Simulating spatial data
We’ve talked about simulating point patterns
Inference was via simulation
Now consider simulating geostatistical and areal data
Given a set of locations s , a model, and parameter values
want to generate a set of values for Z (s )
Focus on values from normal distributions, want N(µ, σ 2 )
If Z independent, easy: generate
calculate: σ Z + µ
Z ∼ N(0, 1)
If spatially correlated: want N(µ, Σ)
a brute-force algorithm:
calculate µ or µ(s) for each location if trend
determine Σ from geostat model or equ’s for CAR/SAR
calculate C = Cholesky square-root decomposition of Σ.
simulate vector of standard normals, Z ∼ N(0, I )
0
return Z (s ) = µ + C Z
c Philip M. Dixon (Iowa State Univ.)
C C =Σ
Spatial Data Analysis - Part 14
0
Spring 2016
1/7
Why does this work?
Mean:
E
Z (s ) = µ + C
0
Z =µ
E
Variance:
Var
Z (s ) = C
0
Var
ZC = C IC = C C = Σ
0
Distribution: linear compbinations of normals
Example:
3 2 1
1.75
Σ = 2 3 2 , C ≈ 0
1 2 3
0
0
are normal
1.15 0.58
1.29 1.03
0
1.26
Zs1 = 1.73Z1
Zs2 = 1.15Z1 + 1.29Z2
Zs3 = 0.58Z1 + 1.03Z2 + 1.26Z3
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 14
Spring 2016
2/7
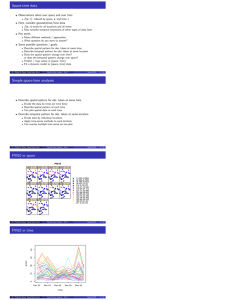
Timing: k = 50,
simulate 1000 sets separately: 7.18 sec
simulate all 1000 simultaneously: 0.04 sec
Difference is time req. to calculate the Cholesky
Practical use:
either calculate C once, do Z (s ) “by hand”
or, simulate many sets, use as needed
Cholesky algorithm fails if Σ is large,
“turning bands” algorithm
simulate a direction θk (will have many of these)
simulate many X ’s in that direction (1D problem)
for any Z (s), project Z (s) (in 2D) onto the line, record X at that
projected location
repeat for many (often 15) directions, average contributions from all
directions
The detail is relating the 2D covariance function for Z (s ) to the
corresponding 1D covariance function for the line
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 14
Spring 2016
3/7
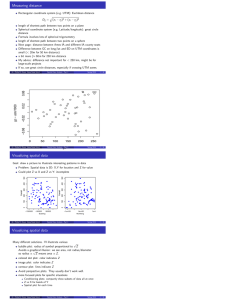
Conditional simulation
Previous method generates a new data set
mean and covariance functions given by the model
same in original data and simulation
but realization may look completely different from original data set
original data may have a high region in top left corner
simulation may have that in the middle, or lower right
Conditional Simulation:
Given values at obs. locations, simulate values at other points
simulation of new values conditional on obs. values
Why use this?
visualize uncertainty
calculate uncertainty in quantity calculated over entire area
e.g. overall average or total, % area > some action level
both assume exact measurements at obs. locations
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 14
Spring 2016
4/7
Conditional simulation
“honors” observed values at {s c }
want to simulate random values at {s n }
the usual algorithm:
calculated kriging predictions = Z ∗ (s n ) using values at Z (s c )
simulate unconditional random field at {s c } and {s n } = Z ◦ (s c ) and
Z ◦ (s n )
calculate kriging predictions = Z † (s n ) using values at Z ◦ (s c )
return Z ∗ (s n ) + Z ◦ (s n ) − Z † (s n )
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 14
Spring 2016
5/7
Conditional simulation properties
If s is a conditioning point (obs. value), i.e. one of the locations in
the {s c } set,
1st kriging prediction: Z ∗ (s c ) = obs. value, Z (s c )
2nd kriging prediction: Z † (s c ) = obs. value, Z ◦ (s c )
so returned value is obs. value, Z (s c )
If
s n is far from any obs. loc, s c :
Z ∗ (s n ) = µ and Z † (s n ) = µ
so return the unconditional predictions, Z ◦ (s n )
Both behaviours for extreme situations “make sense”
Usually only used for geostat data.
With areal data, have an obs. value for all regions in study area
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 14
Spring 2016
6/7
Simulating areal data
Usually much easier than geostat data: many fewer regions
Use brute force algorithm used for small geostat data sets
Given connection matrix and dependence parameter, calculate VC
matrix
Calculate Cholesky decomposition
Simulate appropriate number of standard normals,
multiply by Cholesky to the a realizaiton from the mvNormal
All has been for mvNormal distributions
simulating correlated non-normal distributions much harder
and sometimes the distribution doesn’t exist
c Philip M. Dixon (Iowa State Univ.)
Spatial Data Analysis - Part 14
Spring 2016
7/7
 0
0