大数据点滴
advertisement

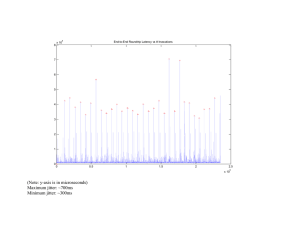
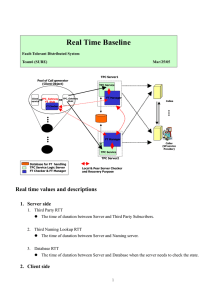
大数据管理与数据质量 - 美国金融业中的对策 汪时奇 (博士) • 处理速度 • 容量限制 • 数据质量 Overview • 数据 <= Data = 信息 (并非数字集合) • 数据科学 (约)= 信息科学 • 为何研究大数据? – 因为相关产品(如硬盘, memory, CPU等)价格指数下降 – 因为信息爆炸 – 因为大数据导致许多新问题 • 大数据研究是多学科的综合(IT, DM, BI, BA, …) • 实业界对大数据问题的对策 (见下文) 1. 数据库策略 • 1.1 Database (DB) performance • 1.2 DB space 1.1 DB performance • • • • • • • Auditing – 2 tables: a small active & a huge passive Partition Index (good/bad; Cluster; Global/Local) Lock type (when apply row lock) Transaction: 1-phase or 2-phase Normalization Internal optimization (e.g. Execution Plan=> hint in Oracle) • Constraints (e.g. Check) usage to replace trigger • Tricks (e.g. Date function; Search small table first; …) 1.2 DB space • Space arrangement for even distribution (e.g. 1 huge table uses a few data files) • Cleaning procedure with defragment • Partition design with cleaning plan 2. Applications (软件) (Java example) • • • • • Using advanced language (e.g. Java or C#) 2.1 Memory(内存) 2.2 Disk/network space 2.3 Performance 2.4 Maintainability 2.1 Memory • Minimize big objects creation and coexistence • GC (Garbage Collection) or null big objects once out of scope – Choose appropriate GC type – gc() • Try to split one big object to small objects • Use mutable class for frequently changed big objects (e.g. StringBuilder, instead of String) 2.2 Disk/network space • Smart clean and archive processes e.g. archive zipped old or not used files to low speed network space and delete very old files from that space • Smart logging settings – e.g. log4j size rolling – e.g. Avoid duplicated or trivial logging info • Monitor for spaces 2.3 Performance • Avoid redundant treatment (in big loops) Maximize reuse • Multi-threading • DB accessing • Logging -- avoid slow options (e.g. line #) 2.4 Maintainability • SOA principles Lose coupling, reusability, granularity, modularity, composability, componentization, interoperability, … • JEE patterns (DAO, DTO, Biz Delegation, …) • Design patterns (23) and MVC – Creation – Structure – Behavior (e.g. Visitor) • OOP principles – Abstraction, encapsulation, polymorphism, … – Open/Close 3. 数据质量控制 • 3.1 Business • 3.2 Process A. Failover & DR (Disaster Recovery) B. QA (Quality Assurance) (see <软件质量管理点滴> for details) C. UAT (User Acceptance Test) • 3.3 Technology 3.1 Business A. Reduce manual work; Increase automation B. Complete approval system for manual work E.g. 1 level => 2 levels or 3 levels approval C. Extend view points to confirm data quality D. Reduce redundancy systems (e.g. due to merge, due to vendors) E. Schedule Cleansing (see details) F. Enhance Reconciliation (see details) G. Build Trust level (see details) H. Try to cover all rare cases 3.1.E Cleansing • When – At system merge – At major change • How – Develop detection applications – Deliver mismatch reports to IT & business – Find solutions on both IT & business 3.1.F Reconciliation • Where – 1+ subsystems have data for same contents. – 1+ subsystems have independent date change functionality. • What – Run & improve recon. app. routinely. – Categorize reports by urgency. – Analyze reports. – Debug or adjust biz rule or apply Cleansing. 3.1.G Trust level • When – At 1+ fixed data inputs – Inputs are independent – Must decide final details from inputs • How (based on) – Provider level (for a detailed data group) – Data history – Samples: Bloomberg, Reuter, Telekurs, DTCC, …; Moody, S&P, Fitch. 3.2.A Failover & DR • Failover – DB: 2+ at diff. locations; real-time replication – App • Active-Active: Cluster with Load Balancing • Active-Passive – Auto (via SAN) – Manual + Auto • DR – DB: e.g. daily or hourly or real-time replication – App: Manual switch 3.3 Technology • DB design – Constraint ‘Check’ (for sensitive table values) – Normalization (to reduce duplications) – Validation processes (to find conflict data) • Application design – Data integration check • E.g. cryptography signature • E.g. CRC check – Data display (e.g. Excel missing leading 0, date=>num)