Ch05 - Min-Shiang Hwang
advertisement

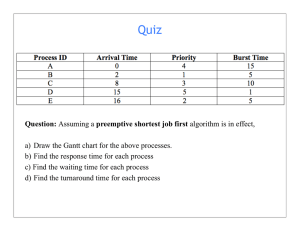
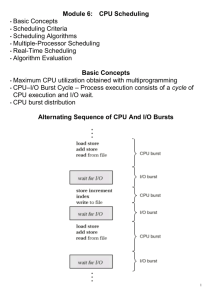
Chapter 5 行程排班 (Process Scheduling) 5.1 5.2 5.3 5.4 Modified by Min-Shiang Hwang (亞大黃明祥) ©2013 基本觀念 排班評定的標準 排班演算法 演算法的評估 1 5.1 基本觀念(Basic Concepts) 在單一處理器(Single-Processor)系統裡,不可以同時有多個程式在執行, 如果有多個行程,其它的都必須在旁邊等待CPU有空,才能接者重新排班。 多元程式規劃(Multiprogramming)系統的主要目的,就是要隨時保有一個 行程在執行,藉以提高CPU使用率。 2 5.1.1 CPU- I/O分割週期 (Burst Cycle) 行程的執行是由CPU執行時間及I/O等 待時間所組成的週期 (cycle)。行程在 這兩個狀態之間交替往返。 行程執行由一個CPU分割 (CPU burst) 開始。跟著是一個I/O分割 (1/O burst), 然後再由另外一個CPU分割跟著,再 來又是另一個I/O分割。 最後的CPU Burst結束時,同時會有系 統要求終止執行此工作。 Alternating Sequence of CPU And I/O Bursts 3 I/O傾向的程式採用短的CPU分割 CPU傾向的程式採用長的CPU分割 4 5.1.2 CPU排班程式(CPU Scheduler) 一旦CPU閒置,作業系統必須從就緒佇列(ready queue)之中選出其 中一個行程來執行。選取行程是由短程排班程式(short-term scheduler) (或CPU排班程式)來執行。排班程式自記憶體之中準備 要執行的數個行程選出一個,並將CPU配置給它。 5.1.3 可搶先排班(Preemptive Scheduling) CPU 排班的決策發生在下面四種情況︰ 1. 當一行程從執行狀態轉變成等待狀態時(例如,I/O要求、等 待其中一個子行程的結束)。 2. 當一行程從執行狀態轉變成就緒狀態時(例如,當有中斷發生 時)。 3. 當一行程從等待狀態轉變成就緒狀態時(例如,I/O的結束)。 4. 當一行程終止時。 Scheduling under 1 and 4 is nonpreemptive (不可搶先的) Scheduling under 2 and 3 is preemptive (可搶先的) 5 5.1.4 分派程式(Dispatcher) 作業系統中CPU排班程式功能所包含的另外一個元件就是 分派程式(dispatcher) 分派程式將CPU控制權交給其他Process(由短程排班程式 選出)時所採用之模組 其功能 轉換內容(switching context) 轉換成使用者模式 (user mode) 跳越到使用者程式的適當位置以便重新開啟程式 Dispatch latency (分派潛伏期) – time it takes for the dispatcher to stop one process and start another running 6 5.2 排班評定的標準(Scheduling Criteria) CPU使用率(utilization) : 使CPU盡可能地忙碌。原則上它的使用率可以 從 0個 百分比到 100個百分比。而在實際的系統裡,它的使用率應該是 40% (負荷 較輕的系統)到 90% (負荷較重的系統)的範圍。 產量 (throughput): 如果CPU是忙碌地執行行程,工作就可以不斷地進 行。 其中有一種衡量工作量的標準,就是用每單位時間所完成的行程數來計 算,稱為產量。對長的行程而言,可能一個鐘頭只完成一個,但是對短 的行程 而言,則產量可能多到每秒鐘完成十個。 回復時間 (turnaround time): 對某一個特定行程而言,是這個行程到底需 要多少時間才能完成。執行一個特定的process所需的時間稱為回復時間。 回復時間是進入等待主記憶體、在就緒佇列等待,以及 CPU執行和執行 輸出/入動作等時間的總和。 等候時間 (waiting time): CPU排班的法則,對於實際執行一個行程所需 的時間,而輸出入動作的次數並沒有任何的影響。它只會影響一個行程 在就緒佇列等待的時間。等候時間是在就緒佇列(ready queue)中等待所 花費週期的總和。 反應時間(response time):在交談式系統之中,一個衡量的標準就是以提 出一個要求到第一個反應出現的時間間隔來計算,這就是所謂反應時間。 7 5.3 排班演算法(Scheduling Algorithms) 5.3.1 先來先做之排班方法(FCFS: First-Come, First-Served ) 把CPU分配給第一個要求CPU的行程。FCFS策略的製作很容易用 FlFO佇列管理。當一個行程進入就緒佇列之後,它的行程控制區段 就鏈接到串列的尾端。 FCFS: Nonpreemptive What’s the average waiting time? Convoy effect (護送現象) short process behind long process 8 5.3.2 最短的工作先做之排班方式(SJF: Shortest-Job-First) 演算法將每一個行程的下一個 CPU分割長度和該行程相結合。當 CPU有空時,就指定給下一個CPU分割最短的行程。如果兩個行程 具有相同長度的下一個CPU分割,那麼就採用先來先做 (FCFS)的方 法。 Process Arrival Time Burst Time P1 0.0 6 P2 0.0 8 P3 0.0 7 P4 0.0 3 SJF scheduling chart P4 0 P3 P1 3 9 P2 16 24 Average waiting time = (3 + 16 + 9 + 0) / 4 = 7 9 SJF is optimal – gives minimum average waiting time for a given set of processes The difficulty is knowing the length of the next CPU request Determining Length of Next CPU Burst Can only estimate the length Can be done by using the length of previous CPU bursts, using exponential averaging 1. t n actual length of n th CPU burst 2. n 1 predicted value for the next CPU burst 3. , 0 1 4. Define : n1 tn 1 n . Examples of Exponential Averaging =0 =1 n+1 = n Recent history does not count n+1 = tn Only the actual last CPU burst counts If we expand the formula, we get: n+1 = tn+(1 - ) tn-1 + …+(1 - )j tn-j + …+(1 - )n +1 0 Since both and (1 - ) are less than or equal to 1, each successive term has less weight than its predecessor Prediction of the Length of the Next CPU Burst 0=10 =1/2 13 5.3.3 優先權排班方式 (Priority Scheduling) 每一個行程都有它的優先順序。CPU 將分配給具有最高優先權的行 程,具有相同優先順序的行程則按照 FCFS 來排班。優先權一般是 一些固定範圍的數字,譬如 0 到 7 或 0 至 4095。 Process Burst Time P1 10 P2 1 P3 2 P4 1 P5 5 P2 0 P5 1 P1 Priority 3 1 4 5 2 P3 P4 16 18 19 6 Average waiting time = (6+0+16+18+1)/5 = 8.2 Problem Indefinite Blocking (無限期阻塞) or Starvation (饑餓) – low priority processes may never execute Solution Aging (老化) – as time progresses increase the priority of the process 14 5.3.4 依序循環之排班方式(Round-Robin Scheduling) 依序循環排班演算法(round-robin, RR, scheduling algorithm)是特別為 了分時作業系統而設計的,這種排班方法和FCFS排班法相類似,但 是加入可搶先的規則以便行程互相交換使用CPU。我們定義一個小 的時間單位,稱為一個時間量(time quantum或是時間片段time slice)。 Time Slice: 4 ms Waiting Time= (10-4)+4+7=17 15 Round Robin (RR) Each process gets a small unit of CPU time (time quantum), usually 10-100 milliseconds. After this time has elapsed, the process is preempted and added to the end of the ready queue. If there are n processes in the ready queue and the time quantum is q, then each process gets 1/n of the CPU time in chunks of at most q time units at once. No process waits more than (n-1)q time units. Performance q large FIFO q small q must be large with respect to context switch, otherwise overhead is too high (time quantum) (switching context) 17 time quantum = 5 P1(5) – p2(3) – p3(1) – p4(5) – p1(1) –p4(2) Turnaround Time = 15 + 8 + 9 + 17 = 49 time quantum = 6 P1(6) – p2(3) – p3(1) – p4(6) – p4(1) Turnaround T = 6 + 9 + 10 + 17 = 42 18 5.3.5 多層佇列之排班方式(Multilevel Queue) 根據行程的性質將它們分成幾個不同的小組。例如,最典型的分類 方法是區分為前景 (foreground)和背景 (background),分別代表交談 式和整批作業的行程。 Each queue has its own scheduling algorithm foreground – RR background – FCFS 19 5.3.6 多層回饋佇列之排班方式(Multilevel Feedback Queue) 多層回饋佇列的排班法則 (multilevel feedback-queue scheduling algorithm)允許行程在佇列之間移動。它是利用不同CPU分割時段的 特性,界分不同等級的佇列。 一個行程需要太長的CPU時間,就會排到低優先的佇列。高優先佇 列通常排的都是系統任務和交談式行程等。同樣地,在低優先佇列 等候太久的行程,隨著時間的增長,也會漸漸地移往高優先佇列。 Queue 0 Queue 1 Queue 3 不同Queue有其獨立 Scheduling 20 Example of Multilevel Feedback Queue Three queues: Q0 – RR with time quantum 8 milliseconds Q1 – RR time quantum 16 milliseconds Q2 – FCFS Scheduling A new job enters queue Q0 which is served FCFS. When it gains CPU, job receives 8 milliseconds. If it does not finish in 8 milliseconds, job is moved to queue Q1. At Q1 job is again served FCFS and receives 16 additional milliseconds. If it still does not complete, it is preempted and moved to queue Q2. 5.4 5.4.1 演算法的評估(Algorithm Evaluation) 定量模式(Deterministic Modeling) 分析性的評估是定量模式取一個特殊預定的工作量,並且規定針對 該工作量做每種演算的效能。 22 23 5.4.2 佇列模式(Queueing Models) 許多系統執行的行程每天都不一樣,因此沒有固定的一組行程 (和時 間)可以用來做定量模式。然而,可以定出的是CPU和I/O分割的分佈 情形。(這些分怖是可以測量及估計) 若平均每秒有7個新的Processes等待執行,並且一般有14個Processes 在Queues中,於是可以計算出每Process大約等待時間為 14/7=2秒。 24 5.4.3 模擬(Simulations) 為了得到更正確的排班演算法之評估,一般都採用模擬(simulation) 方式。 使用Random Number Generator產生亂數,再依照機率分配的情形產生 Process、CPU Burst Time、到達時間、及離開的時間等等。 25