JMP - Purdue University
advertisement

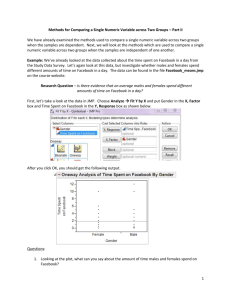
JMP Statistical Software Package JMP was developed by SAS Institute Inc. to be used as a user-friendly interactive statistical package. It is used to allow users with to effectively explore their data with minimal statistics knowledge and training. The JMP statistical package really focuses on data visuals with graphical representation. It is considered a menu point and click pull-down interface and is quite easy to work with. Some of the menu bar options can be seen below in Figure 1. Figure 1.Menu picture from the “Introduction of Statistics” website. The following report on JMP is meant to overview some of the key highlights provided in the JMP package. The methods may differ depending on which version you may be using and it only discusses some of the basic Statistical Techniques. It should be used as a briefing of some of the many capabilities of JMP, but not as a sole source. We will focus on four basic areas involved in Statistical Analysis: Data Set-up, Data Summary, Graphics, and Basic Regression. A more detailed explanation of the following features can be found in the resources provided in the References Section. Creating, Importing, Saving, and Manipulating Data Before you can conduct analysis you must first provide JMP with a dataset using the data table window. This will be the main window used throughout your analysis. There are several ways to provide data. You can import it (i.e. text file, jmp file, excel) or create your own from an empty table. Once you have the data entered in, you must then classify each variable into one of three categories: continuous, nominal, ordinal. This can be done by clicking the column Headers of each variable and selecting Column Info. Here you can assign the different categories. Classify variables continuous (right aligned in the data window) if they are to be analyzed as numeric measurements and Ordinal or Nominal (left aligned in the data window) for Categorical measures. Specify them ordinal if you have ordered categories of either numeric or some type of character values and nominal if they are either numeric or character classifications. After classifying your variables as either numeric or categorical you can also choose to specify whether they are predictor or response variables. This does not have to be done at the beginning you could always do it when you are building your regression model. This is also the point that you are able to name your different variables by clicking and typing in the column headers of each variable. The data table window also allows you to transform (create new) variables using the JMP formula editor. In this feature you are able to create new columns of variables like logs, quadratics, etc. From the data table window you can also combine, sort, edit, add, rearrange, and delete values, columns, and rows as well as conduct various other manipulations of the data. In addition to these features it also provides you with an option to create a subset of your data to conduct analysis on or just save for later. If your data is not formatted correctly, you can utilize the options in the data table window to reformat it into the correct form. Any missing values in the data are usually denoted as a dot. Specific data points/variables can also be individually excluded or included in your data analysis/graphics without having to continuously delete and add them using the Exclude/Unexclude command or Hide/Unhide command. Once you have achieved the data format required you can easily save your data by just clicking save from the File menu option. In the analysis of your data JMP will provide several outputs/reports of your analysis, you can save these and append additional reports on to the current one using the Journal Window screen. 1 Summarizing Data with Continuous and Categorical Variable Analysis Once your data is formatted, you can get a brief understanding of your data using numeric and/or graphical visuals. JMP allows you to create graphical visuals such as charts, boxplots, histograms, and even scatterplots. For categorical variables, JMP will create bar charts and frequency tables. For a quantitative variable it will generate histograms, stem and leaf plots, and information about the measures of central tendency, quantiles, and standard deviation. Looking at a categorical variable, to create a barplot you must first order your values so that they will properly appear in the chart. Next you can use the Chart command in the Graph menu options. In the dialog box you must specify which variables you wish to graph (selecting from the variables you classified as continuous) and how to group them (selecting from the variables you classified as categorical). After selecting what you would like plotted you also are able to label axes, specify an axis scale, provide a plot title, and add footnotes on the plot. You are not just limited to creating a barplot, you could always select some of the various other charts listed as well. To get an idea of just the general data distribution you can select the Distribution command and then identify what variable to group by and what variable serves as the counts. This will display a screen that contains a normal bar chart, a stacked bar chart, and a frequency table. An example is shown below in Figure 2. Figure 2. JMP output from the Distribution Figure 3. JMP output from the Distribution command for a categorical variable. Image from command for a continuous variable. Image from the “Introduction of Statistics” website. the “Introduction of Statistics” website. If you don’t like the bar chart horizontally you can easily point and click the right triangle to make it vertical. When looking at quantitative variables we must group together the variable values to 2 have a look at the overall distribution. Once you have done this you can easily make a histogram as previously mentioned. In the dialog box displayed you only need to specify a Y variable. When the final report shows instead of frequencies it will have quantiles and moments information. The graphics will display both a histogram and a boxplot. This can be shown in Figure 3 above. Again if you wish to view the histogram and box plot vertically it can easily be done as previously mentioned. With the histograms you can also adjust the number of bars through the Tools menu command. As mentioned, stem and leaf plots can be made by clicking the red triangle and selecting that option. It will be attached to the original output. Other plots such as time and line plots can also be made using the options in the Chart command. To get some other more detailed numerical visuals you could click the right triangle and select the More Moments command in the Display options. This command will provide you with other detailed things such as variance, skewness, etc. If you don’t like the boxplot displayed above the histogram you can generate a normal boxplot by selecting the Quantile Box Plot command in the Display options. After looking at some of the summary statistics for the data we can look at some other types of analysis as well for both or continuous and categorical data. When analyzing our variables we can also perform a one or two Sample t-Test. This can be done by selecting the red triangle in the output from the Distribution command and selecting the Test the Mean option. A dialog box will pop up asking you to specify the null hypothesis and then it will generate the results of the t-test. Using the information provided from the Distribution command you can also create a qq-Plot by selecting the Normal Quantile Plot in the options provided by the output. In conjunction with running the tests about the Distribution, you can also determine the sample size and power necessary for your analysis. This can be done using the Sample Size and Power command in the DOE menu options. After selecting one of the cases/situations you would like to use, a dialog box will prompt you to enter in basic information such as: the significance level, population standard deviation, population mean, and then either the power or sample size (whichever you don’t enter it will give the other). From this information it will generate a Power vs. Sample Size graph. Polynomial Regression and Diagnostics Simple Case one X and one Y After an initial look at the data has been done we are usually interested in finding some type of model fit for the data. JMP allows several ways to analyze the data. The first step to finding an appropriate relationship is to launch the Fit Y by X command in the Analyze menu option. In this command you will be prompted to specify which values you are interested in plotting as your X and Y variables. It will then create scatterplots for these variables, given that X and Y are both continuous numeric values. To generate and regress a linear model on your data, from the red triangle you can select the Fit a Line command. Or to do a Polynomial fit you can easily select the Fit Polynomial command and specify which degree order you want in the dialog box. For a transformation you can select the Fit Special command and choose a transformation for X and/or Y from what is listed. If the transformation or polynomial fit that you want is not listed you could always create it in the data table using the formula editor as previously mentioned and select the new variable directly from there. For each fit you select JMP will not only add it to the scatterplot but also create 3 tables with summary information concerning the fit. The first table is the Summary of Fit table. This table provides information summarizing the fit. It includes the actual regression equation, Rsquare, Root Mean Square Error, and the Mean of the values. The second table called the Analysis of Variable Table will provide 3 standard information about how well the model fits the data points. It provides standard ANOVA table information such as p-values, the F-test, degrees of freedom, and the values for both the Sums and Mean of Squares. The last table is the Parameter Estimates table. This table gives information about the estimates, estimate standard errors, and p-values. If there are points on the graph that are of interest you can choose to mark, exclude, or include them directly from the plot by clicking on them. When plotting with multiple fits all at once you can easily remove a particular fit by clicking the red triangle to the left of it and selecting that option. One other thing that may also be of great interest is the use of a smoothing spline on the chart. You can do this by selecting the Fit Spline command and selecting a lambda to fit the spline. It will automatically be added to the graph. Multivariate Regression When dealing with multiple X variables, analysis is done similarly to that as mentioned above. However instead of using the Fit X by Y command we use the Fit Model command in the Analyze menu options. Here we are able to select a Y and multiple X variables. If you are interested in testing interactions this can be done by selecting the variables you want to interact and then selecting the Factorial to Degree command from the Macros command in the Fit Model menu option. If you are only interested in interacting two variables you can do this by selecting them and then clicking the Cross button while still in the Fit Model command dialog box. When a multivariate analysis is done we get similar results as before, but we also get some new options. The Correlation Matrix will appear by default. To see the Covariance matrix you can click on the red triangle in the resulting output and request it. And to get a scatterplot matrix you may also request this using the red triangle in the output. To include a nested or random effect in your model you can do specifically specify it in the Fit Model command dialog box. For nested you would use the Nest command and for a random effect you would specify this with the Attributes command. In both simple linear and multivariate regression JMP, given you request it by right clicking on the Parameter estimate box, provides with you various diagnostics such as: residuals, predicted values, confidence intervals, cook’s distance, leverage values, and even variance inflation factors. It also provides plots for a numerous selection of these values. JMP also allows you to use Chi-squared testing to check you model. To investigate a non-linear relationship of an Experimental Design you can also utilize the Nonlinear Design command in the DOE menu options. This function will seek the optimal design for a nonlinear parameter model. In general when looking at an Experimental Design the DOE menu option should definitely be explored in depth, it offers various features to assist in an adequate analysis. Graphical Representation JMP is definitely known especially for its’ graphical interface. It definitely outputs user-friendly, easy to read, and completely publishable formatted graphics as well as numeric results. Figure 3 and 4 following show some examples of numerical and graphical results reported from the JMP output. Overall we find that JMP provides sufficient graphics for data interpretation. Other Notes about JMP Other highlights to be noted about JMP is that it allows you to run Stepwise Regression. You can do this in the Fit Model command dialog box by changing the Personality option to “Stepwise.” Then you are able to enter all of the X variables to be considered, including desired interactions and functional forms. Once the Stepwise dialog box pops up you need to change the Direction box to “Mixed” and enter probabilities for the variable entry and removal box. After it selects an appropriate model you can view it by selecting the Make Model command. You can also perform logistic regression in JMP. For this you first need to select a binary Y variable using the Fit Model command if you have multivariate regression or either the Fit Y by X for a simple linear regression. From the output of the command you 4 would select the red triangle to select options, if required, for your regression. Using the Fit Model command you can also perform various other analyses like: Factorial and Response Surface Analysis. With Factorial Analysis you can generate leverage plots to investigate interactions and main effects. Principal component analysis (PCA) can also be done using the Multivariate Methods command in the Analyze menu options. In the PCA dialog box able to select each of the variables you wish to analyze. Overall, JMP appears to be user-friendly, easy to use, and adequate when it comes to Statistical analysis. Figure 3. Images from the “JMP Introductory Guide” of JMP numerical analysis output. Figure 4. Images from the “JMP Introductory Guide” of JMP graphical visuals. 5 References 1. Ramirez, Ph D Jose G, and Brenda S. Ramírez. "Analyzing and Interpreting ... - Google Books." Google Books. N.p., n.d. Web. 30 Apr. 2010. <http://books.google.com/books?id=H8YiTo8gNU8C&pg=PA326&lpg=PA326&dq=how+to+calcu late+sample+size+in+jmp&source=bl&ots=eJiiyNPCoJ&sig=iKK4XJzm5dCCQMJM83bPx0TCmI0& hl=en&ei=pr_dS8OsMoze9ASEt4WiBw&sa=X&oi=book_result&ct=result&resnum=4&ved=0CB0 Q6AEwAw#v=onepage&q=how%20to%20calculate%20sample%20size%20in%20jmp&f=false>. 2. Moore, David, and George McCabe. "Introduction To The Practice Of Statistics, Fourth Edition." default. N.p., n.d. Web. 30 Apr. 2010. <http://bcs.whfreeman.com/iphttp://www.bibme.org/s4e/default.asp?s=&n=&i=&v=&o=&ns=0 &t=&uid=0&rau=0>. 3. Mauromoustakos, Andy. "Getting Familiar with JMP." University of Arkansas. N.p., n.d. Web. 30 Apr. 2010. <www.uark.edu/misc/.../Getting%20Familiar%20with%20JMP%208.ppt >. 4. "Introductory Guide Second Edition to JMP 8.0." JMP Software - Data Analysis - Statistics - Six Sigma - DOE. N.p., n.d. Web. 30 Apr. 2010. <http://www.jmp.com/support/downloads/pdf/jmp8/jmp_introductory_guide.pdf>. 5. Fricker, Ronald. "JMP Notes." Naval Postgraduate School. N.p., n.d. Web. 30 Apr. 2010. <faculty.nps.edu/rdfricke/Business_Stats/JMP%20Handout.pdf>. 6