UNIT 4 Sample problems
White Box Testing Example
Consider the below simple pseudocode:
INPUT A & B
C=A+B
IF C>100
PRINT ―ITS DONE‖
For Statement Coverage – we would only need one test case to check all the lines of the
code.
That means:
If I consider TestCase_01 to be (A=40 and B=70), then all the lines of code will be executed.
Now the question arises:
1. Is that sufficient?
2. What if I consider my Test case as A=33 and B=45?
Because Statement coverage will only cover the true side, for the pseudo code, only one test
case would NOT be sufficient to test it. As a tester, we have to consider the negative cases as
well.
Hence for maximum coverage, we need to consider “Branch Coverage”, which will evaluate
the ―FALSE‖ conditions.
In the real world, you may add appropriate statements when the condition fails.
So now the pseudocode becomes:
INPUT A & B
C=A+B
IF C>100
PRINT ―ITS DONE‖
ELSE
PRINT ―ITS PENDING‖
Since Statement coverage is not sufficient to test the entire pseudo code, we would require
Branch coverage to ensure maximum coverage.
So for Branch coverage, we would require two test cases to complete the testing of this
pseudo code.
TestCase_01: A=33, B=45
TestCase_02: A=25, B=30
With this, we can see that each and every line of the code is executed at least once.
Here are the Conclusions that are derived so far:
Branch Coverage ensures more coverage than Statement coverage.
Branch coverage is more powerful than Statement coverage.
100% Branch coverage itself means 100% statement coverage.
But 100 % statement coverage does not guarantee 100% branch coverage.
Now let‘s move on to Path Coverage:
As said earlier, Path coverage is used to test the complex code snippets, which basically
involve loop statements or combination of loops and decision statements.
Consider this pseudocode:
INPUT A & B
C=A+B
IF C>100
PRINT ―ITS DONE‖
END IF
IF A>50
PRINT ―ITS PENDING‖
END IF
Now to ensure maximum coverage, we would require 4 test cases.
How? Simply – there are 2 decision statements, so for each decision statement, we would
need two branches to test. One for true and the other for the false condition. So for 2 decision
statements, we would require 2 test cases to test the true side and 2 test cases to test the false
side, which makes a total of 4 test cases.
To simplify these let's consider below flowchart of the pseudo code we have:
In order to have the full coverage, we would need following test cases:
TestCase_01: A=50, B=60
TestCase_02: A=55, B=40
TestCase_03: A=40, B=65
TestCase_04: A=30, B=30
So the path covered will be:
Red Line – TestCase_01 = (A=50, B=60)
Blue Line = TestCase_02 = (A=55, B=40)
Orange Line = TestCase_03 = (A=40, B=65)
Green Line = TestCase_04 = (A=30, B=30)
Black Box Testing Techniques
In order to systematically test a set of functions, it is necessary to design test cases. Testers
can create test cases from the requirement specification document using the following Black
Box Testing techniques.
Equivalence Partitioning
Boundary Value Analysis
Decision Table Testing
State Transition Testing
Error Guessing
Graph-Based Testing Methods
#1) Equivalence Partitioning
This technique is also known as Equivalence Class Partitioning (ECP). In this technique,
input values to the system or application are divided into different classes or groups based on
its similarity in the outcome.
Hence, instead of using each and every input value we can now use any one value from the
group/class to test the outcome. In this way, we can maintain the test coverage while we can
reduce a lot of rework and most importantly the time spent.
For Example:
As present in the above image, an ―AGE‖ text field accepts only the numbers from 18 to 60.
There will be three sets of classes or groups.
Two invalid classes will be:
a) Less than or equal to 17.
b) Greater than or equal to 61.
One valid class will be anything between 18 to 60.
We have thus reduced the test cases to only 3 test cases based on the formed classes thereby
covering all the possibilities. So, testing with anyone value from each set of the class is
sufficient to test the above scenario.
#2) Boundary Value Analysis
From the name itself, we can understand that in this technique we focus on the values at
boundaries as it is found that many applications have a high amount of issues on the
boundaries.
Boundary means the values near the limit where the behavior of the system changes. In
boundary value analysis both the valid inputs and invalid inputs are being tested to verify the
issues.
For Example:
If we want to test a field where values from 1 to 100 should be accepted then we choose the
boundary values: 1-1, 1, 1+1, 100-1, 100, and 100+1. Instead of using all the values from 1 to
100, we just use 0, 1, 2, 99, 100, and 101.
Example on Boundary Value Analysis Test Case Design Technique:
Example 1:
Assume, we have to test a field which accepts Age 18 – 56
Minimum boundary value is 18
Maximum boundary value is 56
Valid Inputs: 18,19,55,56
Invalid Inputs: 17 and 57
Test case 1: Enter the value 17 (18-1) = Invalid
Test case 2: Enter the value 18 = Valid
Test case 3: Enter the value 19 (18+1) = Valid
Test case 4: Enter the value 55 (56-1) = Valid
Test case 5: Enter the value 56 = Valid
Test case 6: Enter the value 57 (56+1) =Invalid
Example 2:
Assume we have to test a text field (Name) which accepts the length between 6-12 characters.
Minimum boundary value is 6
Maximum boundary value is 12
Valid text length is 6, 7, 11, 12
Invalid text length is 5, 13
Test case 1: Text length of 5 (min-1) = Invalid
Test case 2: Text length of exactly 6 (min) = Valid
Test case 3: Text length of 7 (min+1) = Valid
Test case 4: Text length of 11 (max-1) = Valid
Test case 5: Text length of exactly 12 (max) = Valid
Test case 6: Text length of 13 (max+1) = Invalid
#3) Decision Table Testing
As the name itself suggests that, wherever there are logical relationships like:
If
{
(Condition = True)
then action1 ;
}
else action2; /*(condition = False)*/
Then a tester will identify two outputs (action1 and action2) for two conditions (True and
False). So based on the probable scenarios a Decision table is carved to prepare a set of test
cases.
For Example:
Take an example of XYZ bank that provides interest rate for the Male senior citizen as 10%
and for the rest of the people 9%.
In this example condition, C1 has two values as true and false, condition C2 also has two
values as true and false. The number of total possible combinations would then be four. This
way we can derive test cases using a decision table.
#4) State Transition Testing
State Transition Testing is a technique that is used to test the different states of the system
under test. The state of the system changes depending upon the conditions or events. The
events trigger states which become scenarios and a tester needs to test them.
A systematic state transition diagram gives a clear view of the state changes but it is effective
for simpler applications. More complex projects may lead to more complex transition
diagrams thus making it less effective.
For Example:
#5) Error Guessing
This is a classic example of Experience-Based Testing.
In this technique, the tester can use his/her experience about the application behavior and
functionalities to guess the error-prone areas. Many defects can be found using error guessing
where most of the developers usually make mistakes.
Few common mistakes that developers usually forget to handle:
Divide by zero.
Handling null values in text fields.
Accepting the Submit button without any value.
File upload without attachment.
File upload with less than or more than the limit size.
#6) Graph-Based Testing Methods
A graph represents the relationships between data objects and program objects, enabling you
to derive test cases that search for errors associated with these relationships.
Steps are
1. Create a graph—a collection of nodes that represent objects,
2. Create links that represent the relationships between objects,
3. Assign node weights that describe the properties of a node (e.g., a specific data value
or state behavior),
4. Assign link weights that describe some characteristic of a link.
Nodes are represented as circles connected by links that take a number of different forms.
A directed link (represented by an arrow) indicates that a relationship moves in only one
direction. A bidirectional link, also called a symmetric link, implies that the relationship
applies in both directions. Parallel links are used when a number of different relationships
are established between graph nodes.
As a simple example, consider a portion of a graph for a word-processing application (in the
below figure) where
Object #1 _ newFile (menu selection)
Object #2 _ documentWindow
Object #3 _ documentText
Referring to the figure, a menu select on newFile generates a document window. The node
weight of documentWindow provides a list of the window attributes that are to be expected
when the window is generated. The link weight indicates that window must be generated in
less than 1.0 second. An undirected link establishes a symmetric relationship between the
newFile menu selection and documentText, and parallel links indicate relationships between
documentWindow and documentText. Then derive test cases by traversing the graph and
covering each of the relationships shown.
How to do Step-wise?
In general, when a systematic process is followed to test a project/application then quality is
maintained and is useful in the long run for further rounds of testing.
The foremost step is to understand the Requirement specification of an application. A
proper documented SRS(Software Requirement Specification) should be in place.
Using the above mentioned Black Box Testing techniques such as Boundary Value
Analysis, Equivalence partitioning etc sets of valid and invalid inputs are identified
with their desired outputs and test cases are designed based on that.
The designed test cases are executed to check if they Pass or Fail by verifying the
actual results with the expected results.
The Failed test cases are raised as Defects/Bugs and addressed to the development
team to get it Fixed.
Further based on the defects being fixed, the tester Retests the defects to verify if it is
recurring or not.
Advantages and Disadvantages
Advantages
The tester need not have a technical background. It is important to test by being in the
user's shoes and think from the user‘s point of view.
Testing can be started once the development of the project/application is done. Both
the testers and developers work independently without interfering in each other‘s
space.
It is more effective for large and complex applications.
Defects and inconsistencies can be identified at the early stage of testing.
Disadvantages
Without any technical or programming knowledge, there are chances of ignoring
possible conditions of the scenario to be tested.
In a stipulated time there are possibilities of testing less and skipping all possible
inputs and their output testing.
A Complete Test Coverage is not possible for large and complex projects.
Difference Between White Box Testing And Black Box Testing
Given below are a few differences between them both:
Black Box Testing
White Box Testing
It is a testing method without having knowledge about It is a testing method having knowledge about the
the actual code or internal structure of the application actual code and internal structure of the application
This is a higher level testing such as functional This type of testing is performed at a lower level of
testing.
testing such as Unit Testing, Integration Testing
It concentrates on the functionality of the system It concentrates on the actual code – program and its
under test
syntax's
Black box testing requires Requirement specification White Box testing requires Design documents with
to test
data flow diagrams, flowcharts etc.
Black box testing is done by the testers
White box testing is done by Developers or testers
with programming knowledge.
Boundary Value Analysis and Equivalence Partitioning explained with a
simple example:
Boundary Value Analysis and Equivalence Partitioning both are test case design strategies in
Black-Box Testing.
Equivalence Partitioning
In this method, the input domain data is divided into different equivalence data classes. This
method is typically used to reduce the total number of test cases to a finite set of testable
test cases, still covering maximum requirements.
In short, it is the process of taking all possible test cases and placing them into classes. One
test value is picked from each class while testing.
For Example, If you are testing for an input box accepting numbers from 1 to 1000 then
there is no use in writing thousand test cases for all 1000 valid input numbers plus other test
cases for invalid data.
Using the Equivalence Partitioning method above test cases can be divided into three sets of
input data called classes. Each test case is representative of a respective class.
So in the above example, we can divide our test cases into three equivalence classes of some
valid and invalid inputs.
Test cases for input box accepting numbers between 1 and 1000 using Equivalence
Partitioning:
#1) One input data class with all valid inputs. Pick a single value from range 1 to 1000 as a
valid test case. If you select other values between 1 and 1000 the result is going to be the
same. So one test case for valid input data should be sufficient.
#2) Input data class with all values below the lower limit. I.e. any value below 1, as an invalid
input data test case.
#3) Input data with any value greater than 1000 to represent the third invalid input class.
So using Equivalence Partitioning you have categorized all possible test cases into three
classes. Test cases with other values from any class should give you the same result.
We have selected one representative from every input class to design our test cases. Test case
values are selected in such a way that largest number of attributes of equivalence class can be
exercised.
Equivalence Partitioning uses fewest test cases to cover maximum requirements.
Boundary Value Analysis
It's widely recognized that input values at the extreme ends of the input domain cause more
errors in the system. More application errors occur at the boundaries of the input domain.
‗Boundary Value Analysis' testing technique is used to identify errors at boundaries rather
than finding those that exist in the centre of the input domain.
Boundary Value Analysis is the next part of Equivalence Partitioning for designing test cases
where test cases are selected at the edges of the equivalence classes.
Test cases for input box accepting numbers between 1 and 1000 using Boundary value
analysis:
#1) Test cases with test data exactly as the input boundaries of input domain i.e. values 1 and
1000 in our case.
#2) Test data with values just below the extreme edges of input domains i.e. values 0 and
999.
#3) Test data with values just above the extreme edges of the input domain i.e. values 2 and
1001.
Boundary Value Analysis is often called as a part of the Stress and Negative Testing.
Note: There is no hard-and-fast rule to test only one value from each equivalence class you
created for input domains. You can select multiple valid and invalid values from each
equivalence class according to your needs and previous judgments.
For Example, if you divided 1 to 1000 input values invalid data equivalence class, then you
can select test case values like 1, 11, 100, 950, etc. Same case for other test cases having
invalid data classes.
This should be a very basic and simple example to understand the Boundary Value Analysis
and Equivalence Partitioning concept.
Some more examples about ECP and BVA
Ex of ECP:
A text field permits only numeric characters
Length must be 6-10 characters long
Partition according to the requirement should be like this:
While evaluating Equivalence partitioning, values in all partitions are equivalent
that‘s why 0-5 are equivalent, 6 – 10 are equivalent and 11- 14 are equivalent.
At the time of testing, test 4 and 12 as invalid values and 7 as valid one.
It is easy to test input ranges 6–10 but harder to test input ranges 2-600. Testing will
be easy in the case of lesser test cases but you should be very careful. Assuming, valid
input is 7. That means, you belief that the developer coded the correct valid range (6 10).
Ex of BVA:
Example 1
Suppose you have very important tool at office, accepts valid User Name and
Password field to work on that tool, and accepts minimum 8 characters and m aximum
12 characters. Valid range 8-12, Invalid range 7 or less than 7 and Invalid range 13 or
more than 13.
Write Test Cases for Valid partition value, Invalid partition value and exact boundary
value.
Test Cases 1: Consider password length less than 8.
Test Cases 2: Consider password of length exactly 8.
Test Cases 3: Consider password of length between 9 and 11.
Test Cases 4: Consider password of length exactly 12.
Test Cases 5: Consider password of length more than 12.
Example 2
Test cases for the application whose input box accepts numbers between 1-1000. Valid
range 1-1000, Invalid range 0 and Invalid range 1001 or more.
Write Test Cases for Valid partition value, Invalid partition value and exact boundary
value.
Test Cases 1: Consider test data exactly as the input boundaries of input domain i.e.
values 1 and 1000.
Test Cases 2: Consider test data with values just below the extreme edges of input
domains i.e. values 0 and 999.
Test Cases 3: Consider test data with values just above the ext reme edges of input
domain i.e. values 2 and 1001.
Here are few sample questions for practice on Equivalence Partitioning and BVA.
Question #1)
One of the fields on a form contains a text box that accepts numeric values in the range of 18
to 25. Identify the invalid Equivalence class.
a) 17
b) 19
c) 24
d) 21
Solution:
The text box accepts numeric values in the range 18 to 25 (18 and 25 are also part of the
class). So this class becomes our valid class. But the question is to identify invalid
equivalence class. The classes will be as follows:
Class I: values < 18 => invalid class
Class II: 18 to 25
=> valid class
Class III: values > 25 => invalid class
17 fall under an invalid class. 19, 24 and 21 falls under valid class. So the answer is „A‟
Question #2)
In an Examination, a candidate has to score a minimum of 24 marks in order to clear the
exam. The maximum that he can score is 40 marks. Identify the Valid Equivalence values
if the student clears the exam.
a) 22,23,26
b) 21,39,40
c) 29,30,31
d) 0,15,22
Solution:
The classes will be as follows:
Class I: values < 24 => invalid class
Class II: 24 to 40
=> valid class
Class III: values > 40 => invalid class
We have to identify Valid Equivalence values. Valid Equivalence values will be there in a
Valid Equivalence class. All the values should be in Class II. So the answer is „C‟
Question #3)
One of the fields on a form contains a text box that accepts alphanumeric values. Identify the
Valid Equivalence class
a) BOOK
b) Book
c) Boo01k
d) Book
Solution:
Alphanumeric is a combination of alphabets and numbers. Hence we have to choose an
option which has both of these. A valid equivalence class will consist of both alphabets and
numbers. Option ‗c‘ contains both alphabets and numbers. So the answer is „C‟
Question #4)
The Switch is switched off once the temperature falls below 18 and then it is turned on when
the temperature is more than 21. When the temperature is more than 21. Identify the
Equivalence values which belong to the same class.
a) 12,16,22
b) 24,27,17
c) 22,23,24
d) 14,15,19
Solution:
We have to choose values from the same class (it can be a valid or invalid class). The classes
will be as follows:
Class I: less than 18 (switch turned off)
Class II: 18 to 21
Class III: above 21 (switch turned on)
Only in Option ‗c‘, all values are from one class. Hence the answer is „C‟. (Please note that
the question does not talk about valid or invalid classes. It is only about values in the same
class)
Question #5)
A program validates a numeric field as follows: values less than 10 are rejected, values
between 10 and 21 are accepted, values greater than or equal to 22 are rejected. Which of the
following input values cover all of the equivalence partitions?
a. 10,11,21
b. 3,20,21
c. 3,10,22
d. 10,21,22
Solution:
We have to select values that fall in all the equivalence class (valid and invalid both). The
classes will be as follows:
Class I: values <= 9 => invalid class
Class II: 10 to 21
=> valid class
Class III: values >= 22 => invalid class
All the values from option ‗c‘ fall under all different equivalence classes. So the answer is
„C‟.
Question #6)
A program validates a numeric field as follows: values less than 10 are rejected, values
between 10 and 21 are accepted, values greater than or equal to 22 are rejected. Which of the
following covers the MOST boundary values?
a. 9,10,11,22
b. 9,10,21,22
c. 10,11,21,22
d. 10,11,20,21
Solution:
We have already come up with the classes as shown in question 5. The boundaries can be
identified as 9, 10, 21, and 22. These four values are in option ‗b‘. So the answer is „B‟
Question #7)
In a system designed to work out the tax to be paid:
An employee has £4000 of salary tax-free.
The next £1500 is taxed at 10%.
The next £28000 after that is taxed at 22%.
Any further amount is taxed at 40%.
To the nearest whole pound, which of these groups of numbers fall into three
DIFFERENT equivalence classes?
a) £4000; £5000; £5500
b) £32001; £34000; £36500
c) £28000; £28001; £32001
d) £4000; £4200; £5600
Solution:
The classes will be as follows:
Class I : 0 to £4000
=> no tax
Class II : £4001 to £5500 => 10 % tax
Class III : £5501 to £33500 => 22 % tax
Class IV : £33501 and above => 40 % tax
Select the values which fall in three different equivalence classes. Option ‗d‘ has values from
three different equivalence classes. So the answer is „D‟.
Question #8)
In a system designed to work out the tax to be paid:
An employee has £4000 of salary tax-free.
The next £1500 is taxed at 10%.
The next £28000 after that is taxed at 22%.
Any further amount is taxed at 40%.
To the nearest whole pound, which of these is a valid Boundary Value Analysis test case?
a) £28000
b) £33501
c) £32001
d) £1500
Solution:
The classes are already divided in question # 7. We have to select a value which is a
boundary value (start/end value). 33501 is a boundary value. So the answer is „B‟.
Question #9)
Given the following specification, which of the following values for age are in the SAME
equivalence partition?
If you are less than 18, you are too young to be insured.
Between 18 and 30 inclusive, you will receive a 20% discount.
Anyone over 30 is not eligible for a discount.
a) 17, 18, 19
b) 29, 30, 31
c) 18, 29, 30
d) 17, 29, 31
Solution:
The classes will be as follows:
Class I: age < 18
=> not insured
Class II: age 18 to 30 => 20 % discount
Class III: age > 30 => no discount
Here we cannot determine if the above classes are valid or invalid, as nothing is mentioned in
the question. (But according to our guess we can say I and II are valid and III is invalid. But
this is not required here.) We have to select values that are in the SAME equivalence
partition. Values from option ‗c‘ fall in the same partition. So the answer is „C‟.
Orthogonal Array Test
What is ?
It‘s used for small number of inputs, but with exhaustive number of possibilities. It‘s a black
box testing with systematic and statistics techniques so, you don‘t need to have the
knowledge of the implementation of the system. The main aim is maximize the coverage by
comparatively lesser number of test cases
Orthogonal arrays can be applied in user interface testing, system testing, regression testing,
configuration testing and performance testing.
What are the benefits?
Precise tests
Generate TestCases more quickly and cheaply
Increase coordination among the team
Easy for managers measure the team‘s performance
Make the analysis simple
Isolate defects
Why don‟t use it ?
As any other technique we can find some negative points:
Testing will fail if you fail to identify the good pairs
Probability of not identifying the most important combination which can result in losing
a defect
This technique will fail if you do not know the interactions between the pairs
Applying only this technique will not ensure the complete coverage
It can find only those defects which arise due to pairs, as input parameters
So, you need to choose wisely because not all the applications will suit in this technique, this
depends of the behaviour of your application. You need to measure the priority points of the
project as well, like if you want to cover 100% of the tests of cover a good part of the tests
and save a lot of time…
How to use it ?
1. Identify the independent variables. These will be referred to as ―Parameter x‖
2. Identify the values which each variable will take. These will be referred as ―Test Case x‖
3. Search for an orthogonal array that has all the factors from step 1 and all the levels from
step 2
4. Map the factors and levels with your requirement
5. Translate them into the suitable test cases
6. Look out for the left over or special test cases (if any)
Examples:
If we have 3 parameters, each can have 3 values then the possible Number of tests using
conventional method is 3^3 = 27
While the same using OAT, it boils down to 9 test cases.
The array is orthogonal, because all possible pair-wise combinations between parameters
occurs only once.The given L9 Orthogonal Array assess result of test cases as follows:
Single Mode Faults - Single mode faults occur only due to one parameter. For example, in
above Orthogonal array if test cases 7, 8 and 9 show error, we can expect that value 3 of
parameter 1 is causing the error. Likewise we can detect as well as isolate the error.
Double Mode Fault - Double mode fault is caused by the two specific parameters values
interacting together. Such an interaction is a harmful interaction between interacting
parameters.
Multimode Faults - If more than two interacting components produce the consistent
erroneous output, then it is a multimode fault. Orthogonal array detects the multimode faults.
Cyclomatic complexity
CYCLOMATIC COMPLEXITY is a software metric used to measure the complexity of a
program. It is a quantitative measure of independent paths in the source code of the program.
Independent path is defined as a path that has at least one edge which has not been traversed
before in any other paths. Cyclomatic complexity can be calculated with respect to functions,
modules, methods or classes within a program.
This metric was developed by Thomas J. McCabe in 1976 and it is based on a control flow
representation of the program. Control flow depicts a program as a graph which consists of
Nodes and Edges.
In the graph, Nodes represent processing tasks while edges represent control flow between
the nodes.
Flow graph notation for a program:
Flow Graph notation for a program defines several nodes connected through the edges.
Below are Flow diagrams for statements like if-else, While, until and normal sequence of
flow.
How to Calculate Cyclomatic Complexity
Mathematical representation:
Cyclomatic complexity is calculated using the control flow representation of the program
code.
In control flow representation of the program code,
Nodes represent parts of the code having no branches.
Edges represent possible control flow transfers during program execution
There are 3 commonly used methods for calculating the cyclomatic complexity-
Method-01:
Cyclomatic Complexity = Total number of closed regions in the control flow graph + 1
Method-02:
Cyclomatic Complexity = E – N + 2
Here E = Total number of edges in the control flow graph
N = Total number of nodes in the control flow graph
Method-03:
Cyclomatic Complexity = P + 1
Here,
P = Total number of predicate nodes contained in the control flow graph
Note
Predicate nodes are the conditional nodes.
They give rise to two branches in the control flow graph.
PRACTICE PROBLEMS BASED ON CYCLOMATIC COMPLEXITYExample-01:
Calculate cyclomatic complexity for the given codeIF A = 354
THEN IF B > C
THEN A = B
ELSE A = C
END IF
END IF
PRINT A
SolutionWe draw the following control flow graph for the given code-
Using the above control flow graph, the cyclomatic complexity may be calculated asMethod-01:
Cyclomatic Complexity
= Total number of closed regions in the control flow graph + 1
=2+1
=3
Method-02:
Cyclomatic Complexity
=E–N+2
=8–7+2
=3
Method-03:
Cyclomatic Complexity
=P+1
=2+1
=3
Example-02:
Calculate cyclomatic complexity for the given code{ int i, j, k;
for (i=0 ; i<=N ; i++)
p[i] = 1;
for (i=2 ; i<=N ; i++)
{
k = p[i]; j=1;
while (a[p[j-1]] > a[k] {
p[j] = p[j-1];
j--;
}
p[j]=k;
}
SolutionWe draw the following control flow graph for the given code-
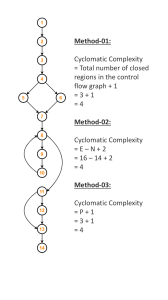
Using the above control flow graph, the cyclomatic complexity may be calculated asMethod-01:
Cyclomatic Complexity
= Total number of closed regions in the control flow graph + 1
=3+1
=4
Method-02:
Cyclomatic Complexity
=E–N+2
= 16 – 14 + 2
=4
Method-03:
Cyclomatic Complexity
=P+1
=3+1
=4
Example-03:
Calculate cyclomatic complexity for the given code1. begin int x, y, power;
2. float z;
3. input(x, y);
4. if(y<0)
5. power = -y;
6. else power = y;
7. z=1;
8. while(power!=0)
9. { z=z*x;
10. power=power-1;
11. } if(y<0)
12. z=1/z;
13. output(z);
14. end
SolutionWe draw the following control flow graph for the given code-
Using the above control flow graph, the cyclomatic complexity may be calculated asMethod-01:
Cyclomatic Complexity
= Total number of closed regions in the control flow graph + 1
=3+1
=4
Method-02:
Cyclomatic Complexity
=E–N+2
= 16 – 14 + 2= 4
Method-03:
Cyclomatic Complexity
=P+1
=3+1
=4
Example 04 i = 0;
n=4; //N-Number of nodes present in the graph
while (i<n-1) do
j = i + 1;
while (j<n) do
if A[i]<A[j] then
swap(A[i], A[j]);
end do;
i=i+1;
end do;
Flow graph for this program will be
Computing mathematically,
V(G) = 9 - 7 + 2 = 4
V(G) = 3 + 1 = 4 (Condition nodes are 1,2 and 3 nodes)
Basis Set - A set of possible execution path of a program
1, 7
1, 2, 6, 1, 7
1, 2, 3, 4, 5, 2, 6, 1, 7
1, 2, 3, 5, 2, 6, 1, 7
Properties of Cyclomatic complexity:
Following are the properties of Cyclomatic complexity:
1.
2.
3.
4.
V (G) is the maximum number of independent paths in the graph
V (G) >=1
G will have one path if V (G) = 1
Minimize complexity to 10
How this metric is useful for software testing?
Basis Path testing is one of White box technique and it guarantees to execute atleast one
statement during testing. It checks each linearly independent path through the program,
which means number test cases, will be equivalent to the cyclomatic complexity of the
program.
This metric is useful because of properties of Cyclomatic complexity (M) 1. M can be number of test cases to achieve branch coverage (Upper Bound)
2. M can be number of paths through the graphs. (Lower Bound)
Example 05 If (Condition 1)
Statement 1
Else
Statement 2
If (Condition 2)
Statement 3
Else
Statement 4
Cyclomatic Complexity for this program will be 8-7+2=3.
As complexity has calculated as 3, three test cases are necessary to the complete path
coverage for the above example.
Steps to be followed:
The following steps should be followed for computing Cyclomatic complexity and test cases
design.
Step 1 - Construction of graph with nodes and edges from the code
Step 2 - Identification of independent paths
Step 3 - Cyclomatic Complexity Calculation
Step 4 - Design of Test Cases
Once the basic set is formed, TEST CASES should be written to execute all the paths.
More on V (G):
Cyclomatic complexity can be calculated manually if the program is small. Automated tools
need to be used if the program is very complex as this involves more flow graphs. Based on
complexity number, team can conclude on the actions that need to be taken for measure.
Following table gives overview on the complexity number and corresponding meaning of v
(G):
Complexity Number
Meaning
1-10
Structured and well written code
High Testability
Cost and Effort is less
10-20
Complex Code
Medium Testability
Cost and effort is Medium
20-40
Very complex Code
Low Testability
Cost and Effort are high
>40
Not at all testable
Very high Cost and Effort
Uses of Cyclomatic Complexity:
Cyclomatic Complexity can prove to be very helpful in
Helps developers and testers to determine independent path executions
Developers can assure that all the paths have been tested atleast once
Helps us to focus more on the uncovered paths
Improve code coverage in Software Engineering
Evaluate the risk associated with the application or program
Using these metrics early in the cycle reduces more risk of the program
Example 06:
Let a section of code as such:
A = 10
IF B > C THEN
A=B
ELSE
A=C
ENDIF
Print A
Print B
Print C
Control Flow Graph of above code
The cyclomatic complexity calculated for above code will be from control flow graph.
The graph shows seven shapes(nodes), seven lines(edges), hence cyclomatic complexity is
7-7+2 = 2.
Example 07:
IF A = 10 THEN
IF B > C THEN
A=B
ELSE
A=C
ENDIF
ENDIF
Print A
Print B
Print C
FlowGraph:
The Cyclomatic complexity is calculated using the above control flow diagram that shows
seven nodes(shapes) and eight edges (lines), hence the cyclomatic complexity is 8 - 7 + 2 =
3
Example 08:
Solution:
1. V(G) = RNumber of regions = 4 , so Cyclomatic Complexity =4
2. V(G) = Predicate node(P) +1 = 3+1 = 4
3. V(G) = E-N+2 = 11 edges – 9 nodes + 2 = 4
Example 09 and solution:
Example 10 and Solution:
Example 11 and Solution:
Control Structure testing.
Control structure testing is a group of white-box testing methods.
1.0 Branch Testing
1.1 Condition Testing
1.2 Data Flow Testing
1.3 Loop Testing
1.0 Branch Testing
also called Decision Testing
definition: "For every decision, each branch needs to be executed at least once."
shortcoming - ignores implicit paths that result from compound conditionals.
Treats a compound conditional as a single statement. (We count each branch taken out
of the decision, regardless which condition lead to the branch.)
This example has two branches to be executed:
IF ( a equals b) THEN
statement 1
ELSE
statement 2
END IF
This examples also has just two branches to be executed, despite the compound
conditional:
IF ( a equals b AND c less than d ) THEN
statement 1
ELSE
statement 2
END IF
This example has four branches to be executed:
IF ( a equals b) THEN
statement 1
ELSE
IF ( c equals d) THEN
statement 2
ELSE
statement 3
END IF
END IF
Obvious decision statements are if, for, while, switch.
Subtle decisions are return boolean expression, ternary expressions, try-catch.
For this course you don't need to write test cases for IOException and OutOfMemory
exception.
1.1 Condition Testing/Branch Testing
Condition testing is a test construction method that focuses on exercising the logical
conditions in a program module.
Errors in conditions can be due to:
Boolean operator error
Boolean variable error
Boolean parenthesis error
Relational operator error
Arithmetic expression error
definition: "For a compound condition C, the true and false branches of C and every simple
condition in C need to be executed at least once."
Multiple-condition testing requires that all true-false combinations of simple conditions be
exercised at least once. Therefore, all statements, branches, and conditions are necessarily
covered.
Branch Testing Example
/** Branch Testing Exercise
* Create test cases using branch test method for this program
*/
declare Length as integer
declare Count as integer
READ Length;
READ Count;
WHILE (Count <= 6) LOOP
IF (Length >= 100) THEN
Length = Length - 2;
ELSE
Length = Count * Length;
END IF
Count = Count + 1;
END;
PRINT Length;
Decision
Possible Outcomes
T
F
T
F
Count <= 6
Length >= 100
1
X
2
X
Test Cases
4 5 6 7 8 9 10
3
X
X
X
Test Cases
Case #
1
2
3
Input Values
Count Length
Expected Outcomes
5
101
594
5
99
493
7
99
99
Actual Outcomes
1.2 Data Flow Testing
Data Flow Testing is a type of structural testing. It is a method that is used to find the test
paths of a program according to the locations of definitions and uses of variables in the
program.
It
has
nothing
to
do
with
data
flow
diagrams.
It is concerned with:
Statements where variables receive values,
Statements where these values are used or referenced.
To illustrate the approach of data flow testing, assume that each statement in the program
assigned a unique statement number. For a statement number SDEF(S) = {X | statement S contains the definition of X}
USE(S) = {X | statement S contains the use of X}
If a statement is a loop or if condition then its DEF set is empty and USE set is based on the
condition of statement s.There are two types of USE(S), 1. Computation use (C_USE/C) and
predicate use (P_USE/P). A def-use association is a triple (x, d, u,), where:
x is a variable,
d is a node containing a definition of x,
u is either a statement or predicate node
containing a use of x, and there is a sub-path in the flow graph from d to u with no other
definition of x between d and u.
Data Flow Testing uses the control flow graph to find the situations that can interrupt the
flow of the program.
Reference or define anomalies in the flow of the data are detected at the time of associations
between values and variables. These anomalies are:
A variable is defined but not used or referenced,
A variable is used but never defined,
A variable is defined twice before it is used
Advantages of Data Flow Testing:
Data Flow Testing is used to find the following issues To find a variable that is used but never defined,
To find a variable that is defined but never used,
To find a variable that is defined multiple times before it is use,
Deallocating a variable before it is used.
Disadvantages of Data Flow Testing
Time consuming and costly process
Requires knowledge of programming languages
Example 1:
1. read x, y;
2. if(x>y)
3. a = x+1
else
4. a = y-1
5. print a;
Control flow graph of above example:
Define/use of variables of above example:
VARIABLE DEFINED AT NODE USED AT NODE
x
1
2, 3
y
1
2, 4
a
3, 4
5
Example 2:
Example 3:
1.3 Loop Testing
Loops are fundamental to many algorithms and need thorough testing.
There are four different classes of loops: simple, concatenated, nested, and unstructured.
Examples:
Create a set of tests that force the following situations:
Simple Loops, where n is the maximum number of allowable passes through the
loop.
o Skip loop entirely
o Only one pass through loop
o Two passes through loop
o m passes through loop where m<n.
o (n-1), n, and (n+1) passes through the loop.
Nested Loops
o Start with inner loop. Set all other loops to minimum values.
o Conduct simple loop testing on inner loop.
o Work outwards
o Continue until all loops tested.
Concatenated Loops
o If independent loops, use simple loop testing.
o If dependent, treat as nested loops.
Unstructured loops
o Don't test - redesign.
Example
Statements and conditions of a sorting program (except for ``end'' statements) will be
labelled as below
S1
i := 2
C1
while (i is less than or equal to n) do
S2
j := i - 1
C2
while ((j is greater than or equal to 1) and
(A[j] is greater than A[j+1])) do
S3
temp := A[j]
S4
A[j] := A[j+1]
S5
A[j+1] := temp
S6
j := j-1
end while
S7
i := i + 1
end while
This program contains two nested while-do loops. Let's assume that this program is supposed
to be able to sort arrays of length at least 100. Then both the inner and outer loop should be
tested on inputs of ``moderate'' sizes (say, some size between 40 and 60), as well as on sizes
1, 2, 99, and 100. In order to keep the number of iterations of the inner loop at ``typical''
values while trying to control the number of iterations of the outer loop, it will probably be
sufficient to start with an array with distinct elements whose entries are ordered in a random
way. In order to keep the number of iterations of the inner loop at a ``minimal'' value, use an
input array that is already sorted in increasing order. In order to keep the number of iterations
of the inner loop at a maximal value, you should use an input array with distinct entries, that
are initially sorted in decreasing order instead of increasing order.
The test that will be added to ensure that the inner loop body is executed twice is as follows.
Test #1
Inputs: n = 3; A[1] = 3, A[2] = 2, A[1] = 1
Expected Outputs: A[1] = 1, A[2] = 2, A[3] = 3
Test #2
Inputs: n=51, A[i] = i for i between 1 and 50, and A[51] = 0
Expected Outputs: A[i] = [i-1] for i between 1 and 51
Test #3
Inputs: n=99,
A[i] = 1 if i is between 1 and 98 and is even,
A[i] = 2 if i is between 1 and 98 and is odd,
A[99] = 0
Expected Output:
A[1] = 0,
A[i] = 1 if i is between 2 and 50,
A[i] = 2 if i is between 51 and 99
Test #4
Inputs: n = 100, A[i] = 101 - i for i between 1 and 100
Expected Outputs: A[i] = i for i between 1 and 100
Test #5
Inputs: n = 101,
A[i] = 2 if i is between 1 and 50,
A[i] = 1 if i is between 51 and 100,
A[101] = 0
Expected Outputs:
A[1] = 0,
A[i] = 1 if i is between 2 and 51,
A[i] = 2 if i is between 52 and 101
Graph Matrices
To develop a software tool that assists in basis path testing, a data structure.
A graph matrix is a square matrix whose size is equal to the number of nodes on
the flow graph. Each row and collumn corresponds to an identified node, and
matrix entries correspond to connections between nodes.
Example: