Intro to Statistics Stat 430 Fall 2011
advertisement

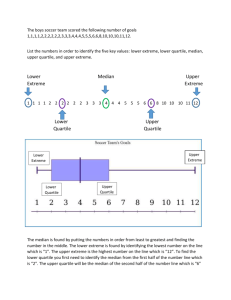
Intro to Statistics Stat 430 Fall 2011 Outline • Data Exploration • Statistics • Estimators • Properties • Maximum Likelihood Estimation • Method of Moments Statistics • (Exploration) • Estimation of Parameters • Hypothesis Testing • Predictions Data Exploration • Understanding patterns/structures based on collected data • sample: data on a representative subgroup of the total population • representativeness allows us to make generalizations Statistical Summaries • Let x , x , ...., x 1 2 N be observations • a statistic is a summary of these numbers: e.g. average, minimum, maximum, range, quartiles, median for categorical values: mode, levels Graphical Summaries Barchart Spinogram Graphical Summaries Histogram %capital Spineplot Graphical Summaries Scatterplot Excursion: Five Point Summary • Let x , x , ..., x be n observations, • the five point summary is made up of 1 2 n min, 1st quartile, median, 3rd quartile, max • the difference of 3rd quartile and 1st quartile is called Interquartile Range (IQR) Excursion: Outlier • The Interquartile Range (IQR) gives an estimate of the variability in the data • an Outlier is a point, which is 1.5*IQR above the 3rd quartile or 1.5*IQR below the 1st quartile Boxplot -3 -2 -1 0 1 2 A boxplot consists: outliers below lower hinge: point, above 1st quartile - 1.5*IQR 1st quartile median 3rd quartile upper hinge: point, below 3rd quartile + 1.5*IQR outliers above Boxplots • are great • for spotting outliers • comparing means (medians) of different samples • not a good idea • if data has multimodal distribution • as the only display of the data . ∩ Xn = xn ) n � i=1 i=1 n→∞ Xi are independent! P (Xi = xi ) n � = =Θ̂2 ] P (Xi = xi ) V ar[Θ̂1lim ] ≤ VPar[ (|Θ̂Θ̂−−θ|θ|>>�)�)==00 lim P (| n→∞ = i=1 P (X1 = x1 ) · P (X2 = n→∞ Estimators V ar[Θ̂ ] ≤ V ar[Θ̂ ] V(*) ar[ Θ̂2 ]2 P (|Θ̂ − θ| E[Θ̂] = Θ̂ θ 11] ≤ V ar[lim n→∞ θ̂ := Θ̂(x1 , x2 , ..., xk ) E[Θ̂] Θ̂]==θθ V ar[Θ̂1 ] ≤ V E[ Θ̂(X , Xi.i.d. Xk ) variables ,X ...., be random 1Θ̂ 2,θ| k1 limLet P (|XΘ̂ −:= >X�) = 02 , ..., n→∞ :=Θ̂(x Θ̂(x1 1, ,xx2 2, ,..., ...,xxk k) ) θ̂θ̂:= with Xi ~ F θ Θ θ̂ Θ̂ E[Θ̂] = �Θ̂Θ̂∞ V then ar[Θ̂a1 ]statistic ≤ V ar[ ] Θ̂(X Θ̂(X1 1, ,XX2 2, ,..., ...,XXk k) ) 2:= := θ̂θ̂ := := Θ̂(x Θ̂(x11,, xx22, (f ∗ g)(z) = f (x)g(z − x)dx is called estimator −∞ofθθ ΘΘ θ̂θ̂ Θ̂Θ̂ � � Θ̂ X22 E[Θ̂] = θ � � Θ̂ := := Θ̂(X Θ̂(X1 , X ∞∞ (f∗∗g)(z) g)(z)== f(x)g(z (x)g(z−−x)dx x)dx (f f P (X + Θ̂(x Y ≤1 ,z) f−∞ (x, y)dydx X,Y θ̂ := x2= , ..., xk ) is the estimate of θ Θ Θ θ̂θ̂ −∞ x+y≤z � ∞ � � � ∞ � � � 1∞ �2 ,z−x Θ̂ := Θ̂(X , X ..., X ) k (f ∗∗ g)(z) g)(z) ff(( (f P (X + Y ≤ z) = f =(x, y)dyd • • • α Xi are independent! ∩ X2 = x2 ∩ . . . ∩lim Xn = =+=c)0 n )− P (|xΘ̂ (θ̂ θ| −> c, θ̂�) n→∞ Properties Pof (| θ̂ −Estimators θ| <Θ̂c)] > α V ar[ Θ̂ ] ≤ V ar[ � n = • 1 2 P (Xi = xi ) i=1 = P (X1 (*) Xi are independent! ∩ X2 = x2Unbiasedness: ∩ . . . ∩ Xn = E[ xnΘ̂] ) =θ = = P (X θ̂ :=lim Θ̂(xP1 ,(|xΘ̂2 ,− ...,θ|xk>) �) = 0 n n→∞ � Efficiency: Estimator 1 is more efficient than = Θ̂P (X x1 ,iΘ̂ )X2] ,≤...,VX (*) ) iV=ar[ k Estimator 2,:= if Θ̂(X ar[Θ̂2 ] 1 i=1 θ Θ θ̂ Θ̂ � ∞ E[ Θ̂] lim P (| −= θ| θ>−�) =0 Consistency: (f ∗ g)(z) n→∞ = fΘ̂(x)g(z x)dx −∞ θ̂ � := �Θ̂(x1 , x2 , ..., xk ) V ar[Θ̂1 ] ≤ V ar[Θ̂2 ] P (X + Y ≤ z) Θ̂ = := Θ̂(X1 , Xf2X,Y , ...,(x, Xy)dydx k) • • Estimator: Example • The average of i.i.d. observations x , x , ...., xN is an unbiased estimator of the expected value 1 2 Finding Estimators AMETER ESTIMATION • i.i.d. observations x , x , ...., x Maximum Likelihood Estimation 1 2 N from We have n data values x1 , . . . , xn . The assumption is, that these data values are realiza distribution Fµ om variables X1 , . . . , Xn with distribution Fθ . Unfortunately the value for θ is unknow X observed values x1, x2, x3, ... f with =0 f with = -1.8 f with =1 ng the value for θ we can “move the density function fθ around” - in the diagram, the thi ts the data best.idea : choose µ so, that we maximize since we do not know the true value θ of the distribution, we take that value θ̂ that m likelihood to observe x1, x2, ...., xN the observed values, i.e. something like • X̄1 − X̄2 ± z · n1 + n2 � � α σ σ X̄ − z · √ , X̄ + z · √ n (θ̂n− c, θ̂ Maximum Likelihood + c Estimation P (|θ̂ − θ| < c) α (θ̂ − c, θ̂ + c) Likelihood function: P (|θ̂ − θ| < c) > αX • P (X1 = x1 ∩ X2 = x2 ∩ . . . ∩ Xn = xn ) i are indepe = Xi are independent! P (X1 = x1 ∩ X2 = x2 ∩ . . . ∩ Xn = xn ) n � = n � = P (Xi =i=1 xi ) = P (Xi = xi ) = P (X1 (*) • for discrete data L(µ; x , ...., x ) = ∏ p (x ) lim P=(| lim P (| Θ̂) −=θ| >f�)(x 0Θ̂ − θ| > continuous data L(µ; x , ...., x ∏ ) • n→∞ i=1 1 1 n→∞ n n µ µ i i V ar[Θ̂1 ] ≤ V ar[Θ̂2 ] V ar[Θ̂1 ] ≤ V ar MLE • Set up likelihood function L • Find log likelihood l • Find derivative of l w.r.t parameter • Set to 0 • solve for parameter Method of Moments • • Example: Pareto Distribution Estimate kth moment µk by 1/n∑xik