Regression Analysis-
advertisement

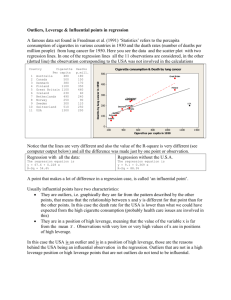
UNC-Wilmington Department of Economics and Finance ECN 377 Dr. Chris Dumas Regression Analysis-- Outliers Outliers Outliers are data points that have unusually large or small values of X or Y relative to other data points in a dataset. Outliers are of concern because they can affect the 𝛽̂’s, and the s.e.’s of the 𝛽’s, of regression models. Relative to other data point, outliers can have a disproportionate influence on regression models, pulling the regression line/curve away from most of the data points, such that the regression line/curve no longer represents the main patterns/relationships/trends supported by most of the data points in the dataset. Regression models based on small samples are especially susceptible to the effects of outliers, because there are fewer “normal” (non-outlier) data points to counter-balance the effects of the outliers. A data point is considered to be an outlier due to an unusual X value when the X value is far from the mean value of X for the dataset. Such an outlier is said to have a large leverage on the regression model. Large leverage decreases the s.e’s of the 𝛽’s; this can cause X’s to appear as if they affect Y when in fact they don’t. A data point is considered to be an outlier due to an unusual Y value when the data point has a large residual (its unusual Y value places the data point far from the regression line/curve). Such an outlier is said to have a large discrepancy. An outlier with a large discrepancy has the potential to affect the 𝛽’s of the regression equation. Large discrepancy also increases the s.e’s of the 𝛽’s; this can cause X’s to appear as if they don’t affect Y when in fact they do. There are several possible cases to consider, depending on whether a data point has an unusual X value (large leverage), and unusual Y value (large discrepancy), or both. Effects of Outliers on Regression Model—Four Cases If an outlier has large leverage and large discrepancy, then it will affect the 𝛽’s (both the intercept and the slope) of the regression equation. In this case, the data point is said to have influence on the regression equation. Because large leverage and large discrepancy have opposite effects of the s.e.’s of the 𝛽’s, it’s unclear in this case how the outlier will affect the s.e.’s of the 𝛽’s. An Outlier with Large Influence on the 𝛽’s and an Ambiguous Effect on the s.e.’s (affects intercept, slope, and s.e.’s) Y Regression Line without Outlier Regression Line with Outlier Outlier X1 1 UNC-Wilmington Department of Economics and Finance ECN 377 Dr. Chris Dumas If an outlier has large leverage and small discrepancy, then it will have little effect on the 𝛽’s of the regression equation. However, a large leverage decreases the s.e’s of the 𝛽’s, and this can cause X’s to appear as if they affect Y when in fact they don’t. An Outlier with Little Influence on the 𝛽’s, but that Decreases the s.e.’s (affects only the s.e.’s) Y Outlier Regression Line same with or without Outlier X1 If an outlier has small leverage and large discrepancy, then it will affect the intercept𝛽̂ of the regression model, but not the slope 𝛽̂’s. Large discrepancy also increases the s.e’s of the 𝛽̂’s; this can cause X’s to appear as if they don’t affect Y when in fact they do. An Outlier with Influence on the 𝛽̂ Intercept and that Increases the s.e.’s (affects only the intercept and the s.e.’s) Y Regression Line without Outlier Regression Line with Outlier Outlier X1 2 UNC-Wilmington Department of Economics and Finance ECN 377 Dr. Chris Dumas If an outlier has small leverage and small discrepancy, then it will have little effect on the 𝛽̂’s of the regression equation. Furthermore, because both leverage and discrepancy are small, the outlier should not have much of an effect on the s.e.’s of the 𝛽̂’s. This case describes a data point that seems to be an outlier when viewed on a graph, but in fact its X and Y values are not unusual enough to significantly distort the 𝛽̂’s or the s.e.’s of the regression model. An “Outlier” with No Significant Influence on the 𝛽̂’s or the s.e.’s (affects nothing) Y Regression Line without Outlier Regression Line with Outlier “Outlier” X1 3 UNC-Wilmington Department of Economics and Finance ECN 377 Dr. Chris Dumas Detecting Outliers 1. Simplest/Basic method: Graph the data points together with the regression line/curve. Look for data points that are far from the regression line/curve. 2. To detect outliers with high leverage, we can look at the Hat Values, “h” (the derivation of Hat Values is beyond the scope of this course). SAS can calculate a Hat Value for each data point. The values of h range between 1/n and 1, and the average hat value is k/n, where k is the number of 𝛽̂’s in the regression model. Data points with h values more than 2·(k/n) are considered outliers. 3. To detect outliers with high discrepancy, we can look at the Studentized Residuals (the derivation of Studentized Residuals is beyond the scope of this course). Data points with Studentized Residuals larger than 2 are considered outliers. 4. In SAS, we can run a regression analysis and have SAS save the predicted values (“yhat”), h values (“lev”) and studentized residuals (“student_resid”) using an output command, as shown below: proc reg data=dataset02; model Y = X1 ; output out=dataset03 p=yhat r=resid h=lev rstudent=student_resid; run; Then we can use plots to quickly determine which data points match the criteria (large h value, large Studentized Residual, etc.) necessary to be considered outliers. proc gplot data=dataset03; plot Y*X1 yhat*X1 / overlay; plot lev*yhat; plot student_resid*yhat; plot lev*student_resid; run; (plot of the data points and the regression line/curve) (plot of Hat Values against yhat values) (plot of Studentized Residuals against yhat values) (plot of Hat Values against Studentized Residuals) The plot of Y*X1 can be used to see which data points lie far from the regression line. This is the simple/basic method of finding outliers. The plot of lev*yhat can be used to find data points with a high leverage, that is, with h value > 2(k/n). The plot of student_resid*yhat can be used to find data points with high Studentized Residuals, that is, with Studentized Residuals > 2. The plot of lev*student_resid is especially interesting. Any data point that is far out in the right-upper quadrant of this graph has both high leverage and a high Studentized Residual. These points have the largest potential effects on the regression model—they can affect the intercept, the slope, and the s.e.’s. 4 UNC-Wilmington Department of Economics and Finance ECN 377 Dr. Chris Dumas Causes of Outliers 1. Data Collection Errors, Data Recording Errors, Data Transcription Errors (entering the data into a computer), or Variable Transformation Errors (creating or modifying variables in the dataset). In this case, the outlier is not a “real” or “true” data point; instead, it is a mistake/error in collecting or manipulating the data. 2. Model Specification Error. In this case, a variable in the regression model is not specified correctly. For example, perhaps an X variable is entered into the regression model in a linear fashion, whereas it should be entered in logged form, or squared form. 3. Truly “Weird/Odd” Data Points. Sometimes, a data point is truly different from the other data points in the data set, in that the X variables in the model don’t explain its Y value very well, whereas the X variables in the model do explain the Y values of the other data points in the dataset pretty well. In this case, the reason is usually that there is some other variable outside the model that is affecting the outlier data point but that is not affecting the other data points. Remedies for Outliers 1. If you suspect Errors in Data Collection, Data Recording, or Data Transcription (entering the data into a computer), check the data row for the outlier data point in the dataset for errors. If you suspect Variable Transformation Errors (creating or modifying variables in the dataset), check the equations that you use in your SAS program to create or modify variables for errors. 2. If you suspect Model Specification Error, check which X variables are causing an unusual value for Y for the outlier data point, and try including the X variables in the regression equation in a different form, logged, squared, etc. 3. If you suspect Truly “Weird/Odd” Data Points, try creating a dummy variable for the outlier data point(s) and adding the dummy variable to the model. The dummy has a value of 1 for the data row in the dataset that represents the outlier data point, and the dummy has a value of 0 otherwise. The purpose of the dummy variable is to represent the effects of the other variables outside the model that are affecting the outlier data point but that are not affecting the other data points. 4. A last resort is dropping outlier data points from the dataset. More Advanced Tests for Outliers In more advanced courses, other, more advanced measures and tests for outliers are discussed, such as “Cook’s D” value and “DFITS” values. These values combine information about leverage and residuals. 5