file - European Urology
advertisement

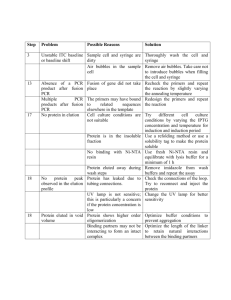
Supplementary Methods 1. DNA extraction from seminomas and matched normal tissues Frozen tissue was submerged in TRIS buffer and homogenized using a Polytron homogenizer. The sample was then mixed with 10% SDS and Proteinase K to a final concentration of 0.1 mg/ml, and incubated overnight at 55 degrees C. DNA was purified with phenol-chloroform extraction and ethanol precipitation. 2. Library preparation and exome sequencing DNA (3 micrograms per sample) was sheared using a Covaris S1 Ultrasonicator. Following adapter ligation, libraries were prepared using Illumina Paired-End Genomic DNA kit. Exome capture was done using Agilent SureSelect Human All Exon Kit v1. Samples were sequenced on Illumina GA-IIx and/or HiSeq sequencers using 76-bp paired-end reads. Image analysis and base calling were done using Illumina pipeline (v1.6) with default settings. 3. Mapping and variant calling Burrows-Wheeler Aligner (BWA) software (http://bio-bwa.sourceforge.net/) was used for aligning sequence reads to the human reference genome NCBI build 36.1 (hg18). PCR duplicates removal was done using SAMTools (http://samtools.sourceforge.net/). We created realigned BAM files with Genome Analysis ToolKit (GATK) v1.0 (https://www.broadinstitute.org/gatk/). For detecting single nucleotide variants (SNVs) we used three different callers: MuTect (http://www.broadinstitute.org/cancer/cga/mutect), GATK v1.0 Unified Genotyper, and Partek Genomics Suite. For SNVs detected by GATK or Partek, we subtracted variants detected in the matched normal from variants detected in the tumor. For further analysis, we restricted our attention to candidate somatic SNVs that were in the capture target and in exons or canonical splice sites, with a variant depth ≥ 4 and depth in the normal sample ≥ 10. To exclude common germline polymorphisms, the detected variants were checked against dbSNP 138 (http://www.ncbi.nlm.nih.gov/SNP/) and 1000 Genomes (http://www.1000genomes.org/) databases. However, any variants present in COSMIC v47 (http://www.sanger.ac.uk/cosmic), a database of somatic mutations in cancers, were retained. Variants were annotated using several gene-transcript databases (Consensus CDS, RefSeq, Ensembl and UCSC, downloaded from http://hgdownload.soe.ucsc.edu/goldenPath/hg18/bigZips/). Amino-acid changes were determined based on the longest gene transcript. Somatic nonsynonymous singlenucleotide mutations were analyzed using PolyPhen2 (http://genetics.bwh.harvard.edu/pph2/) to predict their impact on the protein function. Microindels were detected using GATK IndelGenotyperV2. For further analysis we only considered microindels that were in-target and in an exon or at a canonical splice site. Several filters were applied to reduce false positives: we retained microindels that (1) were not in a simple repeat, (2) had variant depth ≥ 5 with ≥ 1 read on each strand, (3) had depth in the normal sample ≥ 10, (4) were contained in ≥ 5% of the reads, (5) had average base quality of all bases inside the microindel and ±5 bases around the microindel ≥ 25, (6) had average number of mismatches in the reads containing the microindel ≤ 4, and (7) had average fraction of mismatched bases in reads containing the microindel ≤ 0.2. 4. Validation of somatic variants For validation by Sanger sequencing, we used the Primer3 software to design primers for PCR and sequencing. PCR was carried out with Promega GoTaq Hot Start Colorless Master Mix according to the manufacturer’s instructions. We designed primers for 135 variants and we were able to obtain 132 PCR products. Purified PCR products were sequenced in both directions on an ABI 3730xl DNA analyzer using the PCR primers and the ABI PRISM BigDye Terminator Cycle Sequencing Ready Reaction kit. For validation by Ion Torrent PGM, primers were designed at the website www.ampliseq.com. Ampliseq primer design failed for 4 out of the 77 variants we attempted to design primers for. Libraries were prepared using the Ion AmpliSeq Library Kit 2.0 according to the manufacturer’s instructions and run on an Ion 314 Chip. 5. SNP microarrays and ASCAT analysis Genomic DNAs from the eight tumor-normal pairs were hybridized to Affymetrix SNP Array 6.0 microarrays. The raw SNP array data were first normalized using CRMA-v2 (http://www.aroma-project.org/vignettes/CRMAv2) and TumorBoost (http://aromaproject.org/vignettes/tumorboost-highlevel). Next, the log2R ratio (LRR) and the Ballele frequency (BAF) were computed and the ASCAT v 2.0 software (http://heim.ifi.uio.no/bioinf/Projects/ASCAT/) was used to determine the proportion of malignant cells in the tumor sample and the allele-specific chromosome counts (i.e., the number of chromosomes bearing each of the two alleles). Copy-number alterations were identified based on the allele-specific copy-number counts and average ploidy, i.e. the, average number of chromosome copies at each site across the genome.