T Statistic
advertisement

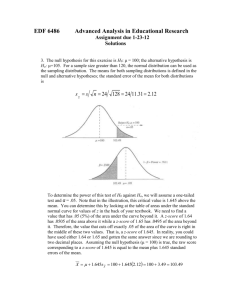
Quantitative Methods Part 3 T- Statistics Standard Deviation Measures the spread of scores within the data set ◦ Population standard deviation is used when you are only interested in your own data ◦ Sample standard deviation is used when you want to generalise for the rest of the population Z - Scores A specific method for describing a specific location within a distribution ◦ Used to determine precise location of an in individual score ◦ Used to compare relative positions of 2 or more scores Normally Distributed (Bell shaped) Distribution of the Means • Frequency Distribution of 4 scores (2, 4, 6,8) X 0 1 2 X 3 4 X 5 6 X 7 • It is flat and not bell shaped • Mean of population is (2+4+6+8)/4 = 5 8 9 Distribution of the Means • Take all possible samples of pairs of scores (2,4,6,8) • Use random sampling and replace each individual sample into data set • Calculate average of all sample pairs 2+6 /2 = 4 6+2 /2 = 4 2+8 /2 = 5 8+2 /2 = 5 2+2 /2 = 2 2+4 /2 = 3 4+2 /2 = 3 0 1 X 2 X X 3 X X X 4 4+4 /2 = 4 4+6 /2 = 5 6+4 /2 = 5 X X X X 5 X X X 6 X X 7 X 8 9 Central Limit Theorem “For any population with a mean μ and standard deviation σ , the distribution of sample means for sample size n will have a mean of μ and standard deviation of σ/√n and will approach a normal distribution as n gets very large.” How big should the sample size be? n=30 X 0 1 X X X X X X X X X X X X X X X 2 3 4 5 6 7 8 9 Standard Error σ/√n is used to calculate the Standard Error of the sample mean Sample data = X The mean of each sample = Then the standard error becomes It identifies how much the observed sample mean differs from the un-measurable population mean μ. So to be more confident that our sample mean is a good measure of the population mean, then the standard error should be small. One way we can ensure this is to take large samples. Example Z= - μ/ σ The population of SATs scores is normal with μ= 500, σ =100. What is the chance that a sample of n=25 students has a mean score =540? Since the distribution is normal, we can use the z-score First calculate Standard Error ◦ 100/5 = 20 Then Z-Score ◦ 540-500/20 =2 z-value is 2, therefore around 98% of the sample means are below this and only 2% are above. So we conclude that the chance of getting a sample mean of 540 is 2%, so we are 98% confident that this sample mean, if recorded in an experiment is false. T - Statistics So far we’ve looked at mean and sd of populations and our calculations have had parameters But how do we deduce something about the population beyond our sample? We can use T-Statistic T - Statistics Remember SD from last week? Great for population of N but not for sample of n Why n -1? Because we can only freely choose n-1 (Degree of freedom = df) T - Statistics Standard Error Z-Score redone to show above = To T-Statistic, we substitute σ (SD of population) with s (SD of sample) But what about μ ? Hypothesis Testing Sample of computer game players n =16 Intervention = inclusion of rich graphical elements Level has 2 rooms ◦ Room A = lots of visuals ◦ Room B = very bland Put them in level 60 minutes Record how long they spend in B Results Average time spent in B = 39 minutes Observed “sum of squares” for the sample is SS = 540. A B Stage1: Formulation of Hypothesis : “null hypothesis”, that the visuals have no effect on the behaviour. : “alternate hypothesis”, that the visuals do have an effect on the players’ behaviour. If visuals have no effect, how long on average should they be in room B? Null hypothesis is crucial; here we can infer that μ = 30 and get rid of the population one Stage 2: Locate the critical region We use the T-table to help us locate this, enabling us to reject or accept the null hypothesis. To get we need: ◦ Number of degree of freedom (df) 16 -1 =15 ◦ Level of significance of confidence ◦ Locate in T-table (2tails)= critical value of t=2.131, t=2.131 Stage 3: Calculate statistics Calculate sample sd Sample Standard Error =6 = 6 / 4 =1.5 T-Statistic =6 The μ 30 came from the null hypothesis if visuals had no effect, then the player would spend 30 minutes in both rooms A and B. Stage 4: Decision Can we reject the , that the visuals have no effect on the behaviour? ◦ T = 6 which is well beyond the value of 2.313 which indicates where chance kicks in. So yes we can safely reject it and say it does affect behaviour Which room do they prefer? ◦ They spent on average 39 minutes in Room B which is bland Workshop Work on Workshop 6 activities Your journal (Homework) Your Literature Review (Complete/update) References Dr C. Price’s notes 2010 Gravetter, F. and Wallnau, L. (2003) Statistics for the Behavioral Sciences, New York: West Publishing Company