Introduction to Field Programmable Gate Arrays
advertisement

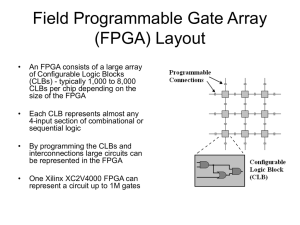
INTRODUCTION TO FIELD PROGRAMMABLE GATE ARRAYS (FPGAS) Bill Jason P. Tomas Dept. of Electrical and Computer Engineering University of Nevada Las Vegas FIELD PROGRAMMABLE ARRAYS Dominant digital design implementation Ability to re-configure FPGA to implement any digital logic function Partial re-configuration allows a portion of the FPGA to be continuously running while another portion is being re-configured FPGAs also contain analog circuitry features including a programmable slew rate and drive strength, differential comparators on I/O designed to be connected to differential signaling channels. Mixed-signal FPGAs contains ADCs and DACs with analog signal conditional blocks allowing them to operate as a system-on-chip (SoC) FPGA ARCHITECTURES Early FPGAs N x N array of unit cells (CLB + routing) Special routing along center axis Next Generation FPGAs M x N unit cells Small block RAMs around edges More recent FPGAs Added block RAM arrays Added multiplier cores Adders processor cores FPGA ARCHITECTURE TRENDS Memories Single & Dual-port RAMS FIFO (first-in first-out) ECC (error correcting codes) Digital Signal Processors Multipliers Accumulators Arithmetic Logic Units (ALUs) Embedded Processors Hardcore (dedicated processors) Dedicated program and data memories Programmable RAM in FPGA can be used in conjunction with the processor to provide program and data memories Soft core (synthesized from a HDL) BASIC FPGA ARCHITECTURE •More recent FPGA architectures have small block RAM arrays (usually placed in center column), multipliers, processor cores, DSP cores w/ multipliers, and I/O cells along columns for BGAs. FPGA OPERATION User writes configuration memory which defines the function of the system. This includes: the connectivity between the CLBs and the I/O cells, the logic to be implemented onto the CLBs, and the I/O blocks. By changing the data in the configuration memory, the function of the system changes as well. This change in data can be implemented at anytime during FPGA operation (run-time configuration). CONFIGURABLE LOGIC BLOCKS (CLBS) ARCHITECTURE CLBs consist of: Look-up Tables (LUT) which implement the entries of a logic functions truth table Carry and Control Logic Some FPGAs can use LUTs to implement small Random Access Memory (RAM) Implements fast arithmetic operations (adders/ subtractors) Can be alsoconfigured for additional operations (Built-in-Self Test iterative-OR chain) Memory Elements Configurable Flip Flops (FFs)/ Latches( Programmable clock edges, set/reset, and clock enable) These memory elements usually can be configured as shiftregisters CONFIGURABLE LOGIC BLOCKS A CLB can contain several slices, which make up a single CLB. Xilinx Virtex-5 FPGAs (right) have two slices: SLICEL (logic) and SLICEM (memory). In addition to the basic CLB architecture, the Virtex-5 contains widefunction MUXs which can implement: - 4:1 MUX using 1 LUT - 8:1 MUX using 2 LUTs - 16:1 MUX using 4 LUTs LOOK-UP TABLES (2:1 MUX EXAMPLE) Configuration memory holds output of truth table entries Internal signals connect to control signals of MUXs to select a values of the truth tables for any given input signals LUT BASED RAM Normal LUT mode performs read operation Address decoders with WE generates clock signals to latches for write operation Smaller RAMs can be combined to create larger RAMs (up to 64bit in Virtex-5) FPGA PROGRAMMABLE INTERCONNECTION NETWORK Horizontal and vertical mesh of wire segments interconnected by programmable switches called programmable interconnect points (PIPs). These PIPs are implemented using a transmission gate controlled by a memory bits from the configuration memory. Consists of global routing connecting PLBs to I/O buffers, non-adjacent PLBs, and other embedded components. Local routing connects PLBs to other adjacent PLBs and PLBs to global routing (done through a switch matrix) Several types of PIPs are used Cross-point = connects vertical or horizontal wire segments allowing turns Breakpoint = connects or isolates 2 wire segments Decoded MUX = group of 2^n cross-points connected to a single output configure by n configuration bits Non-decoded MUX = n wire segments each with a configuration bit (n segments) Compound cross-point = 6 Break-point PIPS (can isolate two isolated signal nets) PROGAMMABLE INPUT/OUTPUT CELLS Bi-directional Buffers Programmable for inputs or outputs Tri-state controls bi-directional operation Pull-up/down resistors FFs/ Latches are used to improve timing issues Set-up and hold times Clock-to-out delay Routing Resources Connections to core of array Programmable I/O voltage and current levels Boundary Scan Access FPGA CONFIGURATION INTERFACES Master (Serial or Parallel) FPGA retrieves configuration from ROM at initial power-up Slave (Serial or Parallel) FPGA configured by an external source (i.e microprocessor/ other FPGA) Used for dynamic partial re-configuration Boundary Scan 4-wire IEEE standard serial interface used for testing Write and read access to configuration memory Interfaces to FPGA core internal routing network BOUNDARY SCAN CONFIGURATION Multi-FPGA Emulation Framework to support NoC design and verification (UNLV NSIL) Developed to test interconnect between chips on PCB Test Access Point (TAP) controller composed of 16 state FSM Daisy Chain Configuration FPGA CONFIGURATION TECHNIQUES Full configuration and readback Simple configuration interface Larger FPGAs have a longer download time Compressed configuration Requires multiple frame write capability Identical frames of configuration data are written to multiple frame addresses Extension of partial re-configuration interface capabilities Automatic internal calculation of frame address Frame address is much smaller than frame of configuration data Reduces download time for initial configuration depending on regularity of system function and the array percent that is utilized Partial re-configuration and readback Only change portions of configuration memory with respect to reference design Reduces download time for re-configuration XILINX VIRTEX-5 FPGAS Multi-FPGA-based emulation framework for NoC design and verification (UNLV Networking and System Integration Laboratory) VIRTEX-5 FPGA PLATFORMS Five Virtex-5 Platforms 1. LX- general logic applications 2. LXT- logic with advanced serial connectivity 3. SXT-signal processing applications with advanced serial connectivity 4. TXT- high performance systems with double density advanced serial connectivity 5. FXT- high performance embedded systems with advanced serial connectivity •Over 320,000 PLBs on the largest Virtex-5 •ExpressFabric interconnect sturcture and 12 levels of metal interconnect allowing implementation of complex logic functions allowing connections to neighboring PLBs in few hops than Virtex-4 •Each PLB contains 8 LUTs, 8 configurable memory elements (can be configured as RAM/ ROM/ shift register) •Enhanced DSP functions on 25 x 18-bit multipliers (ability to be cascaded) •Clock managments contain one PLLC and two managers which can drive global VIRTEX-5 CLB A single CLB in Virtex-5 consists of two slices: SLICEL (logic) and SLICEM (memory). Each CLB is connected to a switch matrix which can access to a general routing (global) matrix. Every slice contains four LUTS, wide function MUXs, carry logic, and configurable memory elements. SLICEM support storing data using distributed RAM and data shifting with 32-bit shift registers SLICEL SLICEM FPGA DESIGN COMPARISON VIRTEX-5, VIRTEX-6, AND SPARTAN 6 Virtex-6 CLB have the same setup as Virtex-5 (SLICEL & SLICEM) Virtex-6 devices add four additional storage elements which can only be configured as edgetriggered D-FFs. The D inputs are driven by the output of the LUTs or bypass slice inputs AX-DX FPGA DESIGN COMPARISON VIRTEX-5, VIRTEX-6, AND SPARTAN 6 Spartan-6 CLB columns are separated into two columns: 1 column for a new SLICEX and 1 column for alternating SLICEL and SLICEM. SLICEX is a basic CLB without any carry logic added BACK TO VIRTEX-5 CLB LUT Up to 207, 360 LUTs (6-input) with greater than 13 million configuration bits. Can be configured as dual-output 5-input LUTs. In single 6-input LUT, O6 is the primary output. Inputs to LUT 2 LUT 1 Inputs to LUT 1 & Select Lines LUT 2 Output MUX (A6) Output A5 LUT SCHEMATIC SIMULATION Logical AND Logical OR VIRTEX-5 PROGRAMMABLE I/O The I/O cells in Virtex-5 have output logic blocks (OLOGIC) , input logic blocks (ILOGIC), I/O delays blocks, and a bidirectional I/O buffer. OLOGIC implements registers to improve system clock-to-output timing and supports single data-rate (SDR) and double data-rate (DDR) reception of data. It can also perform parallel-to-serial conversion of output data (2 & 6 bits) in Serial/De-serializer (SerDes) mode. Two I/O cells are grouped to form a single I/O tile. In master/slave mode, two I/O cells in the same I/O tile are connected via dedicated shift routing to support larger data widths. ILOGIC implements registers to improve setup and hold times and support SDR and DDR transmission of data. It can perform serial-toparallel conversion of input data(2 & 6 bits) when in SerDes mode. VIRTEX-5 PROGRAMMABLE I/O FPGA PROGRAMMABLE INTERCONNECTION NETWORK Horizontal and vertical mesh of wire segments interconnected by programmable switches called programmable interconnect points (PIPs). These PIPs are implemented using a transmission gate controlled by a memory bits from the configuration memory. Consists of global routing connecting PLBs to I/O buffers, non-adjacent PLBs, and other embedded components. Local routing connects PLBs to other adjacent PLBs and PLBs to global routing (done through a switch matrix) Several types of PIPs are used Cross-point = connects vertical or horizontal wire segments allowing turns Breakpoint = connects or isolates 2 wire segments Decoded MUX = group of 2^n cross-points connected to a single output configure by n configuration bits Non-decoded MUX = n wire segments each with a configuration bit (n segments) Compound cross-point = 6 Break-point PIPS (can isolate two isolated signal nets) VIRTEX-5 FPGA INTERCONNECTION NETWORK Global routing consists of Long Lines= routing has three connections: beginning, middle, and end. Double lines have five connections into a switch matrix between beginning and end, and can source in all four directions of the FPGA from a switch matrix. Every direction has 10 BEGs, MIDs, and ENDs (all bidirectional) for a total of 240 wire segments per switch matrix. Spans 24 rows/columns of components with a switch matrix connection at every sixth component Double Lines= resources span three columns/rows of components, with a connection to the switch matrix for each component. Hex lines = three connections into a switch matrix similar to long lines. Source in all four directions from switch matrix. Spans six rows or columns of components VIRTEX-5 FPGA INTERCONNECTION NETWORK PIPs HANDS ON DEMONSTRATION FUTURE FPGA DEVELOPEMENT Moore’s law states that the number of transistors on a IC circuit doubles every two years. How to continue with the trend stated by Moore?? 3D Integrated Circuitry 2D INTEGRATED CIRCUIT Metal layer 6 Metal layer 3 Metal layer 2 Metal layer 1 Active device layer Si Substrate TRANSISTORS NO LONGER DOMINATE, METAL INTERCONNECTIONS TOOK OVER DESIGN COSTS INCREASE AS TECHNOLOGY GETS SMALLER IC DESIGNS DECREASE FPGAS SEE DIMINISHING BENEFITS WITH SCALING 90% of FPGA logic area is programmable interconnect Performance and power penalty are direct result of the area (70% Virtex-2) Interconnect needs to increase faster than number of gates to keep up (Rents rule) 10% Interconnect 14% Logic Clocking 16% 60% Dynamic Power in Virtex-2 (Shang FPGA’02) IOB CROSS-TALK INCREASE AS TECHNOLOGY GETS SMALLER 3D INTEGRATED CIRCUITS •More functionality in a smaller space extends Moore’s Law •More transistors in a package larger designs •Shorter Interconnects less RC delays better chip performance •Power Decrease shorter wires reduce power consumption by producing less capacitance (also less inductance) •Bandwith large number of vertial vias between layers allow construction of wide bandwidth buses between functional blocks in different layers 3D INTEGRATE CIRCUIT Metal layers Device layer 2 Metal layers Device layer 1 Si Substrate Young-Su KWON (MIT) 2005 NUPGA® ARCHITECTURE ( ACHIEVE SAME DENSITIES AS AN ASIC DESIGN? Uses a graphite-based memory process for creating reprogrammable memory elements, which is now being used as anti-fuses for 3D FPGAs. Anti-fuses start as an open circuit, but can be reprogrammed to create a low-resistance with a high voltage. Since the anti-fuses lay above the logic, the interconnection density can rival ASICs. The problem is that high voltage programming transistors take up a lot of area negating the density boost. NuPGA claims they have solved that problem by burying the programmable transistors in a 3D foundation layer beneath the FPGA QUESTIONS?