version: b - Cloudfront.net
advertisement

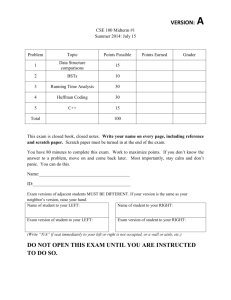
VERSION:
B
CSE 100 Midterm #1
Summer 2014: July 15
Problem
Topic
Points Possible
1
Data Structure
comparisons
15
2
BSTs
10
3
Running Time Analysis
30
4
Huffman Coding
30
5
C++
15
Total
Points Earned
Grader
100
This exam is closed book, closed notes. Write your name on every page, including reference
and scratch paper. Scratch paper must be turned in at the end of the exam.
You have 80 minutes to complete this exam. Work to maximize points. If you don’t know the
answer to a problem, move on and come back later. Most importantly, stay calm and don’t
panic. You can do this.
Name:________________________________________
ID:___________________________________________
Exam versions of adjacent students MUST BE DIFFERENT. If your version is the same as your
neighbor’s version, raise your hand.
Name of student to your LEFT:
Name of student to your RIGHT:
Exam version of student to your LEFT:
Exam version of student to your RIGHT:
(Write “N/A” if seat immediately to your left or right is not occupied, or a wall or aisle, etc.)
DO NOT OPEN THIS EXAM UNTIL YOU ARE INSTRUCTED
TO DO SO.
2
Name__________________________________
1. Data Structure Comparisons [15 points]
Assume you have the choice of the following data structures: sorted arrays, sorted linked list, unsorted
linked list, binary search tree and heap.
Choose the appropriate data structure if your algorithm repeatedly performs each of the following
functions. Briefly justify your answer.
a. Searches for elements in a static data set (insertions and deletions are rare).
Use sorted array or binary search tree.
Reason: Both sorted array and binary search tree has time O(log n) for searching for elements, while
sorted linked list, unsorted linked list and heap has time O(n) for searching. Because insertions and
deletions are rare in static data set, we don’t need to consider the running time of insertion and deletion.
b. Searches for elements in a dynamic data set (insertions and deletions are frequent).
Use binary search tree.
Reason: Both sorted array and binary search tree have time O(log n) for searching for elements, while
sorted linked list, unsorted linked list and heap have time O(n) for searching. When we do search for
elements in a dynamic data set, it’s better to choose binary search tree rather than sorted array
because the running time of insertions and deletions of BST is O(1), which is much faster than sorted
array(O(n)).
c. Extracts the element with the minimum key value.
Choose sorted linked list.
Reason: The running time of extracting the element with the minimum key value of sorted linked list
is O(1), which is much faster than others.
Name________________________________________
2. Binary Search Trees [10 points]
3
For each of the following, state whether or not they are legal Binary Search Tree (BST). If the tree is not a
legal BST, state why not, annotating the tree where appropriate. For all the given trees, indicate if they
are balanced or not. Justify your answer
52
52
A.
B.
12
30
75
30
12
35
a) Is tree (A) a legal BST (circle one)? Yes
If not, why not?
No
[3 points]
b) Is tree (A) Balanced (circle one)?
Justify your answer.
No
[2 points]
Yes
The balance factor of all the nodes in tree A is not smaller than -1 or greater than 1.
The tree cannot be rearranged to have a smaller height.
c) Is tree (B) a legal BST (circle one)?
If not, why not?
Yes
No
[2 points]
For any node in BST, every element in its left subtree should be smaller than the node, and every element
in the right subtree should be greater than the node. Considering the node with 32, its right child is 12,
which is greater than it. So it’s not a legal BST.
b) Is tree (B) Balanced (circle one)?
Justify your answer.
Yes
No
[3 points]
The balance factor of the node with 52 is greater than 1. Currently, tree height is 3. The tree can be
rearranged to have height = 2.
Name________________________________________
3. Running Time Analysis [30 points]
4
a. Write the most general equation for the average number of comparisons needed to find an
element in a particular binary search tree with N nodes, where 𝑑(𝑥𝑖 ) is the depth of node 𝑥𝑖 in
the tree and 𝑝𝑖 is the probability of searching for node 𝑥𝑖 . [3 points]
Note: some students wrote ∑𝑁
𝑖=1 𝑝𝑖 𝑑(𝑥𝑖 ) =
1 𝑁
∑ 𝑑(𝑥𝑖 )
𝑁 𝑖=1
This assumption (pi=1/N) was made in lecture notes, but here, you are asked for the most
general equation. If you just wrote the right hand side, this is incorrect, since it is not most
general.
b. Which of the following assumptions did you rely on in writing the above equation? [2 points]
i. The tree is approximately balanced.
ii. All nodes in the tree are equally likely to be searched for
iii. All orders of insertions are equally likely to occur
iv. All priorities are drawn from a uniform probability distribution
v. None of the above
No assumptions were made here. If you wrote the equation above and choose ii) as
the answer, you received full credit. That was not what the question was asking,
however.
c. Construct all possible binary search trees with the keys 2, 5, 7, 9 under the restriction that the
second key inserted into the tree has to be even. [10 points]
5
Name________________________________________
d. Compute the average total depth over all trees that can be constructed with the keys
(2, 5, 7, 9, 15) under the restriction that the first key inserted into the tree is even. You are
given the following recursive relationship:
6
N*D(N)=(N+1)*D(N-1)+2N-1, where D(N) is the expected total depth of all trees with N
keys, under the assumption that all keys are equally likely to be inserted into the tree.
[15points]
The tree should be like:
2
s
The right subtree contains 5,7,9,15.
D(2) = 1+2 = 3;
D(3) = 17/3;
D(4) = 53/6;
When we combine it with the root 2,
The total depth is:
53/6 + 4 + 1 = 83/6
7
Name________________________________________
4. Huffman coding [30 points]
i)
Which of the binary trees is a better encoding scheme over the symbols {h, u, f, m, a, n}
if all symbols had a non-zero frequency? Justify your answer. [5 points]
A.
B.
m
h
u
f
a
B is better
n
h
u
f
m
a
n
B is prefix free.
8
Name________________________________________
ii) Consider the following symbols with the given frequency distribution:
Symbol
Frequency
Code (see part a)
H
0.15
0000
Frequency that would yield a
worse lower bound on expected
codeword length (See part c)
0.167
U
0.2
01
0.167
F
0.2
001
0.167
M
0.4
1
0.167
A
0.01
00011
0.167
N
0.04
00010
0.165
a. Draw the Huffman code tree below using the following conventions, and then use that tree to
fill in the code table above: [15 points]
The subtree with the lower frequency is always the right child when two trees are merged
The left child is always the 0 child, the right child is always the 1 child
Ties are broken using alphabetical ordering. In the case of a tie in frequency between two
trees, the tree with the symbol that is earlier in the alphabet is the tree that is picked first to be
merged. E.g., if trees with the symbols A and E had the same frequency, then the tree with A
would be picked first.
When merging two trees, the symbol that is alphabetically earlier is propagated up to the new
root. If the trees have the same frequency, the tree with symbol earlier in the alphabet is as
the left child of the root.
9
10
Name________________________________________
b. Using your tree, encode the following string. If you find extra bits at the end of the string just
ignore them. [5 points]
HUFFMAN =
_______00000100100110001100010___________________________________________
c. What is the average code length of your Huffman code? [5 points]
4*0.15+2*0.2+3*0.2+1*0.4+5*0.01+5*0.04=2.25
d. Fill in the final column table above with a frequency distribution which would lead to a worse
theoretical minimum expected length per coded symbol (i.e., has a higher entropy) than the
current frequency distribution. Hint: The theoretical minimum expected length per coded symbol
was referred to as Lave in your book and in class, but you don’t necessarily need to remember the
exact formula to get the right answer here. [5 points]
Can have different correct answers
5. C++ Concepts [15 points]
a. Consider the following implementation of a node in the Huffman Tree
#ifndef HCNODE_HPP
#define HCNODE_HPP
class HCNode {
public:
HCNode* parent; // pointer to
HCNode* child0; // pointer to
HCNode* child1; // pointer to
unsigned char symb; // symbol
int count; // count/frequency
parent; null if root
"0" child; null if leaf
"1" child; null if leaf
of symbols in subtree
bool operator<(HCNode const &) const;
};
#endif
11
Name________________________________________
bool HCNode::operator<(HCNode const & other) const {
if(count != other.count)
return count > other.count;
return symb < other.symb;
};
Now condsider following code snippet:
HCNode n1, n2, n3, n4;
n1.count = 100; n1.symb = ’A’;
n2.count = 200; n2.symb = ’B’;
n3.count = 100; n3.symb = ’C’;
For the above code snippet, what do each of the expressions given below evaluate to. Choose
TRUE or FALSE: [4 points]
i)
n1 < n2 FALSE
ii)
n3 < n1 FALSE
II) Explain why the less than operator was overloaded in the HCNode class [1 point]
Because we need to compare two objects of HCNode, and it isn’t defined in stdlib.
12
Name________________________________________
b. Show the contents of the array ‘a’ before and after line 4 of the given code is executed.
[10 points]
int a[5]={0,1,2,3,4}; //line 1
int* p = a+2; // line 2
int &ra = *(p+1); //line 3
ra = 5; //line 4
p = a;
before: 0 1 2 3 4
after: 0 1 2 5 4
13