Strategies for the Verification of Ensemble Forecasts
advertisement

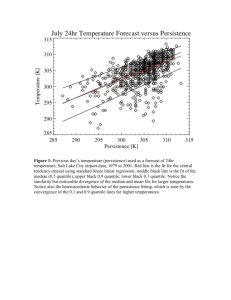
STRATEGIES FOR THE VERIFICATION OF ENSEMBLE FORECASTS (Laurence J. Wilson) Environment Canada Abstract: The subject of ensemble forecast verification naturally divides itself into two parts: verification of the ensemble distribution of deterministic forecasts and verification of probability forecasts derived from the ensemble. The verification of the ensemble distribution presents unique problems because it inevitably involves comparing the full ensemble of forecast values against a single observation at the verifying time. A strategy to accomplish this kind of evaluation of the ensemble distribution is described, along with other methods that have been used to evaluate aspects of the ensemble distribution. By comparison, evaluation of probability forecasts extracted from the ensemble is simpler; any of the existing measures applied to probability forecasts can be used. Following the work of Murphy, the attributes of probability forecasts are described, along with a set of verification measures which are used to evaluate these attributes. Examples of application of each technique to ensemble forecasts is shown, and the interpretation of the verification output is discussed. The verification methods described include the Brier and rank probability scores, skill scores based on these, reliability tables, and the relative operating characteristic (ROC), which has been widely used in the past few years to evaluate ensemble forecasts. 1. Introduction The subject of evaluation of ensemble forecasts naturally divides into two parts, according to the use of ensemble forecasts. Since the output of an ensemble forecast system is a distribution of weather elements, valid at each time and place, it is necessary to consider those methods that apply to the evaluation of the ensemble distribution itself. These are discussed in section 2. Then, since ensemble forecasts are often used to estimate probabilities, it is also necessary to consider methods that are used to evaluate probability forecasts. These are discussed in section 3. 2. Verification of the ensemble distribution Until the advent of ensemble prediction systems, verification of forecasts from numerical weather prediction models involved simply matching the model forecast in space and time with the corresponding observation. With a single model run, there could usually be a one-to-one match between forecast and observation, on which numerous quantitative verification measures could be computed. An ensemble system produces a distribution of forecast values for each point in time and space, but there is still only a single observation value. The challenge of ensemble verification is to devise a quantitative method to compare the distribution against specific observation values. As a starting point, one might consider what constitutes an “accurate” forecast distribution. What characteristics should the forecast distribution possess in order to be considered of high quality as a forecast? Two desirable characteristics of ensemble distribution, “consistency” and “non-triviality” have been stated by Talagrand, 1997 A forecast distribution is said to be consistent if for each possible probability distribution f, the a posteriori verifying observations are distributed according to f in those circumstances when the system predicts the distribution f. (Talagrand, 1997). In other words, if one could compile a sufficiently large set of similar cases, where similar distributions had been forecast by the ensemble system, then the distribution of observations for those cases should match the ensemble distribution. In practice, it is nearly impossible to compile a sufficiently large enough sample of cases that are similar enough because of the large number of degrees of freedom in each distribution, so it would be very difficult to verify consistency directly. The second desirable characteristic of ensemble forecasts stated by Talagrand is “non-triviality”. An ensemble forecast system is said to be non-trivial if it forecasts different distributions on different occasions. This is similar in some ways to the concept of sharpness in a forecast system: the system must give different forecasts for different times and locations. A system which always forecasts the climatological value of the weather element, or, the climatological distribution, would be a trivial forecast system. 2.1 A probability-based score and skill score Wilson et.al (1999) proposed a verification system for ensemble forecasts that attempts to evaluate the ensemble distribution as a basis for estimating the observation value. The concept is illustrated in Figure 1. In Figure 1, three hypothetical distributions are shown, a relatively sharp distribution that might be associated with a short range ensemble forecast, a distribution with greater variance, as might be predicted at medium range by an ensemble system, and a broader distribution which might be the climatological distribution for that date and place. The verifying observation is indicated as -3 degrees C. If +/- 1 degree C is considered a sufficiently accurate forecast for temperature in this case, one can determine the forecast probability within one degree of the observation using each of the distributions (The shaded areas on the figure). Then , this probability can be used directly as a score for the forecast. The probability determined from the climatological distribution can represent the score value for a climatological forecast, and can be used to build a skill score in the usual format: skill score f scorec 1 scorec where scoref is the score value for the forecast, and scorec is the score value for climatology. Figure 1 shows normal distribution curves. If the ensemble is small enough, better estimates of the probability can be obtained by first fitting a distribution (Wilson et. al (1999) suggest normal for temperature, gamma for precipitation and wind speed), then calculating probabilities from the distribution. Experiments with data from the 51-member ECMWF ensemble system indicated that, for ensembles of this size, it is not necessary to fit a distribution; use of the empirical ensemble distribution gave similar results. Figure 1. Schematic representation of probability scoring system as it might be applied to ensemble temperature forecasts at a specific location. Example shows probabilities (hatched areas) for the observed value +/-1 degree C. This type of scoring system evaluates the probability distribution in the vicinity of the observation only; the shape and spread of the distribution far from the observation value are not considered directly. The score is sensitive to both the spread and the location accuracy of the ensemble with respect to the observation: If the observation coincides with the ensemble mode, a relatively high score value can be obtained, especially if the spread (variance) of the ensemble distribution is small. On the other hand, if the forecast is missed in the sense that the observation does not lie near a mode of the ensemble, then the probability score will be low. In such cases, greater ensemble spread, corresponding to an indication of greater uncertainty can lead to higher scores than would be the case for lower ensemble spread. A perfect score (probability=1.0) occurs when all the ensemble members predict within the acceptable range; that is, the score is maximized when the ensemble predicts the observed value with confidence. -3- Figure 2 shows an example of the scoring system applied to a specific ensemble forecast for a specific station, Pearson International Airport, Toronto. The histogram shows the actual ensemble distribution of temperature forecasts for this location, valid May 17, 1996. A normal distribution has been fitted to the ensemble (crosses in the figure), and to the climatological temperature distribution for the valid date (circles). The verifying temperature, indicated by an X on the abscissa, was 11 degrees C. For the short range forecast, (left side), the verifying temperature is close to the mean of the distribution, giving a probability score of 0.27 of occurrence within 1 degree C of the observation. The observed temperature was near normal; the corresponding score value for climatology is 0.19. The skill score in this case, obtained from (1) is 0.11. The forecast has achieved positive skill by forecasting a sharper distribution than the climatological distribution. The right side of figure 2 shows the fitted distributions and scores for a 7-day ensemble forecast verifying on the same day. This forecast is about as sharp as the shorter range one, (i.e., the spread of the fitted and empirical distributions are about the same as for the short range foreast, but the ensemble has totally missed the observation. All the members forecast temperatures too low. As a result, the score value is 0.0 in this case, and the climatological score is 0.19, same as before. The skill score is negative, -0.23, because the forecast has missed in a situation which is climatologically normal. Figure 2. Verification of 72 h (left) and 168 h (right) ensemble 2 m temperature forecasts for Pearson International Airport. The histogram represents the actual ensemble distribution, the fitted normal distribution is represented by crosses, and the corresponding climatological distribution is represented by circles. The computed score (sf), skill score (ss) and climate score (sc) are all shown in the legend. The observed temperature is shown by the X on the abscissa. For ensemble precipitation amount forecasts (QPF), it has been suggested that a gamma distribution might be more appropriate than the normal distribution (Wilson et al, 1999). Figure 3 shows an example of the probability score and skill score computed for a 72h ensemble forecast of precipitation accumulation over 12h. A gamma distribution has been fit to both the ensemble forecast and the climatological distribution of 12h precipitation amounts. The score and skill score were computed in this case using a geometric window for a correct forecast. The lower boundary of the correct range was set to 0.5 times the upper boundary, so that the forecast is considered correct if it lies between (observation/sqrt (2)) and (observation * sqrt(2)). This takes account of the fact that small differences in the predicted precipitation are more important for small amounts than for large amounts. Under this scheme, for example, ranges such as (2.0, 4.0), (5.0, 10.0) and (20.0, 40.0) might all be used, depending on the observed precipitation amount. The factor width of 2 seemed to be strict enough in tests, but other factors could be used to determine the window for a correct forecast. Tests using a smaller window factor of 1.5 indicated that the results are not strongly sensitive to the size of the window in this range. It is nevertheless important to report the selected window size with the results so that they can be interpreted. In Fig. 3, the ensemble has indicated that some precipitation is likely, whereas the climatological distribution favours little or no precipitation. 2.0 mm of precipitation was observed on this occasion, and so the forecast shows positive skill of 0.36. The full resolution operational model (ECMWF) has also predicted precipitation, a higher amount than all the members of the ensemble. The window for a correct forecast is (1.414, 2.828), geometrically centered on the observed value of 2.0 mm. The deterministic forecast from the full resolution model lies outside this window, and would have to be assigned a score of 0.0. Thus the ensemble has provided a more accurate forecast than the full resolution model in this case. Figure 3. Ensemble distribution (bars), fitted gamma distribution (crosses) and corresponding climate distribution (circles) for 72 h quantitative Airport. Score value (sf), climate score (sc) and skill score -4- (ss) are given in the upper right precipitation forecast for Pearson International corner, along with the deterministic forecast from the ECMWF T213 model and the verifying observation. The examples shown so far have been for single ensemble forecasts at specific locations. Of course, the score and skill score can be computed over a set of ensemble forecasts and used to evaluate average performance over a period and for many locations. One such experiment used the probability score to compare the performance of the ECMWF ensemble and the Canadian ensemble on the same period in 1997. Table 1 summarizes the data used in the experiment. Table 1. Sample used in comparison of the ECMWF 51 member and Canadian 9 member ensemble forecasts. Verification period Stations Parameters Ensemble size Ensemble model Projections ECMWF Data 151 days, Jan to May, 1997 23 Canadian stations 2m temperature, 12h precipitation, 10m wind 51 member ensembles T106 model 10 days (12h) from 12 UTC Canadian Data 148 days, Jan to May, 1997 23 Canadian stations 2m temperature, 12h precipitation, 10m wind 9 member ensembles T63 model 10 days (12h) from 00 UTC Figure 4 shows an example from this verification, again for Pearson International Airport. Figure 4a, for the Canadian ensemble shows that the skill remains positive to about day 6 with respect to climatology, and furthermore is asymptotic to 0 skill. One would expect this skill score to be asymptotic to 0 skill as the ensemble spread approaches the spread of the climatological distribution, and the conditioning impact of the initial state is lost It is also an indication that the model’s climatology approaches the observed climatology. (i.e., the model’s temperature forecasts are unbiased) Score values and skill is higher for forecasts verifying at 12 UTC, which suggests the Canadian ensemble system forecasts early morning temperatures near the minimum temperature time more accurately than early evening temperatures. Figure 4b, for the 51-member ECMWF ensemble, shows positive skill with respect to climatology throughout the 10-day run, though the skill is near 0 by day 7 of the forecast. The ECMWF model also exhibits a diurnal variation in the accuracy and skill, but in the opposite sense. That is, forecasts in the evening are more accurate than in the early morning. This might be expected because the ECMWF model is tuned for the European area, which has a maritime climate. Toronto’s climate is more continental in nature, with stronger nighttime cooling than might be experienced in a maritime climate. Figure 4c shows verification results using the score and skill score for 60-member combined ECMWF and Canadian ensembles. Since the scores for the separate ensembles are similar in magnitude, combining the ensembles doesn’t have a large effect overall on the scores. The combined result seems to be as a weighted average of the two individual results. The diurnal effect has been mostly eliminated. Figure 4. Verification of Canadian (a), ECMWF (b) and combined (c) ensemble 2m temperature forecasts for Pearson International Airport for January to May, 1997. Using the score over a set of precipitation amount forecasts (12h accumulation) indicated somewhat lower skill for precipitation forecasting than for temperature forecasting. Figure 5 shows three examples of score and skill score values averaged over the five month test period, for three Canadian stations. The verification was carried out using a window factor of 2.0. At St. John’s Newfoundland, on Canada’s east coast, the skill was slightly positive until about day 2 of the forecast, then slightly negative. Once again, the score values seemed to be asymptotic for longer projections, but tending towards a negative value rather than 0. For Toronto and Winnipeg, the skill was never positive at any -5- projection, and the Winnipeg results are poorer than the Toronto results. Both show a strong diurnal variation, which can be attributed to differences in the observed frequency of precipition in the 00 UTC and 12 UTC verifying samples. The performance differences among these stations are most likely related to the differences in the climatology of precipitation occurrence. At St, John’s, the frequency of occurrence of precipitation is relatively high; this station has a maritime climate. Toronto and especially Winnipeg have more continental climates with generally lower frequencies of precipitation occurrence. In terms of the ensemble forecast, the negative skill is likely caused by too many ensemble members forecasting small amounts of precipitation in situations when none occurs. These are the situations when the climatological distribution, which favours the non-occurrence of precipitation, will have higher accuracy. In other words, it is possible that both models are biased towards forecasting too much precipitation or forecasting a little precipitation too often, since the skill score is asymptotic to negative values. To check this, it would be worthwhile to compare the climatological distribution with the predicted distribution compiled from all the ensemble forecasts. The above results show that the score and the skill score are quite sensitive to differences in performance of the ensemble. It is also relatively easy to interpret the score calues, even for a single forecast. The score applies to any variable for which observations exist. Figures 6 to 8 illustrate its diagnostic use for verification of 500 mb height forecasts. For this experiment, the score was calculated at every model gridpoint, using the analysis to give the verifying heights. After some experimentation with the window width, 4 dm was chosen as the best compromise between smoothness of the result and strictness of the verification. At 2 dm, every small scale deviation in the score values was visible with the result that the spatial distribution of the score was too noisy, while at 6 dm, forecasts tended to be “perfect” well into the forecast period, and spatial variations in the score did not show up at all in the shorter range forecasts. Figure 5. Verification of 60 member combined Canadian-ECMWF 12h quantitative precipitation forecasts as a function of projection time, for three Canadian stations, over the period January to May, 1997. Both score values (top) and skill score values (bottom) are shown in Figure 6 - Probability score values for a 36 h 500 mb height ensemble forecast, using the ECMWF ensemble. Figure 6 shows an analysis of the score values for a 36 h 500 mb height forecast over North America and adjacent oceans, using the ECMWF ensemble and the Canadian analysis. There are two main features of note in these results. First, there are two large areas, one over the eastern Pacific and the other over the Great Lakes area where the score values drop from 100 to low values. Second, there are three small areas in the tropics and a large area in the Arctic where the score values drop suddenly to 0. These results can be explained in comparison to the verifying analysis (Fig. 7) and the analysis of the ensemble standard deviation (Fig. 8). Figure 7 shows two 500 mb troughs which correspond closely in position to the large areas of lower score values in the mid-latitudes. Evidently, the ensemble was unsure of the location or shape of these features, and this increased uncertainty results in lower scores in these locations. This is supported by Fig. 8, which shows higher ensemble spread in the vicinity of the two troughs. On the other hand, there is no indication in Figure 8 of any increased ensemble spread in the vicinity of the other areas of low score values in the tropics and the arctic. Thus, it is evident that these are areas where the ensemble forecast has “missed”; all or nearly all the members lie outside the window for a correct forecast. Figure 7. Verifying analysis for the case of Figure 6. 500 mb heights are in dm. Figure 8. Standard deviation of the ensemble forecast for the case shown in Figure 6, in dm. 2.2 Rank Histogram The rank histogram (sometimes called Talagrand diagram) is a way of comparing the ensemble distribution with the observed distribution over a set of cases, preferably a large set of cases. To construct the histogram, the ensemble forecast values of the element being assessed are first ranked -6- in increasing order. For an ensemble of N members, this defines N+1 intervals where the first and last are open-ended and the rest are the intervals between successive pairs of ensemble members. For each ensemble forecast, the interval containing the observed value is determined and tallied. The number of occurrences of the observation within each interval over the whole sample is plotted as a histogram. If it is assumed that each of the N+1 intervals is equally likely to contain the observation, then the rank histogram would be expected to show a uniform distribution across the N+1 categories, and this would indicate that the spread of the ensemble distribution is on average equal to the spread of the distribution of the observations in the verifying sample. The rank histogram of Fig. 9 shows a ushaped distribution, with relatively higher frequencies of occurrence of the observation in the extreme categories. That means that the observation lies outside the whole ensemble more frequently than would be expected under the assumption that all intervals are equally likely. This is usually interpreted to mean that the ensemble spread is too small; that the ensemble does not cover the whole range of possible outcomes often enough. Figure 9. An example of a rank histogram, for the ECMWF 50 member ensemble system, 6 day forecast of 850 mb temperature. It should be noted that the rank histogram does not constitute a true verification system. It would be possible to generate a perfect (flat) rank histogram simply by randomly selecting the verifying interval, without regard for the observed value of the variable. 2.3 Verification of individual members of the ensemble As discussed above, the major problem of verification of the ensemble is related to the matching of an ensemble of forecast values with a single observation. To get around this issue, it has always been tempting to reduce the information in the ensemble to a single value to match to the verifying observation, for example, by using the ensemble mean. Once the problem is reduced to matching of single values, then any of the standard verification measures that are used to verify single deterministic forecasts can be used, such as mean absolute error, root mean square error, anomaly correlation etc. However, comparing an ensemble mean, which is a statistic of the ensemble, with a single observation is not appropriate, for two main reasons: The ensemble mean has different statistical characteristics than the verifying observation, for example, lower associated variance. Because of this, it often verifies well, especially when quadratic scoring rules are used, which is misleading. The ensemble mean is not a trajectory of the model. That is, it is not necessarily true that the ensemble mean field at 24 h represents a physically possible evolution of the atmosphere from the ensemble mean field at 12 h. Aside from the ensemble mean, there are other, more legitimate strategies for comparing single ensemble members with the observation. One might, for example, wish to compare the unperturbed control forecast, generated using the ensemble model, with the output from the full resolution model. The control forecast may begin as the center of the ensemble distribution (when perturbations are added and subtracted to form the ensemble), but it does not remain so through the integration. Verification of the control forecast and comparison with the full resolution model may give information on how the ensemble can be expected to perform with respect to the full resolution model. The control forecast may also be used instead of the ensemble mean as the reference for computation of statistics of the ensemble such as standard deviation or variance. The accuracy of the control forecast is also used in evaluations of the relationship between ensemble spread and forecast accuracy. It is important to know whether it is the ensemble mean or control that is used in order to -7- interpret the results of such studies, because the spread about the ensemble mean is always less than or equal to the spread about the control forecast. Other individual ensemble members that are sometimes looked at in verification are the “best” and “worst” members. Best and worst can be defined in terms of any verification score, and they can be allowed to change from one projection time to the next. This kind of verification is useful to assess the extent to which the ensemble forecast distribution “covered” the actual outcome, and represents a fair way of comparing ensemble forecasts based on different sizes of ensemble. It is also useful in retrospective case studies, to identify the nature of perturbations which either improved or degraded the forecast. Since the “best” and “worst” members are not known a priori, this kind of verification does not give information which can be used as feedback to the interpretation of future ensemble forecasts, but rather is useful as a diagnostic tool. 3. Verification of probability forecasts from the ensemble One of the principal uses of ensemble forecasts is to give probability forecasts of weather elements. These can range from simple probability of precipitation (POP) to probabilities of precipitation categories, probabilities of extreme temperatures or probability of strong winds. Nearly always, the probability is estimated by first defining a category by setting a threshold, then counting the percentage of the ensemble forecasts which meet the criterion defined by the threshold. For instance, a probability forecast of surface temperature anomaly greater than 4 degrees C would be made by determining the percentage of ensemble members for which the temperature forecast is greater than 4 degrees above normal. Probability estimation in this way is a form of post-processing of the ensemble; the information provided by the ensemble distribution has been sampled by integrating that distribution with respect to a particular value defined by the threshold. Therefore, verification of probability forecasts from the ensemble is not equivalent to verification of the ensemble distribution; the distribution is evaluated only in terms of the threshold used for the probability forecast. If the distribution is sampled more completely by defining several thresholds and several categories, and if these probabilities are verified by methods which are sensitive to the distribution of probabilities over the range of categories, then this is closer to an evaluation of the distribution, but it still remains incomplete with respect to the full distribution. In all cases, the estimation of probabilities from the ensemble distribution means evaluating the distribution in terms of those estimates only. Probability forecasts from the ensemble can be evaluated using the same methods as are used for any other probability forecasts. There is quite a large body of literature on this subject, much ot it due to Allan Murphy. The following discussion is therefore relatively brief; further details on verification of probability forecasts can be found in summary documents such as Stanski et al (1989) and Wilks (1995). -8- 3.1 Attributes of probability forecasts Murphy and Winkler (1987), present a framework for verification and point out that all verification information is contained in the joint distribution of forecasts and observations. In practical terms, all the verificaiton information one might need is contained in the complete set of paired forecasts and corresponding observations which forms the verification sample. The framework provides for two types of factorizations of the joint distribution, or, stratifications of the full verification sample. First, it is possible to stratify by forecast value, that is, to define subsets of the verification sample that share a certain set of forecast values. For example, one may speak of the conditional distribution of observations given that the forecast probability value is between 0 and 10%, where the “condition” is imposed on the forecast value. Second, it is possible to stratify by observation. Since observations are usually binary (the event occurred or it didn’t), there are only two conditions which can be placed on the observation. For example, one may speak of the conditional distribution of forecasts given that the event occurred. Here, the condition is imposed on the observations, that is, the dataset has been stratified into two subsets according to whether the event occurred or not. Murphy (1993) defines a set of attributes of probability forecasts that one may wish to assess using the verification tools available. These are listed in Table 2, along with their definition and some of the verification measures that are appropriate for each. Some of these do not imply stratification of the verification dataset (green in the table), while some refer to stratification or conditioning by forecast (red) or observation (grey). Table 2. Attributes of forecasts (after Murphy, 1993) ATTRIBUTE 1. Bias 2. Association 3. Accuracy 4. Skill 5. Reliability 6. Resolution 7. Sharpness 8. Discrimination 9. Uncertainty DEFINITION Correspondence between mean forecast and mean observation Strength of linear relationship between pairs of forecasts and observations Average correspondence between individual pairs of observations and forecasts Accuracy of forecasts relative to accuracy of forecasts produced by a standard method Correspondence of conditional mean observation and conditioning forecasts, averaged over all forecasts Difference between conditional mean observation and unconditional mean observation, averaged over all forecasts Variability of forecasts as described by distribution forecasts Difference between conditional mean forecast and unconditional mean forecast, averaged over all observations Variability of observations as described by thedistribution of observations RELATED MEASURES bias (mean forecast probability-sample observed frequency) covariance, correlation mean absolute error (MAE), mean squarred error (MSE), root mean squared error, Brier score (BS) Brier skill score, others in the usual format Reliability component of BS, MAE, MSE of binned data from reliability table Resolution component of BS Variance of forecasts Area under ROC, measures of separation of conditional distribution; MAE, MSE of scatte plot, binned by observation value Variance of observations Probability verification methods that are often used to assess these attributes are surveyed in the following sections. -9- 3.1 Scores and skill scores The Brier score is most commonly used for assessing the accuracy of binary (two-category) probability forecasts. It is in fact misleading to use the Brier score for assessing multi-category probability forecasts; the Rank Probability Score (RPS- see below) is preferred for this purpose. The Brier score is defined as: F ij Oij 2 PS N where the observations Oij are binary (0 or 1) and N is the verification sample size. The Brier score has a range from 0 to 1 and is negatively-oriented. Lower scores represent higher accuracy. Using a little algebra, the Brier score can be partitioned into three components, 1 PS N F k O k nk k 1 ij K 2 O k O 2 O O kij 2 As represented here, the sample has been stratified into K bins according to the probability forecast value, the overbars refer to averages over the bins if there is a subscript and over the whole sample if there is no subscript. The sample size in bin k is given by nk. The three terms of the partitioned Brier score are, from left to right, the reliability, the resolution and the uncertainty, all as defined in Table 2. The first two of these terms depend on the forecast through the binning of the data, but the third term depends only on the observations, which means that the forecaster has no control over the value of this term. It is therefore not advisable to compare Brier scores that have been computed on different samples, because the uncertainty term will vary among samples with different climatological frequencies of occurrence of the event, and cause variations in the Brier score which have nothing to do with the accuracy of the forecast. The Brier Skill Score is in the usual skill score format, and may be defined by: BSS PS PS PS C C F 100 1 100 C ij Oij F ij Oij 2 ij 2 ij where the C refers to climatology and F refers to the forecast. It is not necessary to use climatology; any standard forecast can be used in the formulation of the skill score. More recently, skill scores in this format have been used with one forecast system as a standard, in order to determine the percent improvement of a competing forecast system. Probabilities from the ensemble could be compared in this way to probability forecasts from statistically interpreted NWP model output, for example. Figure 10 shows an example of the use of the Brier and Brier skill scores to evaluate ensemble geopotential height forecasts (from Buizza and Palmer, 1998). In this case, the event was defined as “500 mb geopotential height anomaly greater than 50 m” over Europe. The scores were calculated to show the impact of increasing ensemble size on the accuracy and skill of the forecast. Brier skill drops to 0 by day 7 for some of the tests and by day 8 for the others. Figure 10. Brier score (top) and Brier skill score (bottom) over Europe for a 45-day period for different ensemble sizes up to 32 members. (After Buizza and Palmer, 1998) - 10 - The Rank Probability Score (RPS) is intended for verification of probability forecasts of multi-category events. In the computation of this score, the categories are ranked, and the contributions to the score values are weighted so that proximity of the verifying category to the bulk of the probability weight is given credit. For example, in a four category problem, if category 3 is observed, a forecast of 90% probability of occurrence of category 2 will score higher than a forecast which assigns 90% probability to category 1, even though both forecasts are incorrect. The RPS for a single forecast of K mutually exclusive and exhaustive categories is defined as follows: 2 i 1 K i RPS Pn d n K 1 n 1 i 1 n 1 where Pn is the probability assigned to category n and dn is 1 or 0 according to whether category n was observed or not. Like the Brier score, the RPS has a negative orientation and a range of 0 to 1. The ranked probability skill score (RPSS) is the corresponding skill score, and is the same as the BSS except it is based on the RPS, RPSS RPS S RPS F RPS S Figure 11. Rank Probability Skill Score for 10-category probability forecasts of 500 mb height anomaly over Europe for 45 days. Curves are for 5 different ensemble sizes (after Buizza and Palmer, 1998). The RPS and RPSS are quite useful for evaluating ensemble systems because multi-category probability forecasting involves sampling the ensemble distribution at several points; if a large number of categories is used, then the RPS and RPSS give a good evaluation of the full ensemble distribution with respect to the observation. Figure 11 shows an example of the RPSS, based on 10 categories, for probabilities of ranges of 500 mb height anomaly. The skill is with respect to climatology and remains positive throughout the 10 day model run period. 3.2 Reliability Tables A reliability table is a graphical way of evaluating the attributes reliability and sharpness of probability forecasts, and, to a lesser extent, resolution. The tables are nearly always used for two-category forecasts (binary), but a multi-category extension has recently been published (Hamill, 1997). The diagram is constructed by first stratifying the verification sample according to forecast probability, usually into deciles, or perhaps broader categories if there isn’t enough data to support stratification into 10 categories. The observed frequency of the event within each subsample is plotted against the forecast probability at the midpoint of the category. The sample size in each probability category is plotted as a number next to the corresponding point on the graph and/or a histogram is plotted along with the graph which gives the sample size or frequency of each category in the overall verification sample. The climatological frequency of occurrence of the event in the whole sample is represented on the graph by a horizontal line. Interpretation of reliability tables is discussed fully in Stanski et al (1989). Essentially, perfect reliability is indicated by forecast probability=observed frequency, which is true for all points on the 45 degree line. Points above the 45 degree line represent underforecasting of the event (probabilities too low) - 11 - and points below the 45 degree line represent overforecasting (probabilities too high). Reliability for probability forecasts is analagous to bias for continuous variables; it indicates the tendency of the forecast probability value to agree with the actual frequency of occurrence. Unlike continuous variables, however, reliability, and many other verification measures for probability forecasts cannot meaningfully be evaluated on a single forecast. Reliability tables require relatively large verification sample sizes to get stable estimates of the observed frequency of occurrence in all probability categories. Reliability is one of the components of the Brier score as shown above, and can be calculated quantitatively using the first term in the partitioned Brier score. Sharpness is also indicated on a reliability table, by the distribution of forecast probabilities, displayed either as a histogram or numerically on the reliability graph. Sharpness is measured by the spread (variance or standard deviation) of the probability forecasts in the sample. It is a function only of the forecasts, and therefore does not carry any information about the quality of the forecasts, only about their “decisiveness”. In terms of the histogram, sharp forecasts (best) are indicated by a u-shaped distribution: The greater the frequency of use of the extreme probabilities in the sample, the sharper the forecasts. A categorical (or deterministic) forecast is sharp since probabilities of only 0 or 100% are assigned to the values of the variable. At the other end of the spectrum, a forecast with no sharpness is one where the same probability value is used all the time. Reliability and sharpness can usually be traded off in any forecast system. For example a conservative forecasting strategy which does not often forecast the extremes of probability may well be reliable, but is not sharp. Generally, if one attempts to increase the sharpness, forecasts may become less reliable, especially forecasts of extreme probabilities. Reliability is often regarded as more important than sharpness; a forecast system that is sharp but not reliable is in a sense an overstatement of confidence. On the other hand, a forecast of climatology is perfectly reliable but has no sharpness and is not very useful. An optimal strategy would be to ensure reliability first, then increase the sharpness as much as possible with out sacrificing significantly on reliability. The following are some examples of reliability tables as applied to ensemble forecasts. Figure 12. Reliability tables for verification of probability of precipitation > 1 mm in 24 h (left) and > 5 mm in 24 h (right), for three months of 6-day European forecasts from the ECMWF ensemble system. Figure 12 shows two reliability tables for an earlier version of the ECMWF ensemble system, for events “greater than 1mm precipitation in 24 h” and “greater than 5 mm precipitation in 24 h. The climatological frequency is represented by the horizontal line in each case. For precipitation greater than 1 mm, there is fair reliability in the forecasts up to about 70%, but the higher probability values are overforecast. The 0 skill line on the diagram rperesents the locus of points where the reliability and resolution components of the Brier score balance each other, leaving only the uncertainty component. This means that the skill with respect to the climatology goes to 0. The skill scores are shown on the figure; it can be seen that the forecasts for the 5 mm threshold are indeed near the 0 skill level. Both curves show some tendency to underforecast low probabilities and overforecast high probabilities. This is a typical pattern for forecasts which exhibit less-than-perfect reliability. Figure 13. A reliability table for probability forecasts of 850 temperature anomalies less than -4 degrees, for the European area, verified against the analysis. Dotted lines are lines of equal Brier score. Figure 13 shows a reliability table for probability forecasts of the event “850 mb temperature anomaly less than -4 degrees”, temperatures more than 4 degrees colder than normal. The graph shows these forecasts to be quite reliable, with some overforecasting tendency in the larger probabilities. The dashed lines on the graph are lines of equal Brier score. One could visualize calibration of these forecasts by “moving” the points horizontally toward the 45 degree line. Effectively, this means relabelling the probability categories with the actual observed frequency. The Brier score would improve under such a transformation as can be seen visually from the dotted lines on the figure. - 12 - However, the sharpness would decrease considerably. This is an example of the tradeoff mentioned above; increasing the reliability means reducing the sharpness for a specific set of forecasts. The Brier score improves because it is a quadratic scoring rule, which penalizes larger probability errors more than small ones. Figure 13 also indicates that the distribution of forecasts tends toward a ushape; these forecasts are also quite sharp. This example also shows both sample and long-term climatological frequencies, which helps in interpretation of the Brier score. Figure 14. Example of the effect of calibration of probability forecasts on the reliability table and Brier score. 24 h Ensemble forecasts from the U.S. system for 24 h precipitation totals > 0.1 inch (top) and > 0.10 inch (bottom). Corrected forecasts were obtained using the rank histogram. (after Hammill and Colucci, 1997) Calibration of the probabilities from an ensemble system can be easily done using the rank histogram. The simplest way to calibrate is to compute the rank histogram and replace the equally -spaced increments in the cumulative distribution with the true increments from the rank histogram. For example, an ensemble of 49 members gives 50 intervals assumed equal in probability at 2% each, so that the cumulative probability increases by 2% at each of the ranked ensemble member values. If the true frequency of occurrence of the event in the lowest-ranked category is 13%, then the first threshold becomes 13% instead of 2%. Other thresholds are determined by accumulating each of the actual histogram frequencies in turn. This type of calibration normally leaves open the question of how to model the distribution in the tails, outside the ensemble. Hamill and Colucci (1997) do this by fitting a Gumbel distribution in the tails, and using the rank histogram values in the interior of the distribution. Figure 14 shows an example of relaibility tables from their results, for 24h precipitation probability forecasts. The uncalibrated (left side) forecasts are really not very reliable. After correction, the reliability has been substantially improved, and the Brier score is lower (better) as expected. 3.3 Signal Detection Theory and the Relative operating characteristic curve Signal detection theory (SDT), brought into meteorological application by Mason (1982), is designed to determine the ability of a diagnostic system (in this case the ensemble forecast) to separate those situations when a signal is present (for example, the occurrence of rain) from those situations when only noise is present. SDT measures the attribute “discrimination”, and implies stratification of the dataset on the basis of the observation. SDT is for two-category forecast problems. However, one of its greatest advantages when applied to ensemble forecasts is that it can be used to evaluate both probabilistic and deterministic forecasts in comparison to each other in a consistent fashion. SDT is thus a good way of comparing the performance of the deterministic model and the ensemble. In SDT, the relationship between two quantities is explored, the hit rate and the false alarm rate. These two quantities are computed from the verification dataset. Consider the two-by-two contingency table in figure 15. If the forecast is categorical, there are four possibilities: event is forecast and it occurs ( a “hit”), event is not forecast and it occurs (a “miss”), the event is forecast but doesn’t occur (a “false alarm”) and the event is neither forecast nor occurs (a “correct negative”). From the verification dataset, the values of these four quantities, X, Y, Z, and W respectively are simply the totals of each of these four possible outcomes in the sample. The hit rate and false alarm rate can then be defined as shown on the figure. To use this table, however, the probability forecasts must be turned into categorical forecasts, which means adopting a categorization strategy based on the forecast probability. For example, one strategy might be to “forecast the occurrence of the event if the forecast probability is greater than 30%”. Given such a strategy, each pair of forecast probabilities and occurrences (which are already categorical) can be assigned to one of the four possible outcomes tallied in the contingency table, and totalled over the whole sample. Each different value of the decision threshold, 30%, 40 % etc. leads to a different table, and therefore a different hit rate and false alarm rate. - 13 - Figure 15. 2 by 2 contingency table for determination of hit rate and false alarm rate. Figure 16. Example of the distribution of occurrences and non-occurrences of an event, for deciles of forecast probability. Given the total occurrences of the event and the non-event for each decile of forecast probability, for example, as in Fig. 16, one can calculate X, Y, Z, and W for the different threshold probabilities and plot them on a graph, as in Fig. 17. In Fig. 16, for a decision threshold of 30%, X is the total of the occurrences column below the line, Y is the total occurrences above the line, Z is total nonoccurrences below the line, and W is total non-occurrences above the line. Hit rates and false alarm rates are computed in this way for each probability decile as a threshold. Fig 17 is a plot of the hit rate and false alarm rate. This curve is the (empirical) relative operating characteristic (ROC). One would hope that, as the threshold decreases from 1.0, the hit rate would increase much faster than the false alarm rate, so that the curve stays in the upper left half of the diagram. In fact, the closer the curve is to the left side and top of the diagram, the greater the ability of the system to distinguish between situations where a signal is present from those where only noise is present. Figure 17. An example af an empirical ROC, formed by plotting the hit rate against the false alarm rate for probability decision thresholds 0, 10%, 20%,….90%, 100. The most common measure associated with the ROC is the area under the curve, which is the area of the box between the curve and the lower right corner., expressed as a percentage of the whole area of the box. The closer the curve is to the upper left corner, the greater this area, and the maximum value is 1.0. The diagonal, representing hit rate = false alarm rate (area=0.5) is the “0 skill” line in this context, but we have found in practice that values of the area below 0.7 represent a rather weak ability to discriminate. What is really being measured by the ROC is the difference between the two conditional distributions, the distribution of forecast probabilities given that the event occurred and the distribution of forecast probabilities given that the event did not occur. (for example, Fig. 16) A pair of such distributions is shown schematically in Fig. 18. Visually, it is clear that the variable X (the forecast probability in this case) will form a much better basis for determining the occurrence or non-occurrence of the event if these two distributions are well-separated. The separation of the means of the two distributions is another measure of the discriminating ability of the system. Normally, this is expressed in terms of the standard deviation of the forecast distribution for non-occurrences, but it is directly related to the area measure, and does not provide any additional information. Figure 18. A schematic of the two conditional distributions, for occurrences, f 1(x) and nonoccurrences, f0(x). The random variable X is in this case the probability forecast. The distributions shown are normal with mean and standard deviation (m1,s1) and (m0,s0) respectively. Experiments with the ROC from many fields have shown that the ROC tends to be very close to linear in terms of the standard normal deviates corresponding to the hit rate and false alarm rate. In other words, if one takes the hit rate as a probability (frequency), and calculates (from normal probability tables, for example) the value of the random variable X that corresponds to that probability, do the same for the false alarm rate, then plotting these values instead of the original hit rate and false alarm rate will result in a straight line. To apply the so-called normal-normal model to a specific dataset, one would first convert the empirical hit rate and false alarm rates to standard normal deviate values using the normal probability distribution with parameters mean and standard deviation estimated from the data. Then a straight line can be fitted using a method such as least squares regression. Alternatively, the maximum likelihood method can be used. Once the straight line is determined, then the data can be transformed back to linear probability space, which leads to a smooth curve. - 14 - The normal-normal model implies the assumption that the distributions prior to occurrence and nonoccurrence can at least be monotonically transformed to normal. They do not themselves have to be normal distributions. This means that there can be no multi-modality in the distributions, which is usually a good assumption. For variables such as precipitation, where the ensemble might indicate either no rain or a lot of rain on some occasions (a bi-modal distribution), the normal-normal model might not fit as well, but one is unlikely to incur significant error by using it. One might ask why go to the trouble? Well, the difficulty lies in computing the areas under the ROC. If an empirical curve is used, the data points are joined by straight lines. Compared to the normalnormal model, which implies a smooth curve, calculating the area under the empirical curve would always give an underestimate to a greater or lesser degree depending on the distribution of the points across the range and on the number of points used to estimate the ROC. (Note that (0,0) and (1,1) are always the endpoints of the ROC). This problem becomes significant when ROCs are compared for different forecasts, especially if one of the events has a low frequency of occurrence. The lower the frequency of occurrence of the event, the greater the tendency of the points on the ROC to cluster toward the lower left corner of the diagram. The actual discriminating ability may not be affected, but when the points are not well-spread across the domain of the ROC diagram, the error in the estimation of the area from the empirical curve will be larger. Figure 19. A ROC curve for two forecasts of probability of 6 h precipitation accumulation, 0 to 6 h (circles) and 42-48 h (crosses). Hit rate and false alarm rate are plotted in terms of their corresponding standard normal deviates, using the mean and standard deviation estimated from the data. Figure 19 shows an example of a ROC plotted on normal-normal paper. ROCs are represented there for two sets of precipitation forecasts, for 0 to six hours and for 42 to 48 hours. The areas are 0.856 and 0.767 respectively. As can be seen from the plot, the points really do lie very close to a straight line; this has been noted for ROCs in many fields besides meteorology. Provided there are enough points to estimate the ROC, confidence on the straight line fit is usually much higher than the 99% level. Generally, 4 points are needed; it is not advisable to try to estimate the curve with fewer points. Figure 20 is a schematic of a ROC in linear probability space, represented as a smooth curve. Once the curve has been fitted in standard normal deviate space, the curve is defined, and it is convenient to transform back to linear probability space using many more points, e.g. 100 equally-spaced points, to facilitate drawing the curve. To compare the performance of a deterministic forecast, one can compute the hit rate and false alarm rate directly from the forecast and plot a single point on the graph. If the point lies above the curve, then the deterministic forecast gives a better basis for identifying the occurrence of the event than the ensemble, but only in the vicinity of the plotted point. The ensemble’s performance can be evaluated over all probability thresholds, which normally makes it more useful to a wider variety of weather-sensitive users, who may be interested in making decisions at different thresholds, depending on the nature of their operation. Figure 20. Schematic of a fitted ROC in probability space. Az, the shaded area, is the area under the curve and h(p*) and f(p*) are the hit rate and false alarm rate respectively. Figures 21 and 22 show two examples of ROCs obtained for ECMWF ensemble precipitation forecasts. Analagous to the reliability table, it is useful to display ROCs along with histograms of distributions. For the ROC, the relevant distributions are the two conditional distributions for occurrence and non-occurrence cases of the sample. These histograms, sometimes called likelihood diagrams, show graphically the separation of the dwo distributions. In Fig. 21, the ROC is plotted for three different projection times, where the forecast event is 24 h precipitation accumulation >1 mm. As expected, the longer the forecast range, the smaller the area under the curve. By 10 days, the forecasts can be considered to be barely useful to discriminate between precipitation and no - 15 - precipitation, with an area of 0.709. With three curves, there are three likelihood diagrams plotted to the right of the figure. At 4 days, the two distributions are well-separated, with non-occurrences associated with high probability density neat the low end of the range and occurrences associated with higher probability density near the high end of the range. By 10 days, there is still some separation of the two distributions, but they are much less clearly different than at the earlier forecast ranges. If the two distributions were exactly colocated (means equal), then the area under the ROC would be 0.5, and the system can be said to have no discriminating ability. Figure 21. ROC curves for 4- 6- and 10-day probability forecasts of 24 h precipitation accumulation greater than 1mm. for Europe, using ECMWF ensemble data. The area under the curves and the separation distance of the means of the two conditional distributions is shown in the lower right of the ROC graph. The “likelihood diagrams” are histograms of the two conditional distributions of forecast probabilities. Fig. 22 compares ROC curves for a set of 3 day precipitation forecasts, but examines the system’s ability to discriminate occurrences of precipitation above specific thresholds. The four curves, for 1mm, 2 mm, 5 mm, and 10 mm accumulations in 24 h, actually lie quite close to each other, suggesting that the system performance does not differ greatly for the different thresholds. Sampling the ensemble distribution at different thresholds is similar to sampling the probability distribution over many ensembles at different thresholds to generate the ROC. Thus the ROC seems to be insensitive to changes in the threshold of the physical variable. Figure 22. An example of a ROC for 3 day probability forecasts of 24h precipitation accumulation greater than 1mm, 2 mm, 5 mm and 10 mm, based on the ECMWF 51 member ensemble system. Finally, it should be noted that interpretation of the ROC requires a slightly different way of thinking than one may use for the reliability table. The ROC is completely insensitive to reliability, and provides completely different information about the forecasts being verified. With stratification according to the observation, it is a kind of posteriori or retrospective verification: How well did the system perform in effectively distinguishing between occurrences and non-occurrences. Unlike the reliability table, it does not give information that the forecaster can use directly to alter his probability estimate the next time a priori. Rather it gives information which is of greater interest to the user of the forecast, to make decisions based on the ensemble or on probabilities derived from the ensemble. 4. Concluding remarks Ensemble verification strategies are of two types: those which seek to verify the ensemble distribution or aspects of it, and those which verify probability forecasts derived from the ensemble. Verification of an ensemble distribution against single observations requires the development of special methods, while verification of probability forecasts can be carried out with standard methods applicable to probability forecasts in general. This paper has presented a survey of verification methods applicable to both the full ensemble and to probability forecasts. It is not an exhaustive survey, though most of the frequently-used methods have been briefly described. The set of verification tools presented here for verification of probability forecasts is sufficient to evaluate the 9 attributes of probability forecasts as identified by Murphy, except perhaps association. These verification tools are of three types, summary scores, reliability tables and associated measures, and the ROC and its associated measures. They evaluate accuracy and skill, reliability and sharpness; and discrimination and uncertainty respectively. While the scores summarize the verification information into a single score value, the graphical presentation of the reliability table and the ROC permit the extraction of considerable detail about the performance of the ensemble system. The ROC also permits comparison of probability forecasts with deterministic forecasts. None of these - 16 - methods is sufficient on its own, it will always be necessary to use several verification measures to fully assess the quality of an ensemble forecast. 5. References Buizza, R., and T.N. Palmer, 1998: Impact of ensemble size on ensemble prediction. Mon. Wea. Rev., 126, 2503-2518. Hamill, T. M., 1997: Reliability diagrams for multicategory probabilistic forecasts. Mon. Wea. Rev., 12, 736-741. Hamill, T. M., and S. J. Colucci, 1997: Verification of Eta-RSM short range ensemble forecasts. Mon. Wea. Rev., 125, 1312-1327. Hamill, T. M., and S. J. Colucci, 1998: Evaluation of Eta/RSM ensemble probabilistic precipitation forecasts. Mon. Wea. Rev., 126, 711–724. Mason, I., 1982: A model for assessment of weather forecasts. Aust. Meteor. Mag., 30, 291–303. Murphy, A.H., 1993: What is a good forecast? An essay on the nature of goodness in weather foreasting. Wea. Forecasting, 8, 281-293. Murphy, A.H., and R. L. Winkler, 1987: A general framework for forecast verification. Mon. Wea. Rev., 115, 1330-1338. Stanski, H.R., L.J. Wilson and W.R. Burrows, 1989: Survey of common verification methods in meteorology, WMO, WWW Technical Report No. 8, 115 pp. Talagrand, O., 1997: Statistical consistency of ensemble prediction systems. Discussion paper, SAC Working Group on EPS, ECMWF. Wilks, D.S., 1995: Statistical Methods in the Atmospheric Sciences, Academic Press, New York, Chapter 7, p. 233-281.