Lecture 7
advertisement

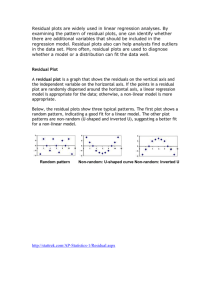
Model Building Estimating the Standard Error in Multiple Linear Regression The estimate s in multiple linear regression is given by s SSE , n k 1 where k is the number of independent variables in the model. This measure of fit should always be analyzed in conjunction with the R 2 . As before, you don’t need to calculate this estimate of because Excel provides it as part of the standard output. However, the formula does tell us something important: s worsens if additional independent variables are added to the model and SSE (the residual sum of squares) is not lowered sufficiently to offset the smaller denominator. Generally speaking, one should not include independent variables in a predictive model (“predictive” meaning a model used for predictions or valuations) if it worsens s , even though R 2 will typically increase. Thus, when analyzing fit, it is essential to examine s . Using Dummy Variables: A Model for Predicting Construction Costs at Carlson George Melas (SMU MBA Class 47) works for Carlson, a national company that designs and constructs “mission critical buildings” for Fortune 500 companies. These buildings are facilities that must operate uninterrupted 7-days per week, 24 hours per day. Interruptions are very costly. Over the past 4 years the company has performed a number of telecommunication projects geared toward companies that want to set-up the infrastructure necessary to operate their fiber networks. George has gathered cost and other data on several facilities. Our goal will be to analyze the data and build a multiple linear regression model that can predict the future construction costs for this type of facility given only a few key variables. After some preliminary screening, 5 variables are identified for possible inclusion in the final model: Gross Area, Network Area, Building Type, Complexity, and City Cost. Gross area is simply the total area of the project. Network area is the area devoted to mission critical systems and their backups. City cost is an index that captures local construction costs. Building Type refers to the type of constructionType A (highrise), Type B (mid-rise), Type C (single-story), and Greenfield (new construction). Complexity is an index that captures the number and complexity of redundant (backup) systems required (“1” in the data indicates high complexity, “0” means normal complexity). These variables along with the cost of 33 completed projects are in file Construction.xls. One of the complicating features of this problem is the presence of categorical independent variables. These are independent variables that describe a particular 45 | P a g e qualitative factor instead of values from a continuous scale. In our example, “Building Type” and “Complexity” are categorical variables. The typical manner for dealing with such variables is through the use of 0/1 dummy (also called indicator) variables that effectively “code” the various possibilities. For example, to model Building Type, we introduce three dummy variables, 1 if the constructi on is Type A IA 0 otherwise 1 if the constructi on is Type B IB 0 otherwise 1 if the constructi on is Type C IC 0 otherwise Observe that four categories require only three dummy variables in the regression model. In general, m categories require only m-1 dummy variables in a regression model. To see why this works, observe that in the construction example, Type A construction is indicated by I A 1, I B 0, I C 0 ; Type B by I A 0, I B 1, I C 0 ; Type C by I A 0, I B 0, I C 1 ; and Greenfield by I A 0, I B 0, I C 0 . In other words, the final category is obtained when the remaining dummy variables are all set to 0. Complexity involves the use of a single dummy variable (two categories, hence one dummy variable), 1 if the constructi on is high complexity IX 0 otherwise The initial full model, including both continuous and dummy variables, is y 0 GA xGA NA x NA CI xCI A I A B I B C I C X I X . If we fit this model in Excel, we get the following output. 46 | P a g e George's Construction Cost Model -1.5 -0.5 Frequency -2.5 0 10 -1.5 2 -0.5 9 5 0.5 14 1.5 5 0 2.5 -2.5 -1.5 -0.52 0.5 1.5 More 1 SS MS F Significance F 7 8.21147E+13 1.17307E+13 16.14082 7.7432E-08 25 1.81693E+13 7.26771E+11 32 1.00284E+14 df Regression Residual Total Coefficients Standard Error 698998.9541 1703695.315 146.8058511 72.39693827 213.6654041 109.5252025 609797.6799 484001.0976 -108064.859 612790.4108 101556.6321 420042.6362 297122.8627 388433.6535 1140763.445 1581964.589 Intercept GrossArea NetArea TypeA TypeB TypeC Complexity CityCost 0.5 1.5 Bin Frequency Regression Statistics Multiple R 0.904887751 R Square 0.818821843 Adjusted R Square 0.768091958 Standard Error 852508.5055 Observations 33 ANOVA Histogram -2.5 15 t Stat 0.410284015 2.027790879 1.950833226 1.259909704 -0.176348808 0.241776961 0.764925644 0.72110555 P-value 0.685093 0.053366 0.062371 0.219337 0.861441 0.810925 0.451477 0.477534 Lower 95% -2809824.77 -2.2983299 -11.9058149 -387020.542 -1370129.45 -763536.765 -502870.661 -2117351.33 2.5 More Upper 95% 4207822.7 295.91003 439.23662 1606615.9 1153999.7 966650.03 1097116.4 4398878.2 Residual s 4000000 Residuals Standard Residuals -216866.768 -0.287805621 -77258.3129 -0.102530124 -1317232.12 -1.748109272 248190.5852 0.329375709 1429819.545 1.897524944 -167226.33 -0.221927399 -597747.332 -0.793275261 -156173.847 -0.20725956 -390109.458 -0.517717379 1481463.879 1.966062552 -636032.559 -0.844083891 9281.739399 0.012317871 234667.2576 0.311428793 2045573.588 2.714697055 -434332.687 -0.57640638 -1218710.01 -1.617359794 -237307.171 -0.314932242 -162407.054 -0.215531699 110323.4631 0.14641115 469871.195 0.623569818 733749.7795 0.973765196 -190770.714 -0.253173339 -947814.442 -1.25785212 -789258.517 -1.047431285 426318.4207 0.565770583 171058.7881 0.227013485 826165.8052 1.096411242 -504636.702 -0.6697074 987856.7895 1.310992639 164348.345 0.218108002 -205051.255 -0.272125159 -513052.51 -0.680876086 -576701.391 -0.765345025 X 0 -2000000 0 0.2 0.4 0.6 Complexity 0.8 1 10000 15000 20000 25000 30000 Residual s 4000000 2000000 0 -2000000 0 5000 10000 15000 20000 NetArea X Residual s 4000000 TypeA Residual Plot 2000000 0 -0.2 0.3 -2000000 0.8 1.3 TypeA TypeB Residual Plot 4000000 2000000 0 -0.2 -2000000 0.3 0.8 1.3 TypeB TypeC Residual Plot 4000000 2000000 0 -0.2 -2000000 Complexity Residual Plot 0 5000 NetArea Residual Plot X 0 -0.2 2000000 GrossArea 2000000 -2000000 GrossArea Residual Plot 4000000 Residual s Predicted Cost 3498742.768 3861405.313 3071253.12 4669309.415 3562627.455 5119092.33 2489294.332 3312755.847 2365320.458 3696099.121 3818441.559 4127309.261 3566836.742 4582391.412 3702083.687 4165524.011 4766138.171 3379751.054 3469140.537 9742296.805 3830230.221 3501202.714 5494452.442 3809883.517 2837058.579 2583341.212 5134572.195 7029148.702 4463062.211 2514006.655 3090735.255 5925052.51 8115701.391 Residuals 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 1.2 Residual s Observation Residuals RESIDUAL OUTPUT 0.3 0.8 TypeC 4000000 1.3 1 CityCost Residual Plot 2000000 0 -20000000.75 0.85 0.95 1.05 1.15 1.25 1.35 CityCost Questions 47 | P a g e (1) What is the estimated cost of a Greenfield site of low complexity having a gross area of 5000 square feet, a network area of 2500 square feet, in a city whose cost index is 1.15? (2) What is the cost difference, ceteris paribus, between high rise construction and Greenfield construction? Is this difference statistically significant? (Use the default value .05 ). (3) What is the cost of increasing gross square footage (ceteris paribus)? (4) What is the cost of increasing network square footage (ceteris paribus)? Fit and Diagnostics The R 2 .818 tells us that nearly 82% of the variation in cost is explained by the independent variables. The standard error of $852208, however, is still pretty large for predictive purposes. The overall model is statistically significant based on the F-statistic, but the t-statistics reveal that some of the variables add little to the model. These are undoubtedly inflating the standard error (why?) and thus should be removed in some systematic manner so that the standard error is improved. We will discuss a procedure later when we talk about model building. The residual plots do not reveal any violations of the homoscedasticity assumption or the independence assumption. However, the histogram appears slightly positively skewed, mostly due to three positive residuals (marked with an “X” above) that highlight projects that were much more expensive than our model would predict. These are potential outliers and possibly influential. A subsequent consultation with George revealed that these three projects were indeed highly unusual compared to the remaining sample points. In project #5, the work involved sequentially building and demolishing parts of the structure, often destroying a portion that was only recently constructed. The second two projects (observations 10 and 14) were done in office buildings that required opening up the construction site in the evening after the tenants had left and then closing up the construction site (so it was concealed) in the early morning before the tenants returned. These three projects were all highly specialized and therefore not representative of “typical” projects. Our model cannot address construction costs for these types of idiosyncratic projects because they involve factors we have not included or measured. If we remove these three projects1 and build a model for the homogeneous population of “typical” construction projects that remain, we get the results below. 1 One should never arbitrarily remove data points without documentation or cause. 48 | P a g e George's Construction Model -2 Frequency (Reduced data set, n=30) Regression Statistics Multiple R 0.95856189 R Square 0.918840896 Adjusted R0.893017545 Square Standard Error 583873.281 Observations 30 Histogram 0 12 -1 10 8 6 4 2 0 -2 -1 1 2 2 More Bin ANOVA df Regression Residual Total 0 1 SS 7 8.49108E+13 22 7.49998E+12 29 9.24108E+13 Coefficients Standard Error Intercept 281625.988 1170746.224 GrossArea139.7814566 49.90307723 NetArea 228.1872883 75.6225792 TypeA 373203.8497 342476.6769 TypeB 42605.88107 420907.3498 TypeC -51206.5948 292254.6326 Complexity17588.80265 274676.667 CityCost 1615820.164 1088843.147 MS F Significance F 1.21301E+13 35.5818 1.44393E-10 3.40908E+11 t Stat 0.240552549 2.801058859 3.017449163 1.089720483 0.101223894 -0.175212261 0.064034571 1.483978816 P-value 0.81213 0.01041 0.00633 0.28763 0.92029 0.86252 0.94952 0.152 Lower 95% -2146355.68 36.28869761 71.35548968 -337050.0691 -830303.4726 -657306.2568 -552056.3508 -642304.737 Upper 95% 2709607.66 243.274216 385.019087 1083457.77 915515.235 554893.067 587233.956 3873945.07 These results appear to be much improved (discussion). Model Building: Improving the Model for Construction Costs Using Backward Elimination Since the construction model was intended to predict construction costs, we want to improve the standard error. We can do so by building a better model, that is, deciding which variables to include and which to exclude. One way to accomplish this is to start with a model that includes everything (the “full model”) and sequentially remove variables (one at a time!) that do not add much to the model. This procedure is known as backward elimination. If any variable is worthy of elimination in the full model, it is the Complexity variable (p-value = .949). After removing this variable and re-running the regression, we obtain a new model with s 571092.5 and R 2 .9188 . The Type B variable is now the least significant variable with a p-value of .9087. If we remove this variable, we obtain a new model with s 559231 and R 2 .9188 . The Type C variable in this model has the biggest p-value at .8127, so we remove it and obtain a model with s 548587 and R 2 .9185 . The biggest p-value occurs for City Cost (p-value = .12), and if we remove it we obtain a model with s 564905 and R 2 .9102 . The value for s has gone up, and this suggests we have gone too far in eliminating variables. The best model for predictive purposes appears to be one that includes Gross Area, Net Area, Type A, and City Cost as independent variables (see below). 49 | P a g e Final Model (Backward Elimination) -0.5 Frequency -2.5 0 -1.5 3 -0.5 7 0.5 10 1.5 8 2 1.5 -2.5 -1.5 2.5 -0.5 0.5 More 0 MS F Significance F 2.12218E+13 70.5164001 3.02103E-13 3.00948E+11 Frequency Regression Statistics Multiple R 0.958427969 R Square 0.918584172 Adjusted R Square 0.90555764 Standard Error 548587.2856 Observations 30 ANOVA df Regression Residual Total 4 25 29 SS 8.48871E+13 7.5237E+12 9.24108E+13 Coefficients Standard Error 361239.4894 977119.3354 137.3786516 44.96420971 229.1804244 70.58166886 402580.9277 231605.6919 1536504.891 958479.9938 Intercept GrossArea NetArea TypeA CityCost Histogram 12 -2.5 10 8 6 4 2 0 t Stat 0.369698435 3.055288917 3.247024732 1.738216899 1.603064123 -1.5 P-value 0.71472048 0.005284993 0.003310698 0.094476673 0.121481454 1000000 0.85 0.95 1.05 1.15 Lower 95% -1651174.042 44.77319309 83.81485814 -74419.58973 -437520.2252 1.25 1.35 -2000000 0 -1000000 0 0.2 0.4 0.6 0.8 1 1.2 -2000000 Residual Plot NetArea Residual Plot 1000000 0 0 5000 10000 15000 20000 25000 30000 -2000000 Residuals Residuals Upper 95% 2373653.021 229.9841101 374.5459907 879581.445 3510530.007 TypeA 1000000 -1000000 More 1000000 CityCost GrossArea 2.5 TypeA Residual Plot Residuals Residuals CityCost Residual Plot 0 -10000000.75 0.5 1.5 Bin 0 -1000000 0 5000 10000 15000 -2000000 GrossArea NetArea In general, backward elimination proceeds by sequentially removing the variable that adds the least to the model. Remember that the variable that adds the least to the model is the one with the largest p-value (i.e., the least significant). Some procedures permanently remove the variable with the highest p-value and this p-value exceeds some pre-established threshold (like .10 or .15 ). Other procedures, like the one we used for the construction model, permanently remove the variable with the highest pvalue only if it improves the standard error. Like any model building procedure, the model we have arrived at is not necessarily the “best,” but rather a plausible candidate capable of doing the job. Questions. In this final model, (1) What is the cost of increasing gross square footage (ceteris paribus)? (2) What is the cost of increasing network square footage (ceteris paribus)? 50 | P a g e 20000 (3) Predict the cost of a Type C project with 6000 square feet gross area, 2500 square feet network area, in a city whose cost index was 1.18. (4) Compute an approximate 95% prediction interval for the same problem. [Use the approximate prediction interval formula Here, k = # independent b0 b1 x1 b2 x2 bk xk t / 2, nk 1 df s 1 1 / n . variables, n = sample size]. (Ans. $3571538 $1148512) (Note: The exact 95% prediction interval is $3571538 $1227694 using another software package) More Applications of Multiple Linear Regression Online Auctions: An Investigation of When to Buy (or Sell) Laptops on eBay Suppose we are interested in buying or selling products through online auctions. What situations are good for buying? What situations are good for selling? To investigate this problem more rigorously, a researcher collected data on winning bid prices for used computers purchased through online auctions. Over an approximately three month interval beginning in May 2002, 488 purchases of Dell’s Latitude CPXH 500GT 500MHz 128MB laptop on eBay were recorded. Data included (1) the winning bid for a particular auction, (2) the day of the week the auction closed, (3) the number of bids in the auction, (4) the number of auctions that closed that day for the same laptop, and (5) the rank of the auction within a day (the order it closed among auctions for the same item). This data is included in the file Auction.xls. The day of the week was coded with dummy variables. SUN = 1 if it was a Sunday (0 otherwise), MON = 1 if it was a Monday (0 otherwise), etc. The Excel output for the model is given below: 51 | P a g e Regression Statistics Multiple R 0.471383199 R Square 0.222202121 Adjusted R Square 0.207557391 Standard Error 31.55046086 Observations 488 ANOVA df Regression Residual Total Intercept SUN MON TUES WED THUR FRI #Bids #AUCTIONS Rank-in-Day 9 478 487 Coefficients Standard Error 558.693216 5.726602353 -4.294706396 5.260381458 9.906281109 5.670000132 17.39920411 5.252984387 15.38320751 5.471611839 16.90919123 5.397031356 10.42141417 5.090961399 1.52278322 0.291589103 -0.839917408 0.356722205 -1.761991465 0.411566571 SUN SUN MON TUES WED THUR FRI #Bids #AUCTIONS Rank-in-Day SS 135931.7025 475816.2955 611747.998 MS F Significance F 15103.5225 15.17284 8.43639E-22 995.4315806 t Stat 97.56102861 -0.816424898 1.747139485 3.312251251 2.811458115 3.133054103 2.047042465 5.222359836 -2.354541982 -4.281182168 P-value 0 0.414664 0.081255 0.000996 0.005134 0.001836 0.0412 2.64E-07 0.018949 2.25E-05 Lower 95% Upper 95% 547.4407827 569.9456493 -14.63104331 6.041630523 -1.234932159 21.04749438 7.077401992 27.72100622 4.631815447 26.13459957 6.304345388 27.51403708 0.417977601 20.42485074 0.949827963 2.095738477 -1.54085534 -0.138979476 -2.570695316 -0.953287614 CORRELATION MATRIX WED THUR FRI -0.160313 -0.166031678 -0.185440699 -0.139881 -0.144871165 -0.161806532 -0.158989 -0.164660978 -0.183909765 1 -0.156328035 -0.174602705 -0.156328 1 -0.180831348 -0.174603 -0.180831348 1 0.018363 -0.009551683 -0.015571909 -0.111259 -0.138577096 -0.048708705 -0.065688 -0.081817125 -0.028758044 1 -0.148563898 -0.16885815 -0.160312802 -0.166031678 -0.185440699 0.026809086 0.005221148 0.003082611 MON -0.148563898 1 -0.147337406 -0.139881152 -0.144871165 -0.161806532 0.08939618 -0.054887516 -0.032406068 TUES -0.16885815 -0.147337406 1 -0.158989315 -0.164660978 -0.183909765 0.048372866 0.135913531 0.080244533 1.686543874 0.768556569 0.811538059 0.812097352 0.833052957 0.884575206 -0.135624146 0.171281717 -0.015765442 0.768556569 1.601056562 0.744962263 0.754937389 0.774085283 0.817335382 -0.180339334 0.212786718 -0.020963297 INVERSE OF CORRELATION MATRIX 0.811538059 0.812097 0.833052957 0.884575206 0.744962263 0.754937 0.774085283 0.817335382 1.662092941 0.779789 0.796794509 0.856283502 0.779789225 1.672419 0.826821526 0.868783747 0.796794509 0.826822 1.712524719 0.893256151 0.856283502 0.868784 0.893256151 1.77626704 -0.16076004 -0.11775 -0.094042202 -0.102422467 0.048830138 0.27359 0.302189257 0.230313932 -0.018687329 -0.013688 -0.010931806 -0.011905958 #Bids #AUCTIONS 0.026809 0.005221 0.089396 -0.054888 0.048373 0.135914 0.018363 -0.111259 -0.009552 -0.138577 -0.015572 -0.048709 1 -0.073642 -0.073642 1 -0.119202 0.590409 Rank-in-Day 0.003082611 -0.032406068 0.080244533 -0.065688364 -0.081817125 -0.028758044 -0.119201966 0.590408718 1 -0.135624 -0.180339 -0.16076 -0.11775 -0.094042 -0.102422 1.040647 -0.013248 0.120969 -0.015765442 -0.020963297 -0.018687329 -0.013687649 -0.010931806 -0.011905958 0.1209686 -0.907884524 1.549175529 0.171282 0.212787 0.04883 0.27359 0.302189 0.230314 -0.013248 1.62273 -0.907885 (a) Do the variables included in the model collectively explain a significant amount of the variation in winning bids? Cite the appropriate test, your test statistic, and your conclusion at the .05 level. What is your p-value? (b) What is the price difference between a Dell laptop auctioned on Saturday and one auctioned on Sunday (all other things held equal)? Is this difference statistically significant? Cite your null and alternative hypothesis, the relevant test statistic, and your conclusion at the .05 level. What is the p-value? (c) Suppose you are more generally interested in whether it is better to auction laptops on weekdays or weekends (all other things being equal). What is your conclusion based on this model? Briefly summarize the appropriate test results and state your general findings. What day would you auction your Dell laptop on? What day would you buy one on? 52 | P a g e (d) Is there a relationship between the winning bid price and the rank of the auction (in this model)? Cite an appropriate test, your test statistic, and your conclusion (at the .05 level). What is the p-value for this test? (e) Can the coefficient values in this model be interpreted safely? Cite appropriate evidence to defend your decision. Are “Wins” Related to Ratings for Relief Pitchers? Relief pitchers are baseball’s equivalent of place kickers in the NFL. You bring in some poor sap with the game on the line and he’s either a forgotten hero or a memorable goat. Many great relief pitchers do not have much on their record in the way of wins or losses since their role is to save games, i.e., protect a lead in the late innings. If you want to know what the “experts” think, CBS Sportsline.Com (September 24, 2002) posts ratings for the majority of MLB relief pitchers. Along with the pitchers’ ratings they post assorted “hard” data on performance. The site does not include any information on how they arrive at their expert ratings. The data is contained in the file Relief.xls. (a) Are “wins” related to ratings? Build a simple linear regression model and discuss your results. (b) There appears to be a lot of residual “noise” in the data. Suppose we include other variables to account for this noise. Are wins related to ratings in this model? Assignment 7 (Do Not Hand This In) 1. Multiple Regression Chapter, problem 37, (page 682-683). In this problem, also check for multicollinearity using the correlation matrix and VIFs. 2. Multiple Regression Chapter, problem 38, (page 683-684). 3. Multiple Regression Chapter, problem 50, (page 694). standardized residual plot to answer part e and part f. 4. Multiple Regression Chapter, problem 51, (page 695). 5. Multiple Regression Chapter, problem 52, (page 695-696). Note: Use Excel’s 53 | P a g e