptually translated Open Reading Frame (ORF) from AgamITmD37E_ele1.1 was used as the query for TBLASTN search of databases through NCBI to find ITmD37E sequences from other taxa. Representative ITmD37E sequences from Ae. aegypti and An. gambiae genomic database searches, as well as sequences from PCR and genomic library screens (see below) were submitted to the TEfam website (http://tefam.biochem.vt.edu/tefam/index.php). TEfam is a relational database that was created to facilitate storage and retrieval of mosquito TE information for the TE research community. An element is defined as those sequences having 70% or greater nt identity to a query element copy (e.g. the element AaegITmD37E_Ele4 can have multiple copies described as AaegITmD37E_Ele4.1, AaegITmD37E_Ele4.2, etc.) Element boundaries were determined by alignment and viewing with CLUSTAL_W and CLUSTAL_X (THOMPSON et al. 1997; THOMPSON et al. 1994). Information regarding sequences used in this study can be found in S2. Polymerase chain reaction and cloning: ITmD37E sequences were obtained by Polymerase Chain Reaction (PCR) (Ae. albopictus not shown here) and genomic library screening (described in Shao and Tu, 2001). Genomic DNA used for PCR was isolated using DNAzol (Molecular Research Center). PCR and primers used for amplification of AgITmD37E_Ele1.2 were described previously (SHAO and TU 2001). A single primer AAGYYTGCTYCRTTTARDMTTGG, corresponding to the consensus sequence of the terminal inverted repeats (TIRs) of ITmD37E elements, was used to amplify sequences from Ochlerotatus togoi (O. togoi) and Armigeres subalbatus (Ar. subalbatus). PCR was performed using an AirClean 600 PCR workstation to minimize the possibility of contamination. PCR was also performed in another laboratory de novo to verify that the products were valid. That laboratory had never worked with mosquitoes prior to this time. PCR products were purified from agarose gel after electrophoresis using the Sephaglass Bandprep Kit (Amersham Pharmacia Biotech) and cloned into pGEM-T Easy vector using a TA cloning kit (Promega). Cloned products were sequenced at the Virginia Bioinformatic Institute Sequencing Facility at Virginia Polytechnic Institute and State University (Virginia Tech). Genomic library screening: The source and methods for screening genomic libraries from O. atropalpus, O. epactius, and O. triseriatus were previously described (SHAO and TU 2001). The genomic library of An. gambiae was provided by Shirley Luckhart in the Department of Biochemistry at Virginia Tech (now at UC Davis, CA). The average insert size of this library is approximately 15 kilobases (kb). Libraries for Ae. aegypti, Ae. polynesiensis, O. bahamensis, and Toxorhynchites amboinensis (T. amboinensis) were provided by the laboratory of Dr. Henry Hagedorn at the University of Arizona. All libraries of different species were screened using three different probes (L, M, and N). Probe L was prepared corresponding to the C-terminal coding region of ITmD37E in O. atropalpus (AY038030, primers CGACCRTCCMGTAATGYTTTSGCC and CATTAGGCGGCGGACACC). Probe M corresponds to the entire ORF of an ITmD37E transposon in An. gambiae, which was obtained by PCR using primers ATGGAAGCCGAAAGAAGGGA and GCAAATGTAGCGTTTTCTTCAT, designed according to AL150661 and AL143513 in the STS database. Probe N corresponds to AI637402 (sites from 11 to 252) from the Ae. aegypti EST database, and was obtained by PCR using primers GCCGGTAATTTGTTTGGTG and CCTTTCCACCCGAGACG). All probes were single stranded and labeled using asymmetric PCR. The labeling conditions were performed as described in Tu and Hagedorn (1997). Hybridization and signal detection were performed as in (SHAO and TU 2001). Genomic sequences flanking ITmD37E elements isolated from non-Aedes aegypti and non-Anopheles gambiae genomic libraries were compared and no match to either the Ae. aegypti genome assembly nor the An. gambiae assembly was found. Phylogenetic inference: Phylogenetic inference was performed using MrBayes version 3.1.2 (HUELSENBECK and RONQUIST 2001; RONQUIST and HUELSENBECK 2003). Sequences were aligned with CLUSTAL_X version 1.83 (THOMPSON et al. 1997) using the following parameters: pairwise alignment gap opening=10, gap extension=0.1; multiple alignment gap opening=10, gap extension=0.2. For the ITmD37E phylogeny based on conceptual translations of the ORFs, MrBayes was allowed to pick the best of 10 fixed-rate evolutionary models, resulting in choosing Blosum as the best model (posterior probability = 1.0). 200,000 generations were run to achieve an average standard deviation of split frequencies below 0.01, evidence of convergence of two independent tree searches. The potential scale reduction factor (PSRF) was 1.0 for all parameters, demonstrating an attainment of a good sample from the posterior probability distribution. Alignments used for phylogenetic inference can be found in S3. Only those mosquito sequences that had intact coding regions were included in the phylogeny, except for AaegITmD37E_Ele4.1, AgamITmD37E_Ele2 and AgamITmD37E_Ele3, which were obtained from whole-genome sequence projects. Whole ORFs were used for ITmD37E phylogenetic inference when available. Of the 38 previously submitted ITmD37E sequences, only those that could be aligned with confidence were included. The 7 excluded sequences contained indels or were too divergent for alignment. The accessions and species for the excluded sequences are: AY09079, Ae. aegypti; AY09061, Ae. albopictus; AY09068, Ae. polynesiensis; AY09073, Ar. subalbatus; AY09051, AY09052, Ae. atropalpus; AY09054, T. amboinensis. The Modeltest server version 3.7 (POSADA and BUCKLEY 2004; POSADA and CRANDALL 1998) was used to determine the best nt evolutionary model according to a calculated Aikaike Information Criteria (AIC) score (ITmD37E: Hasegawa-KishinoYano plus Gamma, Vg-C: General Time Reversible plus gamma). To obtain ITmD37E and Vg-C phylogenies, MrBayes was run for 1,000,000 and 100,000 generations, respectively. For these runs, the average standard deviation of split frequencies was below 0.01 and the PSRF was 1.0. For construction of host phylogeny a 987 bp region (excluding intron sequence) of vitellogenin C (Vg-C), a single copy yolk protein-encoding gene, was obtained from previous work (ISOE 2000) and by PCR. All Vg-C sequences except for Ae. simpsoni and O. togoi were obtained from (Isoe 2000). Ae. simpsoni and O. togoi Vg-C sequences were amplified by PCR in our laboratory according to the methods of Isoe 2000. The following describes methods according to Isoe’s 2000. Degenerate primers were designed to amplify a 1.1 kb region that is specific for the Vg-C ortholog that includes the second intron. Primers Vg-C-specific forward (5’(A/G)A(T/C)(A/G)TNAA(A/G)CA(T/C)CCNAA(A/G)G-3’), Vg-C-specific reverse (5’TC(A/G)TT(T/C)TG(T/C)TT(A/G)TA(T/C)TG(A/G/T)CC-3’), and Aedes universal reverse (5’-C(A/G)T(A/G)CCA(A/G)CANTCNCCCAT-3’) were used in nested PCR. The first PCR used the Vg-C-specific forward and reverse primers for 1 cycle at 94˚C for 3 minutes, 32 cycles at 94˚C for 1 minute, 50˚C for 1.5 minute, and 1 extension cycle at 72˚C for 10 minutes. The second PCR used the Vg-C-specific and Aedes universal reverse primers with the same conditions except that the annealing temperature was increased to 54˚C. PCR products were cloned into pGEM-T Easy (Promega) and sequenced at the VBI core facility (Virginia Tech). Literature Cited ALTSCHUL, S. F., T. L. MADDEN, A. A. SCHAFFER, J. ZHANG, Z. ZHANG et al., 1997 Gapped BLAST and PSI-BLAST: a new generation of protein database search programs. Nucleic Acids Res 25: 3389-3402. HOLT, 2002 The genome sequence of the malaria mosquito Anopheles gambiae. Science 298: 129-149. HUELSENBECK, J. P., and F. RONQUIST, 2001 MRBAYES: Bayesian inference of phylogenetic trees. Bioinformatics 17: 754-755. ISOE, J., 2000 Comparative Analysis of the Vitellogenin Genes of the Culicidae, Ph.D. Dissertation, pp. 201 in Insect Science. University of Arizona, Tucson. POSADA, D., and T. R. BUCKLEY, 2004 Model selection and model averaging in phylogenetics: advantages of akaike information criterion and bayesian approaches over likelihood ratio tests. Syst Biol 53: 793-808. POSADA, D., and K. A. CRANDALL, 1998 MODELTEST: testing the model of DNA substitution. Bioinformatics 14: 817-818. PRICE, A. L., N. C. JONES and P. A. PEVZNER, 2005 De novo identification of repeat families in large genomes. Bioinformatics 21 Suppl 1: i351-i358. RONQUIST, F., and J. P. HUELSENBECK, 2003 MrBayes 3: Bayesian phylogenetic inference under mixed models. Bioinformatics 19: 1572-1574. SHAO, H., and Z. TU, 2001 Expanding the diversity of the IS630-Tc1-mariner superfamily: discovery of a unique DD37E transposon and reclassification of the DD37D and DD39D transposons. Genetics 159: 1103-1115. THOMPSON, J. D., T. J. GIBSON, F. PLEWNIAK, F. JEANMOUGIN and D. G. HIGGINS, 1997 The CLUSTAL_X windows interface: flexible strategies for multiple sequence alignment aided by quality analysis tools. Nucleic Acids Res 25: 4876-4882. THOMPSON, J. D., D. G. HIGGINS and T. J. GIBSON, 1994 CLUSTAL W: improving the sensitivity of progressive multiple sequence alignment through sequence weighting, position-specific gap penalties and weight matrix choice. Nucleic Acids Res 22: 4673-4680.