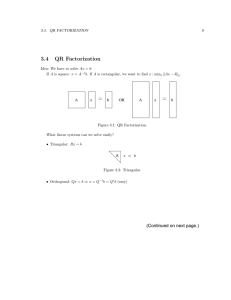
16-APRIL-2022 DEEP LEARNING ASSIGNMENT #2 ZAINAB IFTIKHAR CMS: 242240 Group-2 Question 1: If we use a RNN to predict the next character in a text sequence, what will be the required dimension of any output? If the size of the vocabulary used in the RNN for language modelling is n, the dimension of the required output will be nx1 which will be a one hot vector giving the next character, which will have the highest probability of occurrence given the previous sequence of characters. Question 2: Why RNN’s express conditional probability of a token at some time step t, based on all the previous tokens in the text sequence? The basis of RNN is to have contextual memory. They use the current state at any given time along with the history of all previous states to find out what the next state could possibly be. This is done by giving the probability of all possible next states given previous states. Therefore, the next state is dependent on current and previous states. And thus, RNNs show conditional probability of a particular state or token at some time t based on previous information. Question 3: What are some of the problems associated with the language model described below. As the model does not use a bidirectional RNN layer, it will not be able to capture and utilize semantic information in its operations. It also won’t perform well in term of time and resource complexity in case of long text sequences. Question 4: Derive the equations of the gradient loss function of the weight W at the initial cell state C0 with respect to all the other cell/hidden states in the following figure. Don’t know how to do this.