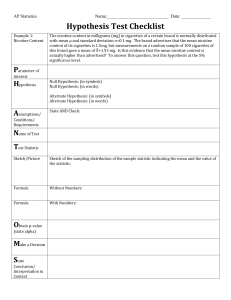
Sample Size Determination
One of the most frequent problems in the application of statistical theory to practical applications is the
determination of sample sizes for surveys and other empirical observations. This paper pulls together
various approaches to this problem from a typical text 1 on statistics for business, economics, and social
sciences in general.
Sample Size Based on Confidence Intervals
If it is desired to gain knowledge of the values of population parameters, a common practice is to perform
observations on a sample from the population. Then an estimate of each of the populations parameters
is calculated as a confidence interval within which the true value will lie for some proportion of all the
samples ever to be taken. For the population mean the upper bound of the confidence interval is given
by:
upperbound = x + z α2 / 2
Where
s
n
= x+e
x = sample mean
za/2 = value from the normal distribution for which a = 1 – C (confidence)
s = sample standard deviation
n = sample size
The term after the + sign is the half width of the interval and can be considered the error, e, with which the
mean is estimated. When x is subtracted from both sides of the equation the result can be solved for n
as follows:
n=
z α2 / 2 s 2
e2
To use this formula, business decisions for the confidence, C (from which a is calculated by C – 1), and
the allowable error, e, have to be made Obviously, both have a lot to do with the situation. Then a
conservative estimate for n should be made (the smaller the sample size the large ta/2, n-1 will be so a
conservative estimates will be small values of n). In addition s must be estimated. This can be done from
historically similar situations or a pilot sample.
n=
z α2 / 2 pq
e2
In this formula q = 1 – p. Since the object of using this formula is to find out what the sample proportion,
p, is it is necessary to estimate p from prior knowledge or a pilot survey, as with s above.
An underlying assumption for the use of these formulas is that the sample size will be less than 5% of the
population size, whose exact size is often not known but needs to be guessed. It can always be assumed
that the population is infinite, in which case the above formulas apply, but if it might be suspected that the
1
McClave, Benson, and Sincich (2007) Statistics for Business and Economics, 10th Edition,
Pearson/Prentice Hall
M Peter Jurkat
Document1
Page 1
2/8/2016
Sample Size Calculation…
above values of n could be greater than 5% then the sample size could be reduced by the correction
factor in the following section.
For two populations the same formulas apply except that the variance factor (second factor in numerator)
is the sum of the two populations variance. Thus for a test for difference in means
z α2 / 2 (σ12 + σ 22 ) z α2 / 2 (p1q1 + q 2 q 2 )
n1 = n 2 =
or
e2
e2
Correction for Finite Populations
The correction in this section needs to be applied when the sample size can be expected to be more than
5% of the population size. Here the population size is designated with an upper case N.
The finite population correction factor is
N n
(for some reason in the formula tool used here the
N 1
minus signs do not appear – the correction factor should be the square root of N minus n in the numerator
and N minus 1 in the denominator). This factor multiplies the sample standard deviation resulting in an
equation with n on both sides of the equal sign. When this equation is solved for n the result is
n=
n0N
n0 + N 1
where n0 is the samples size calculated for infinite populations from the previous section for both the
population mean and proportion (also the denominator is n0 plus N minus 1).
Sample Size Consideration when Sampling for Small Proportions
An additional consideration arises when samples are drawn to estimate small population proportions,
such as for epidemiologic and quality control studies. In both of these case (it is hoped) that the
proportions of diseased individuals and production/service failures are very small, sometimes as few as
one in hundreds of thousands. In this case samples must be large enough so that for each category
being samples at least 5 or 6 diseased individuals or failures are actually found.
Sample Size Calculation for Given Probabilities of Type I and Type II
Error
Section 6.6 of McClave et al2 discusses the probability of Type II errors in hypothesis testing for the mean
of a single population. The probability of making a Type II error is usually denoted by and 1 - is
referred to as the power of the test. However, the section does not extend the discussion to the most
common use of the power of a test, which is to calculate the sample size that will satisfy a predetermined
value of and . This paper provides an example of such calculations.
The situation is specified as follows:
H0: 2400 =
2
Ibid, p376-381
M Peter Jurkat
Document1
Page 2
2/8/2016
Sample Size Calculation…
Ha: > 2400
Significance level = .05, the probability of making a Type I error
Sample size is initially specified as n = 50 and the sample s.d. = 200. Let x denote a typical value of
the mean of such a sample.
The critical region are those values of x for which H0 will be rejected. It may be calculated as follows:
The significance level of .05 means the critical region for z, a normally distributed random variable is z >
1.654, since that region has probability 05.
x 0
x 2400
Corresponding values of x can be calculated by solving 1.645
for x . Thus
s
200
n
50
200
x 2400 1.645
2446 .53 With the critical region of x 2446.53 the probability of a Type I
50
error will be .05 no matter what the true value of the population mean really is.
The acceptance region is now x < 2446.53 no matter what the true value of the population mean really
is. However, the probability, , of this region is the probability of a Type II error will differ with various
values of the true mean. For instance, for the true alternate mean a = 2475 the probability of this region
2446 .53 2475
is P( x 2446 .53 ) P z
P(z 1.007 ) = .5 - P( 0 z 1.007) = .5 - .3413 = .1587.
200
50
This value differs somewhat from the one in the text due to differences of reading and extrapolating the
values of the normal probability table. This results in a power of about 1 - .1587 ~ .84 = 84%.
2446 .53 2475
that is not fixed at
200
50
this point in the development is the sample size n = 50. The upper boundary of the acceptance region,
2445.53, is fixed by the Type I error requirement of .05, the alternate true mean, 2475, is the minimum
value to be distinguished, and the estimated value of the population standard deviation, 200, is the only
estimate we have until other samples are taken.
Suppose a power of 90% is desired. The only value of the expression
For a 90% power the probability of falsely accepting the null hypothesis, H 0 2400, is = .1. The
corresponding value of z.1 is the solution of P( z z.1) = .1, which is z.1 = -1.23. Then the required
2446 .53 2475
sample size can be calculated by solving 1.28
for n which results in
200
n
1.28 200
n
8.99 9 Squaring yields n = 81.
2446 .53 2475
This development has illustrated how the concepts of Type I and Type II error are used to specify a
sample size for a survey. In general:
1. State a null and alternate hypothesis: e.g., H0: = 0 and Ha: 0
2. Select a level of significance, , which will be the probability of making a Type I error, rejecting
the null hypothesis when it is true.
3. Select an alternate population mean value, a, and a power level, 1 - . The alternate mean,
a, is to be distinguished with power 1 - , i.e., when the alternate a is the true mean the null
M Peter Jurkat
Document1
Page 3
2/8/2016
Sample Size Calculation…
hypothesis is to be rejected with probability 1 - . This is the same as making a Type II error,
accepting the hull when it is false, with probability .
4. Use historical data or perform a pilot survey (or guess) to estimate the population standard
deviation, s, and the sample size, n, of the historical data or the survey size..
5. Calculate the boundaries (one could be infinite) of the rejection region, xb. The acceptance
region is then its complement.
6. Calculate the probability of a Type II error, accepting a false null hypothesis, from the
acceptance region assuming the alternate population mean is the true mean.
7. If the probability of a Type II error is greater than b then calculate a larger sample size to be
used in the survey to test the null hypothesis.
This procedure, while correct, is complicated and really applies to only the one alternate mean value, a.
When it is repeated for other alternates the result is an operating characteristic curve. However, even this
does not provide easily applied recommendations for sample size.
Sample Size Estimation Based on Effect Size
An alternate approach to estimate sample sizes to control both Type I and Type II errors can be based on
estimated effect size. Effect size is defined as the difference between a sample statistic, such as the
mean, and the true value divided by the standard deviation. Effectively this is
effectSize =
x μ0
s
(where again there should be a minus sign between x and ). In practice the effect size is often
estimated by the largest difference realistically expected. Once an effect size has been estimated the
following table (Hair, Anderson, Tatham, Black (1998) Multivariate Data Analysis, p12) and graph can be
used to estimated a sample size which can satisfy controls on Type I and Type II errors.
Values of Power (1 - )
Alpha (α) = .05
Alpha (α) = .01
Effect Size (ES)
Effect Size (ES)
Sample size
Small (.2)
Moderate
(.5)
Small (.2)
Moderate(.5)
20
.095
.338
.025
.144
40
.143
.598
.045
.349
60
.192
.775
.067
.549
80
.242
.882
.092
.709
100
.290
.940
.120
.823
150
.411
.990
.201
.959
200
.516
.998
.284
.992
Here is the acceptable probability of a Type I error (reject the null hypothesis when it is true) and is
acceptable probability of a Type II error (accept a false null hypothesis). Typical values of = .05 and =
M Peter Jurkat
Document1
Page 4
2/8/2016
Sample Size Calculation…
.2 are often used unless there is a good reason not to. Power (the values in the above table) is 1 - ; the
previous recommendation results in a power value of .8 = 80%. So the above table recommends
samples sizes for 80 for = .05 and effect size of .5 and samples sizes considerably greater than 200 for
effect sizes of .2.
For = .01 a similar sample size of100 for moderate (.5) effect size and much larger than 200 for small
effect sizes.
A graph3 that shows the relationship between sample size, effect size, and Power is shown next for an
effect size between the small value (.2) and moderate value (.5).
3
Hair, Anderson, Tatham, Black (1998) Multivariate Data Analysis, p13
M Peter Jurkat
Document1
Page 5
2/8/2016