Document 11911312
advertisement

Part 4A: Neural Network Learning
10/11/10
A.
Neural Network Learning
IV. Neural Network Learning
1
10/11/10
input
layer
10/11/10
3
. . .
output
layer
hidden
layers
10/11/10
Typical Artificial Neuron
4
Typical Artificial Neuron
connection
weights
inputs
. . .
. . .
• Produce desired outputs for training inputs
• Generalize reasonably & appropriately to
other inputs
• Good example: pattern recognition
• Feedforward multilayer networks
. . .
Feedforward Network
. . .
Supervised Learning
2
. . .
10/11/10
linear
combination
activation
function
output
net input
(local field)
threshold
10/11/10
5
10/11/10
6
1
Part 4A: Neural Network Learning
10/11/10
Equations
Single-Layer Perceptron
. . .
sʹ′i = σ ( hi )
Neuron output:
. . .
⎛ n
⎞
hi = ⎜⎜ ∑ w ij s j ⎟⎟ − θ
⎝ j=1
⎠
h = Ws − θ
Net input:
sʹ′ = σ (h)
€
10/11/10
7
10/11/10
8
€
Single Layer Perceptron
Equations
Variables
Binary threshold activation function :
⎧1, if h > 0
σ ( h ) = Θ( h ) = ⎨
⎩0, if h ≤ 0
x1
w1
xj
Σ
wj
h
y
Θ
wn
€
xn
⎧1, if ∑ w x > θ
j j
j
Hence, y = ⎨
⎩0, otherwise
⎧1, if w ⋅ x > θ
= ⎨
⎩0, if w ⋅ x ≤ θ
θ
10/11/10
9
10/11/10
10
€
2D Weight Vector
N-Dimensional Weight Vector
w2
w ⋅ x = w x cos φ
€
x
–
v
cos φ =
x
+
+
w
w
separating
hyperplane
w⋅ x = w v
φ
€
€
v
w⋅ x > θ
⇔ w v >θ
w1
–
θ
w
⇔v >θ w
10/11/10
€
normal
vector
11
10/11/10
12
€
2
Part 4A: Neural Network Learning
10/11/10
Treating Threshold as Weight
Goal of Perceptron Learning
⎛ n
⎞
h = ⎜⎜∑ w j x j ⎟⎟ − θ
⎝ j=1
⎠
• Suppose we have training patterns x1, x2,
…, xP with corresponding desired outputs
y1, y2, …, yP • where xp ∈ {0, 1}n, yp ∈ {0, 1}
• We want to find w, θ such that
yp = Θ(w⋅xp – θ) for p = 1, …, P 10/11/10
x1
w1
xj
14
⎛ θ ⎞
⎜ ⎟
w
˜ = ⎜ 1 ⎟
w
⎜ ⎟
⎜ ⎟
⎝ w n ⎠
= −θ + ∑ w j x j
wj
wn
xn
j=1
h
Σ
Θ
y
⎛ −1⎞
⎜ p ⎟
x1
x˜ p = ⎜ ⎟
⎜ ⎟
⎜ p ⎟
⎝ x n ⎠
€
Let x 0 = −1 and w 0 = θ
n
j=1
˜ ⋅ x˜ p ), p = 1,…,P
We want y p = Θ( w
n
˜ ⋅ x˜
h = w 0 x 0 + ∑ w j x j =∑ w j x j = w
j= 0
€
10/11/10
€
θ
Augmented Vectors
n
xj
y
Θ
10/11/10
⎛ n
⎞
h = ⎜⎜∑ w j x j ⎟⎟ − θ
⎝ j=1
⎠
θ
= w0
w1
wj
wn
Treating Threshold as Weight
x1
j=1
h
Σ
xn
13
x0 =
–1
n
= −θ + ∑ w j x j
€
15
€
10/11/10
16
€
€
Reformulation as Positive
Examples
Adjustment of Weight Vector
We have positive (y p = 1) and negative (y p = 0) examples
z5
z1
˜ ⋅ x˜ p > 0 for positive, w
˜ ⋅ x˜ p ≤ 0 for negative
Want w
€
€
€
€
z9
z10
11
z z6
p
p
p
z2
p
Let z = x˜ for positive, z = −x˜ for negative
z3
z8
z4
z7
˜ ⋅ z p ≥ 0, for p = 1,…,P
Want w
Hyperplane through origin with all z p on one side
10/11/10
17
10/11/10
18
€
3
Part 4A: Neural Network Learning
10/11/10
Outline of
Perceptron Learning Algorithm
Weight Adjustment
1. initialize weight vector randomly
zp
2. until all patterns classified correctly, do:
€ €
€
€
€
a) for p = 1, …, P do:
1) if zp classified correctly, do nothing
€
2) else adjust weight vector to be closer to correct
classification
10/11/10
19
Improvement in Performance
˜ ⋅ z p + ηz p ⋅ z p
=w
2
˜ ⋅ zp
>w
10/11/10
20
• If there is a set of weights that will solve the
problem,
• then the PLA will eventually find it
• (for a sufficiently small learning rate)
• Note: only applies if positive & negative
examples are linearly separable
˜ ʹ′ ⋅ z p = ( w
˜ + ηz p ) ⋅ z p
w
˜ ⋅ zp + η zp
=w
10/11/10
Perceptron Learning Theorem
˜ ⋅ z p < 0,
If w
€
p
˜ ʹ′ʹ′ ηz
w
ηz p
˜ ʹ′
w
˜
w
21
10/11/10
22
€
Classification Power of
Multilayer Perceptrons
• Perceptrons can function as logic gates
• Therefore MLP can form intersections,
unions, differences of linearly-separable
regions
• Classes can be arbitrary hyperpolyhedra
• Minsky & Papert criticism of perceptrons
• No one succeeded in developing a MLP
learning algorithm
NetLogo Simulation of
Perceptron Learning
Run Perceptron-Geometry.nlogo
10/11/10
23
10/11/10
24
4
Part 4A: Neural Network Learning
10/11/10
Credit Assignment Problem
Hyperpolyhedral Classes
10/11/10
25
. . .
. . .
. . .
. . .
. . .
input
layer
. . .
. . .
How do we adjust the weights of the hidden layers?
Desired
output
output
layer
hidden
layers
10/11/10
26
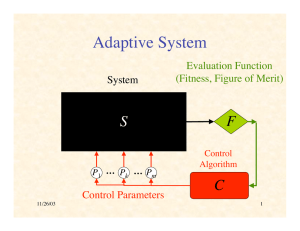
Adaptive System
NetLogo Demonstration of
Back-Propagation Learning
System
Evaluation Function
(Fitness, Figure of Merit)
S
F
Run Artificial Neural Net.nlogo
P1
…
Pk
…
Pm
Control Parameters
10/11/10
27
Control
Algorithm
C
10/11/10
28
Gradient Ascent
on Fitness Surface
Gradient
∂F
measures how F is altered by variation of Pk
∂Pk
⎛ ∂F
⎞
⎜ ∂P1 ⎟
⎜ ⎟
⎜
⎟
∇F = ⎜ ∂F ∂P ⎟
k
⎜ ⎟
⎜
⎟
⎜∂F
⎟
⎝ ∂Pm ⎠
€
∇F
+
gradient ascent
–
∇F points in direction of maximum local increase in F
10/11/10
€
29
10/11/10
30
€
5
Part 4A: Neural Network Learning
10/11/10
Gradient Ascent
by Discrete Steps
Gradient Ascent is Local
But Not Shortest
∇F
+
+
–
10/11/10
–
31
10/11/10
Gradient Ascent Process
General Ascent in Fitness
P˙ = η∇F (P)
Note that any adaptive process P( t ) will increase
Change in fitness :
m ∂F d P
m
dF
k
F˙ =
=∑
= ∑ (∇F ) k P˙k
k=1
k=1
∂Pk d t
€d t
˙
˙
F = ∇F ⋅ P
F˙ = ∇F ⋅ η∇F = η ∇F
fitness provided :
0 < F˙ = ∇F ⋅ P˙ = ∇F P˙ cosϕ
where ϕ is angle between ∇F and P˙
Hence we need cos ϕ > 0
≥0
€
€
€
2
32
or ϕ < 90
Therefore gradient ascent increases fitness
(until reaches 0 gradient)
10/11/10
33
10/11/10
34
€
General Ascent
on Fitness Surface
Fitness as Minimum Error
Suppose for Q different inputs we have target outputs t1,…,t Q
Suppose for parameters P the corresponding actual outputs
+
∇F
€
are y1,…,y Q
Suppose D(t,y ) ∈ [0,∞) measures difference between
–
€
target & actual outputs
Let E q = D(t q ,y q ) be error on qth sample
€
10/11/10
35
€
Q
Q
Let F (P) = −∑ E q (P) = −∑ D[t q ,y q (P)]
q=1
10/11/10
q=1
36
€
6
Part 4A: Neural Network Learning
10/11/10
Jacobian Matrix
Gradient of Fitness
⎛∂y1q
⎞
∂y1q
⎜
∂P1
∂Pm ⎟
⎜
Define Jacobian matrix J =
⎟
⎜∂y q
⎟
∂
y nq
n
⎜
∂P1
∂Pm ⎟⎠
⎝
⎛
⎞
∇F = ∇⎜⎜ −∑ E q ⎟⎟ = −∑ ∇E q
⎝ q
⎠
q
q
∂D(t q ,y q ) ∂y qj
∂E q
∂
=
D(t q ,y q ) = ∑
∂Pk ∂Pk
∂y qj
∂Pk
j
€
Note J q ∈ ℜ n×m and ∇D(t q ,y q ) ∈ ℜ n×1
d D(t q ,y q ) ∂y q
⋅
d yq
∂Pk
q
q
q
= ∇ D t ,y ⋅ ∂y
€
=
€
€
yq
10/11/10
(
)
€
T
37
€
2
2
i
i
i
∂D(t − y ) ∂
∂ (t − y )
=
∑ (ti − y i )2 = ∑ i∂y i
∂y j
∂y j i
j
i
€
€
10/11/10
38
€
Derivative of Squared Euclidean
Distance
Suppose D(t,y ) = t − y = ∑ ( t − y )
=
q
q
∂y q ∂D(t ,y )
∂E q
=∑ j
,
q
∂Pk
∂y j
j ∂Pk
∴∇E q = ( J q ) ∇D(t q ,y q )
∂Pk
€
€
Since (∇E q ) k =
d( t j − y j )
dyj
Gradient of Error on qth Input
d D(t ,y ) ∂y
∂E
=
⋅
q
q
∂Pk
dy
q
q
q
∂Pk
∂y q
= 2( y q − t q ) ⋅
∂Pk
2
= 2∑ ( y qj − t qj )
2
j
= −2( t j − y j )
∂y qj
∂Pk
T
d D(t,y )
= 2( y − t )
dy
€
10/11/10
∇E q = 2( J q ) ( y q − t q )
∴
€
39
10/11/10
40
€
€
Recap
P˙ = η∑ ( J ) (t − y )
q T
q
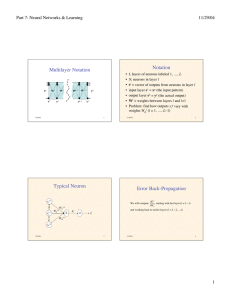
Multilayer Notation
q
q
To know how to decrease the differences between
actual & desired outputs,
€
we need to know elements of Jacobian,
xq
∂y qj
∂Pk ,
which says how jth output varies with kth parameter
(given the qth input)
W1
s1
W2
s2
WL–2
WL–1
sL–1
yq
sL
The Jacobian depends on the specific form of the system,
in this case, a feedforward neural network
€
10/11/10
41
10/11/10
42
7
Part 4A: Neural Network Learning
10/11/10
Typical Neuron
Notation
•
•
•
•
•
•
•
L layers of neurons labeled 1, …, L Nl neurons in layer l sl = vector of outputs from neurons in layer l input layer s1 = xq (the input pattern)
output layer sL = yq (the actual output)
Wl = weights between layers l and l+1
Problem: find how outputs yiq vary with
weights Wjkl (l = 1, …, L–1)
10/11/10
s1l–1
sjl–1
Wi1l–1
Wijl–1
Σ
WiN
hil
sil
σ
l–1
sNl–1
43
10/11/10
44
Error Back-Propagation
Delta Values
Convenient to break derivatives by chain rule :
We will compute
∂E q
starting with last layer (l = L −1)
∂W ijl
∂E q
∂E q ∂hil
=
∂W ijl−1 ∂hil ∂W ijl−1
and working back to earlier layers (l = L − 2,…,1)
Let δil =
€
So
10/11/10
45
€
δiL =
hiL
σ
tiq
siL = yiq
=
WiNL–1
sNL–1
10/11/10
46
Output-Layer Derivatives (1)
s1L–1
Wi1L–1
WijL–1
Σ
∂E q
∂hil
= δil
l−1
∂W ij
∂W ijl−1
10/11/10
Output-Layer Neuron
sjL–1
∂E q
∂hil
Eq
2
∂E q
∂
=
∑ (skL − tkq )
∂hiL ∂hiL k
d( siL − t iq )
dh
L
i
2
= 2( siL − t iq )
d siL
d hiL
= 2( siL − t iq )σ ʹ′( hiL )
47
10/11/10
48
€
8
Part 4A: Neural Network Learning
10/11/10
Hidden-Layer Neuron
Output-Layer Derivatives (2)
∂hiL
∂
=
∑W ikL−1skL−1 = sL−1
j
∂W ijL−1 ∂W ijL−1 k
sjl–1
∂E q
∴
= δiL sL−1
j
∂W ijL−1
€
s1l
s1l–1
W1il
Wi1l–1
Wijl–1
Σ
WiN
10/11/10
49
sil
σ
Wkil
skl+1
Eq
l–1
WNil
sNl–1
where δiL = 2( siL − t iq )σ ʹ′( hiL )
hil
s1l+1
sNl
sNl+1
10/11/10
50
€
Hidden-Layer Derivatives (1)
Recall
Hidden-Layer Derivatives (2)
∂E q
∂hil
= δil
l−1
∂W ij
∂W ijl−1
l−1 l−1
dW s
∂hil
∂
=
∑W ikl−1skl−1 = dWij l−1j = sl−1j
∂W ijl−1 ∂W ijl−1 k
ij
∂E q
∂E q ∂h l +1
∂h l +1
δ = l = ∑ l +1 k l = ∑δkl +1 k l
∂h i
∂
h
∂
h
∂h i
k
i
k
k
l
i
€
€
€
l l
d σ ( hil )
∂hkl +1 ∂ ∑m W km sm ∂W kil sil
=
=
= W kil
= W kilσ ʹ′( hil )
l
l
l
∂h i
∂h i
∂h i
d hil
€
∴
where δil = σ ʹ′( hil )∑δkl +1W kil
∴ δil = ∑δkl +1W kilσ ʹ′( hil ) = σ ʹ′( hil )∑δkl +1W kil
k
∂E q
= δil sl−1
j
∂W ijl−1
k
k
10/11/10
51
10/11/10
52
€
€
Summary of Back-Propagation
Algorithm
Derivative of Sigmoid
Suppose s = σ ( h ) =
1
(logistic sigmoid)
1+ exp(−αh )
−1
Output layer : δiL = 2αsiL (1− siL )( siL − t iq )
−2
∂E q
= δiL sL−1
j
∂W ijL−1
Dh s = Dh [1+ exp(−αh )] = −[1+ exp(−αh )] Dh (1+ e−αh )
€
= −(1+ e−αh )
−2
(−αe ) = α
−αh
e
−αh
−αh 2
(1+ e )
Hidden layers : δil = αsil (1− sil )∑δkl +1W kil
⎛ 1+ e−αh
1
e−αh
1 ⎞
=α
= αs⎜
−
⎟
−αh
1+ e−αh 1+ e−αh
1+ e−αh ⎠
⎝ 1+ e
k
€
∂E q
= δil sl−1
j
∂W ijl−1
= αs(1− s)
10/11/10
€
53
10/11/10
54
€
9
Part 4A: Neural Network Learning
10/11/10
Hidden-Layer Computation
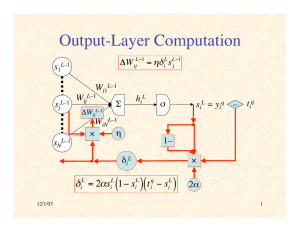
Output-Layer Computation
ΔW
s1L–1
L−1
ij
L L−1
i j
= ηδ s
L–1
sjL–1
Wi1
WijL–1
€
Σ
hiL
sNl–1
L
i
)( t
q
i
L
i
−s
)
hil
Σ
55
€
10/11/10
×
k
Wkil
×
WNil
1–
δil = αsil (1− sil )∑δkl +1W kil
10/11/10
sil
σ
δil
2α
s1l+1
δ1l+1
l–1
WiNl–1
×
η
×
δ = 2αs (1− s
L
i
–
Wi1
W l–1
sjl–1
€ ij
l–1
tiq
1–
δiL
L
i
=
yiq
W1il
ΔWij WiNL–1
η
×
sNL–1
siL
σ
ΔWijL–1
ΔW ijl−1 = ηδil sl−1
j
s1l–1
Eq
skl+1
δkl+1
sNl+1
Σ
δNl+1
α
56
€
Training Procedures
Summation of Error Surfaces
• Batch Learning
– on each epoch (pass through all the training pairs),
– weight changes for all patterns accumulated
– weight matrices updated at end of epoch
– accurate computation of gradient
E
E1
E2
• Online Learning
– weight are updated after back-prop of each training pair
– usually randomize order for each epoch
– approximation of gradient
• Doesn’t make much difference
10/11/10
57
10/11/10
Gradient Computation
in Batch Learning
Gradient Computation
in Online Learning
E
E
E1
E1
E2
10/11/10
58
E2
59
10/11/10
60
10
Part 4A: Neural Network Learning
10/11/10
Testing Generalization
Problem of Rote Learning
error
error on
test data
Available
Data
Training
Data
Domain
error on
training
data
Test
Data
epoch
stop training here
10/11/10
61
10/11/10
A Few Random Tips
Improving Generalization
Training
Data
Available
Data
62
• Too few neurons and the ANN may not be able to
decrease the error enough
• Too many neurons can lead to rote learning
• Preprocess data to:
– standardize
– eliminate irrelevant information
– capture invariances
– keep relevant information
Domain
Test Data
Validation Data
• If stuck in local min., restart with different random
weights
10/11/10
63
10/11/10
64
Beyond Back-Propagation
• Adaptive Learning Rate
• Adaptive Architecture
Run Example BP Learning
– Add/delete hidden neurons
– Add/delete hidden layers
• Radial Basis Function Networks
• Recurrent BP
• Etc., etc., etc.…
10/11/10
65
10/11/10
66
11
Part 4A: Neural Network Learning
10/11/10
Can ANNs Exceed the “Turing Limit”?
What is the Power of
Artificial Neural Networks?
• There are many results, which depend sensitively on
assumptions; for example:
• Finite NNs with real-valued weights have super-Turing
power (Siegelmann & Sontag ‘94)
• Recurrent nets with Gaussian noise have sub-Turing power
(Maass & Sontag ‘99)
• Finite recurrent nets with real weights can recognize all
languages, and thus are super-Turing (Siegelmann ‘99)
• Stochastic nets with rational weights have super-Turing
power (but only P/POLY, BPP/log*) (Siegelmann ‘99)
• But computing classes of functions is not a very relevant
way to evaluate the capabilities of neural computation
• With respect to Turing machines?
• As function approximators?
10/11/10
67
A Universal Approximation Theorem
Suppose f is a continuous function on [0,1]
Suppose σ is a nonconstant, bounded,
monotone increasing real function on ℜ.
€
• Conclusion: One hidden layer is sufficient
to approximate any continuous function
arbitrarily closely
∃a ∈ ℜ m , b ∈ ℜ n , W ∈ ℜ m×n such that if
m
⎛ n
⎞
F ( x1,…, x n ) = ∑ aiσ ⎜⎜ ∑W ij x j + b j ⎟⎟
i=1
⎝ j=1
⎠
€
1
10/11/10
€
xn
n
(see, e.g., Haykin, N.Nets 2/e, 208–9)
b1
x1
[i.e., F (x) = a ⋅ σ (Wx + b)]
€then F ( x ) − f ( x ) < ε for all x ∈ [0,1]
68
One Hidden Layer is Sufficient
n
For any ε > 0, there is an m such that
€
10/11/10
69
10/11/10
Σ
σ
Σ
σ
a1
a2
Σ
am
Wmn
Σ
σ
70
€
The Golden Rule of Neural Nets
Neural Networks are the
second-best way
to do everything!
10/11/10
IVB
71
12