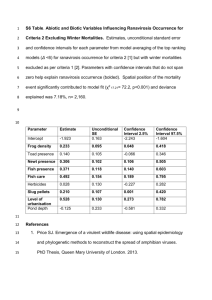
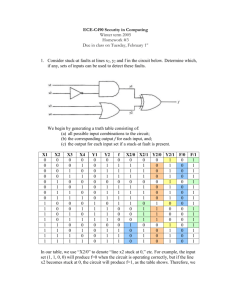
Chapter7 Finite State Machines
advertisement

Information
Information
1. Suppose we were told that a die was rolled and the
outcome was 4. Clearly, we were given all the
information concerning the outcome of the experiment.
1/6, – lg (1/6) = lg 6 = 2.585
2. If we were told that the outcome was red, we would agree
that we were given some information but not as much.
(two possibilities)
2/6, – lg (2/6) = lg 3 = 1.585
3. On the other hand, if we were told that the outcome was
black, we would feel that we were given some
information but even less. (four possibilities)
4/6, – lg (4/6) = lg 3 = 0.585
It is desirable to measure quantitatively how much
information a certain piece of message carries.
1. If a statement tells us the occurrence of a certain event that
is likely to happen, we would say that the statement
contains a small amount of information.
2. On the other hand, if a statement tells us the occurrence of
a certain event that is not likely to happen, we would say
that the statement contains a large amount of information.
The information contained in a statement asserting the
occurrence of an event depends on the probability p, of
occurrence of the event.
I(A) = - lg p(A)
The smaller the value of p, the larger the quantity – lg p.
The unit of the above information quantity is refered as a
bit, since it is the amount of information carried by one
(equally likely) binary digit.
1
Mutual Information
I(A, B): The amount of information concerning the
occurrence of event A that is contained in the statement
concerning the occurrence of event B.
Suppose we were told that the outcome of rolling a die
was red. How much does that help us to determine that the
outcome is a 4?
1. – lg p(A): is the amount of information contained in a
statement concerning the occurrence of event A and
2. – lg p(A|B): is the amount of information contained in a
statement concerning the occurrence of event A given that
B has occurred.
3. Thus, the information provided by the occurrence of event
B on the occurrence of event A is
I(A, B) = [- lg p(A)] - [- lg p(A|B)] = - lg p(A) + lg p(A|B)
Let A be the event that 4 appeared and B be the event that
red appeared. Then
I(A, B) = - lg p(A) + lg p(A|B) = - lg (1/6) + lg (1/2)
= 1.585 bits
3. If p (A|B) is large, it means that the occurrence of B
indicates a strong possibility of the occurrence of A.
Consequently, I(A, B) is large.
Two extreme cases:
1. B is a subset of A, p(AB) = p(B): p(A|B) =
p(A|B)/p(B) = 1 and –lg p(A|B) = 0, Mutual
information = Original information.
2. B is the whole sample space, p(AB) = p(A): –lg
p(A|B) = –lg p(A), I(A|B) = 0. In this case, the
occurrence of B tells us nothing about the occurrence
of A.
2
Entropy
If we have a set of independent events Ai, which are sets of
outcomes of some experiment S, such that Ai = S, where S
is the sample space, then the average self-information
associated with the random experiment is given by
H = p(Ai)I(Ai) = p(Ai)lg p(Ai).
[Shannon] If the experiment is a source that puts out symbols
Ai from a set Α, then the entropy is a measure of the average
number of binary symbols needed to code the output of the
source.
[Shannon] Shannon showed that the best that a lossless
compression scheme can do is to encode the output of a
source with an average number of bits equal to the entropy of
the source.
Coding
Coding: The assignment of binary sequences to elements of
an alphabet. The set of binary sequences is called a code, and
the individual members of the set are called codewords.
The average number of bits per sample is often called the
rate of the code.
entropy code: One might wish to represent more frequently
used letters with shorter sequences and less frequently used
codes with longer sequences so that the overall length of the
string will be reduced.
Uniquely decodable code: A code should have the ability to
transfer information in an unambiguous manner. Any given
sequence of codewords can be decoded in one, and only one,
way.
prefix code : A set of codewords is said to be a prefix code if
no codeword in the set is a prefix of another codeword in the
set.
Theorem [Kraft-McMillan]. Let C be a code with N
codewords with lengths l1, l2, …, lN. If C is uniquely
decodable, then
3
N
K ( C ) 2 l i 1.
i 1
Proof. The proof works by looking the nth power of K(C). If it
is greater than one, then K(C)n grows exponentially with n. If
not, then this is the proof.
Let n be an arbitrary integer. Then
N li N li N li
[ 2 ] 2 2 ... 2
i 1
i 1
i 1
i 1
N
li n
N
N
N
... 2
i1 11 i2 1
-( li1 li2 ... lin )
.
in 1
If l = max{l1, l2, …, lN.}, then the exponent is bounded by n and
nl. Therefore
nl
K (C ) Ak 2 k .
n
k n
Where Ak is # of combinations of n codewords that have a
combined length of k. Because Ak 2k, we have
nl
K (C ) Ak 2
n
k
k n
nl
2 k 2 k nl n 1.
k n
But if K(C) is greater than one, it will grow exponentially with n,
while n(l – 1) + 1 can only grow linearly. We have the proof.
Theorem. Given a set of integers l1, l2, …, lN satisfy the
inequality
N
2
li
1.
i 1
We can always find a prefix code with codeword length l1,
l2, …, lN.
4
Chains and Antichains
Let (X, ) be a partially ordered set. A subset of A is called a
chain if every two elements in the subset are related
(comparable). A subset of A is called an antichain if no two
distinct elements in the subset are related.
A element a in A is called a maximal element if for no b in A,
a b, a b. A element a in A is called a minimal element if
for no b in A, a b, b a.
Theorem 4.1 (Dilworth [1950]). Let (X, ) be a partially
ordered set. Suppose the length of the longest chains in P is n.
Then the elements in P can be partitioned into n disjoint
antichains.
Proof. By induction on n.
Basis: n = 1.
Induction step: Assume the theorem holds for n – 1.
Let M denote the set of maximal elements in P. Clearly, M
is a nonempty antichain.
Consider (P – M, ). length(the longest chains in P – M)
n –1.
length(the longest chains in P – M) < n –1: impossible
By induction hypothesis, P – M can be partitioned into n –
1 disjoint antichains.
Thus, P can be partitioned into n disjoint antichains.
Corollary 4.1.1. Let (X, ) be a partially ordered set consisting
of mn + 1 elements. Either there is an antichain consisting of m
+ 1 elements or there is a chain of length n + 1 in P.
5
Functions and The Pigeonhole Principle
A binary relation f from A to B is said to be a function
if for every element a in A, there is a unique element b
in B so that (a, b) is in f.
f(a) = b, image of a
Domain, Range
Onto (surjection): f(A) = B
One-to-one (injection): f(a) f(b) if a b
Bijection: one-to-one and onto
Pigeonhole principle
Let D and R be finite sets. If |D| > |R|, then for any function f
from D to R, there exists d1, d2 D such that f(d1) = f(d2).
An example: In a sequence of n2 + 1 distinct integers, there
is either an increasing subsequence of length n + 1 or a
decreasing subsequence of length n + 1.
Let
a1 , a2 , ..., an 2 1
‧
‧
‧
‧
denote the sequence of integers. Let us label the integer ak
with an ordered pair (xk, yk), where xk is the length of a
longest increasing sequence starting at ak, where yk is the
length of a longest decreasing sequence starting at ak.
Suppose there is no increasing sequence or decreasing
sequence of length n + 1 in the sequence.
That is, the values of xk, and yk lie between 1 and n for k = 1,
2, …, n2 + 1.
With only n2 distinct ordered pairs as possible labels for the
n2 + 1 integers, there must exist ai and aj in the sequence that
are labeled with the same ordered pair.
However, this is impossible because if ai < aj, there must
have xi > xj; and if ai > aj, there must have yi > yj.
6