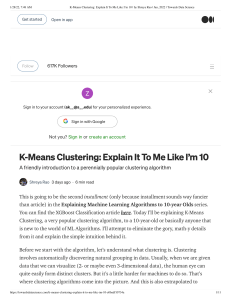
age 18, 22, 25, 42, 28, 43, 33, 35, 56, 28 z
advertisement

1. Given the following measurements for the variables age: 18, 22, 25, 42, 28, 43, 33, 35, 56, 28 standardize the variable by the following: a. Compute the mean absolute deviation of age b. Compute the z-score for the first four measurements 2. Briefly descibe the following approaches to clustering: partitioning methods, hierarchical methods, density-based methods, grid-based methods, model-based methods, methods for high-dimensional data, and constraint-based methods. Give example in each case. 3. suppose that the data mining task is to cluster the following eight points (with (x,y) representing location) into three clusters: A1(2, 10), A2(2, 5), A3(8, 4), B1(5, 8), B2(7, 5), B3(6, 4), C1(1, 2), C2(4, 9) The distance function is Euclidean distance. Suppose initially we assign A1, B1, and C1 as the center of each cluster, respectively. Use the k-means algorithm to show only a. The three cluster centers after the first round execution b. The final three clusters 4. Both k-means and k-medoids algorithm can perform effective clustering. Illustrate the strengh and weakness of k-mens in comparison with k-medoids algorithm. Also, illustrate the strength and weakness of these schemes in comparison with a hierarchical clustering scheme (such as AGNES) 5. Data cubes and multidimensional database contain categorical, ordinal, and numerical data in hierarchical or aggregate form. Based on what you have learned about the slustering methods, design a clustering method that finds clusters in large data cubes effectively and effeciently 6. Suppose that you are to allocate a number of automatic teller machines (ATMs) in a given region so as to setisfy a number of constraints. Households or places of work may be clustered so that typically one ATM is assigned per cluster. The clustering, however, may be constrained by to factors: (1) obstacle objects (i.e., there are bridges, rivers, an highway that can affect ATM accessibility), and (2) additional user-specified constraints, such as each ATM should serve at least 10.000 households. How can a clustering algorithm such as k-means be modified for quality clustering under both constraints? 7. For constraint-based clustering, aside from having the minimum number of customers in each cluster (for ATM allocation) as a constraint, there could be many other kinds of constraints. For example, a constraint could be in the form of the maximum number of customers per cluster, avarage income of customers per cluster, amiximum distance between every two clusters, and so on. Categorize the kinds of constrints that can be imposed on the clusters produced and discuss how to perform clustering efficiently under such kinds of constraints.