3-Simple Regression
advertisement

CHAPTER 3
THE SIMPLE REGRESSION MODEL
1.
2.
3.
4.
5.
The Relationship Between Two Variables—Deterministic versus Stochastic Relationship
1.1. Stochastic Relationship Between Dependent and Independent Variables.
1.2. Regression Line as a Locus of Mean Values of y for Different Values of x
1.3. The Relationship Between the Variance of y and Variance of the Disturbance Term u
1.4. Summary of Assumptions About the Regression Model
The Estimated Regression Equation and Regression Line
2.1. The Least Squares Method of Obtaining the Coefficients of Estimated Regression Equation
2.1.1. Alternative Expression for the 𝑏2 formula
Statistical Properties of Least Squares Estimators 𝑏1 and 𝑏2 —The Gauss-Markov Theorem
3.1. Sampling Distributions of Coefficients of Regression Equation
3.2. Coefficients 𝑏1 and 𝑏2 are the Best Linear Unbiased Estimators
3.2.1. 𝑏1 and 𝑏2 are linear functions of y.
3.2.2. 𝑏1 and 𝑏2 are unbiased estimators of population parameters β1 and β2
3.2.2.1. E(𝑏2 ) = β2
3.2.2.2. E(𝑏1 ) = β1
3.2.3. As Estimators of Parameters 𝛽1 and 𝛽2 , 𝑏1 and 𝑏2 Have the Minimum Variance
3.2.3.1. Variance of 𝑏2
3.2.3.2. Covariance of b1 and b2
3.2.4. The Covariance Matrix
3.2.5. 𝑏2 is the Best Linear Unbiased Estimator of 𝛽2
The Estimator of the Variance of the Prediction Error
4.1. var(𝑒) is an unbiased estimator of σ2𝑢
4.2. The Standard Error of Estimate
Nonlinear Relationships
5.1. Quadratic Model
5.2. Log-Linear Model
5.3. Regression with Indicator (Dummy) Variables
1. The Relationship Between Two Variables—Deterministic versus Stochastic
Relationship
In discussing the relationship between two variables 𝑥 and 𝑦 we observed that the two variables can be
independent. That is the changes in 𝑥 have no influence on the variations in 𝑦. Although theoretically
significant, in practice, two independent variables are of little interest to us.
In most economic studies (and studies in other disciplines) we are interested in the relationship between two
or more variables. For example, how does quantity demanded of gasoline respond to changes in its price?
How is consumption expenditure affected by the variations in household income? For a more down-to-earth
example, consider the variations in students’ test scores on the statistics final tests. What do you think is the
most important factor affecting the variations? How about the number of hours studied for the final?
We can express the relationship between test scores and study hours as a simple linear equation as follows.
Let 𝑥 be the study hours and 𝑦 be the test scores.
𝑦 = β1 + β2 𝑥
The variable 𝑥 is the explanatory (independent or control) variable and 𝑦 is the explained (dependent or
response) variable. β1 and β2 are the parameters of the equation. The coefficient of 𝑥, β2 , is the slope
3-Simple Regression Model
1 of 31
parameter. It indicates the change in scores per unit change in study time (increase in test score per each
additional hour studied). The intercept β1 shows the score for zero hour of study, when the student purely
guesses the answers for multiple choice questions. Statistically, the probability that the student guesses all
questions incorrectly is very low.1 Therefore, a zero vertical intercept in this model is very unlikely.
To illustrate the relationship further, let β1 = 20 and β2 = 8. Then,
𝑦 = 20 + 8𝑥
Thus, according to this equation, if a student studies 5 hours, the test score would be 60. Graphically, this
relationship is shown as a straight line. The graph also shows the 𝑦 value when 𝑥 = 3, 5, and 7.
y
y = 20 + 8x
76
60
44
20
0
3
5
7
x
1.1. Stochastic Relationship Between Dependent and Independent Variables.
Although intuitively the above depiction of the relationship between scores and study hours makes sense—
that is, the more one studies, the better the score—the model is oversimplified and unrealistic. The
relationship shown here is purely deterministic. It implies that all students who study, say, 5 hours will score
60. We all know that rarely students who study the same amount and with the same intensity have identical
scores. In reality one may observe different scores for the same number of study hours. There are other
unobserved or unobservable factors, such as unmeasurable individual attributes, that may affect the
individual test scores. We can summarize these unobserved factors by the variable 𝑢 and incorporate it in the
model.
𝑦 = β1 + β2 𝑥 + 𝑢
The variable 𝑢 is called the disturbance term. When it is incorporated in the model, the relationship
between 𝑥 and 𝑦 changes from a deterministic to a statistical (or stochastic) relationship.
The change to a stochastic relationship between 𝑥 and 𝑦 implies that the variations in the dependent variable
𝑦 is not totally explained by the independent variable 𝑥. The disturbance term, the random variable 𝑢, affects
the value of 𝑦 also. Thus, the values of 𝑦 are also randomly determined. If 𝑢 takes on randomly determined
values, so does 𝑦. The following table shows how the value of the dependent variable 𝑦 (test scores) varies
with u for a given level of 𝑥 (study hours).
If there are 25 questions each with 5 choices, the expected number of correct guesses is 25 × 0.2 = 5. From the scale of
100, the score would be 5 × 4 = 20.
1
3-Simple Regression Model
2 of 31
Different Values of y for a Given Value of 𝑥 When the Relationship is
𝑦 = 20 + 8𝑥 + 𝑢
Value of
𝑥
5
5
5
5
5
5
5
5
5
5
Non Random
Component
20 + 8𝑥
60
60
60
60
60
60
60
60
60
60
Random
Component
𝑢
-12
4
-20
12
16
-12
8
4
20
16
Value of
𝑦
48
64
40
72
76
48
68
64
80
76
We can repeat these calculations assigning other values for 𝑥. The resulting 𝑦 values can all be split between
the non-random component β1 + β2 𝑥 and the random component 𝑢. For each value of 𝑥 there are many
different values of 𝑦. The following diagram shows the various values of 𝑦, test scores, for the three different
values of 𝑥, the hours of study.
y
y = 20 + 8x
76
60
44
0
3
5
7
x
Each set of y values for a given 𝑥, expressed as 𝑦|𝑥𝑖 , has its own independent probability distribution with the
density function 𝑓(𝑦|𝑥𝑖 ). Three of such distributions are shown below, for 𝑦|𝑥 = 3, 𝑦|𝑥 = 5, and 𝑦|𝑥 = 7.
3-Simple Regression Model
3 of 31
This is the two-dimensional depiction of the three density functions. A three-dimensional depiction is
presented in the diagram below.
y
60
44
76
3
5
7
x
1.2. Regression Line as a Locus of Mean Values of y for Different Values of x
This diagram shows clearly that for each value of 𝑥 (hours of study) there are many different 𝑦 values (test
scores). The test scores for each value of 𝑥 are normally distributed. The mean, the expected value, of each
distribution is the nonrandom component of 𝑦:
E(𝑦|𝑥 = 3) = 20 + 8(3) = 44
E(𝑦|𝑥 = 5) = 20 + 8(5) = 60
E(𝑦|𝑥 = 6) = 20 + 8(7) = 76
Thus, even though there are different test scores for each individual value of 𝑥, the expected or average score
is uniquely determined by the slope and intercept parameters alone. For this to hold, the expected value of
the disturbance terms 𝑢𝑖 must be zero.
E(𝑦|𝑥𝑖 ) = E(𝛽1 + 𝛽2 𝑥𝑖 + 𝑢𝑖 )
3-Simple Regression Model
4 of 31
E(𝑦|𝑥𝑖 ) = E(𝛽1 + 𝛽2 𝑥𝑖 ) + E(𝑢𝑖 )
E(𝑦|𝑥𝑖 ) = 𝛽1 + 𝛽2 𝑥𝑖 + E(𝑢𝑖 ). 2
Thus,
E(𝑦|𝑥𝑖 ) = 𝛽1 + 𝛽2 𝑥𝑖
only if E(𝑢𝑖 ) = 0.
The regression line 𝑦 = 𝛽1 + 𝛽2 𝑥 is, therefore, the locus of all the mean values of y for different values of x.
1.3. The Relationship Between the Variance of y and Variance of the Disturbance
Term u
Note that for each value of 𝑥 the values of the dependent variable 𝑦 are dispersed around the center of
gravity, which is the mean value of 𝑦|𝑥. Thus, each 𝑦 value consists of a fixed component, µ𝑦|𝑥 , and a random
component 𝑢:
𝑦|𝑥𝑖 = µ𝑦|𝑥𝑖 + 𝑢
Taking the variance of both sides, we have
var(𝑦|𝑥𝑖 ) = var(µ𝑦|𝑥𝑖 + 𝑢𝑖 ) = var(𝑢𝑖 ) ≡ σ2𝑢
Since µ𝑦|𝑥𝑖 is non-random, then var(µ𝑦|𝑥𝑖 ) = 0.
The diagram also shows that the density functions are similarly shaped. This implies that regardless of the
value of 𝑥, the 𝑦 values for each 𝑥 are similarly dispersed about the mean. This is the “equal-variance” or
homoscedasticity condition:
var(𝑦|𝑥1 ) = var(𝑦|𝑥2 ) = ⋯ = var(𝑦|𝑥𝑛 ) = var(𝑢1 ) = var(𝑢2 ) = ⋯ = var(𝑢𝑛 ) = σ2𝑢
Another feature of the model is that the disturbance term 𝑢 for each 𝑥 are independent. In the test-scorehours-of-study model, this implies that the variations in test scores when, say, 𝑥 = 5, are not affected by the
score variations when 𝑥 = 4 or any other 𝑥 value. Thus, the covariance of any two disturbance terms 𝑢𝑖 and
𝑢𝑗 for each given 𝑥 is zero.
cov(𝑢𝑖 , 𝑢𝑗 ) = E[(𝑢𝑖 − 0)(𝑢𝑗 − 0)] = E(𝑢𝑖 𝑢𝑗 ) = 0
1.4. Summary of Assumptions About the Regression Model
The various assumptions regarding the regression model are summarized as follows:
1.
The regression line is the locus of the mean values of 𝑦 for each given value of 𝑥. The random component
of y is the disturbance term 𝑢. The expected value of 𝑢𝑖 is zero.
𝑦 = β1 + β2 𝑥𝑖 + 𝑢𝑖
Note that here the 𝑥𝑖 are not treated as random variables. The 𝑥𝑖 are given, and the objective is to see how the 𝑦 values
respond to the given values of 𝑥𝑖 . This is why E(𝛽1 + 𝛽2 𝑥𝑖 ) = 𝛽1 + 𝛽2 𝑥𝑖 .
2
3-Simple Regression Model
5 of 31
E(𝑦|𝑥𝑖 ) = β1 + β2 𝑥𝑖
𝐸(𝑢𝑖 ) = 0
2.
Since 𝑢 is the random component of 𝑦, then the variance of 𝑢 and 𝑦 are the same. Furthermore, per
homoscedasticity assumption, the variance of 𝑢 remains the same for all values of 𝑥.
var(𝑦|𝑥𝑖 ) = var(µ𝑦|𝑥𝑖 + 𝑢𝑖 ) = σ2𝑢
var(𝑦|𝑥1 ) = var(𝑦|𝑥2 ) = ⋯ = var(𝑦|𝑥𝑛 ) = var(𝑢1 ) = var(𝑢2 ) = ⋯ = var(𝑢𝑛 ) = σ2𝑢
var(𝑦) = var(𝑢) or σ2𝑦 = σ2𝑢
2.
The variations of 𝑢 for a given value of 𝑥 do not affect the variations of 𝑢 for any other value of 𝑥. That is,
all 𝑢𝑖 are independent random variables, making the covariance zero.
cov(𝑢𝑖 , 𝑢𝑗 ) = E(𝑢𝑖 − 0)(𝑢𝑗 − 0) = E(𝑢𝑖 𝑢𝑗 ) = 0
3. The Estimated Regression Equation and Regression Line
The above explanation of the relationship between 𝑥 and 𝑦 is based on the assumption that we have access to
all population data. It is the theoretical framework for regression. In practice, the population data is rarely
available. We must therefore resort to sampling. Using the sample data we can then determine an estimate of
the population regression equation. The estimated regression equation is:
𝑦 = 𝑏1 + 𝑏2 𝑥 + 𝑒
Here 𝑦 represents the estimator of a 𝑠𝑖𝑛𝑔𝑙𝑒 value of 𝑦 for a given 𝑥 value. The coefficients 𝑏1 and 𝑏2 are the
estimators of the parameters β1 and β2 , and 𝑒 is the estimator of 𝑢. This equation is not the equation for the
estimated regression line. The regression line is represented by:
𝑦̂ = 𝑏1 + 𝑏2 𝑥
where 𝑦̂ (𝑦-hat) is the estimator of the mean value of 𝑦 for each 𝑥 in the population. In a sample regression, 𝑦
is the observed value and 𝑦̂ is the predicted value for a given 𝑥. The difference between the observed and
predicted value is called the prediction error or the residual: 𝑦 − 𝑦̂ = 𝑒.
To explain the determination of the sample regression line, suppose a random sample of 10 students is
selected and the following data regarding hours studied and the test score are obtained.
3-Simple Regression Model
6 of 31
Score
𝑦
52
56
56
72
72
80
88
92
96
100
Hours
Studied
𝑥
2.5
1.0
3.5
3.0
4.5
6.0
5.0
4.0
5.5
7.0
To provide a preliminary indication of the relationship between 𝑥 and 𝑦, we plot the data as a scatter
diagram:
100
90
Test score (y)
80
70
60
50
40
30
20
10
0
0
1
2
3
4
5
6
7
8
Hours studied (x)
Now we need a method to fit the estimated regression line to the scatter diagram. Using the visual method
one may draw any number of lines through the scatter diagram. They would all represent reasonably good
fits. The question is which one is the best fit? We are therefore interested in the best fitting estimated
regression line.
3.1. The Least Squares Method of Obtaining the Coefficients of Estimated
Regression Equation
The mathematical approach to find the best fitting line to the scatter diagram is the Least Squares method.
The estimated regression line determined through the least squares method is the best fitting line because it
minimizes the sum of squared deviations of each observed (scattered) 𝑦 from the corresponding point on the
fitted line for each 𝑥. In the diagram below three such deviations are shown. Since each point on the
regression line corresponding to a given 𝑥 is denoted by 𝑦̂, then the deviation (residual) between the
observed 𝑦 and 𝑦̂ is:
𝑒 = 𝑦 − 𝑦̂
3-Simple Regression Model
7 of 31
Test score (y)
Hours studied (x)
The general form of the equation for the estimated regression line is
𝑦̂ = 𝑏1 + 𝑏2 𝑥
We need to find the values for the coefficients 𝑏1 and 𝑏2 , the intercept and slope coefficients, in order to draw
a line such that the sum of squared residuals,
∑𝑒𝑖2 = ∑(𝑦𝑖 − 𝑦̂𝑖 )2
is minimized.
The least squares method involves minimizing this sum of squared residuals. The following process involves
a mathematical operation called partial differentiation. First rewrite the sum of squared deviations by
substituting for 𝑦̂ so that 𝑏1 and 𝑏2 are explicitly stated.
∑𝑒𝑖2 = ∑(𝑦 − 𝑏1 − 𝑏2 𝑥)2
Find the partial derivative once with respect to 𝑏1 and then with respect to 𝑏2 and set the results equal to
zero. (In calculus this is how the minimum or maximum value of a function is obtained—by setting the first
derivative equal to zero.) The two resulting equations are called the normal equations. (Not to be confused
with normal distribution.)
𝜕∑𝑒 2 ⁄𝜕𝑏1 = −2∑(𝑦 − 𝑏1 − 𝑏2 𝑥) = 0
3
𝜕∑𝑒 2 ⁄𝜕𝑏2 = −2∑𝑥(𝑦 − 𝑏1 − 𝑏2 𝑥) = 0
Using the two normal equations we solve for the two unknowns 𝑏1 and 𝑏2 . Using the properties of
summation, we can write the normal equations as:
∑𝑦 − 𝑛𝑏1 − 𝑏2 ∑𝑥 = 0
When taking the partial derivative with respect to 𝑏1 , we are treating 𝑏1 as the variable and the remaining terms as
constants. Let 𝑦 − 𝑏2 𝑥 ≡ 𝑘, then
∑(𝑦 − 𝑏1 − 𝑏2 𝑥)2 = ∑(𝑘 − 𝑏1 )2 = ∑(𝑘 2 − 2𝑘𝑏1 + 𝑏12 )
Now take the derivative with respect to b1:
∑(−2𝑘 + 2𝑏1 ) = −∑2(𝑘 − 𝑏1 ) = −∑2(𝑦 − 𝑏1 − 𝑏2 𝑥)
3
3-Simple Regression Model
8 of 31
∑𝑥𝑦 − 𝑏1 ∑𝑥 − 𝑏2 ∑𝑥 2 = 0
Since 𝑏1 and 𝑏2 are the “unknowns” or the variables, we can represent the equation system as:
(∑)𝑛𝑏1 + 𝑥(∑𝑥)𝑏2 = ∑𝑦
(∑𝑥)𝑏1 + (∑𝑥 2 )𝑏2 = ∑𝑥𝑦
We can solve for 𝑏1 and 𝑏2 two ways.
Using the matrix notation, the equation system is written as 𝑿𝒃 = 𝒄, where
𝑿=[
𝑛
∑𝑥
∑𝑥
]
∑𝑥 2
“Coefficient” matrix
𝑏
𝒃 = [ 1]
𝑏2
“Variable” matrix
∑𝑦
𝒄=[
]
∑𝑥𝑦
“Constant” matrix
Thus,
[
𝑛
∑𝑥
∑𝑥 𝑏1
∑𝑦
][ ] = [
]
∑𝑥𝑦
∑𝑥 2 𝑏2
The solutions for 𝑏1 and 𝑏2 can be found using Cramer’s rule. First we find the solution for 𝑏2 .
𝑛
∑𝑦
|
∑𝑥 ∑𝑥𝑦
𝑏2 =
𝑛
∑𝑥
|
|
∑𝑥 ∑𝑥 2
|
𝑏2 =
𝑛 ∑ 𝑥𝑦 − ∑ 𝑥 ∑ 𝑦
𝑛 ∑ 𝑥 2 − (∑ 𝑥)2
𝑏2 =
𝑛 ∑ 𝑥𝑦 − (𝑛𝑥̅ )(𝑛𝑦̅)
𝑛 ∑ 𝑥 2 − (𝑛𝑥̅ )2
Dividing the numerator and the denominator by 𝑛, we have,
𝑏2 =
∑ 𝑥𝑦 − 𝑛𝑥̅ 𝑦̅
∑ 𝑥 2 − 𝑛𝑥̅ 2
Now for 𝑏1 ,
∑𝑦 ∑ 𝑥
|
∑𝑥𝑦 ∑𝑥 2
𝑏1 =
𝑛
∑𝑥
|
|
∑𝑥 ∑𝑥 2
|
𝑏2 =
∑ 𝑦 ∑ 𝑥 2 − ∑ 𝑥 ∑ 𝑥𝑦
𝑛 ∑ 𝑥 2 − (∑ 𝑥)2
3-Simple Regression Model
9 of 31
Dividing the numerator and the denominator by 𝑛, we have,
𝑏1 =
𝑦̅ ∑ 𝑥 2 − 𝑥̅ ∑ 𝑥𝑦
∑ 𝑥 2 − 𝑛𝑥̅ 2
Now add ±𝑛𝑥̅ 2 𝑦̅ to the numerator.
𝑏1 =
𝑦̅ ∑ 𝑥 2 − 𝑛𝑥̅ 2 𝑦̅ − 𝑥̅ ∑ 𝑥𝑦 + 𝑛𝑥̅ 2 𝑦̅
∑ 𝑥 2 − 𝑛𝑥̅ 2
𝑏1 =
𝑦̅(∑ 𝑥 2 − 𝑛𝑥̅ 2 ) (∑ 𝑥𝑦 − 𝑛𝑥̅ 𝑦̅)𝑥̅
−
∑ 𝑥 2 − 𝑛𝑥̅ 2
∑ 𝑥 2 − 𝑛𝑥̅ 2
𝑏1 = 𝑦̅ − 𝑏2 𝑥̅
The solutions for 𝑏1 and 𝑏2 can also found by finding the inverse of the coefficient matrix and the postmultiplying the inverse by the constant matrix.
𝑏 = 𝑋 −1 𝑐
To find 𝑿−𝟏, first find the determinant of 𝑿.
|𝑋| = 𝑛∑𝑥 2 − (∑𝑥)2 = 𝑛∑𝑥 2 − (𝑛𝑥̅ )2
|𝑋| = 𝑛(∑𝑥 2 − 𝑛𝑥̅ 2 ) = 𝑛∑(𝑥 − 𝑥̅ )2
Next find the Cofactor matrix,
[𝐶] = [
∑𝑥 2
−∑𝑥
−∑𝑥
]
𝑛
Since the square matrix is symmetric about the principal diagonal, the Adjoint matrix, which is the transpose
of the cofactor matrix, is the same as [𝐶]. The inverse matrix 𝑿−𝟏 is then,
𝑋 −1 =
𝑋 −1
1 ∑𝑥 2
[
|𝑋| −∑𝑥
−∑𝑥
]
𝑛
∑𝑥 2
𝑛∑(𝑥 − 𝑥̅ )2
=
𝑥̅
−
[ ∑(𝑥 − 𝑥̅ )2
𝑥̅
∑(𝑥 − 𝑥̅ )2
1
∑(𝑥 − 𝑥̅ )2 ]
−
It appears that finding the inverse matrix to solve for 𝑏1 and 𝑏2 is too complicated. However, this approach is
far more practical when applied in multiple regression, where the same pattern is used to solve for the
coefficients of the regression function.
1.1.1. Alternative Expression for the 𝒃𝟐 formula
In chapter 1 it was shown that the numerator of the sample variance formula, the sum of square deviations,
can be written as:
∑(𝑥 − 𝑥̅ )2 = ∑𝑥 2 − 𝑛𝑥̅ 2
3-Simple Regression Model
10 of 31
And the numerator of the covariance of 𝑥 and 𝑦 as:
∑(𝑥 − 𝑥̅ )(𝑦 − 𝑦̅) = ∑𝑥𝑦 − 𝑛𝑥̅ 𝑦̅
Thus the formula to compute 𝑏2 can be written either as
𝑏2 =
∑𝑥𝑦 − 𝑛𝑥̅ 𝑦̅
∑𝑥 2 − 𝑛𝑥̅ 2
or,
𝑏2 =
∑(𝑥 − 𝑥̅ )(𝑦 − 𝑦̅)
∑(𝑥 − 𝑥̅ )2
The latter expression will be used in some subsequent proofs.
Now we can compute the estimated regression line for test scores and hours studied:
𝑏2 =
𝑦
52
56
56
72
72
80
88
92
96
100
𝑥
2.5
1.0
3.5
3.0
4.5
6.0
5.0
4.0
5.5
7.0
𝑥𝑦
130
56
196
216
324
480
440
368
528
700
𝑥2
6.25
1.00
12.25
9.00
20.25
36.00
25.00
16.00
30.25
49.00
𝑦̅ = 76.4
𝑥̅ = 4.2
∑𝑥𝑦 = 3438
∑𝑥 2 = 205.00
3438 − (10)(4.2)(76.4)
= 8.01399
205 − (10)(4.2)2
𝑏1 = 76.4 − (8.01399)(4.2) = 42.74126
The estimated regression equation is then,
𝑦̂ = 42.74126 − 8.01399𝑥
Using this estimated regression line now we can predict the mean score for a given number of hours of study.
Let 𝑥 = 3.
𝑦̂ = 42.74126 − 8.01399(3) = 66.78
The following table shows all the predicted values and the deviations. It also shows the computation of the
sum of squared residuals:
3-Simple Regression Model
11 of 31
𝑥
2.5
1.0
3.5
3.0
4.5
6.0
5.0
4.0
5.5
7.0
𝑦
52
56
56
72
72
80
88
92
96
100
𝑦̂
62.78
50.76
70.79
66.78
78.80
90.83
82.81
74.80
86.82
98.84
𝑒 = 𝑦 − 𝑦̂
-10.78
5.24
-14.79
5.22
-6.80
-10.83
5.19
17.20
9.18
1.16
∑𝑒 = ∑(𝑦 − 𝑦) = 0.00
𝑒 2 = (𝑦 − 𝑦̂)2
116.13
27.51
218.75
27.21
46.30
117.18
26.92
295.94
84.31
1.35
∑𝑒 2 = ∑(𝑦 − 𝑦)2 = 961.59
The table also shows that ∑𝑒 = ∑(𝑦 − 𝑦̂) = 0. That is, the sum of residuals is zero. The mathematical proof
follows:
∑(𝑦 − 𝑦̂) = ∑(𝑦 − 𝑏1 − 𝑏2 𝑥 )
∑(𝑦 − 𝑦̂) = ∑𝑦 − 𝑛𝑏1 − 𝑏2 ∑𝑥
∑(𝑦 − 𝑦̂) = 𝑛(𝑦̅ − 𝑏1 − 𝑏2 𝑥̅ )
Substituting for 𝑏1 we have,
∑(𝑦 − 𝑦̂) = 𝑛(𝑦̅ − 𝑦̅ + 𝑏2 𝑥̅ − 𝑏2 𝑥̅ ) = 0
The value ∑𝑒 2 = ∑(𝑦 − 𝑦)2 = 961.59 indicates that any other line fitted to the scatter diagram would yield a
sum of squared residuals that would be greater than 961.59. This is our least squares value.
4. Statistical Properties of Least Squares Estimators 𝒃𝟏 and 𝒃𝟐 —The Gauss-Markov
Theorem
4.1. Sampling Distributions of Coefficients of Regression Equation
To determine the regression equation we compute the coefficient of the regression 𝑏1 and 𝑏2 from a randomly
selected sample. Therefore, 𝑏1 and 𝑏2 are summary characteristics obtained from sample data, and, as such,
each is sample statistic, functioning as estimators of the population parameters 𝛽1 and 𝛽2 , the population
intercept and slope coefficients. Being sample statistics, 𝑏1 and 𝑏2 have the same features as the sample
statistic 𝑥̅ , the sample mean. Take 𝑏2 , for example. Since there are infinite number of possible samples of size
𝑛 out there, then the number of 𝑏2 estimate is also infinite. Given certain requirements, explained below, the
sampling distribution of 𝑏2 is normal with a center of gravity of E(𝑏2 ) = 𝛽2 and a measure of dispersion of
se(𝑏2 ). The following diagram shows the comparison, the similarities, between the sampling distribution of 𝑥̅
and the sampling distribution of 𝑏2 .
3-Simple Regression Model
12 of 31
Sampling Distribution of 𝑥̅
Sampling Distribution of 𝑏2
4.2. Coefficients 𝒃𝟏 and 𝒃𝟐 are the Best Linear Unbiased Estimators
A well-known term in regression analysis is that 𝑏1 and 𝑏2 are BLUE. They are the Best Linear Unbiased
Estimators. This is why these estimators are preferred to estimators that may be obtained through other
methods. The mathematical proof of each of these statistical properties is shown below.
4.2.1.
𝒃𝟏 and 𝒃𝟐 are linear functions of y.
The significance of the linear relationship between the coefficients and the dependent variable y will become
clear when we conduct statistical inference with respect to the population parameters β1 and β2 , using the
sample statistics 𝑏1 and 𝑏2 , respectively. As sample statistics used as estimators of population parameters,
the distributions of 𝑏1 and 𝑏2 must be normal for inferential statistics purposes. If we show that 𝑏1 and 𝑏2
are linear functions of 𝑦, given that 𝑦 is normally distributed, then 𝑏1 and 𝑏2 are also normally distributed.
But first, what do we mean when we say the relationship between any two variables is linear? Generally,
consider any two variables 𝑥 and 𝑦. A linear relationship between 𝑦 and 𝑥 is expressed as:
𝑦 = 𝑎 + 𝑏𝑥
The linearity of the relationship is established by the fact that the coefficients 𝑎 and 𝑏 are constants and the
exponent of 𝑥 is 1. For a given values of 𝑎 (the intercept) and 𝑏 (the slope), the relationship between 𝑥 and 𝑦
is reflected in a straight (non-curved) curve. Thus when we say that the functional relationship in the
regression model between 𝑏1 and 𝑦, and between 𝑏2 and 𝑦 is linear, we need to show that this relationship
can be expressed as
𝑏1 = 𝑘1 𝑦
and
𝑏2 = 𝑘2 𝑦
where 𝑘1 and 𝑘2 are two constants relating 𝑦 to 𝑏1 and 𝑏2 , respectively. First, let’s show that 𝑏2 is a linear
function of 𝑦. Using the alternative expression of the formula to compute the 𝑏2 ,
𝑏2 =
∑(𝑥 − 𝑥̅ )(𝑦 − 𝑦̅)
∑(𝑥 − 𝑥̅ )2
𝑏2 =
∑(𝑥 − 𝑥̅ )𝑦 − 𝑦̅∑(𝑥 − 𝑥̅ )
∑(𝑥 − 𝑥̅ )2
Since ∑(𝑥 − 𝑥̅ ) = 0, then the right-hand-side is simplified into
3-Simple Regression Model
13 of 31
𝑏2 =
∑(𝑥 − 𝑥̅ )𝑦
∑(𝑥 − 𝑥̅ )2
To make presentation of the proof simpler, define
𝑤=
𝑥 − 𝑥̅
∑(𝑥 − 𝑥̅ )2
Then,
𝑏2 =
∑(𝑥 − 𝑥̅ )𝑦
= ∑𝑤𝑦
∑(𝑥 − 𝑥̅ )2
𝑏2 = 𝑤1 𝑦2 + 𝑤2 𝑦2 + ⋯ 𝑤𝑛 𝑦𝑛
Thus 𝑏2 is a linear function (linear combination) of 𝑦𝑖 because 𝑤𝑖 are fixed constants in repeated sampling. 4
The proof that 𝑏1 is also a linear function 𝑦 is simple. Note that
𝑏1 = 𝑦̅ − 𝑏2 𝑥̅
Since 𝑦̅ and 𝑥̅ are fixed for each sample, then 𝑏1 is a linear function of 𝑏2 , which makes it, in turn, a linear
function of 𝑦.
4.2.2. 𝒃𝟏 and 𝒃𝟐 are unbiased estimators of population parameters 𝛃𝟏 and 𝛃𝟐
Any sample statistic is an unbiased estimator of a population parameter if the expected value of the sample
statistic is equal to the population parameter. Thus, we need to show that: E(𝑏2 ) = β2 and E(𝑏1 ) = β1 .
4.2.2.1.
𝐄(𝒃𝟐 ) = 𝛃𝟐
We want to show that E(𝑏2 ) = β2 . In all the mathematical proofs regarding expected values in regression you
should keep in mind that all the terms involving 𝑥 are treated as non-random, since 𝑥 is a non-stochastic
(control) variable. Thus the expected value of 𝑥 or any term involving 𝑥 is the 𝑥 or the term itself. That is,
E(𝑥) = 𝑥
or
E[∑(𝑥 − 𝑥̅ )2 ] = ∑(𝑥 − 𝑥̅ )2 .
We just showed that,
𝑏2 =
∑(𝑥 − 𝑥̅ )𝑦
= ∑𝑤𝑦
∑(𝑥 − 𝑥̅ )2
Therefore,
E(𝑏2 ) = E(∑𝑤𝑦)
4
Each 𝑤𝑖 is a function of 𝑥𝑖 and 𝑥 is a control variable, whose values are assigned rather than randomly obtained.
3-Simple Regression Model
14 of 31
E(𝑏2 ) = E(𝑤1 𝑦2 + 𝑤2 𝑦2 + ⋯ 𝑤𝑛 𝑦𝑛 )
E(𝑏2 ) = E(𝑤1 𝑦2 ) + E(𝑤2 𝑦2 ) + ⋯ E(𝑤𝑛 𝑦𝑛 )
E(𝑏2 ) = 𝑤1 E(𝑦2 ) + 𝑤2 E(𝑦2 ) + ⋯ 𝑤𝑛 E(𝑦𝑛 ) = ∑𝑤E(𝑦)
Substituting for 𝑦 in ∑𝑤E(𝑦),
E(𝑏2 ) = ∑[𝑤E(β1 + β2 𝑥 + 𝑢)]
E(𝑏2 ) = ∑[𝑤(β1 + β2 𝑥) + 𝑤E(𝑢)]
E(𝑏2 ) = β1 ∑𝑤 + β2 ∑𝑤𝑥 + ∑𝑤E(𝑢)
E(𝑏2 ) = β2 ∑𝑤𝑥
Note that ∑𝑤 =
∑(𝑥−𝑥̅ )
∑(𝑥−𝑥̅ )2
= 0 [the numerator, ∑(𝑥 − 𝑥̅ ) = 0] and E(𝑢) = 0.
Thus,
E(𝑏2 ) = β2 ∑𝑤𝑥 = β2
∑(𝑥 − 𝑥̅ )𝑥
∑(𝑥 − 𝑥̅ )2
Now note that in the denominator of the right-hand-side expression can be stated as
∑(𝑥 − 𝑥̅ )2 = ∑(𝑥 − 𝑥̅ )(𝑥 − 𝑥̅ ) = ∑(𝑥 − 𝑥̅ )𝑥 − 𝑥̅ ∑(𝑥 − 𝑥̅ ) = ∑(𝑥 − 𝑥̅ )𝑥
then
∑𝑤𝑥 =
∑(𝑥 − 𝑥̅ )𝑥
=1
∑(𝑥 − 𝑥̅ )𝑥
Thus,
E(𝑏2 ) = β2 .
4.2.2.2. E(b1) = β1.
Prove that the expected value of the intercept coefficient is equal to the population intercept parameter.
𝑏1 = 𝑦̅ − 𝑏2 𝑥̅ =
𝑏1 =
∑𝑦
− 𝑏2 𝑥̅
𝑛
1
∑(𝛽1 + 𝛽2 𝑥 + 𝑢) − 𝑏2 𝑥̅
𝑛
1
𝑏1 = 𝛽1 + 𝛽2 𝑥̅ + ∑𝑢 − 𝑏2 𝑥̅
𝑛
1
E(𝑏1 ) = E[𝛽1 + 𝛽2 𝑥̅ + ∑𝑢 − 𝑏2 𝑥̅ ]
𝑛
3-Simple Regression Model
15 of 31
1
E(𝑏1 ) = 𝛽1 + 𝛽2 𝑥̅ + E ( ∑𝑢) − E(𝑏2 𝑥̅ )
𝑛
1
Note that since ∑𝑢 = 0, then E ( ∑𝑢) = 0, and E(𝑏2 𝑥̅ ) = 𝑥̅ E(𝑏2 ) = 𝛽2 𝑥̅ .
𝑛
Thus,
E(𝑏1 ) = 𝛽1 + 𝛽2 𝑥̅ − 𝛽2 𝑥̅ = 𝛽1
4.2.3.
As Estimators of Parameters 𝜷𝟏 and 𝜷𝟐 , 𝒃𝟏 and 𝒃𝟐 Have the Minimum Variance
4.2.3.1.
Variance of 𝒃𝟐
It is important to understand what the variance of the regression slope coefficient 𝑏2 represents. Note that 𝑏2 ,
as the estimator of 𝛽2 , is a sample statistic whose value is obtained through a random sampling process, thus
making 𝑏2 a random variable. The sample statistic 𝑏2 has a sampling distribution whose expected value is the
population parameter 𝛽2 and its (squared) measure of dispersion is the variance of 𝑏2 , denoted by var(𝑏2 ).
The same argument goes for 𝑏1 .
To show that 𝑏1 and 𝑏2 are the best linear unbiased estimators, we need to determine the formulas for the
variance of the two estimators. First, let’s attend to the variance of the slope coefficient 𝑏2 .
The variance of the random variable 𝑏2 is defined as the expected value of the squared deviation of the
random variable from its expected value. The squared deviation of interest here is (𝑏2 − 𝛽2 )2 . Therefore,
var(𝑏2 ) = E[(𝑏2 − 𝛽2 )2 ]
The following steps show how the formula for var(𝑏2 ) is obtained.
𝑏2 =
∑(𝑥 − 𝑥̅ )𝑦
= ∑𝑤𝑦
∑(𝑥 − 𝑥̅ )2
𝑏2 = ∑𝑤(𝛽1 + 𝛽2 𝑥 + 𝑢)
𝑏2 = 𝛽1 ∑𝑤 + 𝛽2 ∑𝑤𝑥 + ∑𝑤𝑢)
𝑏2 = 𝛽2 + ∑𝑤𝑢
Note: ∑𝑤 = 0 and ∑𝑤𝑥 = 1
Thus,
𝑏2 − 𝛽2 = ∑𝑤𝑢
The variance of 𝑏2 is then,
var(𝑏2 ) = E[(𝑏2 − 𝛽2 )2 ] = E[(∑𝑤𝑢)2 ]
E[(∑𝑤𝑢)2 ] = E(𝑤12 𝑢12 + 𝑤22 𝑢22 + ⋯ + 𝑤𝑛2 𝑢𝑛2 + 2𝑤1 𝑤2 𝑢1 𝑢2 + ⋯ + 2𝑤𝑛−1 𝑤𝑛 𝑢𝑛−1 𝑢𝑛 )
E[(∑𝑤𝑢)2 ] = 𝑤12 E(𝑢12 ) + 𝑤22 E(𝑢22 ) + ⋯ + 𝑤𝑛2 E(𝑢𝑛2 ) + 2𝑤1 𝑤2 E(𝑢1 𝑢2 ) + ⋯ + 2𝑤𝑛−1 𝑤𝑛 E(𝑢𝑛−1 𝑢𝑛 )
Since the expected value of the disturbance term u is zero, that is, E(𝑢𝑖 ) = 0, then
var(𝑢𝑖 ) = E{[𝑢𝑖 − E(𝑢𝑖 )]2 } = E(𝑢𝑖2 )
3-Simple Regression Model
16 of 31
By the homoscedasticity assumption, E(𝑢𝑖2 ) = 𝜎𝑢2 , and by the independence-of-disturbance-terms
assumption, we have cov(𝑢𝑖 𝑢𝑗 ) = E(𝑢𝑖 𝑢𝑗 ) = 0.
Therefore,
var(𝑏2 ) = 𝑤12 𝜎𝑢2 + 𝑤22 𝜎𝑢2 + ⋯ + 𝑤𝑛2 𝜎𝑢2
var(𝑏2 ) = 𝜎𝑢2 ∑𝑤 2
Note that,
𝑤=
𝑥 − 𝑥̅
∑(𝑥 − 𝑥̅ )2
𝑤2 =
(𝑥 − 𝑥̅ )2
[∑(𝑥 − 𝑥̅ )2 ]2
Summing over all 𝑥𝑖 , we have
∑𝑤 2 =
∑(𝑥 − 𝑥̅ )2
1
=
2
2
[∑(𝑥 − 𝑥̅ ) ]
∑(𝑥 − 𝑥̅ )2
Thus,
var(𝑏2 ) =
𝜎𝑢2
∑(𝑥 − 𝑥̅ )2
4.2.3.2.
Variance of b1
The variance for the estimated regression intercept coefficient is defined as,
var(𝑏1 ) = E[(𝑏1 − 𝛽1 )2 ]
The relationship, between var(𝑏1 ) and the variance of u is as follows:
var(𝑏1 ) =
∑𝑥 2
𝑛∑(𝑥 − 𝑥̅ )2
𝜎𝑢2
For the derivation of the formula see the Appendix at the end of this chapter.
4.2.3.3.
Covariance of b1 and b2
The covariance of the regression coefficients is defined as:
cov(𝑏1 , 𝑏2 ) = E[(𝑏1 − 𝛽1 )(𝑏2 − 𝛽2 )]
Again, the relationship between the covariance of the regression coefficients and the variance of 𝑢 is as
follows:
3-Simple Regression Model
17 of 31
cov(𝑏1 , 𝑏2 ) = −
𝑥̅
𝜎2
∑(𝑥 − 𝑥̅ )2 𝑢
Note that cov(𝑏1 , 𝑏2 ) is obtained by simply multiplying var(𝑏2 ) by −𝑥̅ . The derivation of this relationship is
explained in the Appendix.
4.2.4.
The Covariance Matrix
We can use the inverse matrix X −1 to obtain the variances and the covariance for the regression coefficients.
𝑋 −1
∑𝑥 2
𝑛∑(𝑥 − 𝑥̅ )2
=
𝑥̅
−
[ ∑(𝑥 − 𝑥̅ )2
𝑥̅
∑(𝑥 − 𝑥̅ )2
1
∑(𝑥 − 𝑥̅ )2 ]
−
The covariance matrix is obtained by the scalar multiplication of the inverse matrix with 𝜎𝑢2
[
var(𝑏1 )
cov(𝑏1 , 𝑏2 )
∑𝑥 2
cov(𝑏1 , 𝑏2 )
𝑛∑(𝑥 − 𝑥̅ )2
] = 𝜎𝑢2
var(𝑏2 )
𝑥̅
−
[ ∑(𝑥 − 𝑥̅ )2
𝑥̅
∑𝑥 2
𝜎2
∑(𝑥 − 𝑥̅ )2
𝑛∑(𝑥 − 𝑥̅ )2 𝑢
=
1
𝑥̅
−
𝜎2
2
)
∑(𝑥 − 𝑥̅ ] [ ∑(𝑥 − 𝑥̅ )2 𝑢
−
𝑥̅
𝜎2
∑(𝑥 − 𝑥̅ )2 𝑢
1
𝜎2
∑(𝑥 − 𝑥̅ )2 𝑢 ]
−
This procedure will become very handy in multiple regression with several regression coefficients.
4.2.5.
𝒃𝟐 is the Best linear unbiased estimator of 𝜷𝟐
The term “best” means that no other estimator of 𝛽2 has a smaller variance than 𝑏2 . This is shown below:
As derived above,
𝑏2 =
∑(𝑥 − 𝑥̅ )𝑦
= ∑𝑤𝑦
∑(𝑥 − 𝑥̅ )2
Also,
𝑏2 = 𝛽2 +
∑(𝑥 − 𝑥̅ )𝑢
= 𝛽2 + ∑𝑤𝑢
∑(𝑥 − 𝑥̅ )2
Now let 𝑏̂2 be an alternative estimator of 𝛽2 such that
𝑏̂2 = ∑𝑐𝑦
Where 𝑐 = 𝑤 + 𝑑. The term 𝑤 is defined as before, and 𝑑 is an arbitrary constant. Substituting for 𝑦 = 𝛽1 +
𝛽2 𝑥 + 𝑢 in the above relationship, we have
𝑏̂2 = ∑𝑐(𝛽1 + 𝛽2 𝑥 + 𝑢)
𝑏̂2 = 𝛽1 ∑𝑐 + 𝛽2 ∑𝑐𝑥 + ∑𝑐𝑢
The expected value of 𝑏̂2 is then,
3-Simple Regression Model
18 of 31
E(𝑏̂2 ) = 𝛽1 ∑𝑐 + 𝛽2 ∑𝑐𝑥 + E(∑𝑐𝑢)
E(𝑏̂2 ) = 𝛽1 ∑𝑐 + 𝛽2 ∑𝑐𝑥
since E(∑𝑐𝑢) = ∑𝑐E(𝑢) = 0
𝑏̂2 would be an unbiased estimator if and only if ∑𝑐 = 0, and ∑𝑐𝑥 = 1
∑𝑐 = ∑𝑤 + ∑𝑑
Since ∑𝑐 = ∑𝑤 = 0, then ∑𝑑 = 0
∑𝑐𝑥 = ∑𝑤𝑥 + ∑𝑑𝑥
Since ∑𝑐𝑥 = ∑𝑤𝑥 = 1, then ∑𝑑𝑥 = 0
Having established that for 𝑏̂2 to be unbiased, ∑𝑑 = ∑𝑑𝑥 = 0, now we can attend to the variance of 𝑏̂2 ,
var(𝑏̂2 ).
𝑏̂2 = 𝛽2 + ∑𝑐𝑢
𝑏̂2 − 𝛽2 = ∑𝑐𝑢
2
var(𝑏̂2 ) = E [(𝑏̂2 − 𝛽2 ) ] = E[(∑𝑐𝑢)2 ]
var(𝑏̂2 ) = σ2𝑢 ∑𝑐 2
The term ∑𝑐2 can be written as,
∑𝑐 2 = ∑(𝑤 + 𝑑)2 = ∑𝑤 2 + ∑𝑑 2 + 2∑𝑤𝑑
∑𝑤𝑑 = 𝑑∑𝑤 = 0
∑𝑐 2 = ∑𝑤 2 + ∑𝑑 2
Thus,
var(𝑏̂2 ) = σ2𝑢 ∑𝑐 2 = σ2𝑢 (∑𝑤 2 + ∑𝑑 2 )
var(𝑏̂2 ) = σ2𝑢 ∑𝑤 2 + σ2𝑢 ∑𝑑 2
var(𝑏̂2 ) = var(𝑏2 ) + σ2𝑢 ∑𝑑 2
Since the second term on the right-hand-side, σ2𝑢 ∑𝑑 2 > 0, then
var(𝑏̂2 ) > var(𝑏2 )
5. The Estimator of the Variance of the Prediction Error
As explained above, in the simple linear regression model, the disturbance (error) term 𝑢 represents the
random component of the dependent variable 𝑦 for a given 𝑥: 𝑦 = 𝛽1 + 𝛽2 𝑥 + 𝑢. One of the major
assumptions of the model is that the error terms are normally distributed about the mean 𝑦 for a given 𝑥,
µ𝑦|𝑥 , and under the homoscedasticity assumption, the variance of 𝑢, 𝜎𝑢2 , remains unchanged for values of 𝑥.
When sample data is used to estimate the population regression equation, among the important summary
characteristics computed from the sample data is the standard error of estimate, se(𝑒). This sample statistic is
the square root of the sample variance of the error term, var(𝑒), which is the estimator of the population 𝜎𝑢2 .
3-Simple Regression Model
19 of 31
The comparison of the population regression equation with the sample regression equation shows the
relationship between 𝑢 and 𝑒.
Population:
Sample:
𝑦 = 𝛽1 + 𝛽2 𝑥 + 𝑢
𝑦 = 𝑏1 + 𝑏2 𝑥 + 𝑒
The equation for the sample regression line, which is fitted to the scatter diagram through the least squares
method, is
𝑦̂ = 𝑏1 + 𝑏2 𝑥
Substituting for 𝑦̂ in the sample regression function 𝑦 = 𝑏1 + 𝑏2 𝑥 + 𝑒, we have
𝑦 = 𝑦̂ + 𝑒
Thus, the error term or the residual is the difference between the observed 𝑦 and the predicted 𝑦, 𝑦̂, in the
sample:
𝑒 = 𝑦 − 𝑦̂
The variance of 𝑒 is, like all variances, is defined as the mean squared deviation from the mean. Here the
squared deviation of 𝑒 is: (𝑒 − 𝑒̅)2 , where
𝑒̅ =
∑𝑒
𝑛
Since, as shown previously, ∑𝑒 = 0, then 𝑒̅ = 0. Therefore, the squared deviation of 𝑒 is simply 𝑒 2 .
To find the mean squared deviation we divided the sum of squared deviation by the sample size 𝑛. But if sum
of squared deviation of 𝑒 is divided by 𝑛 alone the result is a sample variance which is a biased estimator of
the population variance. To obtain an unbiased estimator of σ2𝑢 , the formula for the sample variance of 𝑒 is:
var(𝑒) =
∑𝑒 2
𝑛−2
5.1.
𝐯𝐚𝐫(𝒆) is an unbiased estimator of 𝛔𝟐𝒖
For var(𝑒) to be an unbiased estimator of σ2𝑢 , we must prove that,
E[var(𝑒)] = E (
∑𝑒 2
𝑛−2
) = σ2𝑢
The proof is shown in the Appendix.
5.2.
The Standard Error of Estimate
The square root of the var(𝑒) is called the standard error of estimate: se(𝑒).
se(𝑒) = √
∑𝑒 2
∑(𝑦 − 𝑦̂)2
=√
𝑛−2
𝑛−2
3-Simple Regression Model
20 of 31
Using ∑𝑒 2 = ∑(𝑦 − 𝑦̂)2 = 961.59 as computed above for the test score-hours of study example,
se(𝑒) = √
961.59
= 10.9635
8
The standard error of the estimate is a measure of the dispersion of the observed y about the regression line.
The more scattered the points in a scatter diagram, the bigger the standard error of estimate. Thus, se(𝑒)
provides an estimate of the dispersion of the disturbance term in the population, σ𝑢 . The larger the random
component of the dependent variable in the population, the more scattered the sample data will be about the
regression line. The standard error of estimate, therefore, provides a measure of the strength of the
relationship by the dependent and the independent variables. However, since value of se(𝑒) is affected by the
scale of the data, the absolute size of the standard error of estimate does not necessarily reflect how closely 𝑦
and 𝑥 are related.
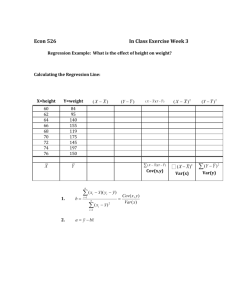
Example: Household food expenditure and weekly income
The data and other calculations are in the Excel file CH3 DATA.xlsx (“food” tab). The data (𝑛 = 40) shows the
weekly food expenditure of 40 households in dollars and weekly income in hundreds of dollars ($100). Let
𝑥 = 𝑤𝑒𝑒𝑘𝑙𝑦 𝑖𝑛𝑐𝑜𝑚𝑒 and 𝑦 = 𝑤𝑒𝑒𝑘𝑙𝑦 𝑓𝑜𝑜𝑑 𝑒𝑥𝑝𝑒𝑛𝑑𝑖𝑡𝑢𝑟𝑒.
The coefficients of the sample regression equation
𝑦̂ = 𝑏1 + 𝑏2 𝑥
Let’s use the matrix method. First determine the elements of the matrix 𝑋 and 𝑐
𝑋=[
𝑋=[
𝑛
∑𝑥
∑𝑥
]
∑𝑥 2
40
784.19
∑𝑦
𝑐=[
]
∑𝑥𝑦
784.19
]
17202.64
11342.94
𝑐=[
]
241046.8
Using Excel, you can easily find the 𝑋 −1, the inverse matrix.
0.23516
𝑋 −1 = [
−0.01072
−0.01072
]
0.00055
Then,
𝑏
0.23516
[ 1 ] = 𝑋 −1 ∙ 𝑐 = [
𝑏2
−0.01072
−0.01072 11342.94
][
]
0.00055 241046.8
𝑏
83.4160
[ 1] = [
]
𝑏2
10.2096
Thus,
𝑦̂ = 83.416 + 10.2096𝑥
The value 𝑏2 = 10.21 implies that for each additional $100 income, we estimate that weekly expenditure is
expected to rise by $10.21. The following diagram shows the estimated regression line fitted to the scatter
diagram.
3-Simple Regression Model
21 of 31
The Fitted Regression
y = weekly food expenditure ($)
700
600
500
Point of the means (𝑥̅ , 𝑦̅)
ŷ
400
300
200
100
0
0
10
20
30
40
x = weekly income ($100)
Point of the means
Note that the regression line goes through the point of the means. This means that when 𝑥 = 𝑥̅ , then 𝑦̂ = 𝑦̅.
𝑦̂ = 𝑏1 + 𝑏2 𝑥
substitute 𝑥̅ for 𝑥 and for 𝑏1 = 𝑦̅ − 𝑏2 𝑥̅ in the regression equation.
𝑦̂ = 𝑦̅ − 𝑏2 𝑥̅ + 𝑏2 𝑥̅
𝑦̂ = 𝑦̅
When 𝑥 = 𝑥̅ = 19.6, then 𝑦̂ = 83.416 + 10.2096(19.6) = 283.57 = 𝑦̅.
Income elasticity of food expenditure
Income elasticity measures how sensitive food expenditure is to changes in income. Elasticity shows the
proportionate (percentage) change in food expenditure relative to a proportionate or percentage change in
income
𝜀=
𝑑𝑦̂⁄𝑦̂ 𝑑𝑦̂ 𝑥
𝑥
=
= 𝑏2
𝑑𝑥 ⁄𝑥 𝑑𝑥 𝑦̂
𝑦̂
Find the elasticity at the point of the means.
𝜀 = 10.2096 ×
19.6
= 0.71
283.57
This shows that at the point of the means, it is estimated that food expenditure rises by 0.71% for each 1%
rise in income.
3-Simple Regression Model
22 of 31
Variance of “e”
var(𝑒) =
∑𝑒 2
∑(𝑦 − 𝑦̂)2
=
𝑛−2
𝑛−2
var(𝑒) =
304505.18
= 8013.294
38
The covariance matrix
The covariance matrix shows the variance of regression coefficients and their covariance.
[
var(𝑏1 )
cov(𝑏1 , 𝑏2 )
cov(𝑏1 , 𝑏2 )
]
var(𝑏2 )
The individual elements of the matrix can be computed using the respective formulas:
var(𝑏1 ) = var(𝑒) ×
var(𝑏2 ) =
∑𝑥 2
17202.64
= 8013.294 ×
= 1884.442
2
𝑛∑(𝑥 − 𝑥̅ )
40 × 1828.788
var(𝑒)
8013.294
=
= 4.382
∑(𝑥 − 𝑥̅ )2 41828.788
cov(𝑏1 , 𝑏2 ) = var(𝑒) ×
[
var(𝑏1 )
cov(𝑏1 , 𝑏2 )
−𝑥̅
−19.605
= 8013.294 ×
= −85.903
∑(𝑥 − 𝑥̅ )2
1828.788
cov(𝑏1 , 𝑏2 )
1884.442
]=[
var(𝑏2 )
−85.903
−85.903
]
4.382
We can obtain this matrix through the scalar multiplication of the inverse matrix 𝑋 −1 by var(𝑒).
var(𝑒)𝑋 −1 = 8013.294 × [
0.23516
−0.01072
−0.01072
1884.442
]=[
0.00055
−85.903
−85.903
]
4.382
2. Nonlinear Relationships
In explaining the simple linear regression model we have assumed that the population parameters 𝛽1 and 𝛽2
are linear—that is, they are not expressed as, say, 𝛽22 , 1⁄𝛽2 , or any form other than 𝛽2 —and also the impact of
the changes in the independent variable on y works directly through x rather than through expressions such
as, say, 𝑥 2 or ln(𝑥).
In this section, we will continue assuming that the regression is linear in parameters, but relax the
assumption of linearity of the variables. In many economic models the relationship between the dependent
and independent variables is not a straight line relationship. That is the change in 𝑦 does not follow the same
pattern for all values of 𝑥. Consider for example an economic model explaining the relationship between
expenditure on food (or housing) and income. As income rises, we do expect expenditure on food to rise, but
not at a constant rate. In fact, we should expect the rate of increase in expenditure on food to decrease as
income rises. Therefore the relationship between income and food expenditure is not a straight-line
relationship. The following is an outline of various functional forms encountered in regression analysis.
3-Simple Regression Model
23 of 31
2.1. Quadratic Model
In a quadratic model the explanatory variable appears as a squared quantity.
𝑦̂ = 𝑏1 + 𝑏2 𝑥 2
Example: House Price and Size
The data and other calculations are in the Excel file CH3 DATA.xlsx (“𝑏𝑟” tab). The data show the prices of
1080 houses sold in Baton Rouge, Louisiana, in the 2005. The explanatory variable is the size of the house (in
square feet). Estimate the following model
̂ = 𝑏1 + 𝑏2 𝑆𝑄𝐹𝑇 2
𝑃𝑅𝐼𝐶𝐸
The process of finding the values of the coefficients is exactly the same as before. Once the explanatory
variables are squared, then they are treated as just another set of 𝑥 data. But when the coefficients are
estimated, beware of the significant difference in the interpretation of their values compared to the linear
regression coefficients.
𝑦̂ = 55776.566 + 0.0154𝑥 2
Now note that the regression function is not linear. Therefore, unlike a linear function, the slope is not a
constant. The slope here is defined for each point on the graph and it is the first derivative of the function.
𝑑𝑦̂
= 2𝑏2 𝑥
𝑑𝑥
The table below and the following diagram show that when size is 2000 square feet the price rises by $61.69
per square foot, for a house with 4,000 square feet, price rises by $123.37, and by $185.06 for each additional
square foot for a size of 6,000 square feet.
𝑥 = 𝑆𝑄𝐹𝑇
2,000
4,000
6,000
3-Simple Regression Model
𝑏2 = 0.0154
𝑑𝑦̂⁄𝑑𝑥 = 2𝑏2 𝑥
$61.69
123.37
185.06
24 of 31
1000000
ŷ
900000
800000
Sales price ($)
700000
185.06
600000
500000
400000
123.37
300000
200000
61.69
100000
0
0
1000
2000
3000
4000
5000
6000
7000
8000
Total square feel
Elasticity
𝜀=
𝑑𝑦̂⁄𝑦̂ 𝑑𝑦̂ 𝑥
𝑥
=
= (2𝑏2 𝑥)
𝑑𝑥 ⁄𝑥 𝑑𝑥 𝑦̂
𝑦̂
𝑥
2,000
4,000
6,000
𝑦
117,462
302,517
610,943
𝑏2 = 0.0154
𝜀 = 2𝑏2 𝑥 2 ⁄𝑦̂
1.05
1.63
1.82
For example, for a house with 4,000 feet, a 1% increase in the size adds 1.63% to the price.
2.2. Log-Linear Model
The log-linear model takes the form of
̂ = 𝑏1 + 𝑏2 𝑥
ln(𝑦)
To run the model you must first change the 𝑦 values to ln(𝑦). The procedure is then as usual. Again, beware
of the change in the interpretation of the 𝑏2 coefficient and the required adjustment to find the predicted
value. Use the same data from the previous example in the 𝑏𝑟 tab. The result of the regression is:
̂
ln(𝑃𝑅𝐼𝐶𝐸)
= 10.8386 + 0.00041𝑆𝑄𝐹𝑇
Prediction
When you plug in values for 𝑆𝑄𝐹𝑇 in the regression equation, the predicted value will be in terms of ln(𝑦).
You must then take the exponent to find 𝑦̂.
3-Simple Regression Model
25 of 31
̂
̂
ln
(𝑦)
11.66
12.48
13.31
𝑥
2,000
4,000
6,000
𝑦̂ = 𝑒 ln(𝑦)
115,975.47
263,991.38
600,915.40
Interpretation of the 𝒃𝟐 coefficient
In the regression equation, 𝑏2 = 0.00041. What does this figure indicate? Consider the calculations in the
following table. The table shows that for 1 square-feet increase in size, from 𝑥0 = 2,000 to 𝑥1 = 2,001, the
house price is predicted to rise by 0.0004 or 0.04%.
𝑏1 = 10.8386
𝑏2 = 0.000411
̂
ln
(𝑦) =
𝑦̂ =
∆𝑥 = 𝑥1 − 𝑥0 =
∆𝑦̂ = 𝑦1 − 𝑦0 =
∆𝑦̂⁄𝑦̂0 =
∆𝑦̂% =
𝑥0
𝑥1
1
2,000
11.6611
115,975.5
1
2,001
11.6615
116,023.2
1
47.7
0.0004
0.04%
Slope of the regression function
To explain the slope of a log-linear function, consider the following diagram. Note that like a quadratic
function, the slope of the log-linear function is not constant. The slope is defined for each point on the
continuous graph as the first derivative evaluated for each 𝑥.
1200000
ŷ
1000000
Sales price ($)
800000
600000
247.14
400000
108.57
200000
47.70
0
0
1000
2000
3000
4000
5000
6000
7000
8000
Total square feel
̂
Here is how you find the first derivative of log-linear function ln
(𝑦) = 𝑏1 + 𝑏2 𝑥. First find the exponent of
both sides of the equation.
𝑦̂ = 𝑒 𝑏1+𝑏2 𝑥
3-Simple Regression Model
26 of 31
Then take the derivative of 𝑦̂ with respect to 𝑥.
𝑑𝑦̂
= 𝑏2 𝑒 𝑏1+𝑏2 𝑥 = 𝑏2 𝑦̂
𝑑𝑥
For example, when 𝑥 = 2,000 𝑆𝑄𝐹𝑇, the slope is 𝑑𝑦̂⁄𝑑𝑥 = 0.00041 × 115,975.5 = 47.70. This slope figure
implies that when the house size is 2,000 𝑆𝑄𝐹𝑇, for each additional square-feet the house price rises by
$47.70. Or, we can also say that for a house with a predicted price of, say, $100,000, the estimated increase in
price for an additional square foot is 𝑏2 𝑦̂ = 0.00041 × 100,000 = $41.00.
Elasticity
Let us start with the general definition of elasticity:
𝜀=
𝑑𝑦̂⁄𝑦̂ 𝑑𝑦̂ 𝑥
=
𝑑𝑥 ⁄𝑥 𝑑𝑥 𝑦̂
Substituting for
𝜀 = 𝑏2 𝑦̂
𝑑𝑦̂
𝑑𝑥
= 𝑏2 𝑦̂ in the elasticity formula, we have:
𝑥
= 𝑏2 𝑥
𝑦̂
𝑥
2,000
4,000
6,000
̂
ln
(𝑦)
11.66
12.48
13.31
𝑦̂
115,975.47
263,991.38
600,915.40
𝑑𝑦̂⁄𝑑𝑥 = 𝑏2 𝑦̂
47.70
108.57
247.14
𝜀 = 𝑏2 𝑥
0.823
1.645
2.468
For example, when 𝑥 = 2,000 square feet, 𝜀 = 0.823 implies that the price is predicted to rise by 0.823% for a
1% increase in size.
2.3. Regression with Indicator (Dummy) Variables
An indicator variable is a binary variable which take on values of 0 or 1 only. This variable is used when it is
of qualitative characteristic: gender, race, or location. For example, the price of a house is significantly
related to the qualitative characteristic location. Two houses with the same size will have different prices
according to where each is located. In regression if the variable has the characteristic of interest, then it is
assigned a “1”, otherwise, a “0”. If the house is located in a specific location which we anticipate would impact
its price, then it is assigned 1, otherwise 0.
Example: Location Impact on the Price of Houses Located Near a University
The Excel file CH3 DATA.xlsx contains the UTOWN data in the tab “𝑢𝑡𝑜𝑤𝑛”. The data provides prices of 1,000
houses (𝑦 = 𝑃𝑅𝐼𝐶𝐸) according to their location, where 𝑥 = 𝑈𝑇𝑂𝑊𝑁 = 1 for house located near a major
university campus, and 𝑥 = 𝑈𝑇𝑂𝑊𝑁 = 0 for houses in other neighborhoods. The regression equation is,
̂ = 𝑏1 + 𝑏2 𝑈𝑇𝑂𝑊𝑁
𝑃𝑅𝐼𝐶𝐸
Using the regular regression formulas to estimate the coefficients, we have
̂ = 215.732 + 61.5091𝑈𝑇𝑂𝑊𝑁
𝑃𝑅𝐼𝐶𝐸
3-Simple Regression Model
27 of 31
The following table shows the impact of location on the price of a house. The estimated price of a house near
the university campus is $277,241, and that of house in other locations is $215,372. Note that the intercept
represents the estimated mean price of a house away from the campus. The slope 𝑏2 = 61.509 is the amount
added to the price of a house located near the campus: $215.372 + $61.509 = $277,241.
b₁ =
b₂ =
215.732
61.509
𝑃𝑅𝐼𝐶𝐸 =
𝛥𝑃𝑅𝐼𝐶𝐸 =
𝑥=0
1
0
215.732
𝑥=1
1
1
277.241
61.509
Also note that we can find the intercept, the sample mean price of non-university houses, and the sample
mean price of near-university houses, directly from the data.
𝑦̅𝑥=0 = 215.732
𝑦̅𝑥=1 = 277.241
Appendix
Variance of 𝒃𝟏
To determine the variance b1 we start with basic formula to compute the intercept coefficient of regression.
𝑏1 = 𝑦̅ − 𝑏2 𝑥̅
Substituting for 𝑦̅ and 𝑏2 , we have
1
∑(𝑥 − 𝑥)𝑦
𝑏1 = ∑ 𝑦 −
𝑥̅
𝑛
∑(𝑥 − 𝑥)2
1
𝑏1 = ∑ 𝑦 − ∑𝑤𝑦𝑥̅
𝑛
1
𝑏1 = ∑ ( − 𝑥̅ 𝑤) 𝑦
𝑛
1
𝑏1 = ∑ ( − 𝑥̅ 𝑤) (𝛽1 + 𝛽2 𝑥 + 𝑢)
𝑛
1
1
1
𝑏1 = ∑ ( 𝛽1 + 𝛽2 𝑥 + 𝑢 − 𝑥̅ 𝑤 𝛽1 − 𝑥̅ 𝑤 𝛽2 𝑥 − 𝑥̅ 𝑤𝑢)
𝑛
𝑛
𝑛
1
𝑏1 = 𝛽1 + 𝛽2 𝑥̅ + ∑𝑢 − 𝛽1 𝑥̅ ∑𝑤 − 𝛽2 𝑥̅ ∑𝑤𝑥 − 𝑥̅ ∑𝑤𝑢
𝑛
1
1
𝑏1 = 𝛽1 + ∑𝑢 − 𝑥̅ ∑𝑤𝑢 = 𝛽1 + ∑ ( − 𝑥̅ 𝑤) 𝑢
𝑛
𝑛
1
𝑏1 − 𝛽1 = ∑ ( − 𝑥̅ 𝑤) 𝑢
𝑛
3-Simple Regression Model
28 of 31
2
1
var(𝑏1 ) = E[(𝑏1 − 𝛽1 )2 ] = E {[∑ ( − 𝑥̅ 𝑤) 𝑢] }
𝑛
2
2
2
1
1
1
var(𝑏1 ) = E [( − 𝑥̅ 𝑤1 ) 𝑢12 + ( − 𝑥̅ 𝑤2 ) 𝑢22 + ⋯ + ( − 𝑥̅ 𝑤𝑛 ) 𝑢𝑛2 + ⋯ ]
𝑛
𝑛
𝑛
2
1
var(𝑏1 ) = ∑ ( − 𝑥̅ 𝑤1 ) 𝜎𝑢2
𝑛
Simplify the first term on the right hand side:
1
2
∑ ( − 𝑥̅ 𝑤1 ) = ∑ (
𝑛2
𝑛
1
2
∑ ( − 𝑥̅ 𝑤1 ) =
𝑛
1
2
∑ ( − 𝑥̅ 𝑤1 ) =
𝑛
var(𝑏1 ) =
1
1
𝑛
+
+𝑥
̅ 2 𝑤2 −
2
𝑛
𝑥
̅𝑤) =
1
𝑛
+𝑥
̅2 ∑𝑤2 −
2
𝑛
𝑥
̅∑𝑤
𝑥
̅2
∑(𝑥 − 𝑥̅)2
∑(𝑥 − 𝑥̅ )2 + 𝑛𝑥̅2
∑𝑥2
=
𝑛∑(𝑥 − 𝑥
̅)2
𝑛∑(𝑥 − 𝑥
̅ )2
∑𝑥 2
𝑛∑(𝑥 − 𝑥̅ )2
𝜎𝑢2
Covariance of 𝒃𝟏 and 𝒃𝟐
cov(𝑏1 , 𝑏2 ) =
−𝑥̅
∑(𝑥 − 𝑥̅ )2
𝜎𝑢2
It is a straightforward exercise to arrive at the above covariance formula from this definition by substituting
the terms used in deriving the var(𝑏1 ) and var(𝑏2 ).
1
𝑏1 − 𝛽1 = ∑ ( − 𝑥̅ 𝑤) 𝑢
𝑛
and
𝑏2 − 𝛽2 = ∑𝑤𝑢
in the above expectation operation
1
cov(𝑏1 , 𝑏2 ) = E {[∑ ( − 𝑥̅ 𝑤) 𝑢] (∑𝑤𝑢)}
𝑛
The covariance is:
cov(𝑏1 , 𝑏2 ) =
−𝑥̅
∑(𝑥 − 𝑥̅ )2
𝜎𝑢2
Proof of
E[var(𝑒)] = E (
∑𝑒 2
) = σ2𝑢
𝑛−2
Starting with the definition of the error term,
3-Simple Regression Model
29 of 31
𝑒 = 𝑦 − 𝑦̂ = 𝑦 − 𝑏1 − 𝑏2 𝑥
substitute for 𝑏1 = 𝑦̅ − 𝑏2 𝑥̅ .
𝑒 = 𝑦 − 𝑦̅ + 𝑏2 𝑥̅ − 𝑏2 𝑥
𝑒 = (𝑦 − 𝑦̅) − 𝑏2 (𝑥 − 𝑥̅ )
(1)
𝑦 = 𝛽1 + 𝛽2 𝑥 + 𝑢
(2)
Summing for all 𝑖, we have
∑𝑦 = 𝑛𝛽1 + 𝛽2 ∑𝑥 + ∑𝑢
Divide both sides of the equation by 𝑛,
𝑦̅ = 𝛽1 + 𝛽2 𝑥̅ + 𝑢̅
Subtracting from (2),
(𝑦 − 𝑦̅) = 𝛽2 (𝑥 − 𝑥̅ ) + (𝑢 − 𝑢̅ )
and substituting for (𝑦 − 𝑦̅) in (1):
𝑒 = 𝛽2 (𝑥 − 𝑥̅ ) + (𝑢 − 𝑢̅) − 𝑏2 (𝑥 − 𝑥̅ )
𝑒 = −(𝑥 − 𝑥̅ )(𝑏2 − 𝛽2 ) + (𝑢 − 𝑢̅)
Square both sides,
𝑒 2 = (𝑥 − 𝑥̅ )2 (𝑏2 − 𝛽2 )2 + (𝑢 − 𝑢̅)2 − 2(𝑥 − 𝑥̅ )(𝑏2 − 𝛽2 )(𝑢 − 𝑢̅)
and sum for all 𝑖:
∑𝑒2 = (𝑏2 − 𝛽2 )2 ∑(𝑥 − 𝑥̅ )2 + ∑(𝑢 − 𝑢̅ )2 − 2(𝑏2 − 𝛽2 )∑(𝑥 − 𝑥̅)(𝑢 − 𝑢̅ )
Find the expected value from both sides
E(∑𝑒2 ) = E[(𝑏2 − 𝛽2 )2 ∑(𝑥 − 𝑥̅)2 ] + E[∑(𝑢 − 𝑢̅ )2 ] − 2E[(𝑏2 − 𝛽2 )∑(𝑥 − 𝑥̅)(𝑢 − 𝑢̅ )]
Consider the three components of the RHS of the equation separately,
E[(𝑏2 − 𝛽2 )2 ∑(𝑥 − 𝑥̅ )2 ] = ∑(𝑥 − 𝑥̅ )2 E[(𝑏2 − 𝛽2 )2 ]
E[(𝑏2 − 𝛽2 )2 ∑(𝑥 − 𝑥̅ )2 ] = ∑(𝑥 − 𝑥̅ )2 var(𝑏2 )
E[(𝑏2 − 𝛽2 )2 ∑(𝑥 − 𝑥̅ )2 ] = σ2𝑢
E[∑(𝑢 − 𝑢̅)2 ] = E[∑(𝑢2 − 𝑢̅2 − 2𝑢𝑢̅)]
E[∑(𝑢 − 𝑢̅)2 ] = E[∑𝑢2 − 𝑛𝑢̅2 ]
1
E[∑(𝑢 − 𝑢̅)2 ] = E [∑𝑢2 − (∑𝑢)2 ]
𝑛
3-Simple Regression Model
30 of 31
1
E[∑(𝑢 − 𝑢̅)2 ] = ∑E(𝑢2 ) − ∑E(𝑢2 )
𝑛
E[∑(𝑢 − 𝑢̅)2 ] = 𝑛σ2𝑢 − σ2𝑢 = (𝑛 − 1)σ2𝑢
E[(𝑏2 − 𝛽2 )∑(𝑥 − 𝑥̅ )(𝑢 − 𝑢̅)] = E[(𝑏2 − 𝛽2 )∑(𝑥 − 𝑥̅ )𝑢]
Note: ∑(𝑥 − 𝑥
̅ )(𝑢 − 𝑢̅ ) = ∑𝑢(𝑥 − 𝑥̅) − 𝑢̅ ∑(𝑥 − 𝑥̅ ) = ∑(𝑥 − 𝑥̅ )𝑢
Substituting for
𝑏2 − 𝛽2 =
∑(𝑥 − 𝑥̅ )𝑢
∑(𝑥 − 𝑥̅ )2
on the right-hand-side,
E[(𝑏2 − 𝛽2 )∑(𝑥 − 𝑥̅ )𝑢] = E [
∑(𝑥 − 𝑥̅ )𝑢
∑(𝑥 − 𝑥̅ )𝑢]
∑(𝑥 − 𝑥̅ )2
E[(𝑏2 − 𝛽2 )∑(𝑥 − 𝑥̅ )𝑢] =
1
E[(∑(𝑥 − 𝑥̅ )𝑢)2 ]
∑(𝑥 − 𝑥̅ )2
E[(𝑏2 − 𝛽2 )∑(𝑥 − 𝑥̅ )𝑢] =
1
∑(𝑥 − 𝑥̅ )2 E(𝑢2 ) = σ2𝑢
∑(𝑥 − 𝑥̅ )2
Finally,
E(∑𝑒 2 ) = σ2𝑢 + (𝑛 − 1)σ2𝑢 − 2σ2𝑢 = (𝑛 − 2)σ2𝑢
E(
∑𝑒 2
𝑛−2
) = σ2𝑢
which proves that E[var(𝑒)] = σ2𝑢 . That is, var(𝑒) is an unbiased estimator of σ2𝑢 .
3-Simple Regression Model
31 of 31