生物信息学及其在医学中的应用
杨建华
2010/9/21
yangjh7@mail.sysu.edu.cn
课程安排
1、时间:每周二晚12~14节(18:05-20:40)
教室:艺203教室
学时:每周3学时(总计123=36学时)
2、学分:2学分
3、成绩考核方式:
研究论文
开卷考试
4、E-mail: yangjh7@mail.sysu.edu.cn
Tel:8411 2517(office)
(办公室地址:生命科学学院北院407室)
5、课程大纲和讲义可在课程网站下载。
( http://deepbase.sysu.edu.cn/compBio/index.html )
参考资料
1.
Durbin等, Biological sequence analysis(英文原版), 清华大学出版社,2002
2.
Mount,Bioinformatics—Sequence and Genome Analysis,科学出版社,2002
年(中文版由钟杨等译、高等教育出版社2003年出版)
3.
生物信息学相关期刊
课程目标
掌握分析技术
1) 机器学习
监督和无监督的机器学习和分类
2) 统计方法
贝叶斯原理(Bayes’ Law),隐马尔可夫模型(HMM)
3) 高通量数据分析技术
基因芯片数据和新一代测序数据的分析技术
4) 软件和数据库的原理和开发
5) 生物医药数据可视化
掌握后基因组时代的“捞鱼”技术
利用工具
提出问题
解决问题
编写代码
理论知识
+
编程实践
课程内容
生物信息学(Bioinformatics)的来源
谁是生物信息学的提出者???
Prof. Dr Paulien Hogeweg
Bioinformatics group, Utrecht University
Dr. Hwa A. Lim (林华安)1987年提
出
“Bio-informatique” →
“Bioinformatics”
生物信息学/计算生物学
美国国家卫生研究院(NIH)的定义:
Bioinformatics
为拓展生物学、医学、行为学和卫生学
数据的用途,而进行有关计算机方法手
段的研究、开发与应用,包括此类数据
的采集、存贮、整理、归档、分析与可
视化。
Computational Biology
开发和应用数据分析、理论方法、数学
模型和计算机仿真技术,用于生物学、
行为学和社会群体系统的研究。
课程网站:http://deepbase.sysu.edu.cn/compBio/index.html
生物信息学
从人类基因组计划(HGP), ENCODE 计划 和千人基因组计划说起
三大科学计划
曼哈顿原子弹计划
阿波罗登月计划
人类基因组计划
人类基因组计划
为什么要开展人类基因组计划?
1984.12
基
犹他州阿尔塔组织会议,初步研讨测定人类整个
因组DNA序列的意义
Dulbecco在《Science》撰文 “肿瘤研究的转
1985
折点:人
有助于认识自身、掌握生老病死规律、
类基因组的测序”
疾病的诊断和治疗、了解生命的起源。
人类基因组计划目标
Human Genome = three billion (3*10^9) base pairs
人类基因组计划
(HGP,Human Genome Project)
目标:整体上破解人类遗传信息的奥秘
人类基因组计划-DNA 测序技术
Sanger测序法
双脱氧链终止法
Sanger测序法
新的测序技术
焦磷酸测序法(454,Solexa,
Solid), 单分子测序
新的整合技术
人类基因组序列的组装
GigAssembler
Kent & Haussler, Genome Res. 2001. 11: 1541-1548
为什么需要组装呢?
人类基因组计划幕后英雄 Jim Kent.
“黄金之路”(The Golden Path
人类基因组序列的组装和注释
基因(gene)
生物信息学
组装
DNA测序技术
转座元件
人类基因组
分析技术
进化保守性
基因的鉴定
Human Genome = three billion (3*10^9) base pairs:
基因--有遗传效应的DNA片断,是控制生物性状的基本遗传单位
编码蛋白质或RNA等具有特定功能产物的遗传信息的基本单位
基因的鉴定-隐马尔可夫模型
例子:偶尔作弊的赌场
1
1/10
2
1/10
1/6
3
1/10
4
1/6
4
1/10
5
1/6
5
1/10
6
1/6
6
5/10
1
1/6
2
1/6
3
0.05
0.95
Fair
0.1
0.9
Loaded
21621665666352321264622533314315136163516312314636
22222222222111111111111111111111111111111111111111
51335613554632416254244212326366645622466146342646
11111111111111111111111111112222222222222222222222
隐状态:那个骰子
基因的鉴定
跟线虫的基因数差不多
暗示着。。。。。。
人类基因组序列的显示
Visualization
2000.6.26
2001.2.15
2001.2.16
公共领域和Celera公司同时宣布完成人类基因组工作草图
《Nature》刊文发表国际公共领域结果
《Science》刊文发表Celera公司及其合作者结果
2001年2月15日《Nature》封面
HGC
2001年2月16日《Science》封面
Celera
基因组学研究
2003年人类基因组计划的完成仅仅标志着人类向着利用基因信息诊断、
治疗和预防疾病的目标迈出了重要的第一步。
生物学的挑战
人类基因组大小:约30亿个碱基对
Encyclopedia of DNA
Elements (ENCODE) 计划
DNA元件百科全书计划
人类基因组计划的延伸
ENCODE计划目标
98.5%
?
“Junk DNA”?
[Human Molecular Genetics, 3rd Edition]
2004年Science的10大突破排名第
4
DNA元件百科全书计划
(ENCODE)
目标:对人类基因组功能元件进行全面的鉴定和分析
ENCODE 计划研究规划
ENCODE计划主要分为三个阶段进行 :
①试点研究阶段(ENCODE pilot project)
②技术开发阶段
③实际生产阶段
gene
ENCODE试点研究计划
(ENCODE pilot project)
目标:对人类基因组1%的序列功能元件进行全面的鉴定和分析
高通量技术-芯片技术
基因的异常表达
肿瘤,疾病等相关
基因芯片的应用
肿瘤基因表达谱差异研究
基因突变
基因多态性分析
遗传病产前诊断等
生物信息学技术
大规模集成的固相杂交
高通量技术-芯片数据分析
选择技术,
设计实验
准备样品,
杂交到芯片上
可视化
显示数据
评价数据的质量
移除低质量
归一化
数据
寻找差异
表达的基因
解析结果
构建和应
用分类器
ENCODE试点研究计划-比较基因组学
开发比较
基
因组学软
件
是什么?
Junk DNA
ENCODE试点研究计划-转录组
高通量芯片技术
生物信息技术
整合分析
测序的表达数据
ENCODE Region:
93% 是转录的
>74% 转录能被两种不同方法检测
暗示着……
ENCODE试点研究计划-转录组注释
Hope or Hype?
ENCODE试点研究计划-转录调控
高通量ChIP技术
蛋白结合位点的
peak整合分析
转录组数据
ENCODE Region:
gene
组蛋白的修饰相邻与转录起始位点
DNaseI 超敏位点有特异的组蛋白修
饰模式
暗示……
ENCODE试点研究计划-非编码RNA
支持向量机
概率罚分模型
非编码RNA (ncRNA)
一类以RNA形式行使功能的非蛋白编码的RNA
功能
在细胞的生长、分化和死亡以及癌症
和肿瘤的发生和发展等方面发挥重要作用。
ENCODE试点研究计划-非编码RNA
(1)支持向量机(RNAz)
进化保守
如何选取向量特征?
(2)随机上下文无关文法(evoFold)
最低自由能(MFE)
ModENCODE Project
模式生物DNA元件百科全书计划
为什么要开展模式生物ENCODE计划?
ENCODE试点研究计划-研究论文
28篇相关的文章
1000 Human Genomes Project
千人基因组计划
(A Deep Catalog of Human Genetic Variation)
千人基因组计划的目标
新一代高通
量测序技术
生物信息学
海量的生物学
数据
分析技术
遗传变异
任何两个人的基因有99%多是相同
解释为什么有些人会得某种疾病
目标:构建最全面的人类遗传变异图
为什么需要新一代高通量测序技术
Next-generation sequencing (NGS),
Next is Now
The Human Genome Project (HGP) :
(i) Time: 1990-2003 (expect: 15 years)
(ii) Cost: the $3 billion project
(iii) Output: 96 sequence reads/run
Goals for NGS :
(i) How to significantly shorten the time?
(ii) How to significantly reduce the costs?
(iii) millions of sequence reads in parallel
Sanger Sequencing
High-throughput sequencing (HTS)
Shendure & Ji, 2008;Nature biotechnology, 26, 1135-1145
新一代高通量测序技术
20um
29um
One Fragment = One Bead
Jonathan M. Rothberg
1. the inventor of massively
parallel sequencing
One Bead = One Read
2. the founder of 454
Life Sciences
CCD(电荷耦合元件,
Nobel prize,2009)
400-600 million bases/run
>1 million reads in excess of
400 bp
~$60/Mb
Mardis. 2008; Annu. Rev. Genomics Hum. Genet. 9:387–402
One Fragment = One Bead = One Read
Charge-coupled Device (CCD)
http://www.454.com/
新一代高通量测序技术
高通量测序技术带来的挑战和机遇
Company: Bioinformatics bottleneck threatens to limit instrument sales.
Storage
How storage new NGS data
Mapping
ultra-fast program for mapping NGS reads?
data-analysis capabilities
Annotation
NGS data derived from what
know genomic elements ?
Discovery
RNA-seq, CNV-seq, SNP, ChIP-seq
NGS
data
Visualization
human eyes are always better
McPherson, et al. 2009; Nature Methods., 6:S2-S5
高通量测序技术-存储
最小的空间存储
压缩和二进制法
+
最快的速度查询
+
索引表
BAM格式
内存:~9M 索引
查询速度:几秒
Binary Alignment/Map (BAM)
高通量测序技术-比对
最小的内存
解决方法
哈希索引测序序列
+
哈希索引基因组
Burrows-Wheeler transform
full-text minute-space (FM) index
最快的速度
BWT索引基因组
高通量测序技术-可视化比对数据
可视化
人类的眼睛是最灵敏的。 Customer experiments
回答各种各样的生物学问题
便携性( portability)
能用于多个操作系统平台(如:Linux,Mac 和 Windows)
规模可伸缩性( scalability )
用有限的内存显示巨大的比对数据( 如:10~100GB )
远程可操作性( efficiency over network )
在台式机上浏览在服务器上巨大的数据
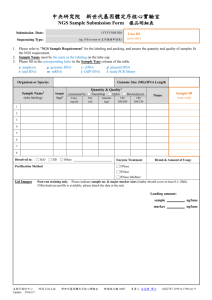
rnaNGS: discovering small and long ncRNAs from pooled NGS data
rnaNGS: 软件界面
deepView 可视化浏览千人基因组计划数据
(a)超快速: 在<1秒, 装载和浏览不限大小的BAM数据和人类基因组序列区域(>3G)
(b)占用内存小:浏览人类基因组序列区域和>900兆BAM数据,只需25兆内存
(c)发现SNP, InDel(insert or delete)位点
deepView 各式各样的功能
(a)支持各式各样的输入格式
(b)改变和移动Track的位置
(c)隐藏和显示Track
(f)改变Track设置
(e)改变背景颜色
(d)改变Track颜色
课程小结
实验技术
人类基因组计划
ENCODE计划
千人基因组计划
生物信息学的应用
Sanger 测序法
基因组整合、注释等
芯片技术
基因鉴定、表达和调控网络
新一代测序技术
整合、比对、可视化和变异
生物信息学的应用
随着实验数据和可利用信息急剧增加,信息的管理和分析成为一项重要的工作
生物信息学的研究意义
认识生物本质
改变生物学的研究方式
了解生物分子信息的组织和结构,破译基因组信
息,阐明生物信息之间的关系
改变传统研究方式,引进现代信息学方法
在医学上的重要意义
为疾病的诊断和治疗提供依据
为设计新药提供依据
生物信息学将是21世纪生物学的核心之一
时刻铭记
•
实验永远起着决定作用
21世纪生命科学
•
计算/理论生物学的发展离不开
实验生物学的贡献
•
实验生物学日益依赖计算/理论
生物学的指导
•
重视基础研究,原创!
理
论
实
验
计
算
数学与物理科学
Perl编程实践
目标:开发计算机的算法解决生物学的问题
Perl 变量定义和声明
变量定义,以$号开头,如:$dna =“ACGT”;
$rna=“ACGU”;
数组定义,以@开头,如:@dnaArray = (‘a’, ’c’, ’g’, ’t’);
数组元素调用 $array [index]。
散列定义,以%开头,如:%hash=(“a",1,“c",2);
变量声明:
私有变量:用 my,如: my $dna = “ACGT”;
全局变量:用our, 如: our $rna = “ACGU”;
临时的变量:用 local, 如: local $word = “ACGTU”;
Perl 语句
if 语句,if (EXPR) BLOCK elsif (EXPR) BLOCK ... else BLOCK
unless语句,unless (EXPR) BLOCK elsif (EXPR) BLOCK ... else
BLOCK
While语句,while (EXPR) BLOCK
until 语句,until (EXPR) BLOCK
for 语句,for (EXPR; EXPR; EXPR) BLOCK
foreach 语句, foreach VAR (LIST) BLOCK
Perl 基本语法-模式匹配
操作符:
匹配:=~ 不匹配:!~
m操作符(匹配)
$haystack =~ m/needle/
$haystack =~ /needle/
# 匹配一个简单模式
# 一样的东西
s操作符(替换)
$dna2rna =~ s/T/U/
# DNA序列转换成RNA序列
tr操作符(转换)
$comp =~ tr/ACGT/TGCA/
# 互补序列
Perl 基本语法-模式匹配
正则量词
字符表缩写
符号
含义
表示方式
量词
原子性
含义
\d
数字
[0-9]
*
否
匹配 0 或者更多次数(最大)。
\D
非数字
[^0-9]
+
否
匹配 或者更多次数(最大)。
\s
空白
[ \t\n\r\f]
?
否
匹配 1 或者0次(最大)。
\S
非空白
[^ \t\n\r\f]
{COUNT}
否
匹配COUNT 次
\w
字
[a-zA-Z0-9_]
{MIN,}
否
匹配至少MIN次(最大)。
\W
非字
[^a-zA-Z0-9_]
{MIN,MAX}
否
匹配至少MIN次但不超过MAX次
(最大)
*?
否
匹配0或者更多次(最小)
+?
否
匹配1或者更多次(最小)
??
否
匹配0或者1次(最小)
{MIN,}?
否
匹配最多MIN次(最小)
{MIN,MAX}?
否
匹配至少MIN次但不超过MAX次
(最小)
修饰词
修饰词
含义
/i
或略字母大小写
/g
全局地查找所有匹配
/cg
在 /g 匹配失败后允许继续查找
Perl 基本语法-函数
传入一个参数
sub printSeq {
sub printSeq {
my $dna = “ACGTATACGT”;
print $dna, “\n”;
my $dna =shift @_;
print $dna, “\n”;
}
}
传入多个参数
sub printSeq {
sub printSeq {
my ($dna,$rna) =@_;
print $dna, “\n”;
my @seq =@_;
print $seq[0], “\n”;
}
}
Perl 基本语法-数据结构
(1)数组的数组
my @seq = ( [“ACG", “CGT" ], [“AGT", “ATT", “ACC" ], [“ACGT", “ACG", “TGG" ] );
print $seq[2][1]; # 打印 “ACG"
(2)
数组的散列
my %RNA = ( snoRNAs => [ “ACA45”, “HBII-52” ], microRNAs => [ “let-7", “lin-4", “mir-1“]);
print $RNA{snoRNAs}[1]; #打印 “HBII-52”
(3)散列的数组
my @RNA = ( {aca45=>”snoRNA”, let-7=>”microrna”},{lin-4=>”microrna”, 5s=>”Rrna”});
print $RNA[1]{lin-4}; #打印 “microrna”
(4)散列的散列
my @gene = (rna=>{aca45=>”snoRNA”, let-7=>”microrna”}, protein=>{lin28=>”target”, hnf4a=>”factor”});
print $gene{protein}{hnf4a}; #打印 “factor”
Perl 编程实践例子
读取基因组序列,并查找序列元件
继续……
Thank You!
 0
0