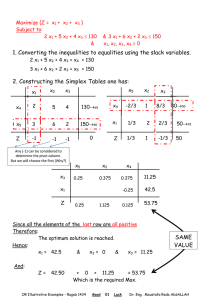
Jie Liu: It's a great pleasure to welcome Sherief...
advertisement

Jie Liu: It's a great pleasure to welcome Sherief Reda from Brown University. He's visiting us today and he's been doing research on power and thermal management on both the chip level and the data center level. And today he's primarily going to talk about the data center level. But be very interesting. On the chip level management things we can chat off-line as well. Shief Reda: Thanks a lot for the introduction and thanks for organizing this visit and initiating it. I'm happy to be here today. Is this mic working or it's not working? Jie Liu: It should be working. Shief Reda: All right. So as he mentioned, I have a number of projects going on; mostly the deal with power, energy, thermal, different places in the stacks of the computing. That mean -- the first research theme is an adaptive energy-efficient computing systems. And by adaptive in here, I mean things that can be applied during runtime. When we started this project, we were looking basically at techniques at the chip level, thermal and power management at the chip level. And eventually we moved on to server level, and then eventually to datacenter level. So that's going to be mainly the focus of this talk. And in fact I'll just be talking about half of it, the part we worked on, the datacenter, which is relatively recent. The second theme that I work on is thermal and power sensing and modeling for processers system on a chip, other computing systems and computing forms, and that's actually where a big bulk of my lab infrastructure is in with grants from UED's and other places. This is for instance, a high-end infrared camera that we used to look at the thermal distribution inside the chip. And for instance, I will show here a realtime video typically. All right. Yep, so this is a realtime video actually from a dual core AMD processor. And this is the thermal map. It usually goes up to 55 degrees, the red and the blue is usually around 35 degrees. I just can't save it with the video. You can see the dual core modules from the infrared camera. What's happening in here, this is the spec Java, spec power SHA workload. So what's happening, you're seeing the Java threads being launched and then we're responding to a query from online and then terminating. And with the infrared sensing, you can see -- I mean you can see the caches, you can see the memory controller, you see the L1 caches in here. So you can actually see the thermal gradients. This is in realtime. So this is a starting point for many of our research including quantifying hotspots. If you're going to put embedded thermal sensors on the chip, before you should put them, because you have to limit the budget for them. We also have a big research project on inverting these temperature maps into power maps so you can actually see what's underlying, what's the power consumption of the different units of the processor. >>: Realtime? Shief Reda: This is Realtime. >>: So basically if the temperature changes [inaudible] -Shief Reda: Yeah, because the thread launches and goes down quickly. So if you have a spec application, if you have a regular spec CPU, it's not going to change like this. It's just going to launch a hotspot and stay as this. It's the nature of this workload. That's why we created that video, because the threads launch in a couple of seconds and then they die off. But other applications want to have this. >>: What is the variance in temperature? Shief Reda: So usually when it peaks like this -- as I said, I couldn't save it to the [indiscernible] but it's about like 55 in here, maybe 35 in here. >>: Wow. Shief Reda: Yeah, so this is a big project and you can actually also -- imagine applications in security where people are trying to insert malicious entries in your circuit, you can detect them with the thermal infrared imaging. So this is a lot of big project in here I work on. I won't be talking about today, but it's a big project. Another big project is low power design techniques and CAD tools. The main project we work on is approximate computing. So approximate computing is a way to trade off accuracy in some applications that allow you like machine learning and computer vision, et cetera. With some reductions in power consumption. And there's a lot of interesting approximate computing and there is different scales you can work on in the computing stack. So you can design circuits that are approximate. That's one thing you can do. Or you can do application. So you can rechange your software, restructure your software. And I think there's a lot of applications in datacenters. I think potentially eventually I would like to merge these two, because we can't imagine large-scale approximate computations happening in datacenters, and you really get a big savings on power consumption. So these are the main three projects. I'll mostly talk about the first one. And I'd like to first acknowledge the people that I work with. These are only the students who worked on this first project. There are other students working on the other one. So some of them graduated, some of them are working on it right now. I also have a league at BU. I show that our club rate with -- especially in the first part of the stock, the pack and cap technique. The rest of the stuff was mainly at Brown. So we usually write proposals together. So what's the big goal in here? The big goal is that -- big goal shared by many researchers is that we want to design energy efficiency, and this goal means that we would like to maximize the total performance of the datacenter while meeting a dynamic total power budget. And a total power budget in here is basically computing and cooling simultaneously. We maybe want to meet a certain cap. There is a cap for the datacenter and we want to meet it. And there are a number of reasons why this problem has to be considered from a dynamic sense. One of them, obviously there are a few things, but one of them is the variance in demand over time. The datacenter -- demand for the datacenter is changing over time. This is data collected from a computing cluster at Brown over 2010, and I'm sure everybody has similar traces. Also, applications themselves change their power consumption over time. They go through different phases and change their power consumption, which means that you might have some settings that are [Indiscernible] you the budget, but over time you see some drift and you're not able to meet this power consumption. >>: What [Indiscernible]. Shief Reda: It's relatively highly utilized. >>: Do you cluster or something? Shief Reda: No, it is not a cluster. This is actually a big computing facility at Brown and researchers submit their job. So instead of everybody getting their own clusters, it's more like batch. >>: [Indiscernible]. >>: Could you go back one slide? I'm curious here. Because you're saying energy efficient datacenters; right? And then you talk about a power budget. Shief Reda: Right. >>: If -- because you're forced to stay within the budget, you have to run things slower. So you end up consuming more energy, not less. Shief Reda: Right, but sometimes -- I will explain actually there's a third reason. If you don't have any concern for power consumption, then as you're saying you could be consuming the least amount of energy. But sometimes you actually want to adhere to a certain cap. And the reason for this is particularly the third one. So many datacenters are connected to the grid and the grid has energy markets you can participate in. And if you want to participate in that energy market, the smart grid or the grid operators will send you a regulation signal that tells you "please regulate your power consumption to a certain level." And if you do, then you get back an energy incentive, you get reduced rates, you get back money. So there's a lot of demand for this dynamic power caps. But you're absolutely right. There's a chance that if you run at the lowest level, you could spend more energy. >>: The main reason, I think right, the fact that you can over subscribe on a datacenter by putting in more servers than it was actually designed for because you have the ability to limit the power is probably more of a factor than the low response stuff; right? Shief Reda: That's another possibility too. So that will tie in with point number one. You're doing this over-provisioning to be able to handle those variations, but sometimes you don't need it. But at the end of the day, if the power budget is the maximum and you want to maximize your performance within this power budget. So that's the energy efficiency, performance over power; so if I -- say you have to consume, say, one megawatt, then you still want to maximize the performance within this megawatt. There are so many ways you can get to the one megawatt, but what is the best way to go through with it. So that's why we always consider this power budget within our work. We don't consider -- we don't want to just maximize performance within the maximum power budget, but potentially within lower power budgets. So what are the degrees of freedom we have during runtime? There's obviously things you can do during planning, like purchasing how many servers you would like to have. But from our runtime point perspective, what do we have? So there are a few degrees of freedom. One of them is that the servers could have power cap controllers. Each server you can tell it consume no more than 150 Watt, and it will adhere to this power consumption. If you have I heterogenous datacenter, things become more interesting, because which workloads goes to which server is going to determine performance, energy, and power, and maybe different servers offer different tradeoffs for different applications. And also, different servers could be -- maybe one is best for performance, maybe one is the least power, maybe one is the highest energy efficiency and so forth. So this is another runtime degree of freedom. Workload co-runners, you could choose to co-run applications on the same server, or you could make sure there's no degradation by just running a single workload. Virtual machine migration. Maybe you do this mapping initially, but then eventually this favorite server for the blue circle is now free. So you can actually start migrating things to it to leverage that usage. The CRAC supply temperature. The CRAC supply temperature is going to determine your pulling power. And that's another degree of freedom you have in your data systems. So what we want to do is to adaptively determine these degrees of freedom in a data system to actually improve energy efficiency. Of course it's challenging, because all of these degrees of freedom are highly interacting and there's a lot of dependencies in between them. So when we try to do sort of a road map for these degrees of freedom, that's how things would look like. And let's see in their the degrees of freedom and their applicability. And there's two domains, homogeneous clusters where all the servers in your clusters have the same configuration, and heterogenous clusters where you actually have different racks, which one with its own server configuration. So the cap controller is applicable to both of them, co-runners is applicable to both of them, workload mapping is really mostly irrelevant for this one, unless you consider cooling into the process. Virtual migration is also applicable only for heterogeneous. Cooling is applicable for both of them. And of course workloads is another degree of freedom really. You can control it, but the way you look at these degrees of freedom will change depending on the workloads that you're running. And you actually look at most of the literature and most of the papers in the literature, you can easily map them into some of these combinations in here. These combinations that are highlighted are actually the ones that I'm working on. This is all work in progress. So we're trying to still do a better integration for all of these degrees of freedom. >>: So the mechanisms for managing power are under the cap controller? Shief Reda: So I will actually talk about cap controller techniques, I'll talk about techniques with corunners and mapping. So all these ones that have this highlight are ones that I will talk about. >>: Have you looked at utilization scenarios? Because I suspect that we in migration will be useful when you try to consolidate [indiscernible]. Shief Reda: So we will see some results on that. The short answer is there will be a difference. Because if you have low utilization, sort of every workload comes and gets its favorite server and you don't need to migrate afterwards. But if you have a high utilization, the jobs comes to the datacenter and in that case you don't have many free servers. So you allocate it to something that is free. But then that opens the rooms for migration afterwards. So it is indeed true that the migration will have different quantitative advantage as a function of your utilization. And I will show this later on in a slide. So this is the overview of the technique that I explained. I will start with a technique that we worked on first for energy efficiency of server, just if you have a server, what would you do. Then I'll move on to a cluster, which is just servers. And eventually then I'll talk about a whole datacenter, and I just mean in here, really it's the cluster plus the cooling equipment. So these are the three parts of the talk and this is how it's going to be structured. So let's look first at the server level management technique, if you want to look at the energy efficiency of maximize performance within a budget. So traditionally the trade-off between performance on power consumption by a server is achieved by using dynamic voltage scaling, also known as the Pstate. By controlling the P-state, you're controlling your performance and power. Many modern servers actually have power cap controllers that can sense the power consumption, say, once every one or two seconds. And you can give the server hardware a certain power cap, and then the firmware in the server on the controller will adjust the P-state or the dynamic voltage of frequency scaling accordingly. It's a very simple mechanism. If you are above the cap, then decrease DVFS until you have a cap. If you're below the cap, then increase your DVFS or P-state, because you're not delivering the best performance, so increase it until you meet the cap. So that's the classical design that's being used right now. And it's mainly done in hardware. >>: That assumes the workload is CPU bound; right? [indiscernible] Shief Reda: And actually that would be one of the things we're going to leverage in the rest of the talk. So problem, it ignores the software. And it ignores the fact that we have multi cores and multi threading. So when we started this project, we thought can we devise better power management techniques by looking at both the software and the hardware in conjunction. >>: So what are the symptoms of that problem? Shief Reda: So the symptoms will appear when you look at the advantage of the technique [Indiscernible]. It's going to come up right now. You're going see like "okay." So in here, we don't just have -- DVFS is a great freedom. We actually have the number of threads. So for instance, if I launch my application with just one thread, I'll get a different power consumption than if I launch it on four threads. So this mean really the DVFS and the number of threads should be both of them considered in basically determining my power consumption. And that's even true if that threads belongs to workloads that are not even like doing something in common with each other. So what we advocate is actually controlling the number of threads in DVFS, but controlling the number of threads adaptively during runtime is not an easy task. So what we do instead is launch the application as usual states of four core, launch with the four threads, and then we apply what we call thread packing. So thread packing meaning that I have four threads in here, and then in that case if I want to switch to a lower power mode I can pack the four threads into three cores, basically by setting the affinities of the three threads to these cores. And by doing that, four core become idle, basically, and the clog gating mechanisms in the processer will automatically shut this core down saving some power consumption. And you can apply DVFS still on top of it. And if I would like to be more aggressive, I can pack four threads into two cores. And eventually if I really would like to be more aggressive, I can pack four threads into one core. So by applying this packing, plus DVFS, we can get better power capping and power management technique. So that's what we call this technique pack and cap, and it appeared in micro a few years back, two, three years ago. >>: Do you consider the increase in temperature on the core that you're concentrating stuff on? Shief Reda: The temperature does increase a little bit. But actually the temperature of this core will slightly increase. Could be a degree. It's a good point. But keep in mind that when you have all the threads running and all the cores, the whole ship overall is consuming a lot of power. So really the temperature of this core would be its own -- coming from its own power plus the heat diffusion. >>: It's more like a hotspot as opposed to having a temperature that's running across [indiscernible]. Shief Reda: It's an important question. But let's say imagine the thread is running in here. The question is this thread running this core to full utilization? If it's running at full utilization and you pack those things, then you're switching from sort of space multiplexing into time multiplexing, and that time multiplexing is not going to necessarily increase the power of this core's temperature. However, if this thread was IO dominated and you get some time where the core is not running, then moving something in there will increase its utilization and increase its temperature. But if it's a regular thread, then effectively by doing this, we actually found that it's no different than launching just one thread on that one core in terms of performance. >>: It will take longer. Shief Reda: It will take longer to finish. >>: [indiscernible]. Shief Reda: So this will go next. So we'll show this. So let's first look at the first benefit from the one disk compared to just DVFS. So let's look at one metric, which is the dynamic power range. Which is if I launch application, what's the highest power it can consume and what's the lowest power it can consume? So with the traditional technique, DVFS, the difference would be basically the highest -- the difference between the highest DVFS setting, this one, minus the lower power setting, and this gives me about 5 watts in the servers. But by applying this packing techniques from top of DVFS, we see those purple lines are actually achieving larger power range. We're able to go into lower deep states because we're packing things, so we're increasing -- we're extending the power range. So this is on a 4 core processor. And if you have an 8 core processor with two different sockets, it becomes more interesting, because as you start packing things into one socket, you're even make the first socket totally idle in that you can shut it down entirely. So you can actually get a larger 40 percent improvement in dynamic power range. So larger power range basically meaning better energy proportionality. But everybody saying the server's basically don't have good energy proportionality. By doing this technique, you're actually able to extend the range even further. Let me show ->>: Is this real results? Shief Reda: This is a real server. This is the real results. >>: So how -- I'm curious, how hard is it to move the thread that's running from one core to another, or is it potentially [indiscernible]? Shief Reda: It's very easy. >>: How sticky are these cores? Shief Reda: It's easy. There's a functional operating [indiscernible] it's called [indiscernible] affinity and you give it the process ID and you give it the set up cores that you prefer it to run on. >>: Right. Shief Reda: So you can even set it at -- it's affinity not just to one core, you can say run on two cores, or run or three cores. So it's relatively easy. >>: And it's pretty instantaneous, is it? Shief Reda: I mean it's certainly within the time limits of the kernels [indiscernible]. >>: Every five milliseconds. Shief Reda: Yeah. So DVFS is in the micro second. You change it to DVFS this one, change it to the millisecond. >>: And you got to dig the cache misses to [indiscernible] -Shief Reda: Yeah, that's a good point. Yeah. And in fact it becomes even trickier if you have multiple sockets. Because if you have [indiscernible], you have no uniform memory access, then switching it to a socket that doesn't have its data would be harder, yeah. So let's look at this data in more detail. So let's take one applications in here from this PARSEC benchmark and launch it with eight threads, it's called black [Indiscernible], and then we configure it to pack it in one core, two cores, four cores, et cetera. And then for each configuration, we look at the power consumption in here. This is just a small slice of it. And this is a hundred billion instructions. And look at the runtime. So every point in here correspond to, you know, we have two degrees of freedom, the number of cores and the DVFS. So every one of those represents the change in the DVFS while one core is active. In here two cores are active and then we change DVFS, over in here is eight cores, and you change DVFS. So the one thing becomes clear is my previous slide. You see the range. If I'm having it at eight threads and I change DVFS, this is power range that I get, the smaller arrow. But if I'm able to pack things then I extend my power range, I'm able to go down with the server all the way down to 120. So I can achieve lower power caps if required for my datacenter or from servers. The main question is, if we say we want to cap the power consumption, say, at 140 watts, it's different than DVFS. Now, there are so many combinations or pair of settings that you can use to achieve that cap. So when you have multiple choices, now it becomes interesting, because one choice will actually give you the best performance. So this is what we're after for right now is things are becoming more interesting. You have a bigger search space. So what we did is that we plotted the Pareto frontier, which basically the settings along the [indiscernible] line would give you the best data between one time and power consumption. So the optimal settings basically would be on this Pareto frontier. And the question is how can we figure out this Pareto frontier. So let's take a look in here. Say you don't have any limits in your power consumption, you're running with eight active threads on eight cores, and then you want to cut down power consumption. Let's see what's happening to the Pareto frontier? Is it moving across the cores or is it moving at first at DVFS? It seems it's -- it seems it's better that if you want to cut power, it's better to cut it with DVFS than to move across the cores to cut it. That give you the better runtime, the better performance. So as you go down in here, you try to cut DVFS first; at some point DVFS will run out of steam, then you switch, reduce the cores as least as possible. So you just move a little bit in here, and then play a game, the DVFS game. So it seems that it's better for performance to keep a larger number of cores than to actually have a higher DVFS. >>: What kind of [indiscernible]. Shief Reda: What is what? >>: Thread synchronization. Shief Reda: Threads synchronization? So we're not doing anything. We're just leaving -- oh, this one, this is from the PARSEC application. So there -- I think the MP thread, the -- sorry. >>: The P threads? Shief Reda: Yeah, the P threads. >>: But is this spinning or blocking? Shief Reda: Well, each application will have its own programs. >>: If this spinning synchronization, right, it would make sense that you would prefer to stay on multiple cores. Shief Reda: Okay. >>: Right? Because as you concentrate more, these guys are going to be spinning, waiting for things that are not going to happen because the other threads are not running. Shief Reda: Right, so we've seen -- so I'll tell you something in here. Actually I'll come to this point later. But I haven't seen anything of the PARSEC benchmarks. Their behavior changed a little bit. But I've never seen a single instance where you actually prefer to use DVFS over the number of cores. So it's a little bit -- so there could be a chance that there's a system out there with 16 thread and the programmer writes it in such a way, or maybe it's two cores or four cores, but a limited number of cores, and you do aggressive packing, and maybe the programmer did not try the core in such a right way. >>: I think the issue is the implementation of the P threads; right. If it's spinning implementation, the result will probably be different than a blocking implementation, or synchronization. Shief Reda: Probably there's a good chance -- I mean in all cases the program will work. We're not talking about ->>: Yeah I know, it's just a matter of how long it's going to -Shief Reda: Yeah, yeah, exactly. Yeah. All right. So let's look at the other slides. Suppose I have the least power cap and I actually try to increase it. Well, let's look at in here, whenever I had some rule to increase the number of cores, the Pareto frontier just suddenly jumped to the other one. So this is a critical point in here. I have some increase in my power budget, it didn't go up there, it actually preferred to increase the number of cores. So that gives us our big idea in here for the Pareto frontier is that the settings we need to maximize the performance for a given cap is that you actually want to activate the largest number of cores that you can allow within the cap before you actually try to increase DVFS. And this observation is repeated across all the PARSEC benchmarks, all of them have the same kind of behavior. So let's give us the idea for our approach, the first approach. The first approach is that this is our server we have right now, two degrees of freedom, DVFS, a number of cores. We going to have some control of it, which I call the multi-gain controller. We can measure power consumption. Say that's the one approach. And then you have a power cap. And the difference will be given to this and this controller will tweak the number of DVFS on cores. So the trick is that if you have a negative power slack, meaning that you're consuming more than the cap, then you actually want to cut down DVFS before you start to degrade the number of cores. Because we said if you want to maximize performance, you want the highest number of cores. And if you have a positive power slack, meaning that you are consuming below the cap, then to improve performance, you actually want to engage, increase the number of active cores before you actually increase DVFS. So that's the -- so you see how it's working. But it's the same -- it's a different strategy, but it boils down to the same concept, that you want to maximize the cores before the frequency. >>: But the reaction could be quite different; right? Increasing the DVFS is easy, right? You're not changing anything. The setting of a different number of cores, this allow that system [indiscernible]. Shief Reda: Like Ricardo was saying, the cache is for instance ->>: Right. So you can't afford to make that kind of mistake. Because you can't predict how much the power consumption is going to be. You can give it more cores, oh, it's too high and drop down and give it more -Shief Reda: So actually you want to -- so actually it's different. When you want to give it more power, you increase the number of cores; but you want to go down, you will say I keep my cores, I try to decrease DVFS. So if you have a positive power slack, increase the number of active cores. And then suddenly power caps go down and you say I have to reduce my power, then go in DVFS first. Try and reduce the DVFS. Because it's the number of cores that you want to maximize. It's -- think about that number of cores is the first priority you want to be using. >>: So I'm looking at, for example, the job featuring one core or two core, the job end set, the lowest DVFS to two cores. And if that's high, too high for whatever the cap is, you have to drop back. Shief Reda: So you have to reduce first DVFS. And if you reach the lowest DVFS, you say okay, I give up, there's nothing I can do except cutting down the cores. Then you switch the number of cores. >>: Okay. Shief Reda: But there is -- I think what you're trying to say is if I jump here immediately and I know at the bottom there's nothing I can do except suggest the cores ->>: Yeah. Shief Reda: Yeah. So if you're at the bottom already of the DVFS, then you will have to switch back to one core. >>: You wanted to be pretty conservative and give it more cores. Shief Reda: Yes. The other big question is how often things are going to change. If things are going to change by ten seconds, maybe the millisecond like you were mentioning in the operating system is not going to be an issue. But if your, actually, power cap is changing at a higher rate, then that's a problem. >>: These benchmarks that you test, I assume, stress the CPUs. Shief Reda: These are classic benchmarks. They have a good range. Some of them do stress, some of them are more memory bound. Some of them are scalable, meaning you increase the number of threads and performance increase linearly. Some of them are not scalable, they have synchronization issues, so you try to scale them and the runtime doesn't increase as much. So they have a good variety, those PARSEC benchmarks. >>: So if you -- say you're running eight cores in ten second utilization, and then you want to just reduce the amount of power by -- power capping such [indiscernible]. Do you see any difference between what you're doing here and what the operating system should do ordinarily with power management enabled? Because the OS will be cold parking. Shief Reda: I think the operating system will actually -- I think most right now will just use DVFS. They won't play any of those tricks with the number of threads and packing them or anything. Right now the assignment from threads to cores is based on fairness basically. >>: You said, I believe, those well-packed cores, it will consolidate threads. Shief Reda: Okay. >>: If the utilization of the OS -Shief Reda: The utilization, not power. >>: Yeah. [indiscernible] >>: So it would be interesting if you have a load utilization test to see sort of the comparison between OS on its own versus [indiscernible]opinion. Shief Reda: What I've seen is the operating system at least for the Linux kernel is always one of -between fairness, between the cores, that's what it's trying to do. >>: So you tried to sort Windows 7 -- [indiscernible]? Shief Reda: No, not Windows 7. >>: And these applications tend to run full tilt on the CPU; right? It might be that their memory bound, but as far as the operation system is concerned -Shief Reda: You don't get utilization 10 percent. >>: Yeah. Shief Reda: So we're talking about ->>: So it's sort of like what we do with ->>: For you to do that, you'd have to use like fewer threads than cores. Shief Reda: Yeah, exactly. Yeah. Yeah. So in that case, it's already packed in some way. So, okay, that's a good point. If you're saying what you're saying, if I manage between two active threads and I have eight cores, then in that case there's no reason for the operating system to try and maintain fairness by switching the threads around. Because that's what the operating system do. I see it with a camera, it switches the threads around from the cores, not for thermal, but to maintain fairness between the cores. So you don't want to do that. You want to pack them ->>: So I'm just looking. I think XP used to do that, and then Windows 7 changed that. Shief Reda: So another thing is this multi-gain controller, is this idea that the impact of changing a setting, say DVFS platform number, of course is actually the function of the value of the other setting. So for instance, if I have eight active cores and I change my DVFS, that's how the power is going to change. So the average impact of the change is 5.61. And it's going to determine the gain of my controller. That's impact. I want to see should I increase DVFS by one setting, two settings. And that's the average gain. However, if I have one active core, and you're not getting the change in power consumption, the average consumption is 0.9 Watt. It makes sense. But the idea in here is that I can't just have a controller with one gain -- actually my gain would be a function -- my gain for DVFS is a function of how many active cores I have. Same things apply on the other side. If I fix my DVFS and try to change the number of cores, say from one to eight, the average impact for power increase on the server is about 9.9 Watt. But if I'm running at a low frequency and I try to increase the number of active cores, then the average impact is 6.1. So really you have a lot of combinations in here and for each one you have to characterize and see what the other value to figure out the average gain. >>: Why is it the most gaining -Shief Reda: What is that? >>: Why is there any scaling? Why is everything not scaled? Shief Reda: Because you have just one active core and you're changing it. So think about -- say here you have active cores eight; right? Let's multiply 8 by .9. You're actually getting close to that number. It's just that you have so many of them so they add up a lot. Because you have more active cores. So this is just inherently what the change of one core of power. But if you have a whole bunch of them, then their power will aggregate and it will become big. >>: And [indiscernible] compared to power. Shief Reda: How is what? >>: How would the [indiscernible] as opposed to power. Shief Reda: So the energy is the runtime, and the power tradeoff that I -- I think it was a few slides back. It was in here. So that's how different power is going to look like. But the goal is to maximize performance within a certain power cap. So that give us the idea for the multi-gain controller. And some servers actually don't have a power meter. So you have an instrument on the server, some old one or some very low sensing. But we done techniques where you can basically project the impact of the settings on the power consumption. And many people here from this group also did techniques where you can model power consumption without a power. And the basic idea is that you have some performance counter saying the CPU that will give you the toolkit and operating system metric like utilization, memory, IO, disk transfer. And then you can combine those to learn off-line some metrics. And those metrics would link basically the DVFS and the number of active cores with power, and you can use this as a proxy for the power meter. And basically during runtime you would query this model with the different possible settings that you're thinking of. So if you have nine DVFS settings on four cores, I have 36 combinations. And you can use this model to evaluate the power consumption for the 36 combination, and then from this combinations I would see the one that consume less than the power cap and which is the winner. The winner would be the one that has the highest number of cores, because that's what we want to do, we want to traverse this Pareto frontier. So we will always select that combination in here from the model that gives the highest number of course, before DVFS. So let's look at some quick results. This is just -- I mean we have so many detailed results, but this is just a quick overview. This is just a baseline controller. We want to compare our technique with something else, so we said let's implement a baseline controller that uses just a single gain like people do. And it almost prioritizes DVFS. So instead of -- it's going to change both of them, but always plays with DVFS. So as a result it's not going to be working on the Pareto frontier. >>: So what do you mean by a single gain controller? This is a BID controller? Shief Reda: Yes, standard controller where you just have, you want to change DVFS, then you just have one gain irrespective of how many active cores you have. >>: I see. So but for a BID control, there's -Shief Reda: Yeah. We actually don't use an I. It's only a P controller in here. P controllers are good enough. Because there's no integration for the area. A P/I controllers are good when you're getting integration, like data accumulates. In here ->>: I'm surprised that the D is not involved either. Shief Reda: Well, there's no -- it just works. I'll show you some results. >>: Okay. Shief Reda: So this is the standard technique. It doesn't work -- there's a big error tracking error, which is the difference between the cap. So let me explain this in detail. In here in this experiment we basically changed the cap randomly every five, I think, or six seconds. So basically the blue line is the power cap of the server, the red line is the actually power consumption from the server, using this technique. And we're actually showing, during this runtime, the frequency and the active number of cores. So this is from what people would have thought should be implemented like. This is our pack and cap controller. So you see very accurate tracking in here. And because it has this multi-gain controller, it basically reduces the power tracking error to 37.5 percent. And the actual runtime, if we finish these applications all to the end, all the application, you will see that we, on the average, we have less -- 10 percent less runtime. And the reason for the lower runtime is basically we try to follow this Pareto frontier, this idea of trying to maximize the number of cores before DVFS. >>: So here, it's still a proportional controller, you just change the game that -Shief Reda: That's a function of the other setting. Yeah. And implementing this idea of trying to maximize the cores before DVFS. >>: Almost like -Shief Reda: It's a closed loop. So this one is the closed loop, this one. >>: I know this was -Shief Reda: Yeah. >>: So the result has the power meter in it. Shief Reda: Yeah, the this one has the power meter. These first two ones have the power meter. This is just like a reference for us to show that we are indeed doing better by throwing this Pareto frontier. This one is without the power meter. So there's no power meter connected to the system, we changed the power cap. But we can model power. So actually this works really well. This one kind of fell off, but for the rest, it's actually going up and down. And there's no power meter associated with it. >>: Well, that's a big problem. If you go 10 seconds [laughter]. Shief Reda: But still, for no meter, it's still a good deal. >>: Well, circuit's still going to break and [indiscernible] [laughter]. Shief Reda: And if you assume that the errors from different servers are like one is high, one is low, then maybe they will add up to zero. Over all, you obviously have higher error than if you have the meter. You also get less reduction over time. But overall, it's actually working pretty well. >>: You should probably have some emergency thing, right, that if you realize that you have not been able to lower the environment exception, you just go down and -Shief Reda: Yeah, you just default it to some low value. >>: Right, because that over there is [indiscernible] [laughter]. Shief Reda: I think -- I was impressed that it was still without a meter. So that's techniques we've seen to increase energy efficiency of a single server by using the software and hardware techniques. So let's do things, upgrade things a little bit and then move to a cluster level power management. So for cluster level power management, I will talk about two parts. One of them is homogenous and one of them, when it becomes more interesting, and you have heterogeneous clusters. So for a single server, quantifying performance is easy, it's runtime. How are we going to do it for a datacenter? So this is from the literature and this is what we think is one of the best way to characterize performance is you look at the actual application normalize performance. Meaning that you look at the ratio between the runtime in the ideal case of execution, meaning by its own self at the highest power cap, versus the runtime at some other condition which is not idle. So that's the application normalize performance. The whole performance of the datacenter, the system normalize performance, will be the arithmetic average for the ANP. Some people also use the geometric average. We didn't really see any difference with both of them. So you can use the SNP. If you use reciprocals of the ANP, that's the slow down mode. That gives you sort of how much applications are slowing down on the average from your policy. Another good metric is unfairness which is the standard deviation on the ANP's. If you have a standard -- big standard deviation, then you're unfair in some way, because you're having more things than other ones. So these are the metrics we're considering for a cluster. So let's look at the easiest scenario for cluster management. All your servers are basically identical. So there's no inherent advantage from sending different workload to different servers. You can pick any server and send it to, if you ignore cooling. The main degree of freedom in here that you can play with is how much power you're going to give to each server. So assuming in here these servers have this power cap controllers, and the question is how much you give to each one of them. So maybe people will say, "Well, take the whole power budget, one megawatt, you have 10,000 servers, you know, give each one 100 watts uniformly." That's not really the best way to go about allocating or budgeting power on a cluster. Why is that? Because you have ->>: It's not feasible. [Indiscernible]. Shief Reda: Huh? >>: The best way is not feasible. There's a big packing problem. Shief Reda: Yeah, so this is -- I'll actually show in a little bit. So the idea in here, it's actually more of a knapsack problem, that's what we found. The idea you don't want to do this uniformly is that because basically different applications will have different characteristics and they will translate power that you give to them differently. So these are power servers, they have the same identical configuration. But they're running different applications from second PARSEC benchmarks. And you see that for each one of them when you give it more power cap, basically the ANP or the performance changes in a different way. So this means really your formula is not the best strategy. I should give it in a different way. So for instance, like you were saying, memory-bound applications usually do not leverage increases in power to increase in performance, so maybe I shouldn't give them too much power to begin with. So need to find a better way to budget the power. So let's look at scenario in here and what people did. Let's say I have four servers, the same four servers, and I only have a budget of 520 watts. So that's really the floor of my power consumption, because it means that each server will get 130 watts to leave the least power cap that I can ever get. Suppose now that there's some good news and the company wants to spend more; so in that case we have 600 watts. So 80 more watts that we have available to budget among these servers. What can we do. One of the techniques in the literature, the greedy technique basically ranges the server by their energy efficiency, meaning it looks at -- it divides the performance by the power and start allocating these extra power consumption based on the energy efficiency of the server. Where servers that are more energy efficient will actually get more power. Because we think that they're energy efficient, so in that case they can leverage it. So in that case, the most energy efficient is this one, we'll give it 35 watts, minus the 80, I still have [indiscernible]. Let's go to the next one, it's .68. We'll give it also another 35, so that's 70 out of my 80 watts. There are 10 left. I give it to the next energy efficient, this one, and then finally this one will not get anything. And if we do this, this will be the ANP that you will get. Can we do better? Can we do better than that? >>: That policy seems to be [indiscernible]. Shief Reda: Yeah. Well, we'll see that we have good improvements over it, so this is indeed counterintuitive. So let's imagine we actually have all these values. If we can actually have that ANP or the performance for the different power caps, can we do better? And like you guys were already heading, we actually can think of the knapsack problem. So if I'm a thief and I have a knapsack with a certain weight and I have some items each with a value and a weight, I want to basically pack those items into the bag to maximize my value so we can think that this problem is connected to ours. In that case really each item is basically a server and a workload combo. And in that case it has multiple choices for power. So for each choice there's a power, that's the weight, and there's a value, which is the performance. And I want to pack -- I want to make my choices for each item to maximize the total performance, the total value subject to a given power budget. So that's the knapsack problem. So if we add these values and solve the knapsack problem, these are the actual optimal choices that will come up, which indeed shows that it was counter-intuitive for the greedy to do this choice. And we could get in this simple case 13 percent improvement in performance. >>: So how much profiling do you have to do to get this table? Shief Reda: So that will be my next couple of slides. So how can we get those values? Those values are unknown to begin with. So how can we fill those entries? So that's a big challenge. So we have to do some modeling in here. So the idea is basically we can capture the characteristic, the ANP versus power, say with a function like this, a quadratic function. So this quadratic function is giving us the performance of a certain workload on a server, as a function of that power cap that you give. Now these model co-efficients, people in the past have thought of them as fixed value. If you have just one kind of workload, then they are fixed in value, but if you have different workloads, then these co-efficients are really going to be capturing those characteristics of the application. So what we are doing is we're actually having -- those co-efficients are actually being functions themselves of the application characteristics. So what are those characteristics we look at? At any time you're running the server, you are actually have three characteristics that you can capture, and we actually use this to successfully have those as dynamically changing. One of them is the number of instruction executed per second by the server, which is basically corresponding to utilization. The other one is its current power consumption. That's another important value. Another important metric is the last level, cache misses. So last level cache miss is an indicator of how memory-bound your application is. And by incorporating those three metrics, we can actually determine values for those coefficients that are actually a function of the application characteristics. So if you go back to our example, let's say you have some power caps right now that are running and this is the ANP of the servers. Well, in that case, here is our ANP predictor. And at those running points you collect the through-put, you collect the power and the LOC. These are measurable and available. You send them to the predictor. Oops, where is it? Why is this? Why is the transmission not working? What happened in here? Sorry about that. I don't know why it's not -Okay, you send those characteristics to the ANP predictor. The ANP predictor is going to use them. Here it is, okay. You send those values in there, and then the ANP predictor is going to calculate those predictions, and once you have those predictions, you can run the knapsack -- multi-choice knapsack algorithm to get the ultimate results. So this is ->>: How long does it take to do that for a fairly large cross search? Shief Reda: So the runtime will be proportional. I mean the runtime of the DP is basically the number of power caps you have times the number of servers. So it's all of ->>: So number of servers or number of server types? Shief Reda: Number of servers. >>: So [indiscernible]. Shief Reda: Yeah, you could. We can say -- you could lose a little bit of efficiency. I mean you want to trade up both of them. You can divide your datacenter into sub-clusters and solve the problem for each sub-cluster. So you lose a little bit of the global picture, but you manage the runtime. It's also a function of how often you want to change the power caps. It would be a function of how often, say, the smart -- the grid is telling you to regulate your power consumption. So that's another factor. This is a result in here, unlike the Part 1 where we built everything in a real server, I don't have a cluster, so we actually have a queuing simulator for 320 servers, and that queuing simulator is using execution traces from the actual server. So we collect execution traces that are through-put, the LLC, the power consumption over time, and various sampling rates for the application, and then we use it in part of our queuing simulator. So when we compare this -- first of all, we apply different power budget and we adjust the power caps, and we look at the SNP, and the bottom line in here is the uniform and greedy results, and then above and atop of it is our approach, the predictor plus the knapsack. And the Oracle plus knapsack, here it is, the upper bound. If you really truly know the actual values in the table, how much performance would you get? So that gives you an upper bound for what the supports is doing. Eventually if you have a really, really, really low power cap, or a really, really, really high power cap, all these algorithms are going to behave in the same way, because you will give them as much power as they need or you will just starve them from power. It's really the range in between in here where these algorithms start to diverse from each other. So that gives us about 4.4 improvement in the SNP over the greedy method that was proposed. And if obviously greedy is not really doing good with [indiscernible] with respect to applications, so we improve the fairness dramatically. And that's actually important because in some cases datacenter assign us a service level agreement where it starts - tries to basically makes things more consistent. So that's another important metric. >>: How is that fairness measured again? Shief Reda: It's the standard deviation of the ANPs. >>: The SNP sounds like a good metric, but could you give a little more explanation about what is the impact of 4 percent improvement or how useful it is or -Shief Reda: You're getting 4.4 percent improvement in performance free. Because you're respecting the same power budget. So you can twist it the other way, meaning I can reduce my power while maintaining my performance. Right? So you can think of it two way depending on what you care about. Do you want to maintain the same performance and cut power? Or do you want to maintain the certain power while maximizing performance with it. >>: So this is an SNP for the fully clustered -Shief Reda: For all the clusters. >>: So it's actually multiplied by 4 percent of whatever kilowatts you have. Shief Reda: Exactly, exactly. So it's not just -- that's the nice thing about datacenter, it gets multiplied. So but we can get much better improvements that are 4 point -- I think still it's pretty good for a datacenter, because that's a large amount of savings. But we can do better if you have a heterogeneous cluster. So I'll explain some techniques right now that's the second part for the cluster. And we're proposing something in here more dramatic for heterogeneous clusters. So for heterogeneous clusters, I'm assuming in here of course that you're -- there's a number of reason why you would have heterogeneous clusters. One of them is some applications could be good for a certain kind of servers, but not good with the other, and some applications are good for this one, but not good for this one. You also have multiple updates and multiple deployment cycles in the datacenter, so there actually is a chance there will be clusters of different machines. And assume of course that when you go purchasing, you purchase them by the racks so the servers within the same rack need to be all kind of the same configuration. So what's happening in here is that workloads come and we can assume we have their characteristics, if they've been running in the datacenter for a while and we don't, or you can predict them. And in that case our HetMan jobs catalog basically will map those applications periodically to the free servers in here, and it tries to map it to, say, maximize the performance within a power budget. It can also map them as single workloads in free server or it can map them to busy servers, say, with 50 percent utilization. If you have a co-runner, if you enable co-runners, and you can have multiple cores on leverage, then it can also do core running. Periodically, every once in a while on a much longer timescale, HetMan would actually reassess the whole mapping of workloads in the center and essentially shuffle things around if it can give you better results. And the reason it would do this, it's maybe that the first choice in here, when you map an application to a free server, maybe it did not pick the best free server for it. >>: So when it's reassigning the workload, is it changing the power cap for each server? Shief Reda: Okay ->>: Or a power cap for each server and then -Shief Reda: So I actually did not include the power cap in this one. So for a homogeneous server, the power cap was my only degree of freedom, so I used it over there. In here I thought we actually have the possibility to map the jobs around to maintain the power without actually touching the power cap. So I'm assuming in here that servers will be running at their highest power cap. But this is an area that I think potentially could be included. The degrees of freedom in here I'm choosing are mapping and core running and migration. So these are the three degrees of freedom. So I'm not playing with the power caps in here any more. Because I think that we can meet a certain power budget by just assigning things around, without touching the power cap. But I think it's definitely relevant and we want to do it. I'm telling my students we need to include the cap controllers in here too. >>: So in here what is the goal here? Is it to -Shief Reda: The same goal we have always, maximize the performance per power budget. Except ->>: So power budget is whatever the power budget that has been given to that server. Shief Reda: Exactly, to the cluster. Just like -- so in the knapsack that was the goal in here; right? We had a power budget for the whole cluster and we were distributing it among the servers to maximize >>: That's exactly my question. In this next setup -Shief Reda: In this setup, instead of using the power caps, we will leverage the fact that we have multiple servers with multiple powers performance tradeoffs and we can leverage that to achieve the same effect. >>: Okay. Shief Reda: Good questions. All right, so let's look at the first one in here is that you're engaging, you get some jobs in this queue, and very frequently, you're mapping this jobs in the queue into the free servers. So this looks like the classical [indiscernible] matching problem. It's very similar to it. You want to match the things in here and one part of the graph to the other one to maximize your performance. But there's a little bit trick in here, because we also want to cap the power consumption, which makes it different. So in that case if we have -- if you, say, executed this benchmark and or we have some predictor that can tell us what will be the ANP of executing workload I on server J, and what will be the additional power over idle from executing P over J -- I over J, sorry, then we can actually write an IOP, like this one. And when you solve this IOP optimally, it seeks to maximize the SNP such that each workload gets assigned to a server, and each server has at most one workload, and the total power budget is met. So we're meeting the power budget this time by shuffling things around. Now, because of this constraint, this actually has to be solved as an IOP. Which is a problem because of runtime. So we relax it and we round the solution. We found that actually when you relax it and you round the solution, in 99.99 percent of the cases you don't get, in the rounded solution, any violation to the constraints. But sometimes it can happen that two workloads get assigned to one server and one server's free. So in that case we kind of have a little clean-up procedure that if the founding solution is not correct then we just have heuristic to fix it. But it works nicely. So this is if you have jobs in the queue, you have free servers and you want to map it to them. >>: So this approximation, are you solving an IOP as an LP? Shief Reda: We're solving, yeah, exactly ->>: And then the RAM? Shief Reda: And then the RAM. Now, so this is if you're mapping the jobs to pre-servers, but in many cases you actually want to -you're having the high utilization, and then you want to apply co-runners. You want to co-run applications together. Problem with co-running application is interference. When you run them together they're going to degrade the performance. So this is also another extended experiment many people have done, including this group; you run those pairs of applications together and you see the average degradation that is happening to the ANP. If you don't run them together then they get an ANP1, but if you run them together, they degrade. And what you will see in here is basically applications that are memory-bound tend to actually degrade more if you locate them with each other. Makes sense, because they might among a shared resource, which is the memory controller and the main bus and the main memory. So when you co-locate them on the same server, they tend to degrade with each other. So can we somehow map the workloads, the server in such a way that we can like put nice people together with each other on the same server and minimize degradation? And that's what we want to do. But the main -- before we can do that, we have to capture this interference in the linear program. And the way we do this is with the last level cache misses. If we know the last level cache misses in the application, this is something we can characterize in advance, then we can actually have a model that predict the degradation that will happen to work [indiscernible] if it's assigned to server J that has already some existing workload. So how does this work? Let's look at this plot. This plot, actually each point in here represents a core location or pairs of application. And I'm plotting in here the sum of the LLC misses of those individual applications. So before I put them on the same server, I profile them beforehand, I know the LLC of each one of them, I sum them up and run them on the server, and that's the ANP that I will get. And what you're seeing in here is a clear trend is that the sum of the LLC increases. That of course means they're more memory-bound than degradation will increase. And then we can capture that degradation basically in this formula. So the only thing you need to know to figure out the degradation from assigning a workload I to some server J is just having the LLC for the servers that exist plus the workloads and you plug them in here and you get number one. >>: So there are many simplifications here; right? Shief Reda: There are many simplifications. >>: No IO, the LLC misses that are additive. Shief Reda: So we're not necessarily assuming that they're additive. Because we added them beforehand. So there are two ways that you can do it. You can have a model that says what will be the LLC if I add these two and then use this to query another model, that gave me the degradation. Or then what do we do, it's just one direct model. So you're assuming that LLC beforehand, but this is the ANP actually co-locating them together. So it's like a shortcut directly to it. >>: Right, but you're looking at only a pair of applications; right? Sherief Reda: Yeah, so there's a chance -- so that's another thing open for future work. You could have three or four -- yeah, could be more. Or however many. >>: And we need to do this for every [inaudible]. Sherief Reda: So you actually need to -- it's a good point. This function will be one for each kind of server. So this degradation has to be learned for every class of servers. So there's four of them in my experiments. But if you have this degradation function, so here it is, the jobs in the queue, so this time I'm having the servers with just one workload. Then in that case you want to assign those jobs to the busy servers to still maximize the SNP. But this time there's a little thing in here, which is the degradation that's going to happen. So that's the old ANP. But I have to subtract twice the degradation. Why? Because the "I" was the average of the two. So when I'm assigning this to this one, this one will degrade and the original one will degrade, because of this co-runner, and that's why there's a factor of two in here. >>: So you think that the number of workloads that you're trying to co-locate, do you think it's going to have an impact on how good the approximation is? Sherief Reda: So here's the trick. This LP approximation is trying to model what's in reality, but it's not a perfect model. But it's solutions is definitely better than many of the heuristics done in the literature. So this is what I will show. So the goal -- the goal is not necessarily to say my LP is a perfect mimic of what's in reality. But what you want to do is that it has a good fidelity with the good solutions, meaning that the solution gives [indiscernible]. >>: So have you tried to use a different heuristic, like use a simulator -Sherief Reda: Yes, we use the paragon paper from the guys at Stanford? So we use their model for corunners, and we basically have better results. We just smitted this paper. So this part in here is still 234 submission. But we have better results than paragon. >>: So doing two workloads per server? Sherief Reda: There's a potential for more, but we do two right now. >>: Yeah, we found that two is sort of a greedy algorithm or LP can solve, it's more [indiscernible] -Sherief Reda: I mean I don't know how this model will look like if we have any more than -- to look more complicated. >>: It's not a greedy thing any more. You can do the two co-runners, is already -- it's an LP, right, so it's going to be hard. [indiscernible]. Sherief Reda: So the LP is no longer NP hard. We relax the LP to LP and it works. But it gives better results than greedy, because greedy is basically what Paragon is doing in many of its decisions. So another thing is ->>: But they're really fast though. Sherief Reda: Paragon is really fast, yeah. LP is slow. >>: And a question. So memory is just one of the rates, so I'm [indiscernible]. Sherief Reda: Yeah, so that's a good question. And I think it echos what you were saying about the IO's was what was Ricardo was saying. >>: Yeah. Sherief Reda: So in here, we're just modeling memory bound. But if you have a cluster and there is, say, some communicating with NPI, network interfaces, hard disks or SSD's -- >>: So the disk is really -Sherief Reda: Yeah, so it's a function of your workload. So we're using PARSEC and spec, so this works well with it. But for other kind of application, it's the thing. You know, I mention in the beginning how the degree of freedom applies and for the different servers, and then I mention kind of like cheaply that, you know, that the workloads -- which workloads you choose is actually a big degree of freedom that will change all your conclusion about the whole -- all these techniques, including this next one. So for instance, when you map -- I'm wondering how much time do I have left? Because I think -- right now it's one hour exactly from when we started. Are people okay for another -Jie Liu: Yeah. Sherief Reda: Okay. So the next technique is that in here if you recall, we're talking the workloads that come in the queue, assign them to the pre-servers. If you have low utilization, then hopefully you will have enough free servers from the different kind of server classes. So you still get a good solution. But if you have high utilization in your servers, there's -- in your datacenter, there's a chance at that time jobs actually won't get their best servers. However, after time maybe one server will finish the workload that was assigned to it. And maybe in that case it's good to start migrating application from one server to the other. So we did some experiments with live migration, with the Xen Hyperviser, and it's a little bit tricky; and again, it's a function of workloads. If your workloads really spends two, three seconds, it's not worth it to migrate. But if your workload takes enough long time, say, a couple of minutes like happening in this spec and PARSEC, then in that case it might be a good idea to serve from Server A to switch from Server B. In that case, the runtime will be almost a linear combination. Because when you do live migration the downtime is really low at the end; right. If you have cold migration and you have live migration and they have different tradeoffs. But with live migration, the downtime at the end is really tiny. So we looked at actually this idea of the linear combination with the actual runtime between two servers. So these are two servers in here, Server A and Server B, and there's something called initiation time, which is how far into the application you engage it to do it to migrate on the other virtual machine. So the transition time it zero. It means that I move this application right away to Server B. And in that case you're incurring the runtime mostly of what Server B is, which is the good server. But if your [Indiscernible] time is really low, if you were really late in migrating this application, then most of your runtime will be incurred on Server A. Anything in the pin is basically a linear combination, and that's the actual estimated time with the linear combination versus the actual time. Live migration, it incurs little downtime, overhead, but it still has two problems. One of them is network traffic. Because right now if you migrate the virtual machines they will be going from one rack to another rack, because we said each rack has the same set of servers. So if you go outside the rack, you're going on that switch on top of the rack, and that basically is going to create network traffic. So that's going to impose a limit on the number of virtual machine migrations you can do. In addition, during the live transfer phases, actually additional power consumption somewhere between 5 to 10 percent. It's a function of how big, say, the memory allocated for your virtual machine. But that's another thing that can happen, and for PARSEC applications and spec, you can have this additional 10 power consumption for about twenty seconds, during the live transfer phase. >>: You're making an assumption that it's no point in migrating between machines of a blank characteristics. But what if your VM is a different size and you want to pack different size VMs to a small -Sherief Reda: Good point, consolidating virtual machines, yeah. There's a lot of paper in that. So in here we actually have all the virtual machines at the same configuration. So there was one inherit difference from moving it to another one. It's really the server that's running the virtual machine that's giving it either higher performance ->>: Is that something you observe in real life in your own cluster? Sherief Reda: You guys have bigger clusters than mine, so you tell me about it. [laughter] I had two computers just migrating things between them. So you know better what is the deal in here. So if you want to do migration -- and also with co-runners. So there's no point -- if we say all the virtual machines have the same configurations, it could be useful to migrate if you have co-runners. So maybe the initial co-runner assignment was no good, but now something is free, you can move it and now this co-runner is a better scenario. So that's another thing. So how are we going to do it? If you really want to rip up all the workloads and remap them, that's a quadratic program. Because now we need to model two free ones. So how do we do this? So this is our algorithm. So if we imagine these are workloads on the servers, what we do first is flood them into two mutually exclusive sets, say the set left and the set R. So no two [indiscernible] residing on the same server exist in the same set. So you see how they're mutually exclusive and each one has one workloads. What we do is, say, fix set R. Let's imagine those workloads are fixed on the servers and then we rip off the workloads that are on L. Once we rip them off we can calculate the new ANP as a linear combination of the initiation time of the migration. And then basically use our good -- use our old good LP. Because one of the workloads is fixed, it's like you're ripping half of it and you're allocating it with co-runner. So it's a same problem. Then you remap them, you shuffled L, you fix it, and you do the same thing for R. Now you calculated, updated the performance, and then you rip them and reshuffle them. So you basically solved the LP twice, and this way we can break the complexity that will come from assigning two application at the same time. Any questions about how this algorithm can actually work? Otherwise, if you think about it, the problem will be quadratic, you will have XIG times XIG if you want to map two things at the same time. So that's the way we break it. There's a little slide in here ->>: [Indiscernible] VMs on the same server, which one do you choose to make [Indiscernible]? Sherief Reda: So in here we just assume two co-runners. So really there's only two. So that's why I'm dividing into set L and R. If there are more than we have to change the degradation, we have to change this algorithm. So now for simplicity, it's only two. There is a slide in here. Maybe I won't go into much details, but all these LPs require you to know the ANP, the power, and the LLC of the application. In many cases you've seen these applications before in the datacenters, you know their characteristics. But in some case it's not. And we have a machine learning technique in here that can actually run the machine for very briefly on a reference server and actually estimate the characteristics on different clusters of servers that the workload did not run on. And it's better than the one that in Paragon which uses the NetFlix heuristic, if you would, that paper. So this is, again, our experiment repeats. We have eight racks in here, two racks per cluster server, so these are four different servers -- or not really servers, but four different machines in my lab with different configuration. And again we execute the applications on all of them to get the application traces for performance, LLC, and power, and then we feed it to the simulation to the queuing simulator, and we run it until study state. In here we compare our technique, HetMan, with one technique in the literature, Paragon. We actually modified Paragon a little bit so that can work at multiple power budgets. And you see in here that it's given you -- first of all, it's meeting the different power budget you give it for the cluster by just moving things around and reshuffling the applications to the servers. And it's always consistently given 12.5. So Paragon is mostly based on that greedy heuristics. This is just a runtime trace. Initially the power consumption of that simulator, under medium load conditions for the datacenter, there is no constraining power. The utilization increase a little bit, Java rate increases, so the power goes up and down. At some point with the HetMan, we have a 38-kilowatt budget, make sure application get assigned to server so that you meet it, so it meets it. And if you increase the power budgets a little bit it will allow this extra. >>: But if you just show this, this is not a fair comparison to Paragon; right? Because the goal there was not to profile all of these different applications and the combinations and so on, right, we're doing that. Sherief Reda: So that's the slide that I skipped. So I actually have Paragon, I have -- I can show you the comparisons afterwards. So this is actually -- Paragon, as I mentioned, has desk NetFlix heuristics, is that it does not profile every -- I don't profile every combination of workloads, and that's why this function [Indiscernible], I use the sum of the LLC of the individual applications rather than the sum when I run them together. Because then in that case I will need to profile every pair. So what we do in here basically, it's similar in style to Paragon, but the idea is different. You can profile a application on one server, so this is a different server than instructions per second, and I get a certain number. And then from that number I use it to figure out the instruction per second if I run it to on platform A or Platform C or Platform D. And these models in here basically capture the relationship between the LLC of a reference server versus another server from a different class. So this is different from Paragon which is uses, since you're familiar with it, uses the NetFlix heuristic. And this one actual actually is based on a more simpler observation, is that there is actually links between the different servers in many ways. If I have a processor is four cores I'm expecting it to have twice the number of instructions it had per second. So there is actually a physical reason why this server is behaving like the other one. The NetFlix is not assuming this. The NetFlix is people random choices and moods, whatever. This one actually, there is a physical reason why a server would have high LLC than the other one, is they have to have the cache. If you have the cache memory, then it's expected that you have a higher LLC. Same thing, if I have a System C that has a higher DVFS, I will always get higher power for that system. So we can have upper [Indiscernible] models built that link this information that we need to characterize things directly and we don't need to profile every pair of applications. And actually I have results, I can show it afterwards, for our technique using the heuristics from Paragon and the ones we are using, and you can see the difference right away. So we actually even mixed and matched their components just to isolate how much we're better here and there and so forth. So let's get some insights in here on what's happening. This I think actually one of my favorite results. This shows you, as a function of the job arrival rate into the queue of the system, what will the SNP look like. So when you have low job arrival rate, your datacenter is locally utilized, then it's simply mapping the free application and the applications to the free server works really well. There's no reason for co-runners. Co-runners are actually going to degrade things. Because you have low utilization, things come in the queue, they get their favorite servers right away. If you degrade things, you know, they don't sit in -- they don't wait in the queue for a long time. But so the waiting time in the queue is much less than the penalty you get from co-runners. So that's why there is no point in doing co-runners when you have low utilization. When you do the migration, it doesn't give you a big improvement. Why? Because the server was low utilized to begin with, which means there were enough diversity within that system to map the jobs and get the best performance. There is no point in migration. But if we increase the job rate, things start to switch. So in that case, for instance in here, it's better to do co-runner than a single application. Why? Because if you do single application, the workload will stay in the queue, the job will stay in the queue for a long time; that it's degradation, because waiting in the queue will be higher than its degradation if you run it as a co-runner. So co-runner in here becomes better. And this trend appears over time. As the server -- as the datacenter became more and more utilized, it's better to do co-runner than to make things run as a single -- on a single server on its own. Because the waiting time in the queue will keep increasing. And the same trend. As the datacenter becomes more and more utilized, the advantage of migration keeps increasing; the relative advantage from using migration. Because it's utilized, it means that applications when they get assigned in the first time, they're not assigned to their best machines. So by periodically revisiting the assignment, you can get better results. And important metric in here is the number of virtual machine migrations. So we've found in our experiment it's about 20.8 percent to 6.7 percent of the virtual machines being migrate. So that's good news. If we were talking about migrating 50 percent of the virtual migration in this technique, it doesn't work. So this is a reasonable number and it's a function of whether we have co-runners or not. >>: And [indiscernible] is 5 percent migration; right? Sherief Reda: The virtual machine migration, right, that will be the overhead. >>: So it's 5 percent of this one. Sherief Reda: Yeah, it's 5 -- no, no, this is the number of virtual machines that will need to be migrated. >>: So each machine is 5 percent overhead? Sherief Reda: No, let's say you have 400 virtual machines running in your -- virtual machines running in your center. Then you run your algorithm. How many of them will migrate? So 5 percent of the 400. So 20 virtual machines will be migrated around. And that's important, because the more virtual machine you're migrating, the more network traffic you're creating and the whole thing will start to degrade. I think there's -- this needs to be dug deeper with a real datacenter with network topology, and know, you get it right. In that case you can assess how things will interfere with each other. But it needs a more detailed simulator. Should I go on? There's a final part in here for cooling, for datacenter cooling where you actually have a -- the problem in here is that we're assume that we're given a power budget for computing, but in reality you have a total power budget for the datacenter. And that total power budget needs to be partitioned between the computing and the cooling in a self-consisting way, meaning that this cooling power is sufficient to extract the computing power, the heat from the computing power. So how can this be done? That's a big question. Do we have time to continue? Or are you people starting to -Jie Liu: Five minutes. Sherief Reda: Five minutes? Okay, I'll try explain it in five minutes. So how can we do this goal? So quickly, the cooling power of a CRAC unit is equal to the heat that is coming to the computing power divided by co-efficient of performance. And the co-efficient of performance is usually an empirical function of T, which is the supply temperature. Easily enough if I set temperature high, the cooling power will go down, something we all aware of. So as the CRAC supply temperature increases, I get higher values for the COP and my cooling power goes down. So how can we compute the cooling power for a data center? Usually the goal is to find the maximum temperature for the CRAC, because that's going to minimize my cooling. But there is a constraint. The inlet temperature of the server has to be within the red line temperature of the manufacture. And to figure this out you actually need to have execute a computation fluid dynamics, and we actually have a tool to do that. So basically that's the computation fluid dynamics from the tool, and from that CFD simulation you can seen the inlet temperature of the servers. And if they are below the red line it means that you're spending more than you need on the cooling, so in that case you increase the supply temperature. And if you see them above the red line, that means you're not doing enough cooling and you have to cut down the supply temperature. So that's the right way to figure the supply temperature in simulation. But now we have this procedure to compute the cooling power. How can we actually split the power? So that comes to our proposed self-consistent method. Let's say I have a datacenter with this total power budget, 70-kilowatt, and I want to split it between computing and cooling. So that really presents this straight line. This straight line is the set of all possible solutions that split the computing and the cooling such that it's equal to 70-kilowatt. So my solution that I'm looking for is somewhere along this line -- let's say the start, and this is where I'm getting, but I don't know what it is. So we can start in the simulation with a particular split, like say this point in here. So let's say I start with this split, 4.45 for computing and the rest is for cooling. Now, I take this 45 watts -- sorry, 45-kilowatts and run my CFD simulation to give me some cooling. Remember, this computing power is less than the start. So it's going to actually use less cooling power. So the cooling power that it needs is 21-kilowatts. But from this point actually I'm consuming way less than my budget, so I can actually increase my computing power budget to become 48. But in that case if it's 48, this cooling is not going to be correct and I need to compute my cooling and it's going to be higher than the start, so I need -- so that's the new cooling. And then this process could be repeated. So right now I'm consuming above the budget, so I will cut it by cutting down my computing. And then I can keep on iterating this procedure until it converges, and we actually have a proof that it does converge. So by doing this self-consistent partitioning, we can zoom in to this magical solution where I know if I give 47 kilowatt to my computing and set the supply temperatures to what this procedure will give me, I will consume 22.8 kilowatt and both of them will sum to be exactly equal to 70 kilowatts. So that's this iterative procedure. We tried it for different power budgets and it always work correctly. It always give you the cooling power and the supply temperatures that would exactly take out what you give to the computing such that the sum in here is exactly equal to the total power budgets. So it works nicely. So just to rehash the whole talk, I hope I did not give you headaches. The first key point is that if we integrate the software, the number of threads, and active number of cores to DVFS, we have a larger exploration space that we can actually leverage to achieve better power capping, better power ranges, better power capping accuracy and improvements in runtime. There are a few future directions to work. The workload is a big one. We can think of the same idea for virtual machines; cannot source the number of resources given for a virtual machine and that becomes your degrees of freedom. Thread pack and choices. We packed threads to the cores, but maybe if we actually carefully look at which thread gets packed with which ones we can get better results. There are also situations where you have asymmetric cores. Maybe your cores are not all having the same preference, like say in new architectures or in some of the new ARM processers will people have these four-plus-one strategies with different cores. Key Point 2 is that we don't need to allocate the power caps here formally to the clusters, server clusters. We can actually leverage the workload characteristics, build the predictor and use it with a knapsack algorithms to get better power locations for a given budget. And the Key Point 3 is that if you have [indiscernible] in your datacenter, you have a large improvement in runtime optimization space, because then you can do co-runners, you can map different applications to different servers, you can do migration, and that gives you a much more better improvement for energy efficiency. There are a few directions, one of them I definitely would love to do is work on a real cluster to answer some of the questions you guys mentioned that are not clearly visible with the simulator we're having, different kind of workloads, especially ones that require more coordination between the servers, because it's important. Right now we're considering each workloads are independent. But maybe actually there's connections between them. Multiple co-runners is something -- was one of the questions in here raised, more than two. There's also the idea of software energy profiling for heterogenous servers. I think it's building models for energy profiles that work across different servers with different server configuration and different makeup as an interesting research direction. Key Point No. 4 is that we don't need to suffer from violation because cooling power exceeds our computing for total power budget. We can actually plan both of them simultaneously in a selfconsistent way so that the cooling can extract the heating power from the cluster and meet the total power budget. One of the things we actually just submitted a work on is that -- this idea is that you can actually reduce the cooling power, not during runtime, but better planning for heterogeneous datacenters. You can actually take the racks from the different server, look at their specs and look at their characteristics, and you can strategically place them in the data center during the planning phase so that you improve your thermal characteristic and reduce the cooling power [Indiscernible]. So it's different -- it's not a runtime degree of freedom, but during the planning you can do some magic layout tricks to kind of cut down the cooling. So this -- some more information in these papers. Some of them appeared and some of them are being submitted. But that's about it. Any questions? [Applause] Sherief Reda: Thank you. Everybody's probably eager to go to lunch or go to do whatever you want. I hold you in here for some time. Sorry about it if you had to -- all right. See you. All right. Thank you guys.