sge - The University of Sheffield High Performance and Grid
advertisement

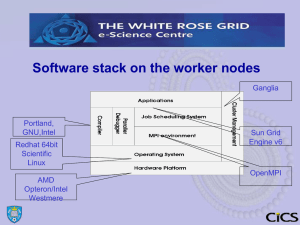
Submitting Jobs to the Sun Grid Engine CiCS Dept The University of Sheffield Email D.Savas@sheffield.ac.uk M.Griffiths@sheffield.ac.uk October 2011 Topics Covered • • • • • • Introducing the grid and batch concepts. Job submission scripts. How to submit Batch Jobs. How to monitor the progress of your jobs. Starting Interactive Jobs. Cancelling submitted jobs. iceberg Resources in 2010 • Two head nodes ( for logging on, system management and light user tasks etc.) • 96 of AMD Opteron based Sun X2200 Servers: – Each server has 4 cores (=in 2*dual processor configuration) and 16 GB of RAM (i.e 4 GB per core ), Clock rate of each core is 2.6GHz – Therefore total cores = 96*4 = 384 • 20 of AMD Opteron based Sun V40 servers (parallel nodes): • • – Each server has 8 cores ( in 2*quadcore configuration) and 32 GB of RAM ( i.e. 4GB per core ). Clock rate of each core is 1.9GHz . – These parallel nodes are connected to each other with Infiniband based fast interconnects for use with MPI programming, each connection providing 16 Gbits of connection speed – Therefore total cores = 20*8=160 10 more Sun V40 servers for dedicated research projects. Total number of cores generally available =384+160=544 ( not including the 10 dedicated research project servers ) • 45 Terabytes of usable file store. Iceberg resources after the 2011 upgrade • 76 extra nodes proving (12*76=912) extra cores. • Each node contains two Intel X5650 CPU’s with hyper-threading disabled but turbo-boost enabled. • Each CPU has 6 cores. • Therefore, each node has 12 cores and they share RAM memory of 24 GBytes ( i.e. 2 GBytes per core ) • A few of the nodes has 4 GBytes per core RAM making a total of 48 GBytes per node. These nodes will be dedicated to running large memory ( i.e upto 48 GByte ) jobs. • 8 NVideo Tesla M2070 GPU’s (i.e. 8*448=3584 GPU cores) • An extra brand-new parallel file system ( lustre ) providing 80 Terabytes of extra filespace ( /fastdata ) as well as the currently available 45 Terabytes (in /home & /data ) Iceberg Cluster There are two head-nodes for the cluster login qsh,qsub,qrsh Worker node Worker node HEAD NODE1 HEAD NODE2 Iceberg(1) Iceberg(2) Worker node Worker node There are 127 +76(new) worker machines in the cluster Worker node Worker node Worker node login qsh,qsub,qrsh Worker node Worker node All workers share the same filestore Worker node Worker node Worker node Using the iceberg cluster • • • • Iceberg headnodes are the gateways to the cluster of worker nodes and the only ones where direct logging in is allowed. File system looks identical from all worker nodes and the headnode ( exception being the HPC software directories that are only visible from the worker nodes) All cpu intensive computations must be performed on the worker nodes. This is achieved by the qsh or qrsh command for the interactive jobs and qsub command for the batch jobs. Once you log into iceberg, taking advantage of the power of a worker node for interactive work is done simply by typing qsh and working in the new shell window that is opened. This what appears to be a trivial task would in fact have queried all the worker nodes for you and started a session on the least loaded worker in the cluster. SGE worker node SGE worker node SGE worker node SGE worker node C Slot 1 B Slot 1 A Slot 1 C Slot 2 Queue-B C Slot 1 B Slot 1 B Slot 3 B Slot 2 B Slot 1 C Slot 3 C Slot 2 C Slot 1 B Slot 1 A Slot 2 A Slot 1 Queue-A SGE worker node Queue-C SGE MASTER node Queues Policies Priorities JOB X JOB Y Share/Tickets JOB Z JOB O JOB N JOB U Scheduling ‘qsub’ batch jobs on the cluster Resources Users/Projects Running interactive jobs on the cluster 1. User asks to run an interactive job (qsh, qrsh ) 2. SGE checks to see if there are resources available to start the job immediately (i.e a free worker ) – – If so, the interactive session is started under the control/monitoring of SGE on that worker. If resources are not available the request is simply rejected and the user notified. This is because by its very nature users can not wait for an interactive session to start. 3. User terminates the job by typing exit or logout or the job is terminated when the queue limits are reached (i.e. currently after 8 hours of wall-clock time usage). Summary table of useful SGE commands Command(s) Description User/System qsub, qresub,qmon Submit batch jobs USER qsh,qrsh Submit Interactive Jobs USER qstat , qhost, qdel, qmon Status of queues and USER jobs in queues , list of execute nodes, remove jobs from queues qacct, qmon, qalter, qdel, qmod Monitor/manage accounts, queues, jobs etc SYSTEM ADMIN Working with SGE as a user – – – – qsub ( submit a batch job ) qsh or qrsh ( start an interactive job ) qstat ( query jobs’ status ) qdel ( delete a job ) Exercise 1: Submit a job via qsub • Create a script file (named example.sh) by using a text editor such as gedit ,vi or emacs and inputing the following lines: #!/bin/sh # echo “This code is running on” /bin/hostname /bin/date • Now Submit this script to SGE using the qsub command: qsub example.sh More on Submitting Batch Jobs qsub command details In its simplest form any script file can be submitted to the SGE by simply typing qsub scriptfile . In this way the scriptfile is queued to be executed by the SGE under default conditions and using default amount of resources. Such use is not always desirable as the default conditions provided may not be appropriate for that job . Also, providing a good estimate of the amount of resources needed helps SGE to schedule the tasks more efficiently. There are two distinct mechanisms for specifying the environment & resources; 1) Via parameters to the qsub command 2) Via special SGE comments (#$ ) in the script file that is submitted. The meaning of the parameters are the same for both methods and they control such things as; - cpu time required number of processors needed ( for multi-processor jobs), output file names, notification of job activity. Method 1 Using qsub command-line parameters Format: qsub [qsub_params] script_file [-- script_arguments] Examples: qsub myjob qsub –cwd $HOME/myfolder1 qsub –l h_rt=00:05:00 myjob -- test1 -large Note that the last example passes parameters to the script file following the -- token. Method 2 special comments in script files A script file is a file containing a set of Unix commands written in a scripting language ‘usually Bourne/Bash or C-Shell’. When the job runs these script files are executed as if their contents were typed at the keyboard. In a script file any line beginning with # will normally be treated as a comment line and ignored. However the SGE treats the comment lines in the submitted script, which start with the special sequence #$ ,in a special way. SGE expects to find declarations of the qsub options in these comment lines. At the time of job submission SGE determines the job resources from these comment lines. If there are any conflicts between the actual qsub command-line parameters and the special comment (#$) sge options the command line parameters always override the #$ sge options specified in the script. An example script containing SGE options #!/bin/sh #A simple job script for sun grid engine. # #$ -l h_rt=01:00:00 #$ -m be #$ -M username@shef.ac.uk benchtest < inputfile > myresults More examples of #$ options in a scriptfile #!/bin/csh # Force the shell to be the C-shell # On iceberg the default shell is the bash-shell #$ -S /bin/csh # Request 2 GBytes of virtual memory #$ -l h_vmem=2G # Specify myresults as the output file #$ -o myresults # Compile the program pgf90 test.for –o mytestprog # Run the program and read the data that program # would have read from the keyboard from file mydata mytestprog < mydata Qsub options on iceberg (resources related) -l h_rt=hh:mm:ss The wall clock time. Example: -l h_rt=01:00:00 ( for one hour job ) -l h_vmem=memory or -l mem=memory Sets the limit of virtual memory required (for parallel jobs per processor). Memory can be nnK, nnM or nnG Example: -l mem=3G ( 3 Gigabytes ) -l mem= 512M ( 512 Mbytes ) -pe openmp n -pe mvapich2-ib n -pe openmpi-ib n -pe ompigige n Specifies the parallel environment to be used for parallel jobs. n is the number of cpu’s needed to run the parallel job. In general, to run an n-way parallel job you must specify n number of processors via this option. -pe [env] n-m Rather than a fixed number of processors for any of the above parallel environments, a range of processors can also be specified to request minimum of (n) and maximum of (m) processors. Example: –pe openmp 4-8 -help Prints a list of options Qsub options ( environment related … ) -cwd directory Execute the job from the specified directory. By default the job runs on the same directory it was submitted from. However, using this option you can specify a different directory. -P projectname Run the job under a special project account -S shell Use the specified shell to interpret the script rather than the default Bash shell. Example: -S /bin/csh -v variable[=value] Passes an environment variable to the executing jobs shell. Example –v OMP_NUM_THREADS=4 -V Export all environment variables to the job. Qsub options ( notifications and testing related ) -M email_address Email address for job notifications. Example: -M Joe.Bloggs@gmail.com -m b e a s Send email(s) when the job begins , ends, aborted or suspended Example: –m be -now Start running the job now or if can’t be run exit with an error code. -verify do not submit the job but check and report on submission. Qsub options (output files and job names related ) When a job is submitted it is given a unique job_number . Also by default the name of the script file becomes the jobname . When the job starts running the standard output and error output is sent to files that are named as jobname. ojob_number and jobname. ejob_number respectively. For example: myscript.o45612 myscript.e45612 The following parameters modify this behaviour. -o pathname Name of the file that will contain the main output -e pathname Name of the file that will contain error output messages -j y (Join) Send both main ouput and error output messages into the same file. ( highly recommended ) -N jobname Rather than the scriptfile use the supplied name as the jobname Example: relating to job output files Passed to qsub as arguments during submission: qsub –N walldesign –j y walljob OR insert in the submit script file walljob: #$!/bin/bash #$ -N walldesign #$ -j y /home/data/my_app and submit the job qsub walljob Using either of these methods, when the job runs the both normal and error output will be contained in a file named walldesign.onnnnn where nnnnn is the unique job number SGE designated to your job at the time of submission. More on starting interactive iobs qsh and qrsh commands • qsh : starts an Xterm session on a worker node. Use this command if you have XWindows capabilities. • qrsh : starts a remote command shell and optionally executes a shellscripts on a worker node. If you do not have Xwindows capability, i.e. you are not using “Exceed, Xming Cygwin ” so on, this is the way for starting interactive jobs on iceberg. It is suitable when you log in using putty or ssh in line-mode. In Sheffield all interactive jobs are put into the short queues that limit the clock time to 8 hours of wall clock time. BEWARE: As soon as the time limit is exceeded the job will terminate without any warning. qrsh command qrsh [parameters] • If no parameters are given it behaves exactly like qsh. This is the normal method of using qrsh. • If there are parameters a remote shell is started up on one of the workers and the parameters are passed to shell for execution. For example, if a script file name is presented as a parameter, commands in the script file are executed and the job terminates when the end of the script file is reached. Example : qrsh myscript Monitoring your jobs A submitted job will either be; 1. 2. 3. still waiting in the queue, be executing, finished execution and left the SGE scheduling system. In order to monitor the progress of your job while in states (1) and (2) use the qstat or Qstat commands that will inform you if the job is still waiting or started executing. The command qstat gives info about all the jobs but Qstat gives info about your jobs alone. While executing (state 2) ; use qstat –j job_number to monitor the jobs status including time and memory consumptions. Contains too much information ! Better still use qstat –j job_number | grep mem that will give time and memory consumed information. Also use tail –f job_output_filename to see the latest output from the job Finished executing ( state 3) ; qacct is the only command that may be able to tell you about the past jobs by referring to a data-base of past usage. Output file names will contain the job number so; qacct -j job_number should give some information. Monitoring your job • If you are interested in only your job use Qstat job-ID prior name user state submit/start at queue slots ja-task-ID -----------------------------------------------------------------------------------------------------------------------------------------3067843 0.50859 INTERACTIV cs1ds r 10/21/2010 09:03:05 interactive.q@node94.iceberg.s 1 3076264 0.50500 INTERACTIV cs1ds r 10/21/2010 16:37:37 interactive.q@node94.iceberg.s 1 • If you want to see all the jobs use qstat job-ID prior name user state submit/start at queue slots ja-task-ID ----------------------------------------------------------------------------------------------------------------------------------------3064625 0.57695 grd80x120x cpp06kw r 10/15/2010 02:35:43 long.q@node81.iceberg.shef.ac. 1 3064818 0.56896 M11_NiCl.3 chp09bwh r 10/15/2010 15:44:44 parallel.q@node107.iceberg.she 4 3065270 0.56657 pythonjob co1afh r 10/16/2010 13:34:33 long.q@node59.iceberg.shef.ac. 1 3065336 0.56025 parallelNe elp05ws r 10/16/2010 13:34:33 long.q@node86.iceberg.shef.ac. 1 3065340 0.56025 parallelNe elp05ws r 10/16/2010 15:31:51 long.q@node23.iceberg.shef.ac. 1 3065558 0.55060 coaxialjet zzp09hw r 10/17/2010 14:03:53 parallel.q@node105.iceberg.she 17 3065934 0.54558 periodichi mep09ww r 10/18/2010 08:39:06 parallel.q@node96.iceberg.shef 8 3066207 0.53523 gav1 me1ccl r 10/18/2010 20:00:16 long.q@node87.iceberg.shef.ac. 1 3066213 0.53510 ga2 me1ccl r 10/18/2010 20:00:26 long.q@node87.iceberg.shef.ac. 1 3066224 0.53645 DDNaca0 mep09ww r 10/18/2010 23:41:56 parallel.q@node112.iceberg.she 12 3066226 0.53493 ga3 me1ccl r 10/18/2010 20:00:46 long.q@node33.iceberg.shef.ac. 1 3066231 0.53491 ga4 me1ccl r 10/18/2010 20:00:46 long.q@node33.iceberg.shef.ac. 1 3066415 0.53078 job elp07dc r 10/19/2010 09:25:24 eenano.q@node124.iceberg.shef. 32 3066896 0.52323 fluent12jo fc1jz qw 10/19/2010 05:32:01 3067083 0.52222 Oct_ATLAS php09ajf qw 10/19/2010 17:41:01 qstat command • qstat command will list all the jobs in the system that are either waiting to be run or running. This can be a very long list ! • qstat –f full listing ( even longer) • qstat –u username or Qstat ( recommend this ! ) • qstat –f –u username ( detailed information ) Status of the job is indicated by letters in qstat listings as: qw waiting t transfering r running s,S suspended R restarted T treshold Deleting Jobs with the qdel command qdel command will remove from the queue the specified jobs that are waiting to be run or abort jobs that are already running. • Individual Job qdel 15112 • List of Jobs qdel 15154 15923 15012 • All Jobs running or queueing under a given username qdel –u <username> Reasons for Job Failures – SGE cannot find the binary file specified in the job script – One of the Linux environment resource limits is exceeded (see command ulimit –a ) – Required input files are missing from the startup directory – You have exceeded your quota and job fails when trying to write to a file ( use quota command to check usage ) – Environment variable is not set (LM_LICENSE_FILE etc) – Hardware failure Job Arrays By using a single qsub command, it is possible to submit a series of jobs that use the same job template. These jobs are described as array jobs. For example: qsub myanalysis –t 1-10 will submit the script named myanalysis as 10 separate jobs. Of course it is pointless to run the same job 10 times. The only justification for doing so is that all these jobs are doing different tasks. This is where a special environment variable named SGE_TASK_ID becomes essential. In the above example in each job the variable SGE_TASK_ID will contain a unique number between 1 and 10 to differentiate these jobs from each other. Thus we can use this variable’s value to control each job in a different manner. Example Array jobs and the $SGE_TASK_ID variable #$ -S /bin/tcsh #$ -l h_cpu=01:00:00 #$ -t 2-16:2 #$ -cwd myprog > results.$SGE_TASK_ID < mydata.$SGE_TASK_ID This will run 8 jobs. The jobs are considered to be independent of each other and hence may run in parallel depending on the availability of resources. Note that tasks will be numbered 2, 4 ,6 ,8 … (steps of 2) For example job 8 will read its data from file mydata.8 and write its output to file results.8 It is possible to make these jobs dependent on each other so as to impose an order of execution by means of the –hold_jid parameter. An example OpenMP job script OpenMP programming takes advantage of the multiple CPU’s that reside in a single computer to distribute work amongst CPUs that share the same memory. Currently we have maximum of 8 CPU’s per computer and therefore only upto 8 processors can be requested for an iceberg openmp job. After the next upgrade this figure will increase to minimum 24. #$ -pe openmp 4 #$ -l h_rt=01:30:00 OMP_NUM_THREADS=4 ./myprog An example MPI job script MPI programs are harder to code but can take advantage of interconnected multiple computers by passing messages between them ( MPI= Message Passing Interface ) 23 workers on the iceberg pool are connected together with fast Infiniband communications cabling to provide upto 10 Gbits/sec data transfer rate between them. The rest of the workers can communicate with each other via the normal 1 Gbits/sec ethernet cables. #$ -pe mvapich2-ib 4 # limit run to 1 hours actual clock time #$ -l h_rt=1:00:00 mpirun_rsh -rsh -np $NSLOTS -hostfile $TMPDIR/machines ./executable Hints • Once you prepared your job script you can test it by simply running it, if possible for a very small problem. Note also that the qsub parameters which are defined using the #$ sequence will be treated as comments during this run. • Q: Should I define the qsub parameters in the script file or as parameters at the time of issuing qsub ? A: The choice is yours, I prefer to define any parameter, which is not likely to alter between runs, within the script file to save myself having to remember it at each submission. SGE related Environment Variables Apart from the specific environment variables passed via the –v or –V options, during the execution of a batch job the following environment variables are also available to help build unique or customized filenames messages etc. • • • • • • $HOME : Your own login directory $USER : your iceberg username $JOB_NAME : Name of the job $HOSTNAME : Name of the cluster node that is being used $SGE_TASK_ID : Task number (important for task arrays) $NSLOTS : Number of processors used ( important for parallel ‘openmp or mpi’ jobs ) Submitting Batch Jobs via the qmon command If you are using an X terminal ( such as provided by Exceed ) then a GUI interface named qmon can also be used to make job submission easier. This command also allows an easier way of setting the job parameters. Job submission panel of QMON Click on Job Submission Icon Click to browse for the job script test2 Job queues • Unlike the traditional batch queue systems, users do not need to select the queue they are submitting to. Instead SGE uses the resource needs as specified by the user to determine the best queue for the job. • In Sheffield and Leeds the underlying queues are setup according to memory size and cpu time requirements and also numbers of multiple cpu’s needed (for mpi & openmp jobs ) • qstat –F displays full queue information, Also qmon (TaskQueue_Control) will allow information to be distilled about the queue limits. Job queue configuration Normally you will not need to know the details of each queue, as the Grid Engine will make the decisions for you in selecting a suitable queue for your job. If you feel the need to find out how the job queues are configured, perhaps to aid you in specifying the appropriate resources, you may do so by using the qconf system administrator command. • qconf –sql will give a list of all the queues • qconf –sq queue_name will list details of a specific queue’s configuration Monitoring the progress of your jobs • The commands qstat and the XWindows based qmon can be used to check on the progress of your jobs through the system. • We recommend that you use the qmon command if your terminal has X capability as this makes it easier to view your jobs progress and also cancel or abort it, if it becomes necessary to do so. Checking the progress of jobs with QMON Click on Job Control Icon Click on Running Jobs tab Tutorials On iceberg copy the contents of the tutorial directory to your user area into a directory named sge: cp –r /usr/local/courses/sge sge cd sge In this directory the file readme.txt contains all the instructions necessary to perform the exercises. Further documentation and help • man ( manual pages) : man sge , man qsh man qsub so on.. • HTML pages http://www.sheffield.ac.uk/wrgrid/using/runapps The End