Chapter 13: Regression Overview Regression is a very powerful
advertisement

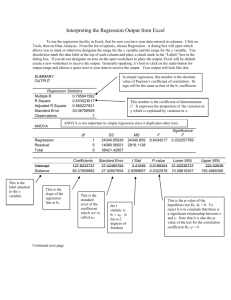
Chapter 13: Regression I. Overview a. Regression is a very powerful statistical technique that allows researchers to examine how two or more continuous (i.e., intervally scaled) variables are associated with each other. b. Regression is based on the strength and direction of the correlations among these variables. c. In a regression analysis, there is one dependent variable and one or more independent variables, often called predictor variables. d. Regression can be used to predict a value for the dependent variable for any value of the independent (i.e., predictor) variable(s). It can also be used to tell you how of the variance in the dependent variable is explained by the predictor variable(s). e. There are many kinds of regression techniques. In this chapter, we focus on simple linear regression with two variables and a brief introduction to multiple linear regression. II. Simple Linear Regression a. Purpose: To examine the strength of the association between two intervally scaled variables and to determine how much of the variance in the dependent variable is explained by the independent, predictor variable. b. How it works i. Regression uses the correlation coefficient between two variables, the means of those variables, and the standard deviations of those variables to produce an intercept and a slope for a regression line. 1. The intercept is the point where the regression line intersects the Y axis. a. The Y axis contains the scale for the dependent variable b. The intercept represents the predicted value of Y (the dependent variable) when the value of X (the independent variable) is 0. 2. The slope of the regression line is determined by calculating how much the value of the dependent variable (Y) is expected to change for each unit of change in the independent variable (X). a. The value of Y would be expected to increase with each increase in X if the two variables are positively correlated and to decrease if the two variables are negatively correlated. 3. The intercept has the symbol a and the slope, also known as the regression coefficient, has the symbol b. ii. Using the slope and the intercept, you can find a predicted value for Y, the dependent variable, for any value of X, the independent variable. iii. The percentage of variance in Y that is explained by X depends on the strength of the correlation coefficient. 1. For a simple linear regression with two variables, this value (R2) is simply the correlation coefficient squared (i.e., the coefficient of determination). iv. The line of Ordinary Least Squares (OLS) 1. Although regression allows you to predict values of Y for any given value of X, these predicted values of Y will not always be accurate. a. The accuracy of the predicted values depends on how strongly the two variables are correlated and how large the standard deviations of the two variables are. 2. III. Multiple Regression IV. Summary a. Distributions of data are not always normally distributed. b. There are several nonparametric statistics researchers can use when their data are not normally distributed. c. One of these is the chi-square test of independence (χ2). i. This statistic is used to determine whether expected frequencies differ from observed frequencies on two categorical variables.