Supplementary Text: Development of the IGS locus
advertisement

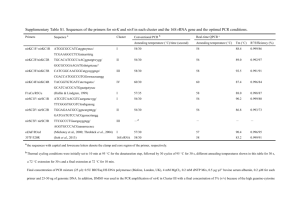
SUPPLEMENT: Additional Loci: Development of the IGS Locus General Methods: The nuclear ribosomal RNA intergenic spacer regions were amplified using primer pairs LR20R/5SA (for IGS 1) and 5SDNA/invSR1R (for IGS 2) (White et al., 1990). Initial PCRs amplified many bands. Bands were cut and cloned using pGEM-T easy vectors and JM109 competent cells (Promega Corporation, Madison, WI) following manufacturer’s specifications. Cloned PCR products were plated on LB media containing ampicillin, IPTG, and X-Gal, and allowed to grow at 37˚C overnight. For each cloned PCR product, between 10 and 40 colonies were amplified and sequenced using vector primers SP6 and T7. PCR parameters used to amplify colonies were as described in the text of this manuscript, except no PCR enhancer and no other additives were used, and 0.5 U/µl of Econotaq replaced Platinum Taq. Thermalcycler parameters for PCR of colonies was as described in the text. Obtaining sequence data from the Intergenic Spacer region presented several challenges. In the first place, the IGS1 and IGS2 are very large (about 1500-2000 base pairs each), and some material, especially from older tissue, was difficult to amplify. The use of Platinum Taq and the bulking of several weak PCR products helped to alleviate these problems. However, the greatest challenge was the massive diversity of the IGS locus within an A. phalloides genome. Using the original primers, it became clear that between 2-4 IGS ‘types’ are housed within the genome of a single individual, moreover, original primers also amplified non-target DNA. Many of the sequences taken from colonies could not be aligned to any of the more conserved flanking regions of the IGS (beyond the primer sequence). Parts of the 5S region appear to have motifs in common with other regions of a genome (Nazar and Wong 1985), and the primers appear to amplify non-target regions of the A. phalloides genome. It is not clear what these other regions of the genome may be, as non-target sequences could not be identified with NCBI BLAST searches. To solve this problem, we used alignments of published fungal 28S and 5S sequences to design multiple additional primers at the end of the 28S region and within the 5S region (see Supplementary Table 1, Supplementary Figure 1). With these new primers, non-specific amplification was not as common, however, it was still necessary to clone PCR products. Non-specific amplification was a greater problem in the 28S region when amplifying IGS 1, and so IGS 2 became the target of our research. Primers used to create clone libraries of the IGS 2 were either 5Sphl1F or 5Sphl2F and invSR1R (Supplementary Table 1, Supplementary Figure 1) To verify the identity of sequenced IGS 2 alleles, an alignment was made of the 5S region using 17 ascomycete and basidiomycete genera from the 5S ribosomal DNA Database (Szymanski et al. 2002; URL: http://www.man.poznan.pl/5SData/, Supplementary Table 2). Our sequences were compared to this alignment and also the inferred canonical sequence of 5S derived from sequences of protist, plant and fungal lineages (Yu and Thorne 2006). Parts of this alignment were highly conserved across all fungi, and only IGS 2 types whose linked 5S alleles could be aligned to these conserved motifs and the canonical structure were included in our analysis. To be sure that all possible IGS 2 types were recovered from every individual, we also developed primers to specifically target the different IGS 2 types (Supplementary Table 3). Several 5S forward primers were designed using sequences obtained in the early part of the study, and direct sequencing of unique IGS 2 types used PCR and sequencing protocols as described in the text, with the exception of a shorter extension time of one minute. Defining Types: New types were defined when they could not be aligned to existing IGS 2 sequences. Although small motifs were sometimes shared among types, a gross alignment across the sequence among types was not possible, and even the shared motifs were typically found in different parts of each type. Pairwise distances between types average about 65%-70%, versus about 0.5-3% within a type. Distances of 65-75% are only slightly better than random; on average two unrelated sequences will match at 25% of all sites (and be different at 75% of all sites). Dominance of Types: We discovered that certain types in some individuals could only be detected by probing directly with our type-specific internal primers. This was not a function of not sequencing enough clones. For example, only two types were found from over 30 clones sequenced from the Corsican individual (Cor02.1), but another two types were discovered using direct sequencing with type-specific primers. To determine if the differential success of sequencing certain types from some individuals was caused by a low copy number of these types, PCRs were repeated with some of the IGS-type specific primers using fewer cycles (25 versus 35 in the original). When fewer PCR cycles were used to try and amplify a rare type, it did not work, suggesting that in fact these types exist in extremely low copy numbers within an individual. LITERATURE Nazar RN, Wong WM (1985) Is the 5S RNA a primitive ribosomal RNA sequence? Proceedings of the National Academy of Sciences of the USA, 82, 5608-5611. Szymanski M, Barciszewska MZ, Barciszewski J, Erdmann VA (2000) 5S ribosomal RNA Database Y2K. Nucleic Acids Research, 28, 166-167. White TJ, Bruns T, Lee S, Taylor JW (1990) Amplification and direct sequencing of fungal ribosomal RNA genes for phylogenetics. In: PCR Protocols: A Guide to Methods and Applications (eds. Innis MA, Gelfand DH, Sninsky JJ, White TJ) pp. 315-322. Academic Press, Inc., New York. Yu J, Thorne JL (2006) Dependence among sites in RNA evolution. Molecular Biology and Evolution, 23, 1525-1537.