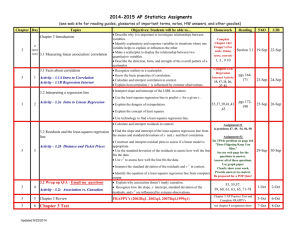
Chapter 7 Introduction to Linear Regression Ch. 7: Introduction to Linear Regression Learning Objectives 1) Choose a linear model of the relationship between two variables 2) Use the correlation to analyze the usefulness of the model 3) Deal with nonlinear relationships 7.1 The Linear Model Example: The scatterplot below shows monthly computer usage for Best Buy verses the number of stores. How can the company predict the computer requirements if they decide to expand the number of stores? 7.1 The Linear Model Example (continued): We see that the points don’t all line up, but that a straight line can summarize the general pattern. We call this line a linear model. This line can be used to predict computer usage for more stores. 7.1 The Linear Model Residuals A linear model can be written in the form yˆ b0 b1 x where b0 and b1 are numbers estimated from the data and ŷ is the predicted value The difference between the predicted value and the observed value, y, is called the residual and is denoted e ˆ e y y 7.1 The Linear Model In the computer usage model for 301 stores, the model predicts 262.2 MIPS (Millions of Instructions Per Second) and the actual value is 218.9 MIPS. We may compute the residual for 301 stores. y yˆ 218.9 262.2 43.3 7.1 The Linear Model The Line of “Best Fit” Some residuals will be positive and some negative, so adding up all the residuals is not a good assessment of how well the line fits the data If we consider the sum of the squares of the residuals, then the smaller the sum, the better the fit The line of best fit is the line for which the sum of the squared residuals is smallest – often called the least squares line 7.1 The Linear Model 7.2 Correlation and the Line Straight lines can be written as y b0 b1 x. The scatterplot of real data won’t fall exactly on a line so we denote the model of predicted values by the equation yˆ b0 b1 x The “hat” on the y will be used to represent an approximate value 7.2 Correlation and the Line For the Best Buy data, the line shown with the scatterplot has the equation that follows yˆ 833.4 3.64 Stores A slope of 3.64 says that each store is associated with an additional 3.64 MIPS, on average An intercept of –833.4 is the value of the line when the x-variable (Stores) is zero. This is only interpreted if it has a physical meaning 7.2 Correlation and the Line 7.2 Correlation and the Line 7.2 Correlation and the Line 7.2 Correlation and the Line 7.2 Correlation and the Line We can find the slope of the least squares line using the correlation and the standard deviations b1 r sy sx The slope gets its sign from the correlation. If the correlation is positive, the scatterplot runs from lower left to upper right and the slope of the line is positive The slope gets its units from the ratio of the two standard deviations, so the units of the slope are a ratio of the units of the variables 7.2 Correlation and the Line To find the intercept of our line, we use the means. If our line estimates the data, then it should predict y for the x-value x . Thus we get the following relationship from our line y b0 b1 x We can now solve this equation for the intercept to obtain the formula for the intercept b0 y b1 x 7.2 Correlation and the Line Least squares lines are commonly called regression lines. We’ll need to check the same condition for regression as we did for correlation. 1) Quantitative Variables Condition 2) Linearity Condition 3) Outlier Condition 7.2 Correlation and the Line Getting from Correlation to the Line If we consider finding the least squares line for standardized variables zx and zy, the formula for slope can be simplified b1 r sz y szx 1 r r 1 The intercept formula can be rewritten as well b0 z y b1 z x 0 r 0 0 7.2 Correlation and the Line Getting from Correlation to the Line From the values for slope and intercept for the standardized variables, we may rewrite the regression equation zˆ y rz x From this we see that for an observation 1 standard deviation (SD) above the mean in x, you’d expect y to have a z-score of r 7.2 Correlation and the Line For the variable Monthly Use, the correlation is 0.979. We can now express the relationship for the standardized variables zˆMonthlyUse 0.979 z Stores So, for every SD the value of Stores is above (or below) its mean, we predict that the corresponding value for Monthly Use is 0.979 SD above (or below) its mean 7.2 Correlation and the Line 7.2 Correlation and the Line 7.2 Correlation and the Line 7.2 Correlation and the Line 7.3 Regression to the Mean The equation below shows that if x is 2 SDs above its mean, we won’t ever move more than 2 SDs away for y, since r can’t be bigger than 1 zˆ y rz x So, each predicted y tends to be closer to its mean than its corresponding x This property of the linear model is called regression to the mean 7.3 Regression to the Mean One Correlation but Two Regressions For two variables, x and y, there is only one correlation coefficient, r but there are two regression lines: one in which x is the explanatory variable and one in which y is the explanatory variable 7.4 Checking the Model Models are only useful only when specific assumptions are reasonable. We check conditions that provide information about the assumptions. 1) Quantitative Data Condition – linear models only make sense for quantitative data, so don’t be fooled by categorical data recorded as numbers 2) Linearity Condition – two variables must have a linear association, or a linear model won’t mean a thing 3) Outlier Condition – outliers can dramatically change a regression model 7.5 Learning More from the Residuals The residuals are part of the data that hasn’t been modeled. Data Predicted Residual Residual Data Predicted We have written this in symbols previously. e y yˆ 7.5 Learning More from the Residuals Residuals help us see whether the model makes sense A scatterplot of residuals against predicted values should show nothing interesting – no patterns, no direction, no shape If nonlinearities, outliers, or clusters in the residuals are seen, then we must try to determine what the regression model missed 7.5 Learning More from the Residuals The plot of the Best Buy residuals are given below. It does not appear that there is anything interesting occurring. 7.5 Learning More from the Residuals The standard deviation of the residuals, se, gives us a measure of how much the points spread around the regression line We estimate the standard deviation of the residuals as shown below se e 2 n2 The standard deviation around the line should be the same wherever we apply the model – this is called the Equal Spread Condition 7.5 Learning More from the Residuals In the Best Buy example, we used a linear model to make a prediction for 301 stores The residual for this prediction is –43.3 MIPS while the residual standard deviation is –24.07 MIPS This indicates that our prediction is about –43.3/24.07 = –1.8 standard deviations away from the actual value This is a typical size for residual since it is within 2 SDs 7.6 Variation in the Model and R2 The variation in the residuals is the key to assessing how well a model fits. Consider our Best Buy example. Monthly Use has a standard deviation of 117.0 MIPS. Using the mean to summarize the data, we may expect to be wrong by roughly twice the SD, or plus or minus 234.0 MIPS The residuals have a SD of only 24.07 MIPS, so knowing the number of stores allows a much better prediction 7.6 Variation in the Model and R2 All regression models fall somewhere between the two extremes of zero correlation or perfect correlation of plus or minus 1 We consider the square of the correlation coefficient r to get r2 which is a value between 0 and 1 r2 gives the fraction of the data’s variation accounted for by the model and 1 – r2 is the fraction of the original variation left in the residuals 7.6 Variation in the Model and R2 r2 by tradition is written R2 and called “R squared” The Best Buy model had an R2 of (0.979)2 = 0.959. Thus 95.9% of the variation in Monthly Use is accounted for by the number of stores, and 1 – 0.959 = 0.041 or 4.1% of the variability in Monthly Use has been left in the residuals 7.6 Variation in the Model and R2 How Big Should R2 Be? There is no value of R2 that automatically determines that a regression is “good” Data from scientific experiments often have R2 in the 80% to 90% range Data from observational studies may have an acceptable R2 in the 30% to 50% range 7.7 Reality Check: Is the Regression Reasonable? • The results of a statistical analysis should reinforce common sense • Is the slope reasonable? • Does the direction of the slope seem right? • Always be skeptical and ask yourself if the answer is reasonable 7.8 Nonlinear Relationships A regression model works well if the relationship between the two variables is linear What should be done if the relationship is nonlinear? 7.8 Nonlinear Relationships To use regression models: Transform or re-express one or both variables by a function such as: •Logarithm •Square root •reciprocal What Can Go Wrong? • Don’t fit a straight line to a nonlinear relationship • Beware of extraordinary points • Look for y-values that stand off from the linear pattern • Look for x-values that exert a strong influence • Don’t extrapolate far beyond the data • Don’t infer that x causes y just because there is a good linear model for their relationship • Don’t choose a model based on R2 alone •Be sure to get the regression the right way around What Have We Learned? • Linear models can help summarize the relationship between quantitative variables that are linearly related • The slope of a regression line is based on the correlation, adjusted for the standard deviations in x and y • For each SD a case is away from the mean of x, we expect it to be r SDs in y away from the y mean • Since r is between –1 and +1, each predicted y is fewer SDs away from its mean than the corresponding x • R2 gives us the fraction of the variation of the response accounted for by the regression model •Transform the variables to convert a nonlinear relationship to a linear one to use linear regression