第頁共6頁 機器學習 期末考試 學號: 姓名: 100/6 是非題(14%) ( )1. In
 ( )1. In")
第 1 頁共 6 頁
機器學習
期末考試
學號: 姓名:
100/6
一、 是非題
(14%)
( )1. In semiparametric estimation, the density is written as a disjunction of a small number of parametric models.
( )2. A decision tree is a hierarchical model using a divided-and-conquer strategy.
( )3. To remove subtrees in a decision tree, postpruning is faster and prepruning is more accurate.
( )4. The impurity measure of a classification tree should be satisfies the following properties:
(1)
( 1 / 2 , 1 / 2 )
( p , 1
p ), for any p
[ 0 , 1 ] , (2)
( 0 , 1 )
( 1 , 0 )
0 , and (3)
( p , 1
p ) is increasing in p on [ 0 , 1 / 2 ] and decreasing in p on [ 1 / 2 , 1 ]
( )5. Rule induction works similar to tree induction except that rule induction does a breadth-first search, whereas tree induction goes depth-first.
( )6. When classes are Gaussian with a shared covariance matrix, the optimal discriminant is linear.
( )7. Support vector machines are likelihood-based methods.
( )8. In SIMD machines, all processors execute the same instruction but on different pieces of data.
( )9. Hints can be used to create virtual examples.
( )10.
A real-valued function f defined on an interval is called convex, if for any two points x and y in its domain C and any t in [0,1], we have f ( tx
( 1
t ) y )
tf ( x )
( 1
t ) f ( y ) .
( )11. Adaptive resonance theory (ART) neural networks are unsupervised learning.
( )12. In a multilayer perceptron, if the number of hidden units is less than the number of inputs, the first layer performs a dimensionality reduction.
( )13. The self-organizing map (SOM) is a winner-take-all neural network. It is as if one neuron wins and gets updated, and the others are not updated at all.
( )14. In a local representation, the input is encoded by the simultaneous activation of many hidden units such as Radial basis functions.
二、 簡答題
1.
(4%) What are the advantages and the disadvantages of the nonparametric density estimation?
1
2.
(1)(4%) What is the meanings of a leaf node and an internal node in a decision tree?
(2)(4%) How to decide to split a node in a decision tree? What are the split critira?
第 2 頁共 6 頁
3.
(4%) In a neural network, can we have more than one hidden layers? Why or why not?
4.
(4%) Why is a neural network overtraining (or overfitting)?
5.
(4%) (1) What are support vectors in support vector machine?
(2) Given an example as follows. Please show the supports vectors.
6.
(4%) What is the different between a likelihood-based method and a discriminant-based method?
2
第 3 頁共 6 頁
7.
(10%) Here shows the batch k -means algorithm and the online k -means algorithm, respectively.
(1) (4%) What are the differences between these two methods?
(2) (6%) What are their advantages and disadvantages?
8.
(4%) Condensed Nearest Neighbor algorithm is used to find a subset Z of X that is small and is accurate in classifying X . Please finish the following Condensed Nearest Neighbor algorithm.
3
第 4 頁共 6 頁
9.
(4%) In nonparametric regression, given a running mean smoother as follows, please finish the graph with h = 1.
t
N
1 t
N
1 b b
x , x r
t
where b
1
0 if x t is in the same bin with x otherwise
10.
(12%) Let d k
( x ) be the distance to the k -nearest sample, N the total sample number, and K is a kernel function.
K
1
2
exp
u
2
2
The following shows some density estimators, can you
(1) (4%) link the fomulars to their corresponding graphs, and
(2) (8%) calculate the values of k or h ?
1
Nh t
N
1
K
h x t
( x )
k
2 Nd k
( x )
#
x
h
x t
2 Nh
ˆ
#
x t in the same bin as x
Nh x
h
4
第 5 頁共 6 頁
11.
(4%) Given a regression tree as follows. Please draw its corresponding regression result.
12.
(6%) In a pairwise separation example as follows, and H ij
indicates the hyperplane separate the examples of C i and the examples of C j
Please decide each region belongs to which class. g ij
x w ij
, w ij 0
T w x ij
w ij 0 g ij
0 if x
C i
0 if x
C j don't care otherwise choose if j i g ij
0
13.
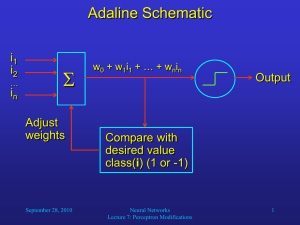
Given a perceptron as follows:
(1) (4%) What are the values of these weights if we use this perceptron to implement the AND gate?
(2) (4%) Why can’t a perceptron learn the Boolean function XOR?
5
三、計算證明題
1.
(10%) Given a backpropogation neural network, where y i
T v z i
h
H
1 v z
v ih h i 0
, z h
sigmoid
d j
1
1 w x hj j
w h 0
.
If the learning factor is
and the error function is defined as
E
W
, |
X
1 r t y t
2
2 t
Please find the weight update rules
v and
h w hj where
E
w hj
E y i
z h i z w h hj
.
,
ANS:
第 6 頁共 6 頁
6