slides
advertisement

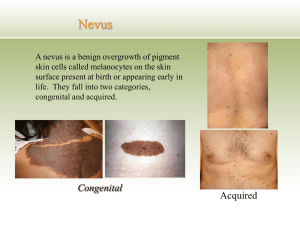
Large Scale Visual Recognition Challenge (ILSVRC) 2013: Classification spotlights Additions to the ConvNet Image Classification Pipeline Andrew Howard – Andrew Howard Consulting Changes to Training: Use more pixels: Train on square patches from rectangular image instead of cropped central square Additional color manipulation of contrast, brightness, color balance used on training patches Use Patches From: Instead of Patches From: Changes to Testing: Make Predictions at different scales and different views which use all pixels Previous: Used 10 predictions (2 flips * 5 translations) This Submission: Used 90 predictions (2 flips * 5 translations * 3 scales * 3 views) The number of predictions can be reduced with no loss of accuracy with stagewise regression View 1: View 2: View 3: Higher Resolution Models: Use a fully trained model and fine tune on image patches from a higher resolution image This can be trained in about 1/3 the number of epochs Predictions on higher resolution images give complimentary predictions to the base model Final Vision System achieves 13.6% error and is made of 5 base models and 5 higher resolution models Structure is the same as last year with fully connected layers twice as large, which doesn’t add much value CognitiveVision team Cognitive Psychology Inspired Image Classification using Deep Neural Network Kuiyuan Yang, Microsoft Research Yalong Bai, Harbin Institute of Technology Yong Rui, Microsoft Research Our Classification Scheme CognitiveVision team Given a image, predict its basic category firstly. Basic Category Classification Dog Easy to distinguish Predict sub category French bulldog Maltese dog Dog Classification … Cat dalmatian tiger cat English setter Egyptian cat Siamese cat Cat Classification … Caffe: Open-Sourcing Deep Learning Yangqing Jia, Trevor Darrell, UC Berkeley • Convolutional Architecture for Fast Feature Extraction – – – – Seamless switching between CPU and GPU Fast computation (2.5ms / image with GPU) Full training and testing capability Reference ImageNet model available • A framework to support multiple applications: Classification Embedding Detection Your next Application! Publicly available at http://caffe.berkeleyvision.org/ Experiments for large scale visual recognition + We tried: Deep CNN (following Krizhevsky et al’12) Low level features &spatial granularities Where did we fail? top 1 acc = 0.567 Appliance and instrument are confusing for us, including - TV vs. Screen, - Coffee mug vs. Cup, - Flute vs. Microphone, -… Television (0.18) Hair spray (0.18) Coffee mug (0.10) Flute (0.10) Agenda 8:30 Classification&localization 8:50 9:20 9:05 9:35 9:50 Spotlights 10:30 Detection 10:50 11:10 11:30 Spotlights 11:40 Noon Discussion panel 14:00 Invited talk by Vittorio Ferrari: Auto-annotation and self-assessment in ImageNet 14:40 Fine-Grained Challenge 2013 http://www.image-net.org/challenges/LSVRC/2013/iccv2013