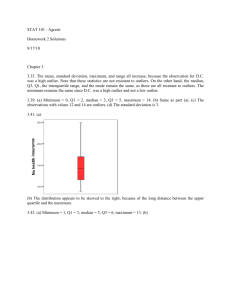
Example 4.6 A dentist is researching the average
advertisement

Chapter 4 Numerical Methods for Describing Data 4.1 Describing the Center of a Data Set In last chapter, we introduced some graphical and tabular methods for describing data. We have seen that a stem-and-leaf display, a frequency distribution, or a histogram gives general impressions about where each data set is centered and how much it spreads out about its center. Now we introduce how to calculate numerical summary measures that describe more precisely both the center and extent of spread. A measure of center is the number that describes roughly where the data set is “centered”. The two most popular measures of center are the mean and the median. Notations: x = the variable for which we have sample data. n = the number of observations in the sample (sample size) x1 = the first sample observation x2 = the second sample observation xn = the nth(last) sample observation x n xi x1 x2 xn . i 1 Definition 4.1 The sample mean of a numerical sample x1, x2, , xn, denoted by x , is the arithmetic average, that is, x x1 x2 xn n x n Example 4.1 A student took five exams. His scores of the five exams are 96 85 93 87 91 Then the mean of the scores is x 96 85 93 87 91 5 90.4 Note: The mean x is not necessary to be a possible observable value of x. Definition 4.2 The population mean, denoted by , is the average of all x values in the entire population. It is customary to use Roman letters to denote sample characteristics and Greek letters to denote population characteristics, for example, x for sample mean and for population mean. The value of x varies from sample to sample, whereas there is just one value for . We shall see subsequently how the value of x from a particular sample can be used to draw various conclusions about . One drawback to the mean as a measure of center for a data set is that its value can be greatly affected by the presence of even a single outlier in the data set. We now introduce another measure of center that is not so sensitive to outliers. Definition 4.3 Once the data values have been listed in order from smallest to largest, the median is the middle value in the list and divides the list into two equal parts, that is, The single middle value if n is odd Sample median = The average of the middle two values if n is even The population median is the middle value in the ordered list of all population observations. If we denote the ordered sample list from smallest to largest by x(1), x( 2 ), , x( n ) then x( n21 ) Sample median = x( n ) x( n 1) 2 2 2 if n is odd if n is even. Example 4.2 The ordered scores in Example 4.1 are 85 x(1) 87 x(2) 91 x(3) 93 x(4) 96 x(5) median = x( 51 ) x( 3) 91 2 An advantage of median over mean is that median is not highly influenced by outliers. Question: If the student failed to get a good score in the fourth exam for a special reason, say 37 instead of 87, what are the mean and the median? Comparing the Mean and the Median (1) When the histogram is symmetric, the mean and median are equal. (2) When the histogram is positively skewed, the mean lies above the median. (3) When a histogram is negatively skewed, the mean is smaller than the median. We also have some other measures of center, for example, trimmed mean. Definition 4.4 A trimmed mean is computed by (i) first ordering the data values from smallest to largest, (ii) then deleting a selected number of values from each end of the ordered list, and (iii) finally averaging the remaining values. The trimming percentage is the percentage of values deleted from each end of the ordered list. Number deleted from each end = (trimming percentage) n Sometimes the number of observations to be deleted from each end of the data set is specified. Then the corresponding trimming percentage is trimming percentage = (number deleted from each end / n) 100 Question: (1) How many observations should we delete from each end to get a 20% trimmed mean of a data set of size 20? (2) What is the 0% trimmed mean? (3) What is the range of trimming percentage? Example 4.3 The following are data on the number of seconds showing alcohol use in each of 30 animated films released between 1980 and 1997. Find the 10% trimmed mean. 34 0 414 0 0 0 0 0 76 74 123 0 3 0 28 0 7 0 0 0 46 0 38 39 13 0 74 0 76 0 0 0 123 414 73 0 72 0 5 3 5 7 The ordered data values are 0 13 0 28 0 34 0 38 0 39 0 46 0 72 0 73 0 0 Since 10% of 30 is 3, the 10% trimmed mean results from deleting the three largest and three smallest data values and then averaging the remaining 24 data values. 10% trimmed mean =(0+0++74) / 24 = 432 / 24 = 18, which falls between the mean x =34.83 and the median ?. A trimmed mean with a small to moderate trimming percentage (between 5% and 25%) is less affected by outliers than the mean, but it is not as insensitive as the median. Trimmed means are used in many sports, for example, gymnastics and dive. In these sports, several judges give scores to each athlete. However, the final score of an athlete is computed by first deleting the lowest and highest scores and then averaging the remaining scores. 4.2 Describing Variability in a Data Set Reporting a measure of center gives only partial information about a data set. It is also important to describe the spread of values about the center. For example, given the following scores of two students in a course Student 1 Student 2 85 80 90 90 95 100 which student’s performance is better? We cannot distinguish the two students’ performances based only on a measure of center. Definition 4.5 The range of a sample = the largest value – the smallest value. The n deviations from the sample mean are the differences x1 x , x2 x , , xn x . A deviation is positive if the x value exceeds x and negative if the x value is less than x . Generally, the larger the magnitudes (ignoring the signs) of the deviations, the greater the amount of variability in the sample. How to combine the deviations into a single numerical measure? Since ( x x ) x nx x x 0 , we can not simply add the deviations together to measure variability. The standard way to prevent positive and negative deviations from counteracting one another is to square them before combinging. Definition 4.6 The sample variance, denoted by s2, is the sum of squared deviations from the mean divided by n-1. That is, 2 (x x) s 2 n 1 S xx n 1 The sample standard deviation is the positive square root of the sample variance and is denoted by s. s is most used since it has the same unit as observations. Note: (1) Interpretation of s: the typical amount by which an observation deviates from x . (2) A computational formula for S xx is S xx Thus, s 2 S xx n 1 ( x2 x ) ( x 2 2 xx x 2 x x nx ( x) ( x) 2 x 2 n n ( x) 2 x n 2 2 2 x2) 2 2 2 2 x ( x) / n . n 1 Example 4.4 A sociologist is studying the amount of time 3 to 6 year olds are allowed to watch television each day. A sample of 15 children is selected and the amount of time they were allowed to watch television was recorded. The data is listed below in hours. 4.0 2.5 1.5 2.0 8.0 3.5 4.0 4.0 2.0 1.0 3.2 1.5 2.5 3.0 3.5 x = (4.0+2.5+1.5+2.0+8.0+3.5+4.0+4.0+2.0+1.0+3.2+1.5+2.5+3.0+3.5) / 15 = 46.2/15 = 3.08 Observation 4.0 2.5 1.5 2.0 8.0 3.5 4.0 4.0 2.0 1.0 3.2 1.5 2.5 3.0 3.5 Deviation (x x) 0.92 -0.58 -1.58 -1.08 4.92 0.42 0.92 0.92 -1.08 -2.08 0.12 -1.58 -0.58 -0.08 0.42 x2 Squared Deviation ( x x )2 0.8464 0.3364 2.4964 1.1664 24.2064 0.1764 0.8464 0.8464 1.1664 4.3264 0.0144 2.4964 0.3364 0.0064 0.1764 16 6.25 2.25 4 64 12.25 16 16 4 1 10.24 2.25 6.25 9 12.25 Sum = 39.444 Sum =181.74 s2 = ?. ( x)2 x2 n s can also be calculated by s = ?. n 1 2 2 s= s 2 = ?. The measures of variability for the entire population that are analogous to s2 and s for a sample are called the population variance and population standard deviation, and are denoted by 2 and respectively. Generally 2 is unknown and is estimated by s2. We use the divisor n-1 in s2 rather than n because, (1) on average, it tends to be a bit closer to 2, (2) the degrees of freedom of s2 is n-1. It is better to use s and for comparative purposes than for an absolute assessment of variability. As with x , s is greatly affected by the presence of even a single outlier. A measure of variability that is resistant to the effects of outliers is the interquartile range. Definition 4.7 lower quartile = median of the lower half of the sample Upper quartile = median of the upper half of the sample. (if n is odd, the median of the entire sample is excluded from both halves.) The interquartile range (iqr) = upper quartile – lower quartile. The population interquartile range = upper population quartile – lower population quartile. Example 4.5 Determine the lower quartile, upper quartile, and the interquartile range for the data in Example 4.4. The ordered data values are 1.0 1.5 1.5 2.0 2.0 2.5 2.5 3.0 3.2 3.5 3.5 4.0 4.0 4.0 8.0 The sample size n = 15 is an odd number, so the median, 3.0 is excluded from both halves of the sample: Lower half Upper half 1.0 3.2 1.5 3.5 1.5 3.5 2.0 4.0 2.0 4.0 2.5 4.0 2.5 8.0 Lower quartile = ?, upper quartile = ?, and iqr = ? - ? = ?. If a histogram of a data set can be reasonably well approximated by a normal curve, then roughly standard deviation s 1iqr .35 . 4.3 Boxplots A boxplot is a display that provides information about the center, spread, and symmetry (or skewness) of the data. Construction of a skeletal boxplot 1. Draw a horizontal (or vertical) measurement scale. 2. Construct a rectangular box whose left (or lower) edge is at the lower quartile and whose right (or upper) edge is at the upper quartile. 3. Draw a vertical (or horizontal) line segment inside the box at the location of the median. 4. Extend horizontal (or vertical) line segments from each end of the box to the smallest and largest observations in the data set. (These line segments are called whiskers.) Example 4.6 A dentist is researching the average time that people brush their teeth. A sample of 21 brushing times is collected and listed below (in seconds). 15 30 120 45 35 30 90 60 45 335 240 50 135 75 120 15 30 30 45 60 30 The ordered observations are 15 15 30 30 30 30 120 120 135 240 335 30 35 45 45 45 50 60 60 75 90 Five-number summary: Smallest observation = 15 Median = x((21+1)/2) = x(11) = ? Lower quartile = median of the lower half = ? Upper quartile = median of the upper half = ? Largest observation = 335 +----------+---------+---------+---------+---------+---------+---------+ 0 50 100 150 200 250 300 350 Figure 4.1 Skeletal boxplot for the brushing times data The median line is closer to the lower edge of the box than to the upper edge, suggesting a concentration of values in the lower part of the middle half. The upper whisker is much longer than the lower whisker, giving the impression of positive skewness. Construction of a modified boxplot We know that an outlier is an unusually small or large data value. Then what does “unusually small or large” mean? Here we give a more formal definition of outliers. An outlier An observation that is more than 1.5 iqr away from the closest end of the box. An extreme outlier An outlier that is more than 3 iqr from the closest end of the box. A mild outlier An outlier that is not an extreme outlier. A modified boxplot A boxplot in which mild outliers are represented by shaded circles, extreme outliers are represented by open circles, and whiskers extend on each end to the most extreme observations that are not outliers. Example 4.7 Draw a modified boxplot for the data set in Example 4.6 Median = 45 Lower quartile = 30 Upper quartile = 105 iqr = 105 –30 = 75 1.5 iqr = 1.5 75 = 112.5 3 iqr = 3 75 = 225 Thus, Upper edge of box + 1.5 iqr = ? + 112.5 = ? Lower edge of box – 1.5 iqr = ? – 112.5 = ? So 240 and 335 are both outliers on the upper end (because they are greater than 217.5), and there are no outliers on the lower end (because no observations are less than -82.5). Since Upper edge of the box + 3 iqr = ? + 225 = ? 335 is an extreme outlier, and 240 is a mild outlier. The upper whisker extends to the largest observation that is not an outlier, ?, and the lower whisker extends to ?. Mild outlier Extreme outlier +----------+---------+---------+---------+---------+---------+---------+ 0 50 100 150 200 250 300 350 Figure 4.2 Modified boxplot for the data in Example 4.6 4.4 Measures of Relative Standing After you take a test, you probably want to know the position of your score in all scores of the test. Does your score place you among the top 10% of those who took the test, or only among the top 30%? Such questions can be answered by measures of relative standing. The z score of a particular observation in a data set is z score = (observation – mean) / standard deviation The z score tells us how many standard deviations the observation is from the mean. It is positive if the observation lies above the mean, and negative if the observation lies below the mean. Example 4.8 In a GRE, a student scored 540 in the verbal section with mean 520 and standard deviation 20, 750 in the math section with mean 720 and standard deviation 40. In which section did the student perform better? Verbal z score = (? – ?) / ? = ? Math z score = (? – ?) / ? = ? Thus, the student performed better in verbal section. Another important measure of relative standing is percentile. For any number r between 0 and 100, the rth percentile is a value such that r percent of the observations in the data set is less than or equal to that value. The median is the ?th percentile, and the lower and upper quartiles are the ?th and ?th percentiles, respectively.