ch4_variability1
advertisement

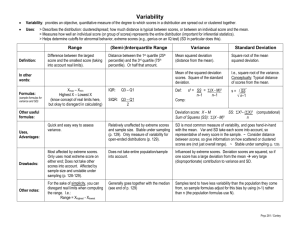
Variability (chapter 4) What is variability? Conceptually it is a quantitative measure of how much scores in a distribution are spread out (high variability) or clustered together (low variability) Three important points: Variability provides an indication of how accurately the mean describes the distribution Variability provides an indication of how well any individual score represents the entire distribution When comparing different distributions, the variability of the scores and the extent to which the distributions do or do not overlap determines whether the distributions are reliably different (inferential statistics – is condition A different from B) Most common measures of variability: Range Interquartile and semi-interquartile ranges Standard deviation and variance Standard error of the mean (discussed later in the course) 1 Range: Distance between upper limit of a data set (x max) and the lower limit (x min) For discrete variables: 2,7,9,1,5 For continuous variables: 2,7,9,1,5 range = 9-1= 8 lower real limit = 0.5, upper real limit =9.5 range = 9.5 – 0.5 = 9 Advantage: easy, simple way to describe the variability in a set of data Disadvantage: 1) completely determined by 2 single values in the data set (could be extreme scores) 2) neglects the rest of the data Interquartile range: Distributions can be split up into 4 parts called quartiles Median is at the second quartile (Q2) Interquartile range is the difference between the 1st and 3rd quartiles: Interquartile range = Q3 – Q1 2 Interquartile range is often expressed as semi-interquartile range (Q 3 Q1) Semi-interquartile range = 2 For the following data set: 3, 4, 5, 7, 9, 10, 11, 13 3, 4 | 5, 7 | 9, 10 | 11, 13 Q1 = 4.5, Q2 = 8.0, Q3 = 10.5 Advantage: less likely than range to be influenced by extreme scores (based on middle 50% of distribution) Disadvantage: does not take into account the actual distances between all scores, therefore, it provides an incomplete picture of the variability 3 Standard deviation (for a population) Most commonly used and most important measure of variability Uses the mean as a reference point and measures the variability of every score from the mean Once the variability of every score from the mean is obtained, the average of this value (divided by N) is what we term the standard deviation (on average, how much do scores in the data set differ from the mean) Here’s where we start: X 8 1 3 0 µ X- 5 -2 0 -3 12 3 N 4 ( ) 0 ( ) 0 scores reflect distances of scores from the mean but in this form cancel each other out 4 To get around this problem we create an additional column showing squared distances of each score from the mean (show 2 on board ( ) X X- ( )2 8 1 3 0 5 -2 0 -3 25 4 0 9 Sums of squares sum of squared differences between individual scores and the 2 mean ( ) is called sums of squares or SS sums of squares can be expressed in 2 ways: SS 2 1) Definitional formula: SS 2 2 2) Computational formula: N (memorize – particularly useful when data has fractions or decimals) Note: these formulas are equivalent 5 The next step in calculating population standard deviation is to work out the variance Population variance or is the mean squared deviation of the scores in the data set from the mean (on average what’s the squared deviation of scores from the mean) 2 SS N 2 the value for variance will always be inflated (out of scale with the original data set because of the squaring procedure) to return to the original scale of measurement we use a square root procedure to give us the standard deviation standard deviation = VARIANCE for a population: SS N Note: you should always estimate sigma before you start to calculate it (it will be somewhere between the closest and furthest scores from the mean) 6 see the text for how to calculate SS with a calculator (you can also do this in separate steps by hand and with a calculator) Standard deviation (for a sample): We have similar definitional and computational formulas for sums of squared with sample data as compared to population data: definitional formula: SS x x 2 computational formula: 2 x SS x 2 n SS S n 1 2 sample variance: n 1 also referred to as degrees of freedom is to correct for bias in sample variation (explain) standard deviation for a sample: df n 1 S S SS n 1 SS df 7 Transformations: adding a constant to each score will not influence the standard deviation multiplying each score by a constant will multiply the standard deviation by the same constant Example of reporting in the literature (p 101 Table 4.2) Demonstration 4.1 (p104) 8